对一组数据的理解
数据摘要:通过以下方法:有损地提取数据特征的过程。
- 基本统计(含排序)
- 分布/累计统计
- 数据特征
- 相关性
- 周期性等
- 数据分析
Pandas库的数据排序
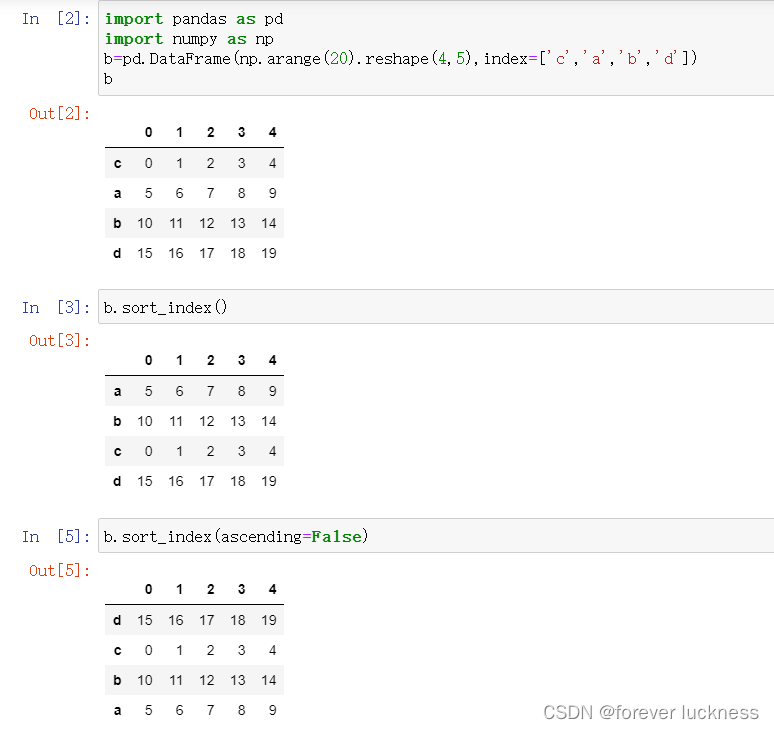
- .sort_index(axis=0,asccending=True)。
- .sort_index()方法在指定轴上根据索引进行排序,默认升序。
- 对索引的操作就是对数据的操作。
import pandas as pd
import numpy as np
b=pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','b','d'])
b
b.sort_index()
b.sort_index(axis=0,ascending=False)##默认情况下是对0轴进行排序,二维就是行索引
c=b.sort_index(axis=1,ascending=False)##对列的索引按照降序排列
c

c=b.sort_index(axis=1,ascending=False)##对列所在索引进行降序排列
c

c=c.sort_index()
c

import pandas as pd
import numpy as np
b=pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','b','d'])
b
c=b.sort_values(2,ascending=False)##按照第2列索引的数据大小按照降序进行排序
c
c=c.sort_values('a',axis=1,asccending='False')##对c按照a行的戴奥按照降序排列
c

Pandas的基本统计分析函数
适用于Series和DataFrame类型
| 方法 | 说明 |
|---|---|
| .sum() | 计算数据的总和,按0轴计算,下同 |
| .count() | 非Na值的数量 |
| .mean()/.median() | 计算数据的算术平均值/算术中位数 |
| .var()/.std() | 计算数据的方差、标准差 |
| .min()/.max() | 计算数据的最小值和最大值 |
只适用于Series类型
| 方法 | 说明 |
|---|---|
| .argmin() /.argmax() | 计算数据最大值、最小值所在位置的索引位置(自动索引) |
| .idxmin()/idxmax() | 计算数据最大值、最小值所在位置的索引(自定义索引) |
基本的统计分析函数
适用于Series和DataFrame类型
| 方法 | 说明 |
|---|---|
| .describe() | 针对0轴(各列)的统计汇总 |
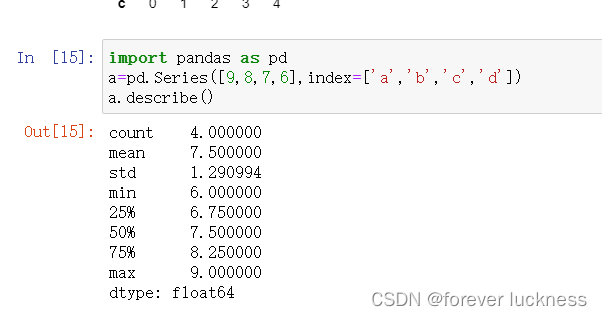
import pandas asss pd
a=pd.Series([9,8,7,6],index-['a','b','c','d'])
a.describe()
import pandas as pd
import numpy as np
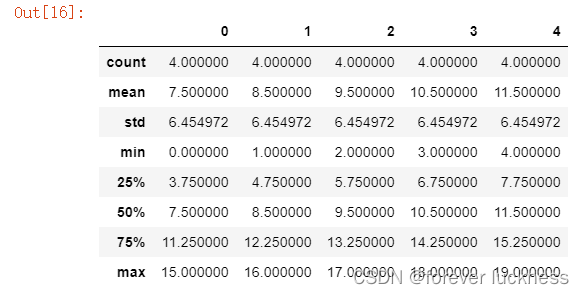
b=pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','b','d'])
b.describe()##获得b的基本统计信息
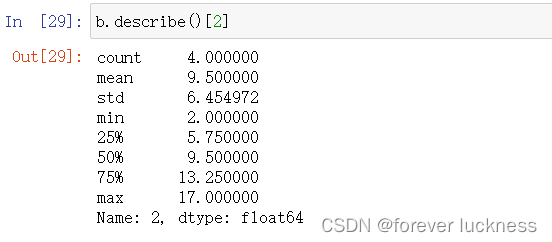
b.describe()[2]##获得基本统计信息中第二行的信息
数据的累计分析
累计统计分析函数
适用于Series和DataFrame类型
| 方法 | 说明 |
|---|---|
| .cumsum() | 依次给出前1、2、…、n个数的和 |
| .cumprod() | 依次给出前1、2、…、n个数的积 |
| .cummax() | 依次给出前1、2、…、n个数的最大值 |
| .cummin() | 依次给出前1、2、…、n个数的最小值 |
import pandas as pd
import numpy as np
b=pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','b','d'])
b

b.cumsum()##对前n个进行求和

b.cumprod()##对b的前n行求积

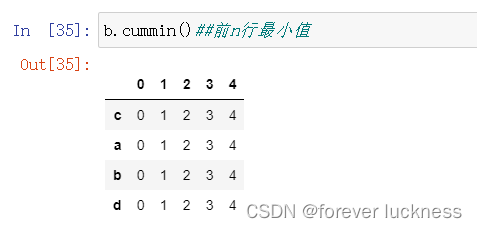
b.cummin()##前n行最小值
b.cummax()##前n行的最大值

滚动计算(窗口计算)
适用于Series和DataFrame类型,滚动计算(窗口计算)
| 方法 | 说明 |
|---|---|
| .rolling(w).sum() | 依次计算相邻w个元素的和 |
| .rolling(w).mean() | 依次计算相邻w个元素的算术平均值 |
| .rolling(w).var() | 依次计算相邻w个元素的方差 |
| .rolling(w).std() | 依次计算相邻w个元素的标准差 |
| .rolling(w).min/max() | 依次计算相邻w个元素的最小值和最大值 |
举例
import pandas as pd
import numpy as np
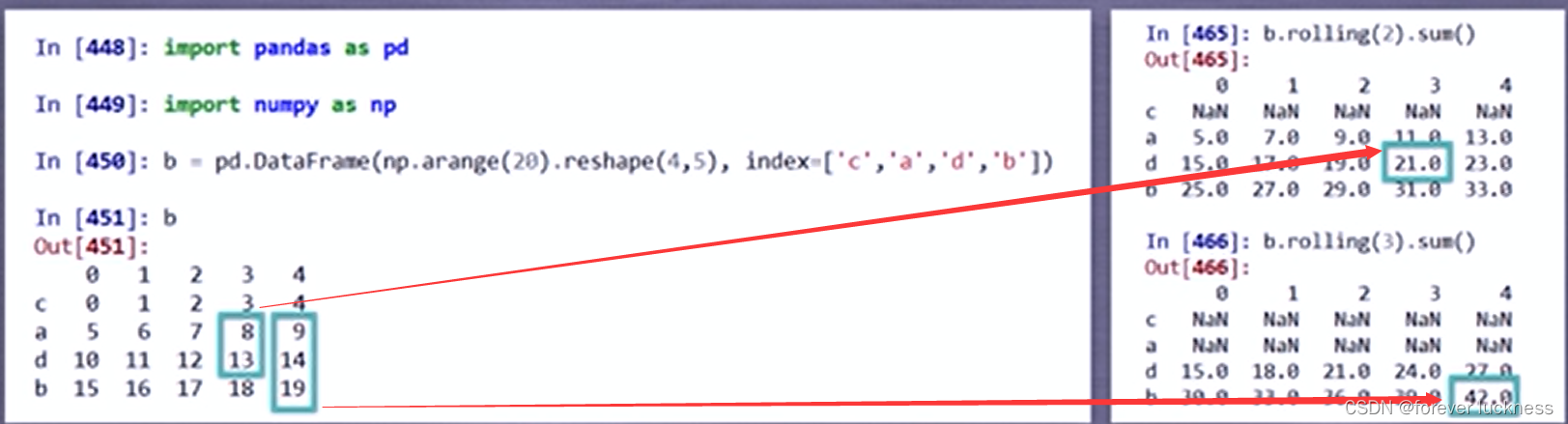
b=pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','b','d'])
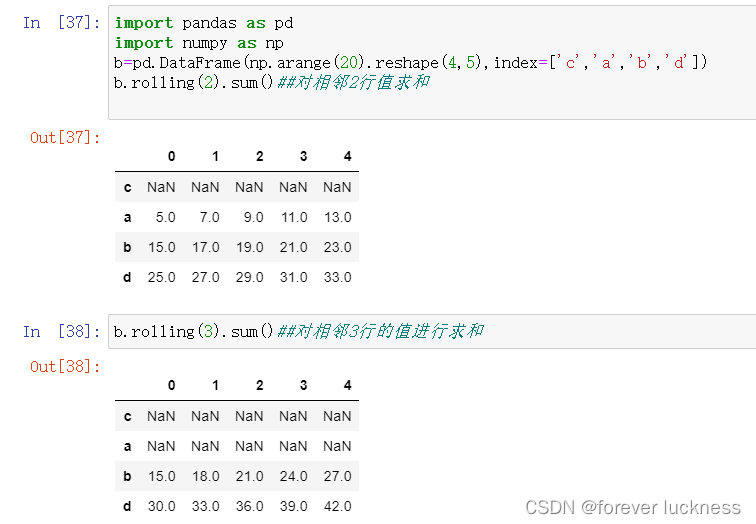
b.rolling(2).sum()##对相邻2行值求和
b.rolling(3).sum()##对相邻3行的值进行求和
相关性分析
两个事物,表示为X和Y,如何判断他们之间的存在相关性?
相关性
-
正相关,X增大,Y增大,连个变量正相关。
-
负相关,X增大,Y减小,两个变量负相关。
-
不相关,X增大,Y无视,两个变量不相关。
如何判断两个数据是否具有相关性呢?
协方差
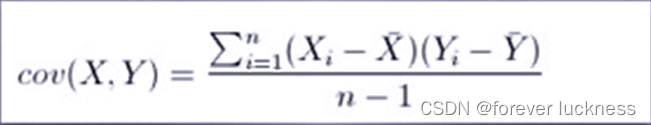
-
协方差>0,X和Y正相关。
-
协方差<0,X和Y负相关。
-
协方差=0,X和Y独立无关。
Pearson相关系数

其中r的范围在[-1,1]范围间,r的绝对值 -
0.8-1.0极强相关
-
0.6-0.8强相关
-
0.4-0.6中等程度相关
-
0.2-0.4弱相关
-
0.0-0.2极弱相关或无关
相关分析函数
适用于Series和DataFrame类型
| 方法 | 说明 |
|---|---|
| .cov() | 计算协方差矩阵 |
| .corr() | 计算线管系数矩阵,Pearson,Spearman,Kendall等系数 |

Pandas数据单元小结:
一组数据的摘要:
排序:.sort();.sort_values()
基本统计函数:.describe()
累计统计函数:.cum*();.rolling().*()
相关性分析函数:.corr();.cov()