文章目录
- 注意力机制是怎么工作的
- 注意力机制的类型
- 构建Transformer模型
- Embedding层
- 注意力机制的实现
- Encoder实现
- Decoder实现
- Transformer实现
注意力机制的主要思想是将注意力集中在信息的重要部分,对重要部分投入更多的资源,以获取更多所关注目标的细节信息,抑制其他无用信息;
在注意力机制的背景下,我们将自主性提示称为查询(Query)。对于给定任何查询,注意力机制通过集中注意力(Attention Pooling)选择感官输入(Sensory Input),这些感官输入被称为值(Value)。每个值都与其对应的非自主提示的一个键(Key)成对。通过集中注意力,为给定的查询(自主性提示)与键(非自主性提示)进行交互,从而引导选择偏向值;
注意力机制计算过程如下:
![![[Pasted image 20240512132525.png]]](https://img-blog.csdnimg.cn/direct/4d74e86cf5264c50af551931a9ac0dac.png)
注意力机制是怎么工作的
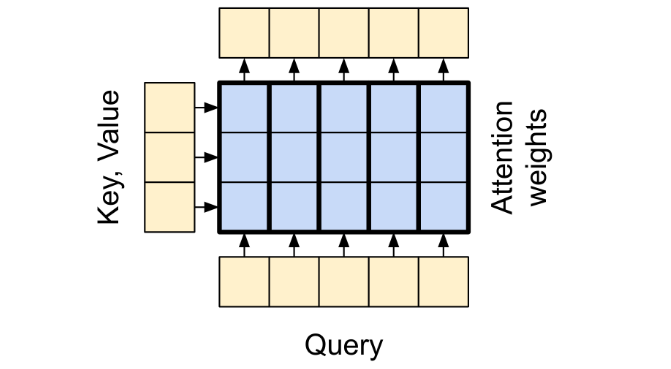
图中有四个东西,Query,Key,Value,Attention,图中把Key和Value放在了一起是因为其产生的output是与Key,Value的维度是无关的,只与Query的维度有关;文中把Key,Value称作为Context sequence,Query还是称作为Query sequence;为什么要这么做?可以看模型中右上方的Multi-Head Attention和左下角的Multi-Head Attention的区别进行分析;
Query,Key,Value这三个东西可以用python中的字典来解释,Key,Value表示字典中的键值对,而Query表示我们需要查询的键,Query与Key,Value匹配其得到的结果就是我们需要的信息;但是在这里并不要求Query与Key严格匹配,只需要模糊匹配就可以;Query对每一个Key进行一次模糊的匹配,并给出匹配程度,越适配权重就越大,然后根据权重再与每一个Value进行组合,得到最后的结果;其匹配程度的权重就代表了注意力机制的权重;
多头注意力机制就是把Query,Key,Value多个维度的向量分为几个少数维度的向量组合,再在Query_i,Key_i,Value_i上进行操作,最后把结果合并;
注意力机制的类型
Transformer模型中Multi-Head Attention有三个, 这三个分别对应三种Multi-Head Attention Layer:the cross attention layer,the global self attention layer, the causal self attention layer,从图中也可以发现每一层都有各自的不同,下面来一一介绍;
the cross attention layer:模型右上角(解码器)的Multi-Head Attention是注意力机制最直接的使用,其将编码器的信息和解码器的信息充分的结合了起来,文中把这一层叫做the cross attention layer;其context sequence是Encoder中得到的;
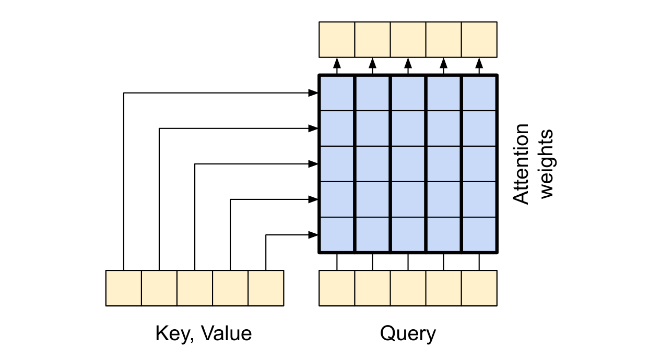
在这里要注意的是,每一次的查询是可以看得到所有的Key,Value的,但是查询与查询相互之间是看不到的,即独立的;
the global self attention layer:模型左下角(编码器)的Multi-Head Attention,这一层负责处理上下文序列,并沿着他的长度去传播信息即Query与Query之间的信息;
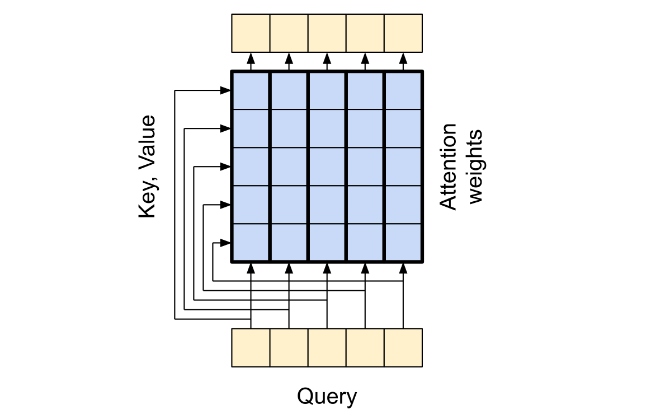
Query与Query之间的信息传播有很多种方式,例如在Transformer没出来之间我们普遍采用Bidirectional RNNs 和 CNNs的方式来处理;
但是为什么这里不使用RNN和CNN的方法呢?
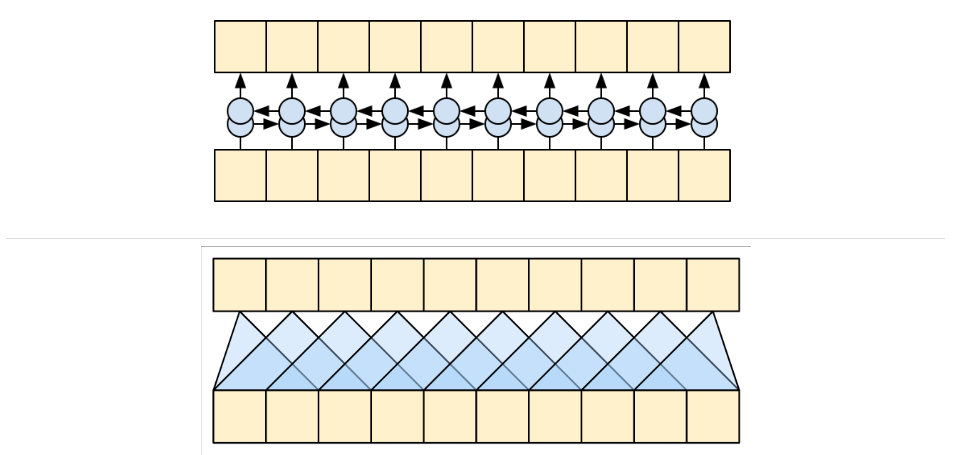
RNN和CNN的限制:
- RNN 允许信息沿着序列一路流动,但是它要经过许多处理步骤才能到达那里(限制梯度流动)。这些 RNN 步骤必须按顺序运行,因此 RNN 不太能够利用现代并行设备的优势。
- 在 CNN 中,每个位置都可以并行处理,但它只提供有限的接收场。接收场只随着 CNN 层数的增加而线性增长,需要叠加许多卷积层来跨序列传输信息(小波网通过使用扩张卷积来减少这个问题)。
the global self attention layer允许每个序列元素直接访问每个其他序列元素,只需少量操作,并且所有输出都可以并行计算。 就像下图这样:
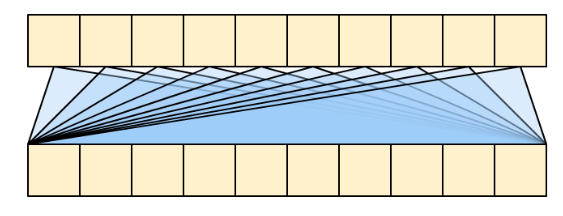
虽然图像类似于线性层,其本质好像也是线性层,但是其信息传播能力要比普通的线性层要强;
the causal self attention layer:因果自注意层,这一层与the global self attention layer类似,其不同的特点是需要mask,Masked Multi-Head Attention;这里要注意的是Transformer是一个自回归模型,每次产生一个输出并且把输出当作输入用来继续产生输出,因此这些模型确保每个序列元素的输出仅依赖于先前的序列元素,所以需要对Attention weights进行处理;
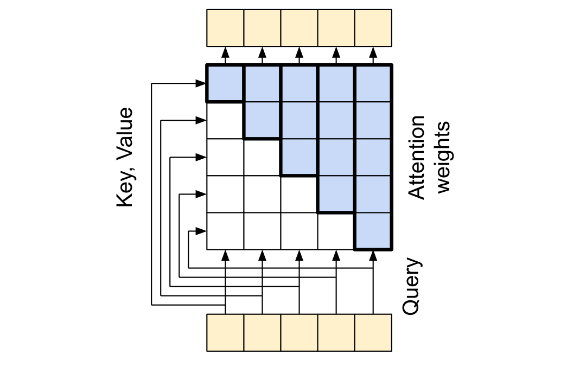
根据论文公式:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
可以发现
Q
Q
Q和
K
K
K是做矩阵运算的,
A
t
t
e
n
t
i
o
n
Attention
Attention中的单个元素计算是
Q
Q
Q中的某行和
K
K
K中的某行做点积运算;论文中是计算
A
t
t
e
n
t
i
o
n
Attention
Attention后在相应掩码位置乘一个无穷小,这里其实可以优化一下,只计算
A
t
t
e
n
t
i
o
n
Attention
Attention有效的位置,可以加快速度;
这一层根据训练和推理有一点不同,如上文所说,在训练时,我们不需要每一次新产生的输出做为输入,我们直接用真值(shift)代替新产生的输出进行训练就好,这样可以在缺失一点稳定性的情况下,加快训练速度,并得到每一个位置上的损失大小;
在推理时,我们并没有真值,我们只能以每一次新产生的输出作为输入进行计算,这里有两种自回归的处理方式;一个是RNN,一个是CNN:Fast Wavenet;
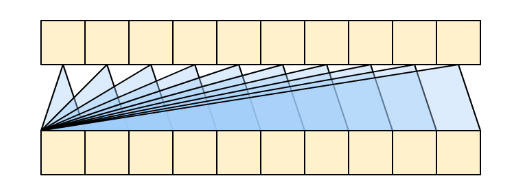
以下是该层的简要表示,即每个序列元素的输出仅依赖于先前的序列元素;
构建Transformer模型
模型结构如下:
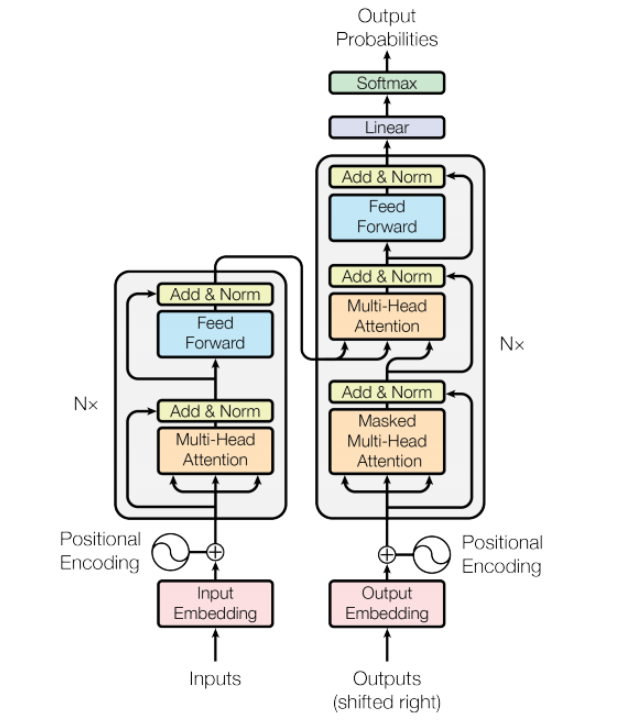
Embedding层
Embedding层分为两个部分:input_embedding 和 position_embedding
首先是input_embedding,假设 “注意力机制是Transformer的核心” 这句话分词得到 [注意力机制, 是, Transformer, 的, 核心];用序号表示为[1,2,3,4,5],由于是分类变量,需要转化为独热编码再使用权重矩阵映射到某一维度,然而这里可以直接用tf.kears.layers.Embedding一步实现上述两步功能;其需要一个input_dim:表示分类个数,也就是序号的最大值;output_dim:表示隐藏层维度,也就是d_model
其次是position_embedding,论文中采用的是绝对位置编码的方式:
![![[Pasted image 20240512143453.png]]](https://img-blog.csdnimg.cn/direct/8d060cf12ca14902973b0124c3c549fe.png)
其需要两个参数,一个是pos,这是表示位置,也就是 输入序列的长度 范围内的值,第二个是i,这表示嵌入向量的位置,也就是d_model 隐藏维度范围内的值;实现代码如下:
def absolute_position_embedding(n_len, d_model):
positions = tf.range(n_len, dtype=tf.float32)[:,tf.newaxis]
depths = tf.range(d_model//2, dtype=tf.float32)[tf.newaxis, :]/(d_model//2)
angle_rads = positions / (10000**depths)
pos_embedding = tf.concat([tf.sin(angle_rads), tf.cos(angle_rads)], axis=-1)
return pos_embedding
# position_input = absolute_position_embedding(n_len=2048, d_model=512)
# plt.pcolormesh(position_input.numpy().T, cmap='RdBu')
# plt.ylabel('Depth')
# plt.xlabel('Position')
# plt.colorbar()
# plt.show()
结合起来获得Embeding,使用 tf.keras.layers.Layer 类表达如下:
class Embedding(tf.keras.layers.Layer):
def __init__(self, n_len, input_dim, d_model):
super(Embedding, self).__init__()
self.input_embedding = tf.keras.layers.Embedding(input_dim=input_dim, output_dim=d_model)
self.position_embedding = self.absolute_position_embedding(n_len=n_len, d_model=d_model)
def absolute_position_embedding(self, n_len, d_model):
positions = tf.range(n_len, dtype=tf.float32)[:,tf.newaxis]
depths = tf.range(d_model//2, dtype=tf.float32)[tf.newaxis, :]/(d_model//2)
angle_rads = positions / (10000**depths)
pos_embedding = tf.concat([tf.sin(angle_rads), tf.cos(angle_rads)], axis=-1)
return pos_embedding
def call(self, x):
x = self.input_embedding(x)
output = x + self.position_embedding
return output
注意力机制的实现
由于要适应三种注意力机制,我们需要分离 mask,q,k,v功能
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(Self_Attention_Mechanism, self).__init__()
self.num_heads = num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.wo = tf.keras.layers.Dense(d_model)
def split_head(self, x):
"""(batch_size, heads, len, depth)"""
output = tf.reshape(x, [x.shape[0], x.shape[1], self.num_heads, -1])
output = tf.transpose(output, [0,2,1,3])
return output
def scaled_dot_product_attention(self, q, k, v, mask=False):
dk = tf.cast(k.shape[-1], tf.float32)
matmul_qk = tf.matmul(q, k, transpose_b=True) / tf.math.sqrt(dk)
if mask:
matmul_qk += -(1 - tf.linalg.band_part(tf.ones_like(matmul_qk), 0, -1)) * 1e9
attention_weighs = tf.nn.softmax(matmul_qk, axis=-1)
outputs = tf.matmul(attention_weighs, v)
return attention_weighs, outputs
def call(self, q, k, v, mask=False, return_attention_weights=False):
q = self.split_head(self.wq(q))
k = self.split_head(self.wk(k))
v = self.split_head(self.wv(v))
attention_weighs, output = self.scaled_dot_product_attention(q, k, v, mask=mask)
output = tf.transpose(output, [0,2,1,3])
output = tf.reshape(output, [output.shape[0], output.shape[1], -1])
output = self.wo(output)
if return_attention_weights:
return attention_weighs, output
else:
return output
Encoder实现
由于 Encoder 有六个相同的子块 EncoderLayer,这里先实现一下 EncoderLayer;
EncoderLayer 中 包含一个自注意力机制以及一个前反馈层,所以需要三个参数初始化:d_model , num_heads,dff
这里 dff 表示前反馈层中的投影维度;
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.fnn_in = tf.keras.layers.Dense(dff, activation='relu')
self.fnn_out = tf.keras.layers.Dense(d_model)
self.layernorm1 = tf.keras.layers.LayerNormalization()
self.layernorm2 = tf.keras.layers.LayerNormalization()
def call(self, x):
x1 = self.mha(q=x, k=x, v=x)
x1 = self.layernorm1(x + x1)
x2 = self.fnn_in(x1)
x2 = self.fnn_out(x2)
output = self.layernorm2(x1 + x2)
return output
Encoder 从本质来说就是 EncoderLayer 的累加:
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_encoder_layer, d_model, num_heads, dff):
super(Encoder, self).__init__()
self.encoder_layers = [EncoderLayer(d_model, num_heads, dff) for _ in range(num_encoder_layer)]
def call(self, x):
for encoder_layer in self.encoder_layers:
x = encoder_layer(x)
return x
Decoder实现
同样按照Encoder中一样实现,但是不同的是:首先多了一个 Mask MutliHead Attention,其次第二个MHA中 k 和 v 是来自于Encoder
class Decoder_layer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff):
super(Decoder_layer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.fnn_in = tf.keras.layers.Dense(dff, activation='relu')
self.fnn_out = tf.keras.layers.Dense(d_model)
self.layernorm1 = tf.keras.layers.LayerNormalization()
self.layernorm2 = tf.keras.layers.LayerNormalization()
self.layernorm3 = tf.keras.layers.LayerNormalization()
def call(self, x, enc_output):
x1 = self.mha1(q=x, k=x, v=x, mask=True)
x1 = self.layernorm1(x + x1)
x2 = self.mha2(q=x1, k=enc_output, v=enc_output)
x2 = self.layernorm2(x1 + x2)
x3 = self.fnn_in(x2)
x3 = self.fnn_out(x3)
output = self.layernorm3(x2 + x3)
return output
循环 DecoderLayer 得到 Decoder:
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_decoder_layer, d_model, num_heads, dff):
super(Decoder, self).__init__()
self.decoder_layers = [Decoder_layer(d_model, num_heads, dff) for _ in range(num_decoder_layer)]
def call(self, x, enc_output):
for decoder_layer in self.decoder_layers:
x = decoder_layer(x, enc_output)
return x
Transformer实现
结合一下前面实现的东西,很轻松可以得到:
class Transformer(tf.keras.Model):
def __init__(self, num_encoder_layer, num_decoder_layer, input_dim, n_len, d_model, num_heads, dff):
super(Transformers, self).__init__()
self.embedding_1 = Embedding(n_len, input_dim, d_model)
self.embedding_2 = Embedding(n_len, input_dim, d_model)
self.encoder = Encoder(num_encoder_layer, d_model, num_heads, dff)
self.decoder = Decoder(num_decoder_layer, d_model, num_heads, dff)
self.final_dense = tf.keras.layers.Dense(input_dim, activation='softmax')
def call(self, x1, x2):
x1 = self.embedding_1(x1)
x2 = self.embedding_2(x2)
x1 = self.encoder(x1)
x2 = self.decoder(x2, x1)
output = self.final_dense(x2)
return output