DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
引言
任务规划在机器人技术中扮演着至关重要的角色。它涉及到为机器人设计一系列中级动作(技能),使其能够完成复杂的高级任务。这一过程不仅需要考虑机器人的能力,还需考虑周围环境以及可能存在的各种约束和不确定性。近年来,利用大型语言模型(LLMs)直接生成动作成为了任务规划领域的新趋势。这种方法因其卓越的性能和用户友好性而受到青睐。然而,传统的基于LLM的任务规划方法存在诸多效率问题,如高代价的令牌消耗和冗余的错误修正,这些问题限制了其在大规模测试和应用中的可扩展性。
论文概览
- 标题:TREE-PLANNER: Planning with Large Language Models for Efficient Close-Loop Task
- 作者:Mengkang Hu, Yao Mu, Xinmiao Yu, Mingyu Ding, Shiguang Wu, Wenqi Shao, Qiguang Chen, Bin Wang, Yu Qiao
- 机构:
- The University of Hong Kong
- Noah’s Ark Laboratory
- Harbin Institute of Technology
- Shanghai AI Laboratory
- 链接:https://arxiv.org/pdf/2310.08582.pdf
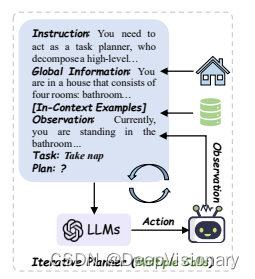
TREE-PLANNER方法介绍
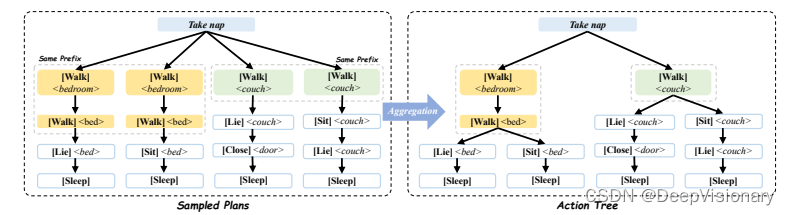
TREE-PLANNER是一种新型的任务规划方法,它通过将任务规划过程分解为三个阶段来提高效率和减少错误:计划采样、动作树构建和基于环境的决策。这种方法首先利用大型语言模型(LLM)来采样可能的任务计划,然后将这些计划聚合成一个动作树,最后在执行过程中根据实时环境信息对动作树进行决策。

1. 计划采样(Plan Sampling)
在这一阶段,TREE-PLANNER利用LLM根据任务的全局信息和初始观察来生成一系列潜在的任务计划。这些计划是基于LLM的常识性知识生成的,每个计划都是一系列动作的序列。
2. 动作树构建(Action Tree Construction)
在动作树构建阶段,采样得到的所有潜在计划被整合到一个树状结构中。这个动作树的构建是通过比较不同计划中的动作并将相同的动作聚合在一起来实现的。这样可以避免在执行相同动作时的重复工作,提高执行效率。
3. 基于环境的决策(Grounded Deciding)
最后一个阶段是基于当前环境信息对动作树进行顶向下的决策。TREE-PLANNER会根据实时的环境反馈调整计划,选择最合适的动作执行。当执行中发生错误时,TREE-PLANNER能够通过回溯动作树灵活地进行错误修正,从而减少了错误修正的次数和代价。
通过这三个阶段的分解,TREE-PLANNER大大减少了令牌的消耗和错误修正的需要,使得任务规划更加高效和准确。
实验设置与数据集描述
环境
实验在VirtualHome环境中进行,这是一个用于模拟家庭任务的仿真平台。VirtualHome包含多个场景,每个场景中都有数百个对象,这些对象具有各自的属性,并且对象之间存在关系。例如,一个任务的目标条件可能是“电视已打开”,这需要在环境中找到电视并执行打开操作。
数据集
我们构建了一个数据集,包括4个VirtualHome场景和35个独特的家庭任务。每个任务都包括任务名称、目标条件和一个标准计划。我们首先从VirtualHome的ActivityPrograms知识库中注释目标条件,然后通过执行这些程序来生成标准计划。为了确保数据质量,我们采用了简单的启发式规则来过滤掉质量低的注释,并通过两名计算机科学专业的研究生进行手动质量控制。
评估指标
我们使用四个指标来评估不同方法的性能:可执行性(EXEC.)、成功率(SR)、目标条件召回率(GCR)和评估的财务开销( C O S T )。 E X E C . 指的是计划是否可以在给定环境中执行,而不考虑其与任务的相关性。 G C R 通过比较生成计划达到的目标条件与真实目标条件的差异来计算。 S R 衡量是否所有目标条件都已满足,即当 G C R = 1 时, S R = 1 。 COST)。EXEC.指的是计划是否可以在给定环境中执行,而不考虑其与任务的相关性。GCR通过比较生成计划达到的目标条件与真实目标条件的差异来计算。SR衡量是否所有目标条件都已满足,即当GCR=1时,SR=1。 COST)。EXEC.指的是计划是否可以在给定环境中执行,而不考虑其与任务的相关性。GCR通过比较生成计划达到的目标条件与真实目标条件的差异来计算。SR衡量是否所有目标条件都已满足,即当GCR=1时,SR=1。COST用于评估不同方法的令牌效率,根据OpenAI提供的定价计算。
通过这些设置和评估指标,我们能够全面地测试和比较TREE-PLANNER与其他基线模型的性能和效率。
主要实验结果与分析
在VirtualHome环境中进行的实验表明,TREE-PLANNER在两种设置下均展现出了卓越的性能。在允许修正错误的设置中,TREE-PLANNER在成功率方面超过了最佳基线模型1.29%,在不允许修正错误的设置中,这一优势更是提高到了3.65%。此外,TREE-PLANNER在令牌效率上也表现出色,相比ITERATIVE-PLANNER,其令牌成本降低了53.29%。在允许修正错误的设置中,与LOCAL REPLAN和GLOBAL REPLAN相比,令牌成本分别降低了74.36%和92.24%。
修正效率方面,TREE-PLANNER减少了37.99%和40.52%的动作重试次数,这一改进显著减少了令牌消耗。这些结果不仅证明了TREE-PLANNER在执行任务规划时的高效性,也显示了其在处理动态和复杂环境中的高适应性。
讨论TOKEN与修正效率
1. TOKEN效率
TREE-PLANNER通过将LLM查询分解为单一的计划采样调用和多个基于环境的决策调用,显著降低了令牌消耗。在传统的ITERATIVE-PLANNER中,每一步执行都需要重新加载和处理全局信息和环境观察,导致高令牌消耗。TREE-PLANNER通过一次性采样并构建行动树,减少了这部分重复的计算成本,从而实现了高令牌效率。
2. 修正效率
TREE-PLANNER的修正机制提供了一种介于LOCAL REPLAN和GLOBAL REPLAN之间的新方法。通过在行动树上进行回溯,TREE-PLANNER允许在发现执行错误时,不必重新从头开始规划,而是从上一个有效的分叉点重新决策。这种方法不仅减少了决策的冗余,也大大减少了因错误修正而产生的时间和令牌消耗。
总体来看,TREE-PLANNER通过创新的任务规划方法有效地解决了传统LLM任务规划中的令牌和修正效率问题,提供了一种既高效又实用的新框架。
错误分析与未来方向
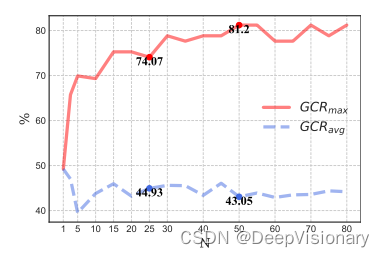
在TREE-PLANNER模型的实验和分析中,我们发现了几个关键的错误类型和潜在的改进方向。首先,错误类型可以分为三类:(i) 缺失正确计划;(ii) 决策错误;(iii) 虚假否定。其中,缺失正确计划占据了错误的主要部分,这表明尽管计划采样在某种程度上能够达到较高的GCRmax,但它仍然是模型性能的一个瓶颈。
针对这些问题,未来的改进方向包括:
1. 增强计划采样阶段的效率和准确性:可以通过增加计划重采样的设计来打破现有的性能上限,特别是在grounded deciding阶段,以确保能够从更广泛的正确计划中进行选择。
2. 提高决策阶段的准确性:实验中发现,大量错误是由于LLM在grounded deciding阶段的决策错误造成的。未来可以通过引入更先进的技术,如链式思考(chain-of-thought)和自我反思(self-reflection),来提高模型在这一阶段的表现。
3. 优化错误修正机制:虽然TREE-PLANNER在错误修正方面已经取得了显著进展,减少了重复决策和令牌消耗,但仍有改进空间。可以探索更灵活和高效的错误追踪和修正策略,以进一步提高模型的实用性和效率。
通过这些改进,我们希望能够进一步提升TREE-PLANNER的性能,使其在更广泛的应用场景中表现出更高的效率和更强的鲁棒性。
总结与展望
TREE-PLANNER作为一种新型的基于大型语言模型的任务规划框架,通过其创新的计划采样、动作树构建和基于环境的决策过程,有效地解决了传统迭代规划方法中的令牌效率低和错误修正冗余的问题。实验结果显示,TREE-PLANNER在虚拟家庭环境中的表现超越了现有的基线模型,无论是在任务成功率还是在令牌和错误修正效率上都有显著提高。
展望未来,TREE-PLANNER的研究可以在几个方向上进行深入:
-
扩展到更复杂的环境和任务:考虑将TREE-PLANNER应用于更多种类的环境和任务,特别是那些动态变化更加剧烈和不确定性更高的场景。
-
集成更先进的语言模型和决策技术:随着语言模型和人工智能决策技术的不断进步,集成最新的研究成果可能会进一步提升TREE-PLANNER的性能和适应性。
-
优化模型的可解释性和用户交互:提高模型的可解释性,使用户能够更好地理解模型的决策过程和修正策略,同时探索更自然和有效的用户交互方式。
通过这些研究和改进,TREE-PLANNER有望成为未来智能任务规划领域的一个重要工具,为自动化系统和机器人技术的发展提供强大的支持。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!