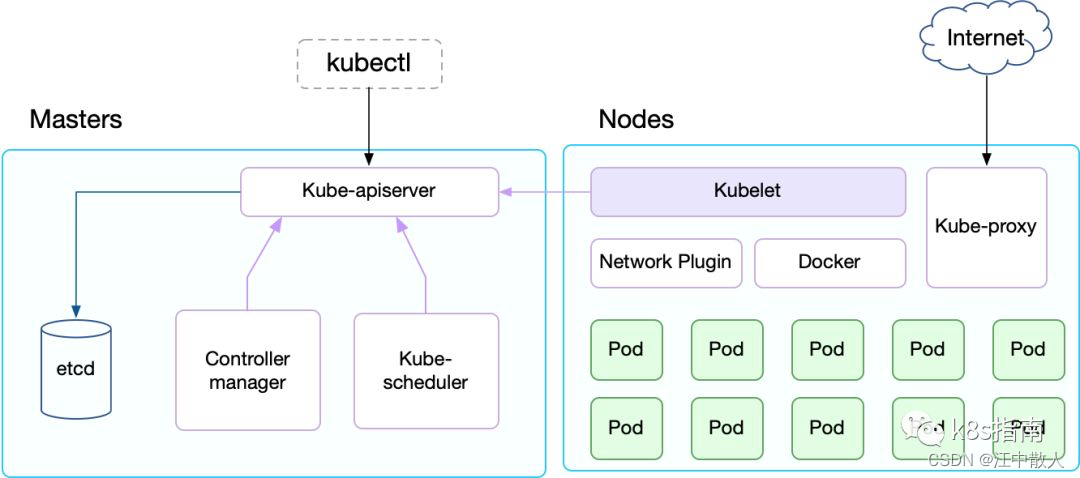
导语:从风格迁移到特征解耦、语言概念解耦,研究人员正通过数学和语言逐步改善GAN的功能。

作者 | 莓酊
编辑 | 青暮
首先想让大家猜一猜,这四张图中你觉得哪张是P过的?小编先留个悬念不公布答案,请继续往下看。
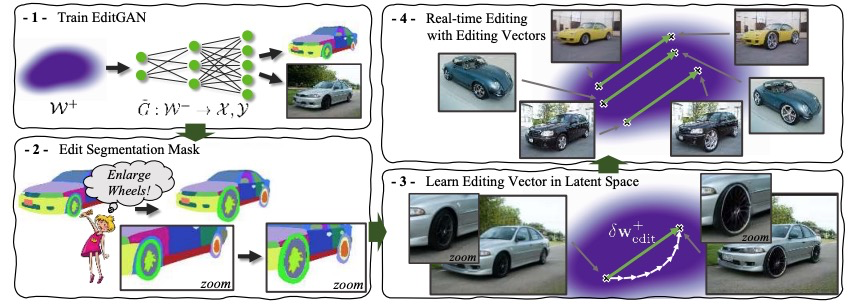
生成对抗网络(Generative Adversarial Network, GAN)是通过让两个神经网络对抗学习生成数据的方法。GAN从伊始到现在发展“壮大”,比如我们熟悉的PGGAN和StyleGAN,已经可以生成高质量、高分辨率的图片。最近英伟达、多伦多大学和麻省理工大学的研究者们为GAN“家族”又添一员—— EditGAN。

大多数基于 GAN 的图像编辑都需要在具有语义分割注释的大规模数据集上训练,并只提供极少的修改,或仅在不同图像之间进行插值。
而EditGAN作为一种高质量、高精度语义图像编辑的新模型,允许通过修改高精细度零件的分割掩码(Segmentation mask)来编辑图像。简而言之,EditGAN能自己P图,而且还P得特别好。就如上图所示,除了第一张是小哥原版的“邪魅笑容”,其余都是EditGAN的作品,请问你猜对了吗?
EditGAN是建立在GAN框架上,该框架是对图像及其语义分割 (DatasetGAN) 进行联合建模,只需要少量标记数据就能训练,进而成为可扩展的编辑工具。

使用 EditGAN 进行高精度语义图像编辑
在动图中可以更直观地观察到EditGAN的修图效果:

具体来说,就是将图像嵌入到GAN潜在空间中,并根据分割编辑执行潜在的代码优化从而高效地修改图像。为了摊销优化,研究人员在潜在空间中找到编辑向量,并允许任意数量的编辑向量以交互速率直接应用于其他图像。
以可爱猫猫的“张嘴编辑”为例:
横向第一排是图像和学习编辑向量的蒙版,编辑前后的对比及原图的分割掩码和手动修改后的目标分割掩码。第二排是EditGAN将学习提炼到的编辑应用于新图像的前后对比。

实验证明,EditGAN 可以用前所未有的细节自由度操作图像,同时保持高质量的完整度。而且还可以轻松组合多个编辑,在 EditGAN 的训练数据之外执行合理的图像修改。
目前只有EditGAN可以达到这样的效果!大多数基于GAN 的图像编辑方法,有的依赖于GAN对类标签或像素级语义分割注释的调节,其他则需要辅助属性分类器指导合成编辑图像。而且训练它们必须背靠大型标记数据集,导致这些方法目前仅适用于大型注释数据集的图像类型。除此之外,即使注释可用,但由于注释只包含高级别全局属性或相对粗略的像素分割,大多数技术只提供有限编辑操作。
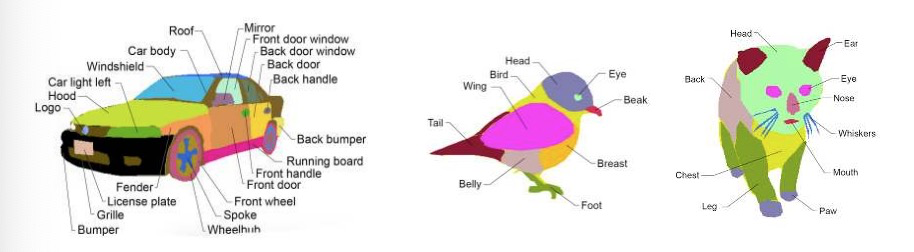
而EditGAN的“制胜法宝”就在于:高精度的分割掩码(Segmentation mask)。

详细的面部标记,连鱼尾纹、法令纹都有属于自己的语义模块,其实大可不必这么真实的。

汽车、鸟和猫的部分标记模版也是无比精细了。
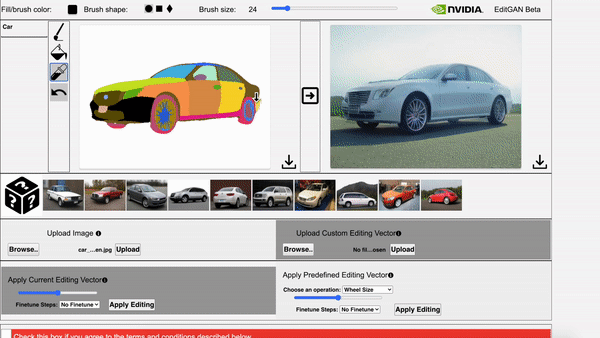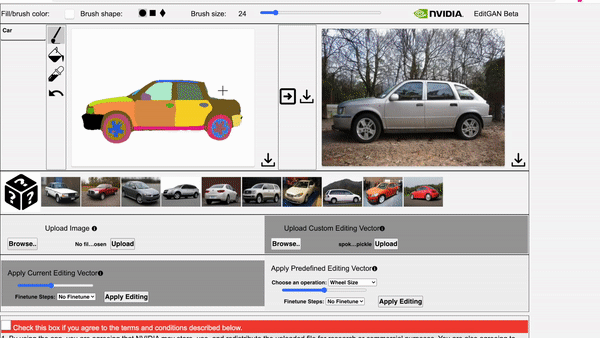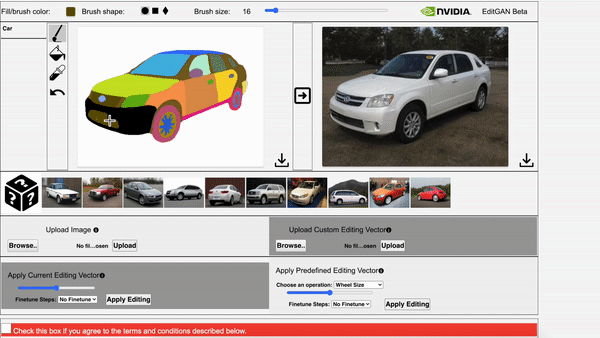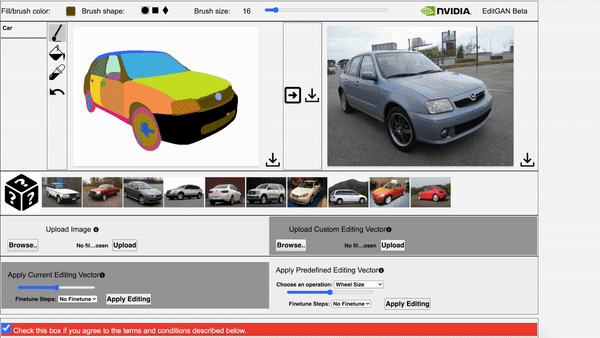
在EditGAN的交互式演示工具中,通过调整相应部位的分割掩码就修改图像。
还能同时应用多个编辑,并利用预定义的编辑向量生成新图像。
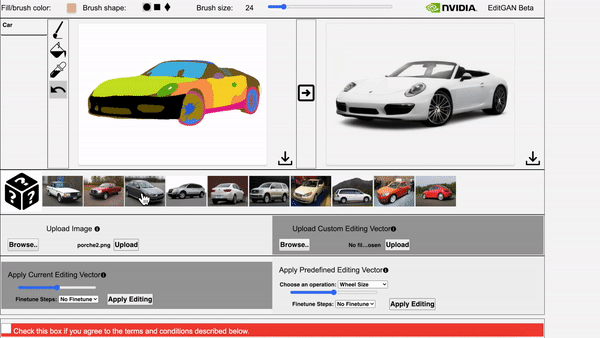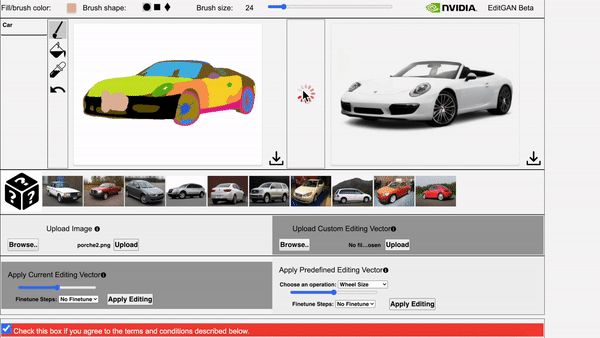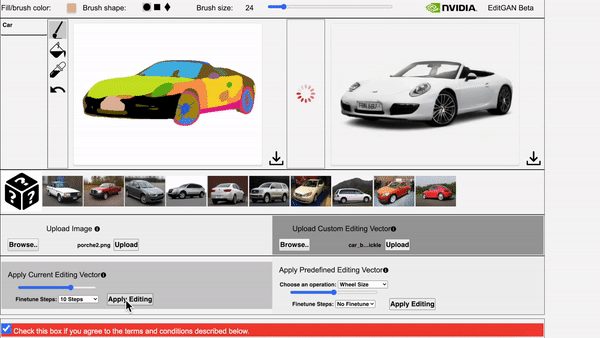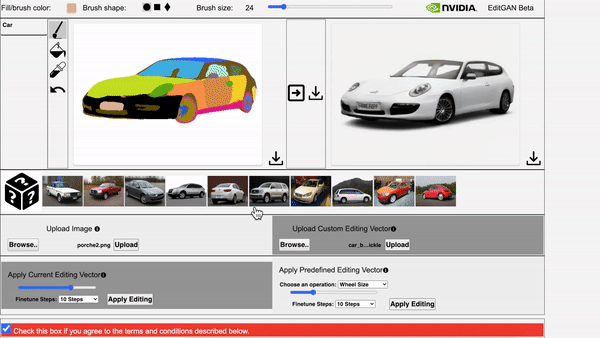
EditGAN在绘画作品上的泛化应用也很出色。

可以说,EditGAN是第一个GAN驱动的图像编辑框架,它能提供非常高精度的编辑,只需要很少带注释的训练数据(并且不依赖于外部分类器),运行实时交互,允许多个编辑的直接组合,并适用于真实嵌入、GAN生成图像,甚至是域外图像。
GAN框架下的编辑图像发展
计算机视觉(Computer Vision, 简称CV)领域取得了许多进展。2012年之前,人工设计(hand-designed)是计算机视觉的主要研究方法。2012年,深度神经网络(Deep Neural Network, DNN)在ImageNet的分类任务上发挥了巨大作用,热门研究如:自动驾驶,物体识别,对人体的理解等等。直到2014年,计算机科学家Ian Goodfellow发表生成对抗网络(GAN)的开创性论文,开启了深度学习的变革,取得了很多技术上的重大突破。虽然生成对抗网络原先是为了无监督学习提出的,它也被证明对半监督学习、完全监督学习、强化学习是有用的。在一个2016年的研讨会,杨立昆描述生成式对抗网络是“机器学习这二十年来最酷的想法”。
GAN包含了两个神经网络,生成器G(Generator)和鉴别器D(Discriminator),生成器的作用是生成图片,鉴别器则接收图片作为输入对象,随后对图像的真假进行辨别,输出1为真,输出0则为假。在博弈的过程中两者都在不断变强,即生成器产出的图像愈发“惟妙惟肖”,鉴别器也更加“火眼金睛”。训练效果达到峰值后,这时再把D直接拿来作为图片生成器。
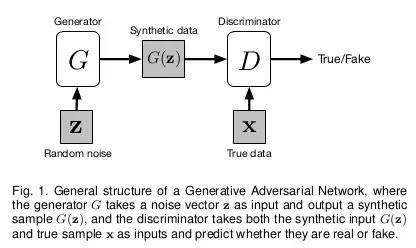
下面我们将从风格迁移、特征解耦和语言概念解耦三个方面,向大家展示GAN框架之下的视觉生成发展历程。
1
风格迁移
这一阶段的图像生成技术继承自CycleGAN、pix2pix等经典模型,属于条件生成,也就是基于确定的输入来得到输出,而不是像GAN那样通过随机采样生成,从而输出更加可控,或者得以实现对输入的风格化编辑。
在此基础上,人们按照“输入-输出”配对的套路开发出了各种不同的玩法,比如漫画真人化、风景动漫化、静物变“动物”、2D变3D等等。
“纸片人”变“真人”
YouTube博主AIみかん通过机器学习生成灌篮高手里各角色的真人版,80后90后泪目直呼“爷青回”。他使用的正是由艺术家Joel Simon在2018年创建的Artbreeder。Artbreeder是基于StyleGAN和bigGAN的在线图像生成网站(曾被GANBreeder),人们使用它已经创造了超过5400万张图像。除了可将漫画人物转化为真人,还有肖像,风景,建筑等图片生成模式,网址:https://artbreeder.com/browse。



现实变“漫画风”
由清华大学,卡迪夫大学的研究人员提出的CartoonGAN,作者们设计了一个GAN网络框架,用非成对图像训练GAN模型,能够使用漫画风格直接重现现实世界的场景。

论文链接:https://openaccess.thecvf.com/content_cvpr_2018/papers/Chen_CartoonGAN_Generative_Adversarial_CVPR_2018_paper.pdf
研究人员提出了损失函数,在生成器里VGG网络中引入高阶特征映射稀疏正则化以保证现实照片和生成漫画之间风格差。在鉴别器里提出推进边缘的对抗损失,以确保生成边缘清晰的图片。CartoonGAN有四种训练好的模型:宫崎骏风、细田守风、今敏风和新海诚风。

“静物”变“动态”
2020年大谷老师使用四个AI模型“复活”了兵马俑。分别是基于StyleGan2的Artbreeder、First-order-model、DAIN、Topaz Labs,都是训练好的模型。
在整个修复过程中,每张图都要按照顺序用这4个AI模型进行处理。其中,Artbreeder把角色从绘画转成写实风格,First-order-model生成人物动态,DAIN进行补帧(60fps),最后用Topaz Labs提升分辨率,使用的显卡是Nvidia 2080Ti。

大谷老师其他“神笔马良”作品。
“2D”变“3D”
上海交通大学和华为公司联合提出基于GAN的感知生成器CIPS- 3D,使用单视角图片,无需采集样本,就能生成视觉立体图像。CIPS- 3D在浅层使用的是主负责把人像从2D变3D的NeRF(Neural Radiance Fields,隐式神经表达法),在深层网络设置为能让合成图像保真的INR(Implicit Neural Representations,神经辐射场)。为解决镜像对称问题,研究人员在神经网络中添加了一个鉴别器,用以辅助甄别镜像问题。

论文地址:https://arxiv.org/pdf/2110.09788.pdf
不支持在 Docs 外粘贴 block
当然,这种图像生成或编辑模式比较单一,通常一个模型只能实现一个功能。
人们开始思考,是否可以实现一个模型、多种PS?当然可以,秘密藏在向量空间的特征解耦中。
2
特征解耦
特征解耦就是,在神经网络的输入层和输出层之间的编码层,也就是向量空间中,将图像的不同特征分解开来,从而改变一个特征的时候,不会影响另一个特征。这正是实现一个模型、多种PS的必要条件。
比如由加州大学伯克利分校提出的InfoGAN。InfoGAN可以在向量空间控制生成图像的不同变量,并且不会互相干扰,比如MNIST数据集中的数字类型、旋转角度,以及人脸生成中的五官控制等等。

论文链接:https://arxiv.org/pdf/1606.03657.pdf
在标准的GAN中,生成数据的来源一般是一段连续单一的噪声z,这会导致Generator会将z高度耦合处理,z将不可解释。作者对GAN的目标函数进行改进,让网络学习拥有可解释的特征表示。
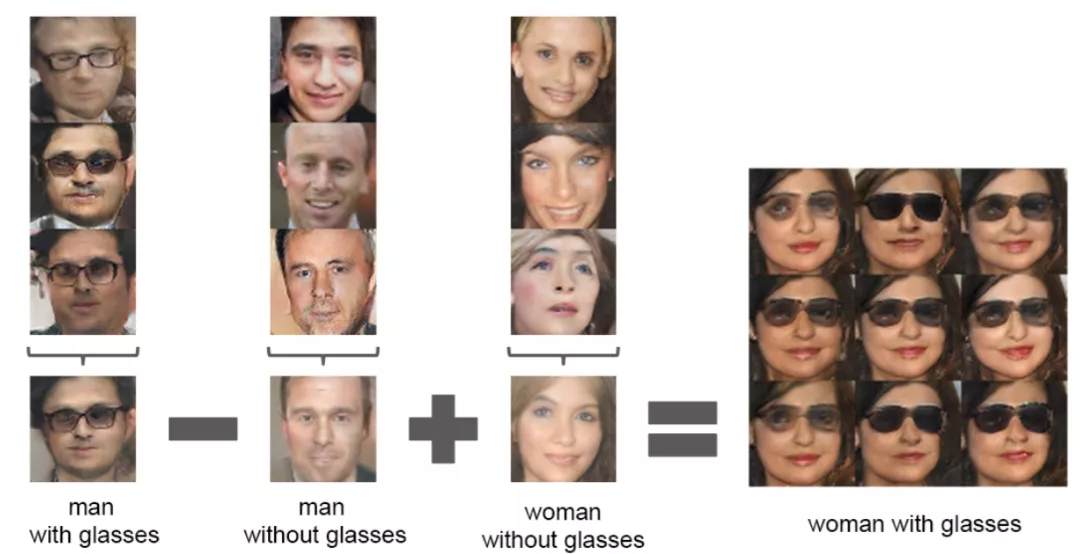
在InfoGAN中,模型的输入就被分成了两部分:
(1)不可压缩的 z,该部分不存在可以被显式理解的语义信息。
(2)可解释的隐变量 c,该部分包含我们关心的语义特征(如 MNIST 数据集中数字的倾斜程度、笔画的粗细),与生成的数据之间具有高相关性(即二者之间的互信息越大越好)。
对于可解释的部分,另一篇论文在特征空间层面给出了更加具体的解释。
香港中文大学助理教授周博磊在CVPR2020提出了一个叫InterFaceGAN的方法,这个方法就是为了在隐空间跟最后输出图片的语义空间建立联系。这个方法本身非常简单,但是很有效。

具体步骤是,训练好了生成模型过后,就得到了一个隐空间。然后可以从隐空间里面进行采样,把这些采样出来的向量放到生成器之中,进行图片生成,后面可以再接一个现有的分类器,给生成的图片打上一个具体的语义标签(比如性别标签)。
这样就可以把预测出来的标签当做隐空间向量的真实标签,从而进一步再回到隐空间,把预测的标签当成真实标签,然后训练一个分类器,对隐空间向量进行分类。
研究发现,在隐空间里面,GAN其实已经把隐空间的向量变得非常解耦。只需要用一个线性分类器,就可以在隐空间里实现90%左右的二分分类准确率。
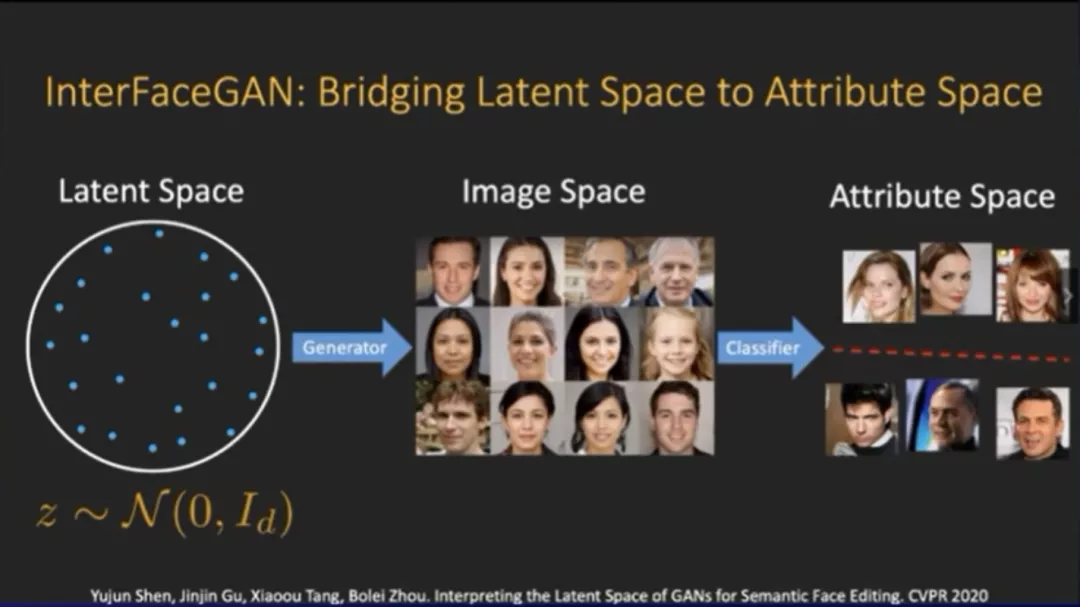
在训练了一个线性分类器后可在隐空间里得到了一个子空间,这个子空间就对应了生成图片的性别。
当然,要实现这种有明确语义的编辑方式,除了依靠数学的力量,也可以借助语言的魔法。比如,OpenAI在2021年初提出的DALL·E就通过直接的文本-图像映射,实现了视觉效果惊艳,同时语义对应上接近填空的控制力。
比如输入“竖琴状的蜗牛”,AI可以生成这样的图像:

要知道,这些图像在训练集中是不存在的,不得不令人怀疑AI获得了人类般的概念组合能力,也就是基于语言思维的概念解耦能力。
3
语言概念解耦
StyleCLIP进一步将这个能力精细化,当然这个模型也比DALL·E好实现多了。
由自希伯来大学、特拉维夫大学、Adobe 等机构的学者们提出了名为StyleCLIP模型,它可以只“听”文字指令就能“画”出你想要的图片。
StyleCLIP是StyleGAN 和 CLIP 两种模型的“进化体”。它既保留了预训练 StyleGAN 生成器的生成能力,也拥有CLIP 的视觉语言能力。

论文地址:https://arxiv.org/pdf/2103.17249.pdf
论文中有3种结合StyleGAN和CLIP的方法:
Optimizer:以文本为指导的latent优化,其中 CLIP 模型被用作损失网络。
Mapper:训练一个特定文本提示的latent残差映射器,使潜在向量与特定文本一一对应。
Global dir:一种在StyleGAN的style space中将文本描述映射到输入图像的全局方向(global direction),提供了对操作强度和解耦的控制。

4
尾声
从风格迁移到特征解耦、语言概念解耦,研究者们正通过数学和语言逐步改善GAN的功能,无论是从基本能力上,还是从功能精细化上,我们也在这个过程中不断增进对GAN的理解。当然,这两个方向并无优劣之分,未来皆可期。
链接:
https://arxiv.org/pdf/2111.03186.pdf
https://mp.weixin.qq.com/s/h5gZCKRGZlG03DZL-2FWIw
https://tandon-a.github.io/Image-Editing-using-GAN/
https://mp.weixin.qq.com/s?__biz=MzA5ODEzMjIyMA==&mid=2247571522&idx=1&sn=380ab14b7cf34783fd412e60713b6b48&chksm=9095d1d1a7e258c79fbfda93ac25b66f651af60b77e28c4c17855aecfc1979471a03205e1e55&token=1979387772&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=MzA5ODEzMjIyMA==&mid=2247629931&idx=1&sn=3ee515e9f3e618c4cd05bb5841a96ecc&chksm=909af5f8a7ed7ceebfcc48fd9e38140412b6244de846b6bd11e800f3f65b0985dfa4f674c927&token=1979387772&lang=zh_CN#rd
https://arxiv.org/pdf/2103.17249.pdf






![[idekCTF 2023] Malbolge I Gluttony,Typop,Cleithrophobia,Megalophobia](https://img-blog.csdnimg.cn/img_convert/075d78485bd91437286c0636c2fd0896.png)