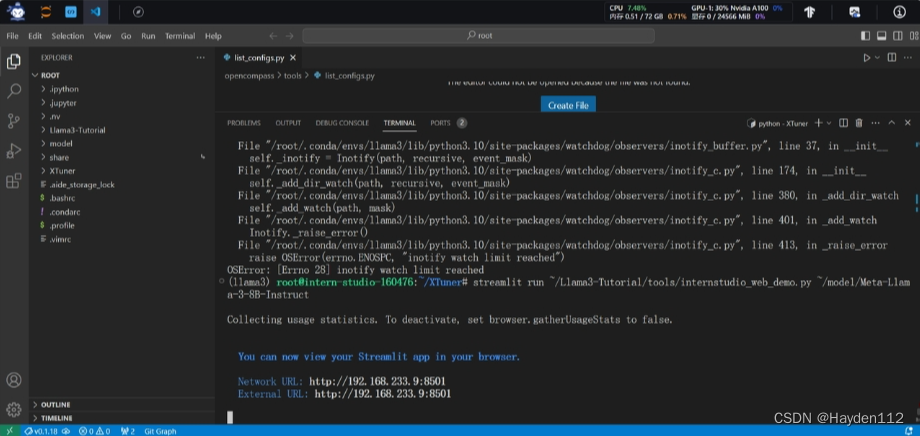
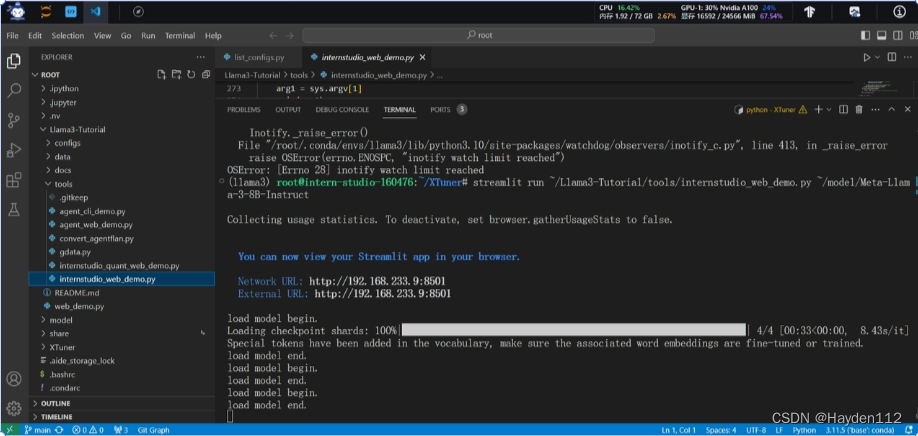
第1节—Llama 3 本地 Web Demo 部署
![[图片]](https://img-blog.csdnimg.cn/direct/d455bdba6bef445982df65f2b6980ba6.png)
![[图片]](https://img-blog.csdnimg.cn/direct/87153968627b499da28b519ecec88582.png)
端口转发
vscode里面设置端口转发
https://a-aide-20240416-b4c2755-160476.intern-ai.org.cn/proxy/8501/
![[图片]](https://img-blog.csdnimg.cn/direct/b826e01dca354b37b655e0934e223b99.png)
ssh -CNg -L 8501:127.0.0.1:8501 root@ssh.intern-ai.org.cn -p 43681
参考
- https://github.com/SmartFlowAI/Llama3-Tutorial/blob/main/docs/hello_world.md
第2节–Llama 3 微调个人小助手认知(XTuner 版)
![[图片]](https://img-blog.csdnimg.cn/direct/6b863a650daa4b82bba2be4289984f93.png)
![[图片]](https://img-blog.csdnimg.cn/direct/c361395340f44b92a79fa2c1082c2e1d.png)
![[图片]](https://img-blog.csdnimg.cn/direct/3347b523205b4fd0bf2ee5a6fe1220c6.png)
参考
- https://github.com/SmartFlowAI/Llama3-Tutorial/blob/main/docs/assistant.md
第3节–Llama 3 图片理解能力微调(XTuner+LLaVA 版)
第4节–Llama 3 高效部署实践(LMDeploy 版)
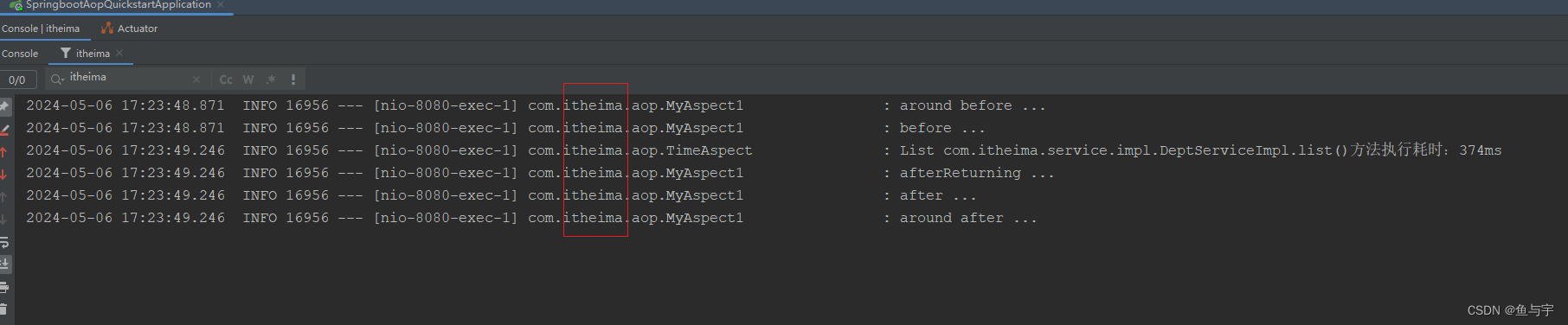
![[图片]](https://img-blog.csdnimg.cn/direct/5b088fd2a32044cc88fdcba0b65f344a.png)
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/
nvidia-smi
![[图片]](https://img-blog.csdnimg.cn/direct/d947944e53e6451698cdd4cd37ce9aa3.png)
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.5
有一点变化,变化不大,从39998MB到37366MB。
![[图片]](https://img-blog.csdnimg.cn/direct/7949ac6f90134dac84ab57fbabde82c7.png)
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.01
然后与模型对话,可以看到,此时显存占用仅为16213M,代价是会降低模型推理速度。
![[图片]](https://img-blog.csdnimg.cn/direct/62470a3774764f24a0cd1c59cdcd2c23.png)
Meta-Llama-3-8B-Instruct_4bit
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq --cache-max-entry-count 0.01
![[图片]](https://img-blog.csdnimg.cn/direct/9d1e2fc7142c455a9176050312d266e1.png)
lmdeploy serve api_server
lmdeploy serve api_server \
/root/model/Meta-Llama-3-8B-Instruct \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
端口转发
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 43681
![[图片]](https://img-blog.csdnimg.cn/direct/2dbf22b80ff942a2aee8bc5955e54ff5.png)
参考
- https://github.com/SmartFlowAI/Llama3-Tutorial/blob/main/docs/lmdeploy.md
第5节–Llama 3 Agent 能力体验与微调
第6节–Llama 3 能力评测(OpenCompass 版)
课程信息
【结课时间】
我们的结课时间已经延迟到5月12日,同样,我们的算力支持和共学计划的有效期也会延迟到5月12日
【结课福利】
- 可加入人均大佬的【Llama 3 结课大佬】群,并可参加书生·浦语(InternLM)的特别兴趣小组和后续活动
- 精美的结课证书(结课后 1 个月内可领取)
- 24 GB 算力的额外支持(有效期至5月12日)
【结课条件】
- 完成所有视频的观看
- 完成 Llama 3 Web Demo 部署
- 使用 XTuner 完成小助手认知微调
- 使用 LMDeploy 成功部署 Llama 3 模型
【结课福利领取方式】
通过下方“作业提交问卷”提交基础作业后,即可联系班级助教帮忙拉进【Llama 3 结课大佬】群,结课福利的相关信息会在结课群内通知
📰 作业提交问卷:https://aicarrier.feishu.cn/share/base/form/shrcnjQM61uIwVIZxkoGy6kc0Bh
📰 学习手册:学习手册
📰 课程文档:
https://github.com/SmartFlowAI/Llama3-Tutorial
📺 课程视频:
https://space.bilibili.com/3546636263360696/channel/series
【共学计划】
邀请 3 位同学即可获得 24GB 的算力,24 GB 足够完成所有基础作业了。详见:https://llama3.vansin.top/
【FQA】
- 出现算力点不足的学员,请来联系我补充
- 出现显存不足问题(out of memory),一般群聊天记录里会有解决方案(搜索:【oom问题】),或者通过共学计划提升算力支持