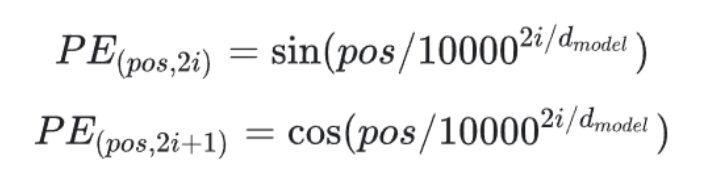前言
本次博客将要实现一下栈和队列,好吧
他们两个既可以使用动态数组也可以使用链表来实现
本次会有详细的讲解
栈的实现
栈的基础知识
什么是栈呢?
栈的性质是后进先出
来画个图来理解

当然可不可以出一个进一个呢,当然可以了
比如先进1 2 3再出一个
还剩下 1 2 再进一个5
最后出完所有元素
那么出的元素为 3 5 2 1
但是进入的顺序为1 2 3 5
所以先进后出也是相对而言的
我们上面的图只是让大家理解后入先出的概念
ok接下来我们开始来选择用什么结构来实现栈
分析
数组实现
很明显我们知道,栈是后入先出,所以它是需要进行尾插尾删的
而数组的尾插尾删,只需要将大小也就是size++或者-- 就可以实现,
在取栈顶的数据时也可以直接调用,取栈底时也可以直接调用
链表实现
当然链表也可以实现,但是普通的链表需要找尾,才可以尾插
我们可以多用一个指针来指向这个尾,这样可以解决问题
但是尾删怎么办?
如果要尾删,我们还是要再加一个指针指向这个尾的前一个才好尾删呀
然后取栈底栈顶可以通过头结点以及尾来找到
这样也可以实现,但是很麻烦
所以这个普通的单链表是不好实现链表的
但我们就是要搞事情
解决方法一
使用双向链表,这个就不多说了,多加个尾,尾插尾删,很简单
解决方法二
反过来看链表
看图吧

是不是实现的方法有很多种
我们这次要干大的,把这三种都敲一敲,当然在敲的过程中一定要注意细节
本次博客还会把细节交代清楚
1数组实现栈
我们先来看看头文件吧
#pragma once
#include<stdlib.h>
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>
//这里是动态数组的定义
typedef int DataType;
typedef struct Stack {
DataType* a;
int top;
int capacity;
}ST;
//初始化栈
void InitStack(ST* st);
//取栈顶
DataType TopStack(ST* st);
//入栈
void PushStack(ST* st, DataType x);
//出栈
void PopStack(ST* st);
//取栈的大小
int SizeStack(ST* st);
//取栈底
DataType BottomStack(ST* st);
//销毁栈
void DestroyStack(ST* st);
//栈的判空
bool EmptyStack(ST* st);细节1
注意我们这里定义了一个int top;
栈顶 在这里其实可以有两种写法,1 top初始值为0 2 top初始值为-1
第一种是top指向栈顶元素的下一个 第二种为top指向栈顶元素
其实就是因为数组的元素是以0开始的
这两种不同的写法,会导致后序的函数实现有一些差别
比如取栈的大小时,第一种是 返回top的值 第二种是返回top+1
本次博客使用第一种
细节2
在动态开辟数组时还有一个问题
就是一开始要不要给容量的问题,如果不给容量的话
在push操作中就会多一个判断,给容量的话一开始在Init(初始化)就要开辟空间
这也是细节之一这两种写法也有所不同 ,本次博客使用一开始不给容量
另外还有注意在满容量时的扩容,是扩二倍还是扩定量
搞清楚这几个细节就可以敲代码了
我们直接看吧
#include"stack.h"
void InitStack(ST* st)
{
assert(st);
st->a = NULL;
st->capacity = 0;
st->top = 0;
}
DataType TopStack(ST* st)
{
assert(st);
assert(st->top > 0);
return st->a[st->top - 1];
}
void PushStack(ST* st, DataType x)
{
assert(st);
if (st->a == NULL)
{
st->a=(DataType*)malloc(sizeof(DataType)*4);
st->capacity = 4;
st->a[st->top++] = x;
}
else
{
if (st->capacity == st->top)
{
DataType* temp = (DataType*)realloc(st->a, sizeof(DataType) * 2 * st->capacity);
if (temp != NULL)
{
st->a =temp;
st->capacity *= 2;
}
}
st->a[st->top++] = x;
}
}
void PopStack(ST* st)
{
assert(st);
assert(st->top > 0);
st->top--;
}
int SizeStack(ST* st)
{
return st->top;
}
DataType BottomStack(ST* st)
{
assert(st);
assert(st->top > 0);
return st->a[0];
}
void DestroyStack(ST* st)
{
free(st->a);
st->a = NULL;
st->capacity = 0;
st->top = 0;
}
bool EmptyStack(ST* st)
{
return st->top == 0;
}测试的话,大家自行去看,反正我是已经测试过了
2单链表实现栈
当然先看头文件
再来说说细节之处
#pragma once
#include<stdlib.h>
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>
typedef struct Stack2_ {
struct Stack2* next;
DataType value;
}ST2_;
typedef struct Stack2 {
ST2_* top;
ST2_* bottom;
int size;
}ST2;
//初始化
void InitStack2(ST2* st);
//栈顶
DataType TopStack2(ST2* st);
//入栈
void PushStack2(ST2* st, DataType x);
//出栈
void PopStack2(ST2* st);
//返回栈的大小
int SizeStack2(ST2* st);
//栈底
DataType BottomStack2(ST2* st);
//销毁栈
void DestroyStack2(ST2* st);
//判空
bool EmptyStack2(ST2* st);细节1
我们是使用了嵌套结构体避免了空间的浪费
比如如果使用一个结构体
那么每一个结构体都要有栈底,栈底,大小,还有下一个成员指针next,以及值value
而且对于不带头的单链表来说必须使用二级指针,很麻烦
这里是一定不能带头的
如果带头结点的话,那么我们有怎么头插呢,是不是,所以这里可是可以不写两个
结构体,但是要使用二级指针,来搞定第一个结点的情况
而且,它本质上浪费了空间
OK看看.c文件
void InitStack2(ST2* st)
{
assert(st);
st->top = st->bottom = NULL;
st->size = 0;
}
DataType TopStack2(ST2* st)
{
assert(st->top);
return st->top->value;
}
void PushStack2(ST2* st, DataType x)
{
assert(st);
ST2_* temp = (ST2_*)malloc(sizeof(ST2_));
if (temp == NULL)
return;
temp->value = x;
if (st->top == NULL)
{
st->bottom = st->top = temp;
temp->next = NULL;
}
else
{
temp->next = st->top;
st->top = temp;
}
st->size++;
}
void PopStack2(ST2* st)
{
assert(st);
assert(st->top);
if (st->bottom == st->top)
{
free(st->top);
st->bottom = st->top = NULL;
}
else
{
ST2_ *temp = st->top->next;
free(st->top);
st->top = temp;
}
st->size--;
}
int SizeStack2(ST2* st)
{
return st->size;
}
DataType BottomStack2(ST2* st)
{
assert(st->top);
return st->bottom->value;
}
void DestroyStack2(ST2* st)
{
assert(st);
while (!EmptyStack2(st))
{
PopStack2(st);
}
st->size = 0;
}
bool EmptyStack2(ST2* st)
{
return st->size == 0;
}再来看看下一个,真挺累的,哈哈哈哈
3双链表实现栈
其实原理是一样的,但是这个结构会使操作更加简单
这个就直接看代码就好
void InitStack3(ST3* st);
DataType TopStack3(ST3* st);
void PushStack3(ST3* st, DataType x);
void PopStack3(ST3* st);
int SizeStack3(ST3* st);
DataType BottomStack3(ST3* st);
void DestroyStack3(ST3* st);
bool EmptyStack3(ST3* st);
void InitStack3(ST3* st)
{
st->size = 0;
st->bottom = NULL;
}
DataType TopStack3(ST3* st)
{
assert(st);
assert(st->bottom);
return st->bottom->prev->value;
}
void PushStack3(ST3* st, DataType x)
{
assert(st);
ST3_* temp = (ST3_*)malloc(sizeof(ST3_));
temp->value = x;
if (st->bottom == NULL)
{
st->bottom = temp;
temp->prev = temp;
temp->next = temp;
}
else
{
ST3_* tem = st->bottom->prev;
tem->next = temp;
temp->next = st->bottom;
temp->prev = tem;
st->bottom->prev = temp;
}
st->size++;
}
void PopStack3(ST3* st)
{
assert(st);
assert(st->bottom);
//st->bottom->next == st->bottom->prev
//只有两个节点时也会有上式成立
//下面是解决方法
//st->bottom==st->bottom->next
//SizeStack3(st)==1
if (SizeStack3(st) == 1)
{
free(st->bottom);
st->bottom = NULL;
}
else
{
ST3_* tem = st->bottom->prev;
st->bottom->prev = tem->prev;
tem->prev->next = st->bottom;
free(tem);
}
st->size--;
}
int SizeStack3(ST3* st)
{
return st->size;
}
DataType BottomStack3(ST3* st)
{
assert(st);
assert(st->bottom);
return st->bottom->value;
}
void DestroyStack3(ST3* st)
{
while (!EmptyStack3(st))
{
PopStack3(st);
}
st->size = 0;
}
bool EmptyStack3(ST3* st)
{
assert(st);
return st->size == 0;
}哎呀,写的过程还是有些小问题,但都是小问题
OK,下面来看看队列
队列的实现
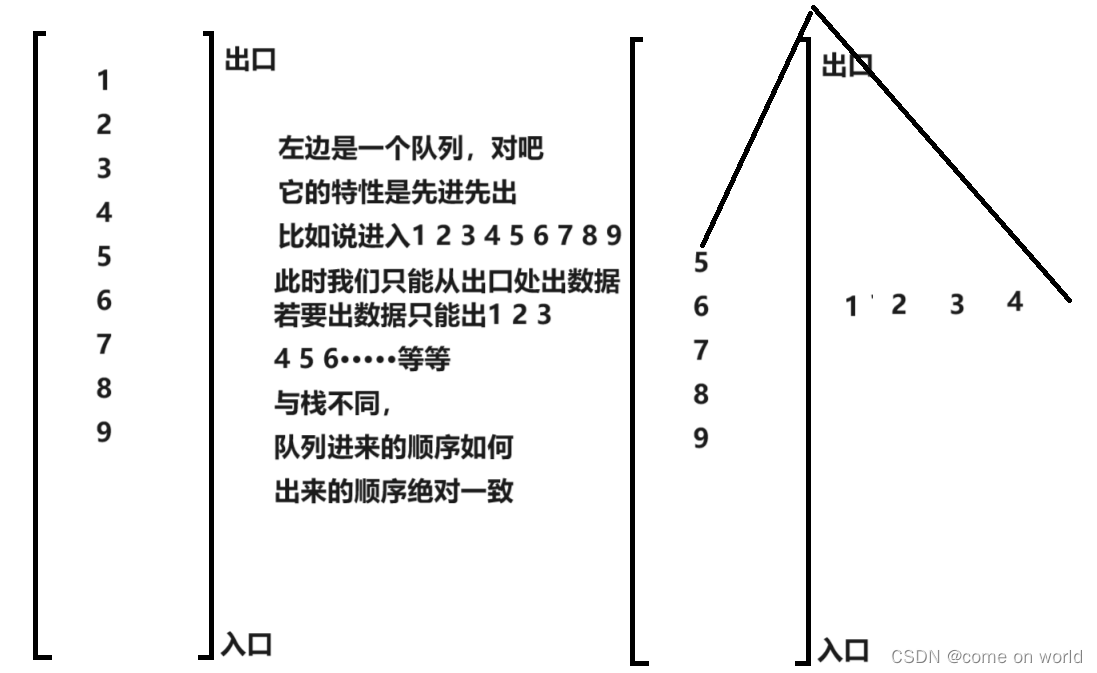
队列的特性与栈正好相反
他是先入先出
看图吧
当然了
队列的实现与栈的实现大差不差
队列也可以通过数组和链表来实现
分析
首先队列是需要从入口进,出口出的,
对于数组来说,他需要尾插和头删,
尾插很简单,只需要再接一个元素即可
但是头插,很麻烦需要整体左移然后size--时间复杂为o(n)
所以用数组实现有硬伤,因为其顺序结构,所以必然如此
对于链表来说
我们先使用单链表,要进行尾插以及头删
我们需要使用尾插,一般的单链表进行尾插的时间复杂度为o(n)
头删很简单,复杂度为o(1)
但是,我们可以使用一个指针来指向尾,这样就可以直接使尾插的复杂度变为o(1)
ok,从结构来讲,单链表最适合
但是,咱么都干了!!!
1数组实现队列
直接看代码吧
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int DataType;
typedef struct Queue {
DataType* a;
int size;
int capacity;
}Que;
void InitQue(Que*que)
{
que->a = (DataType*)malloc(sizeof(DataType)*4);
que->capacity = 4;
que->size = 0;
}
void QuePush(Que* que, DataType x)
{
if (que->size == que->capacity)
{
DataType* temp = (DataType*)realloc(que->a,sizeof(DataType)*que->capacity*2);
if (temp == NULL)
{
printf("realloc fail\n");
return;
}
else
{
que->a = temp;
que->capacity *= 2;
}
}
que->a[que->size++] = x;
}
void QuePop(Que* que)
{
assert(que->size != 0);
for (int i = 1; i < que->size; i++)
{
que->a[i - 1] = que->a[i];
}
que->size--;
}
bool QueEmpty(Que* que)
{
return que->size == 0;
}
DataType QueBack(Que* que)
{
assert(que);
assert(que->size > 0);
return que->a[que->size-1];
}
DataType QueFront(Que* que)
{
return que->a[0];
}
void QueDestroy(Que* que)
{
free(que->a);
que->capacity = 0;
que->size = 0;
}上面的代码,基本实现的逻辑与栈相差无几,甚至可以说跟简单
OK
看看更加实用的链表实现
2单链表实现队列
这里的注意点与用栈实现栈也是一样的
但是有一个注意点还是要讲一讲的
这里差点漏了
注意点1
就是在pop队列时
如果只有一个结点时,此时请你一定要把tail指针置空
上面的链表实现栈是也会有这个问题,
大家要注意,不然你就会被自己幽默到,看到nullter被调用 哈哈哈哈哈
OK大家看代码呗
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int DataType;
typedef struct Queue_2 {
struct Queue2* next;
DataType data;
}Que_2;
typedef struct Queue2 {
Que_2* a;
Que_2* tail;
int size;
}Que2;
void InitQue2(Que2* que);
void QuePush2(Que2* que, DataType x);
void QuePop2(Que2* que);
bool QueEmpty2(Que2* que);
DataType QueFront2(Que2* que);
void QueDestroy2(Que2* que);
int QueSize2(Que2* que);
DataType QueBack2(Que2* que);
void InitQue2(Que2* que)
{
assert(que);
que->tail=que->a = NULL;
que->size = 0;
}
void QuePush2(Que2* que, DataType x)
{
Que_2* temp = (Que_2*)malloc(sizeof(Que_2));
if (temp == NULL)
{
printf("malloc fail\n");
return;
}
temp->next = NULL;
temp->data = x;
if (que->a == NULL)
{
que->tail=que->a= temp;
}
else
{
que->tail->next = temp;
que->tail = temp;
}
que->size++;
}
void QuePop2(Que2* que)
{
assert(que->a);
Que_2* temp = que->a->next;
free(que->a);
que->a = temp;
if (que->a == NULL)
que->tail = NULL;
que->size--;
}
bool QueEmpty2(Que2* que)
{
return que->a == NULL;
}
DataType QueFront2(Que2* que)
{
assert(que->a);
return que->a->data;
}
DataType QueBack2(Que2* que)
{
assert(que->a);
return que->tail->next;
}
void QueDestroy2(Que2* que)
{
assert(que->a);
while (que->a)
{
Que_2* temp = que->a->next;
free(que->a);
que->a = temp;
}
que->tail = NULL;
que->size = 0;
}
int QueSize2(Que2* que)
{
return que->size;
}总结
额,终于算是肝完了,这里的代码的重复性很高,不要看字很多
很多都是重复的!好吧,栈和队列这个基础数据结构的各项实现方法算是都敲了一遍
当然,我们还有一个循环队列没有实现,对吧
下一次再来,搞一搞oj题
加油!