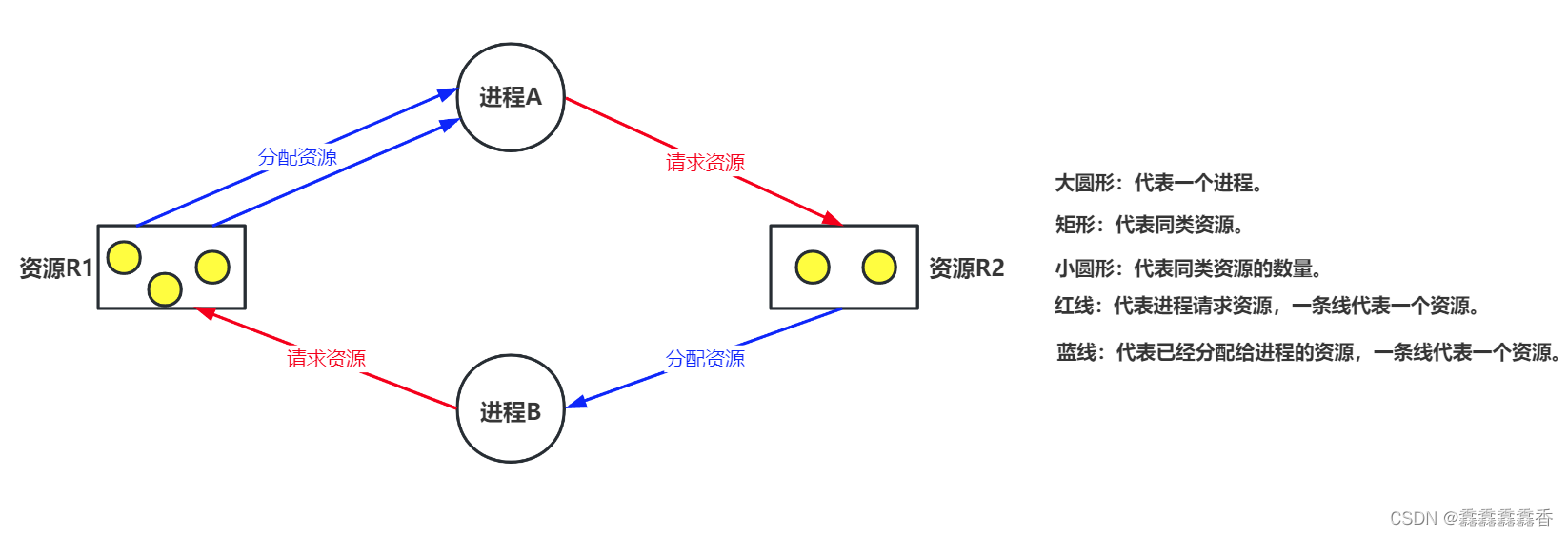
5.1 简介
借助HTTP协议所提供的功能以及命令行实用工具,我们可以用脚本满足大量的web自动化需求。
5.2 web页面下载
wget是一个用于文件下载的命令行工具,选项繁多且用法灵活。
下载单个文件或web页面

指定从多个URL处进行下载
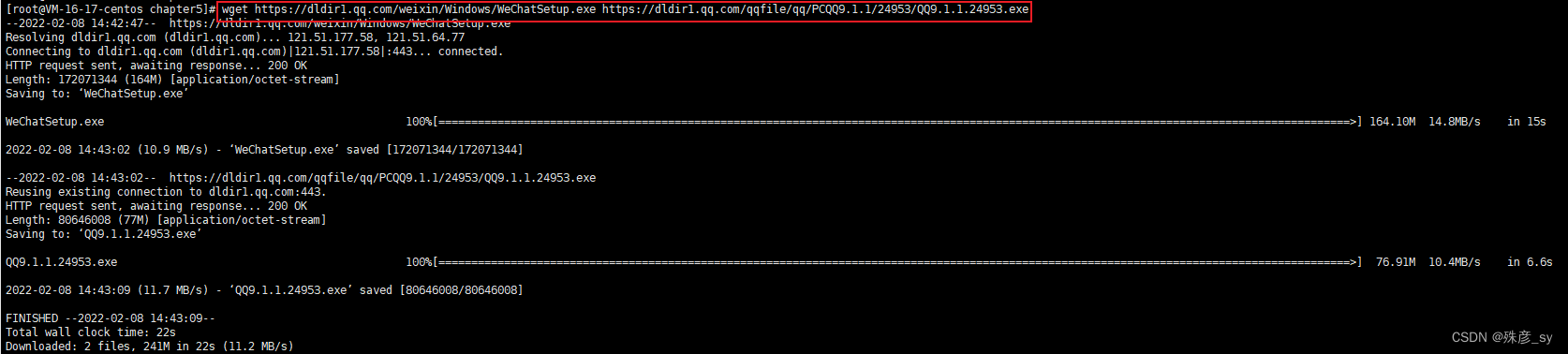
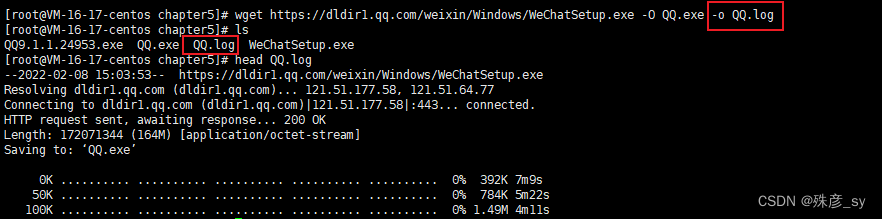
我们可以通过选项-O指定输出文件名。

也可以通过-o来指定一个日志文件,这样日志信息就不会被打印到stdout了。
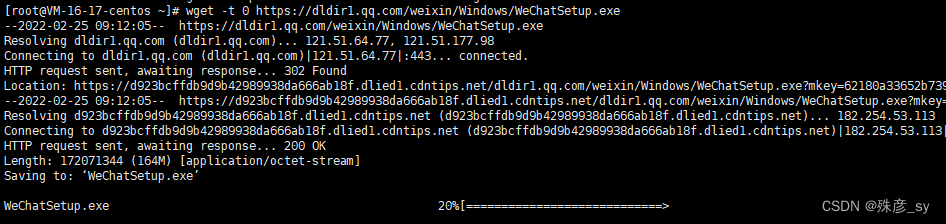
选项-t可以指定在放弃下载之前尝试多少次

选项--quota或-Q可以指定最大下载配额,对于存储空间有限的系统,限制下载量是有必要的。


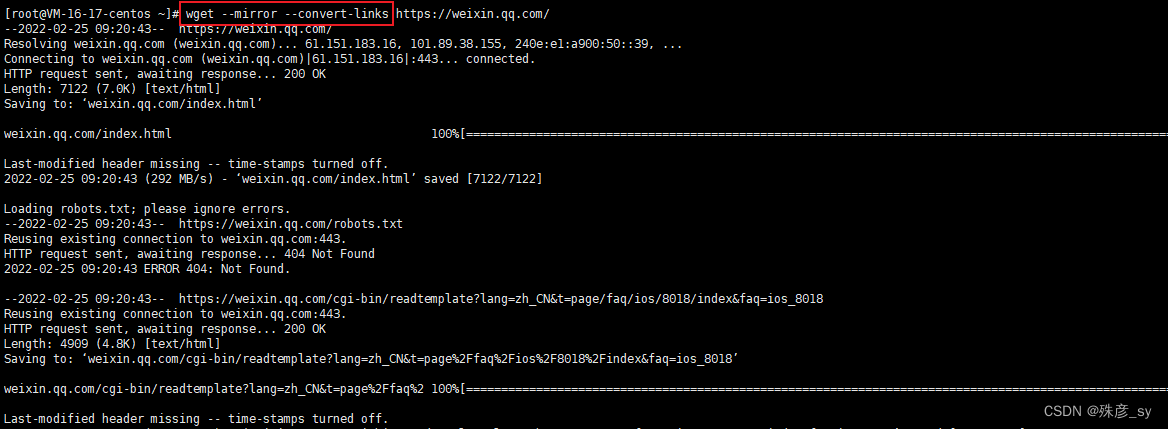
wget像爬虫一样以递归的方式遍历网页上所有的URL链接,并逐个下载。
![]()
5.3 以纯文本形式下载页面
Lynx是一款基于命令行的web浏览器,能够以纯文本形式下载web网页。
选项-dump能够以纯ASCII编码的形式下载web页面。
![]()
5.4 cURL入门
cURL默认会将下载文件输出到steout,将进度信息输出到stderr。如果不想显示进度信息,可以使用--silent。
选项-O指明将下载数据写入文件,采用从URL中解析出的文件名。

选项-o可以指定输出文件名

如果需要在下载过程中显示形如#的进度条,可以使用选项--progress

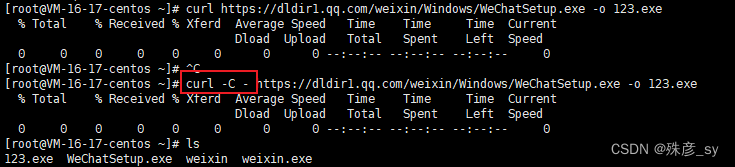
- 断点续传
cURL能够从特定的文件偏移处继续下载,偏移量是以字节为单位的整数。如果只是想断点续传,那么cURL不需要指定明确的字节偏移。
要是你希望cURL推断出正确的续传位置,请使用选项-C -。
- 用cURL设置参照页字符串
web开发人员可以根据条件做出判断:如果参照页是www.google.com,那么就返回一个google页面,否则返回其他页面
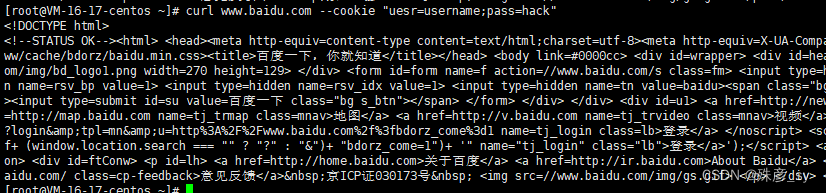
- 用cURL设置cookie
可以使用curl来指定并存储HTTP操作过程中使用到的cookie。cookie需要以name=value的形式来给出。多个cookie之间使用分号分隔。
选项--cookie-jar可以将cookie另存为文件
5.7 图片爬取器及下载工具

#!/bin/bash
#Filename: img_downloader.sh
if [ $# -ne 3 ];
then
echo "Usage: $0 URL -d DIRECTORY"
exit -1
fi
while [ $# -gt 0 ]
do
case $1 in
-d) shift; directory=$1; shift;;
*) url=$1; shift;;
esac
done
echo "URL: $url"
echo "DIR: $directory"
mkdir -p $directory;
baseurl=$(echo $url | egrep -o "https?://[a-z.\-]+")
echo Downloading $url
curl -s $url | egrep -o "<img src=[^>]*>" |
sed 's/<img src=\"\([^"]*\).*/\1/g' |
sed "s,^/,$baseurl/," > /tmp/$$.list
cd $directory;
while read filename;
do
echo Downloading $filename
curl -s -O "$filename" --silent
done < /tmp/$$.list