问题:
mmdetection在训练自己数据集时候 报错‘ValueError: need at least one array to concatenate’
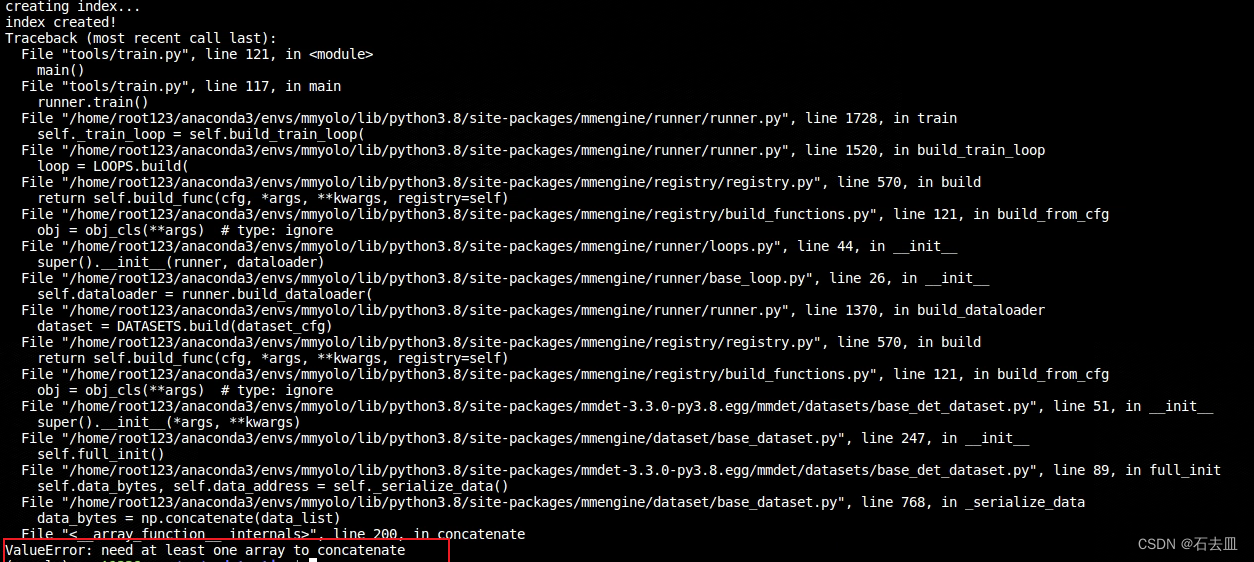
解决方法:
需要修改数据集加载的代码文件,数据集文件在路径configs/base/datasets/coco_detection.py里面,需要增加metainfo这个dict,另外在train_dataloader和val_dataloader这两个dict里面将metainfo传入,使用这个语句传入metainfo = metainfo。
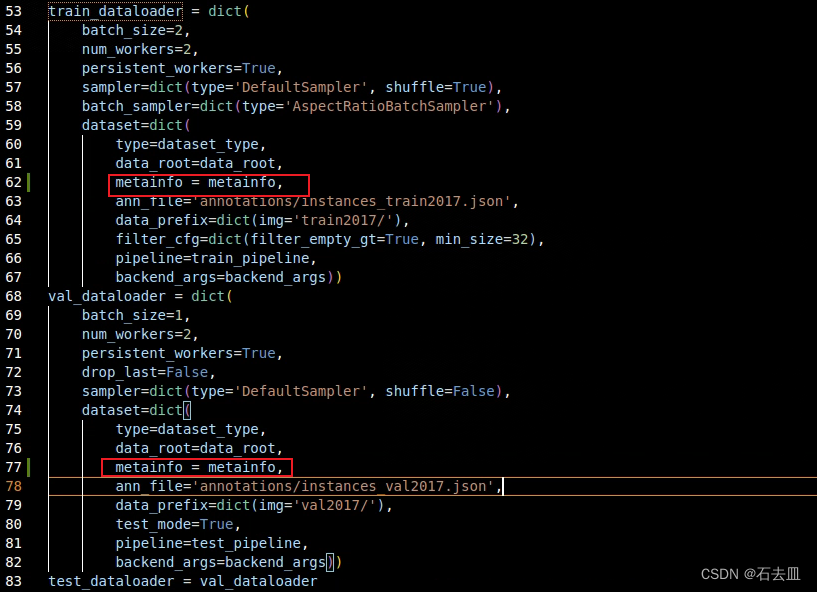
其中,metainfo这个dict里面classes是自己数据集的类别,palette是对应类别画图时候的颜色,随便设置即可。
代码举例:
# configs/_base_/datasets/coco_detection.py
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'path/mmdetection/datasets/coco2017/'
# Example to use different file client
# Method 1: simply set the data root and let the file I/O module
# automatically infer from prefix (not support LMDB and Memcache yet)
# data_root = 's3://openmmlab/datasets/detection/coco/'
metainfo = dict(
classes=('x', 'x1', 'x2', 'x3', 'x4'),
palette=[(220, 17, 58), (0, 143, 10), (0, 143, 10), (0, 143, 10), (0, 143, 10)] # 画图时候的颜色,随便设置即可
)
# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
# backend_args = dict(
# backend='petrel',
# path_mapping=dict({
# './data/': 's3://openmmlab/datasets/detection/',
# 'data/': 's3://openmmlab/datasets/detection/'
# }))
backend_args = None
train_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', prob=0.5),
dict(type='PackDetInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='Resize', scale=(1333, 800), keep_ratio=True),
# If you don't have a gt annotation, delete the pipeline
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=2,
num_workers=2,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=dict(type='AspectRatioBatchSampler'),
dataset=dict(
type=dataset_type,
data_root=data_root,
metainfo = metainfo,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=train_pipeline,
backend_args=backend_args))
val_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
metainfo = metainfo,
ann_file='annotations/instances_val2017.json',
data_prefix=dict(img='val2017/'),
test_mode=True,
pipeline=test_pipeline,
backend_args=backend_args))
test_dataloader = val_dataloader
val_evaluator = dict(
type='CocoMetric',
ann_file=data_root + 'annotations/instances_val2017.json',
metric='bbox',
format_only=False,
backend_args=backend_args)
test_evaluator = val_evaluator










![[华为OD]BFS C卷 200 智能驾驶](https://img-blog.csdnimg.cn/direct/7be53d007ae449998893958753283d72.png)