目录
- 🍁统一的列表初始化 { }
- initializer_list
- 🍁decltype 推导表达式类型
- 🍁可变参数模板
- 解析可变参数包
- 方法一
- 方法二
- 🍁lambda 表达式
- 捕捉列表的使用
- 运用场景举例
- lambda表达式 与 函数对象
🍁统一的列表初始化 { }
在 C++98 标准中,花括号 { } 可以对数组、结构体元素进行同一的初始化处理:
struct Point
{
int _x;
int _y;
};
int main()
{
int arr[] = { 1, 2, 3, 4, 5 }; //初始化数组
char str[] = { "hello world" };
Point p = { 1, 2 };
return 0;
}
时间来到 C++11 的时候,就扩大了花括号 { } 列表的使用范围。
花括号 { } 可以用来所有的内置类型 和 自定义类型;简单的来说就是可以用花括号来初始化一切变量,并且可以省略赋值符号。
struct Point
{
int _x;
int _y;
};
int main()
{
int x1 = 10;
int x2 = { 20 }; //初始化变量x2
int array1[] { 1, 2, 3, 4, 5 }; //初始话array1数组省略赋值符号
char str[] { "hello world" };
Point p { 1, 2 };
return 0;
}
列表初始化可以对 new 对象进行初始化:
int* pa = new int[5]{ 1, 2, 3, 4, 5 };
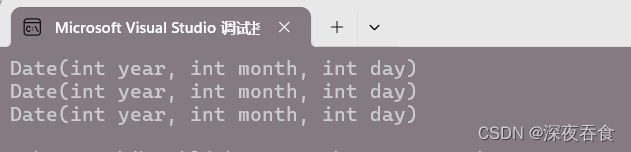
创建对象时使用列表初始化会调用该对象的构造函数:
class Date
{
public:
Date(int year, int month, int day)
:_year(year), _month(month), _day(day)
{
std::cout << "Date(int year, int month, int day)" << std::endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d(2024, 1, 1); //调用构造函数
//使用列表初始化
Date d1 = { 2024, 1, 2 }; //构造+拷贝构造==>编译优化为构造
Date d2{ 2024 ,1, 3 };
return 0;
}
列表初始化还可以运用在容器上:
#include <vector>
#include <list>
int main()
{
std::vector<int> v1 = { 1, 2, 3, 4, 5 }; //初始化vector容器
std::list<int> lt1 = { 10, 20, 30, 40 }; //初始化list容器
return 0;
}
注意:在初始化 vector 和 list 这样的容器的时候,并不是直接去调用 vector 和 list 的构造函数。vector 和 list 的构造函数也不支持这么多参数的传参。
initializer_list
花括号里面的初始化内容,C++会识别成 initializer_list :
int main()
{
auto i1 = { 1, 2, 3, 4, 5, 6 };
auto i2 = { 10, 20, 30, 40, 50, 60 };
std::cout << typeid(i1).name() << std::endl;
std::cout << typeid(i2).name() << std::endl;
return 0;
}
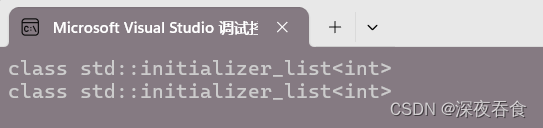
initializer_list 是一个类:
initializer_list 会构建一个类型,这个类型有两个指针:第一个指针指向列表的开始,另一个指针指向列表结尾的下一个位置

int main()
{
auto i1 = { 1, 2, 3, 4, 5, 6 };
auto it1 = i1.begin();
auto it2 = i1.end();
std::cout << it1 << std::endl;
std::cout << it2 << std::endl;
std::cout << it2 - it1 << std::endl;
return 0;
}
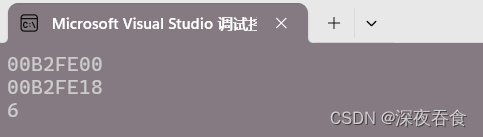
尾指针地址减去列表首元素的地址,得到就是列表元素个数
提示:列表中的内容是不能修改的,因为它们是被存放到常量区
int main()
{
auto i1 = { 1, 2, 3, 4, 5, 6 };
auto it = i1.begin();
(*it)++; //报错
return 0;
}

当然,我们也可以使用这个类:
int main()
{
std::initializer_list<int> il = { 1, 2, 3, 4, 5, 6 };
for (auto& e : il)
{
std::cout << e << " ";
}
std::cout << std::endl;
return 0;
}

为什么 vector 和 list 容器能够支持列表初始化呢?
C++11 标准出来后,像 vector 和 list 这样的容器推出了这样的构造函数:
vector(initializer_list<value_type> il,
const allocator_type& alloc = allocator_type());
vector 和 list 通过 initializer_list类去初始化列表,进而实现 vector 和 list 的构造初始化。
下面来实现一个简单版的 vector 支持 initializer_list 的构造函数:
vector(std::initializer_list<T> il)
{
reserve(il.size()); //检查容量
for (auto& e : il)
push_back(e);
}
下面再来举例几个列表初始化的案例:
#include <map>
#include <set>
#include <vector>
int main()
{
std::vector<int> v1 = { 1, 2, 3, 4, 5 };
std::vector<int> v2 = { 10, 20, 30, 40, 50 };
std::vector<std::vector<int>> vv1 = { v1 ,v2 };//对象初始化
std::vector<std::vector<int>> vv2 = { std::vector<int>{100, 200, 300}, v2 }; //匿名对象初始化
std::vector<std::vector<int>> vv3 = { { 1, 2, 3 }, { 4, 5, 6 }, { 7, 8, 9 } }; //编译器自动推导类型
std::set<std::vector<int>> s = { {1, 2, 3}, {10, 20, 30} };
std::map<std::string, int> m = { {"苹果", 1}, {"香蕉", 2}, {"哈密瓜", 3} };
return 0;
}
🍁decltype 推导表达式类型
decltype 是 C++11 中引入的一个新的关键字,主要用于 声明和推导表达式的类型
int main()
{
int x = 10;
int y = 20;
double a = 1.1;
double b = 2.2;
decltype (x + y) ret1;
decltype (b - a) ret2;
decltype (&x) ret3;
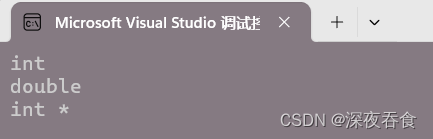
std::cout << typeid(ret1).name() << std::endl;
std::cout << typeid(ret2).name() << std::endl;
std::cout << typeid(ret3).name() << std::endl;
return 0;
}
decltype 可以用于 auto 推导不了类型的场景,例如模板的实例化传参:
int main()
{
double a = 1.1;
double b = 2.2;
//要求vector存储与 a*b 表达式的返回值一致的类型
std::vector<decltype(a * b)> v; //利用 decltype 推导表达式的类型
return 0;
}
🍁可变参数模板
C++98/03中,类模板的和函数模板中只能含有固定数量的模板参数,比较局限。在 C++11 引入了可变参数模板,可以创建可变参数函数和类模板。
示例:
template <class ...Args> //...Args表示模板参数包
void ShowList(Args... args)
{}
int main()
{
ShowList();
ShowList(1);
ShowList(1, 'x'); //不会限制传入的类型和参数的个数
return 0;
}
- Args是一个模板参数包,args是一个函数形参参数包
在函数声明一个形参参数包 Args... args ,表示这个参数包中可以被传入的参数个数是 0 个甚至是多个参数
也可以用sizeof来统计传入参数的个数,如下:
#include <iostream>
using namespace std;
template<typename ...Args>
void ShowList(Args... args)
{
cout << sizeof...(args) << endl; //统计传入参数的个数
}
int main()
{
ShowList();
ShowList(1);
ShowList(1, 'x'); //不会限制类型
ShowList(1, 'x', "abc");
return 0;
}

解析可变参数包
可变参数的作用我们看到了,就是解决了传参个数的限制。但是,当一个函数设置了参数包,那么在函数内部我们如何去获取可变参数包参数变量呢?
方法一
C++11提供了一个递归的方式来解析可变参数包,在函数模板中多设置一个模板参数:
void ShowList()
{
cout << endl;
}
template<typename T, typename ...Args>
void ShowList(const T& val, Args... args)
{
cout << val << " ";
ShowList(args...);//传入参数包,递归解析
}
int main()
{
ShowList();
ShowList(1);
ShowList(1, 'x');
ShowList(1, 'x', "abc");
return 0;
}

当参数被传入后,T 模板参数 val 会获取首次传入的参数。在之后都是获取到可变参数包的参数内容,每获取一次,可变参数个数递归传给下一次 ShowList 的参数个数就会减少一次。至此,就达到解析可变参数包的效果。
由于在参数包中传入的参数个数可以是 0 个,因此当参数包个数为 0 时也就是递归结束的条件!
方法二
通过调用函数的方式初始化数组来解析参数包:
template<typename T>
int PrintArg(const T& t)
{
cout << t << " ";
return 0;
}
template<typename ...Args>
void ShowList(Args... args)
{
int arr[] = { PrintArg(args)... }; //初始化数组
cout << endl;
}
int main()
{
ShowList();
ShowList(1);
ShowList(1, 'x');
ShowList(1, 'x', "abc");
return 0;
}

以 ShowList(1, 'x', "abc"); 为例子,编译器在编译阶段会将上面代码解析为下面这样:
void ShowList(int a1, char a2, string a3)
{
int arr[] = { PrintArg(a1), PrintArg(a2), PrintArg(a3) };
cout << endl;
}
使用参数包会影响编译器的效率,因为要推演函数参数的类型。对此,一般的参数包都会设计成下面这样的情况:
这里拿 ShowList 模板函数为例子
template<typename ...Args>
void ShowList(Args&&... args) //这里的&&表示折叠引用
{
int arr[] = { PrintArg(args)... }; //初始化数组
cout << endl;
}
在参数包后加上 &&,在推演参数类型时,传递的参数为左值 && 就会折叠为左值;传递的参数为右值 && 就没有变化还是右值;因此,在参数包后加上 &&,也被称为万能引用!
🍁lambda 表达式
介绍 lambda 表达式前,先来看这样的一个例子:
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
return 0;
}
vector 容器中的 Goods 对象有这样的属性:价格、名称 和 重量。
现在,如果想要将 vector 容器中的 Goods对象 按照价格进行降序排序,正常操会是这样的:先定义一个对货物的价格做比较的仿函数,再使用 sort 函数进行排序处理
struct ComparePriceGreater //定义仿函数
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
//降序
sort(v.begin(), v.end(), ComparePriceGreater());
return 0;
}
为了方便展示,这里直接使用了 VS 的监视窗口。
排序前:
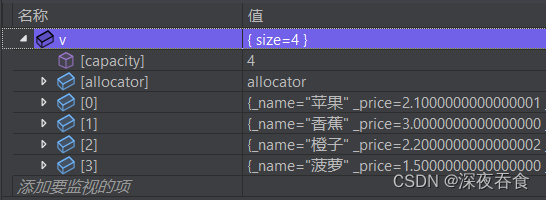
排序后结果如下:
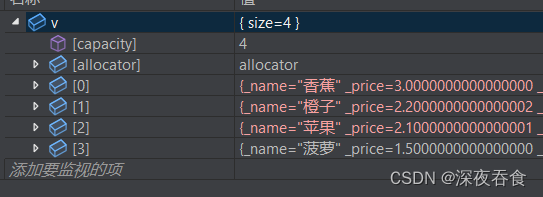
可以看到在 vector 容器中,各个物品都是按照价格降序的顺序进行排列。
在使用仿函数时,需要定义一个类,实现对应的函数运算符重载。仿函数的名字,定义都是有些许的繁琐和麻烦。
在 C++11引出了这么一个新的语法:lambda 表达式 可以代替仿函数而去使用 sort 函数。
下面就来介绍一下 lambda 表达式。
lambda 表达式由以下几个部分构成:
[]捕捉列表:编译器会根据[]来判断代码是否为 lambda 表达式。[]捕捉列表 用于捕获上下域中的变量提供给lambda 函数使用()参数列表:与普通的函数参数列表一样,当形参不存在时,()可以省略不写- mutable:通常情况下,lambda 表达式总是一个const 函数,mutable 关键字用于取消 lambda表达式的常性,可以省略
->返回值类型:用追踪返回类型形式声明函数的返回值类型,返回值类型明确情况下可以省略不写,由编译器自动推导{}函数体:实现 lambda 表达式的功能,函数体内部可以使用形参列表的内容,以及被捕获的变量值
lambda 表达式的书写格式:[] () mutable->return-type {}
注意:lambda 表达式返回值是一个对象
下面来举个示例,实现两个数相加的 lambda 表达式 :
int main()
{
std::cout << [](int x, int y)->int { return x + y; }(1, 2) << std::endl;
return 0;
}

但是这样写 lambda表达式很抽象,不利于代码的阅读。
lambda 表达式返回值是一个对象,可以将上面代码改写为下面这样:
int main()
{
auto add = [](int x, int y)->int { return x + y; }; //让编译器自动推导lambda表达式的类型
std::cout << add(10, 20) << std::endl;
return 0;
}

将 lambda 表达式返回,编译器会自动推导 lambda表达式类型定义为add。实例化一个 add 匿名对象执行对应的相加功能,通过打印输最后出到终端。
上面是通过传参的方式实现两个数相加的功能,下面用 lambda 表达式的捕获方式来实现相加功能:
int main()
{
int x = 10, y = 20;
auto add = [x, y]()->int { return x + y; }; //用[]来捕获x和y的值
std::cout << add() << std::endl;
return 0;
}

对 lambda 表达式有了一定了解后,我们再回过头来看看先前举的例子:
struct ComparePriceGreater //定义仿函数
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price > g2._price;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
//降序
sort(v.begin(), v.end(), ComparePriceGreater());
return 0;
}
写仿函数的进行排序的方式是不是太过于有点麻烦了,我们可以将仿函数改写成 lambda 表达式:
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) //使用lambda表达式
{
return g1._price > g2._price;
});
return 0;
}
排序前:
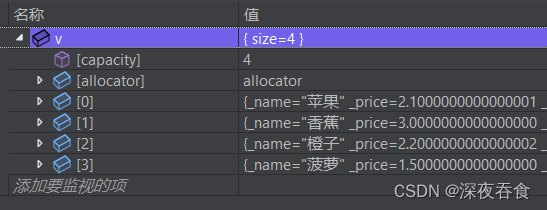
排序后:

使用lambda表达式进行排序的实现效果跟使用仿函数一样
捕捉列表的使用
下面用 lambda 表达式实现 swap 函数:
可以通过参数列表来实现,不过在使用参数列表时,需要用引用参数来接收:
int main()
{
int x = 10, y = 20;
//引用传入变量,正常值拷贝不会影响lambda表达式外的变量
auto swap = [](int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
};
swap(x, y); //实例化swap匿名对象
cout << x << " " << y << endl;
return 0;
}

lambda 表达式内部作用域 与 当前使用 lambda表达式 的函数作用域是分开的。
也就是说:在当前函数中的变量,在 lambda 表达式内部是使用不了的。如果,想要在 lambda 表达式中使用当前函数的变量,有两种方式:参数列表传参 和 捕捉列表。
如上举例,可以想象成函数传参。
下面再来通过捕获列表来实现 swap交换功能:
int main()
{
int x = 10, y = 20;
auto swap = [x, y]() //捕获x,y变量
{
int tmp = x;
x = y;
y = tmp;
};
swap();
cout << x << " " << y << endl;
return 0;
}
但是,直接捕获的变量,对其直接进行修改会报错:

在 lambda表达式中 被捕获的变量是按照拷贝的形式。
这里的 x 和 y 变量被捕获到 lambda表达式后,是被 const 修饰过的,直接进行值修改会报错 。
捕捉列表有两种捕获变量的方式:传值捕捉 和 传引用捕捉
传值捕捉 和 传引用捕捉 可以在捕捉列表中任意组合,下面来举例几个案例:
int x = 10, y = 20;
[&]() {};//全部传引用捕捉
[=]() {};//全部传值捕捉
//混合捕捉
[&x, y]() {};
[&, x]() {};
[=, &y]() {};
捕捉列表不能重复捕捉同一个变量,下面这种情况编译器会报错:
int x = 10;
[=, x]() {}; //出错
回到刚刚实现的 lambda 表达式。如果想要通过 传值捕捉 实现 swap 交换的功能,就要在 lambda 表达式中就要加上 mutable关键字:
int main()
{
int x = 10, y = 20;
auto swap = [x, y]() mutable //捕获x,y变量,使用mutable关键字
{
int tmp = x;
x = y;
y = tmp;
};
swap();
cout << x << " " << y << endl;
return 0;
}

当然,也可以通过 传引用捕捉 的方式实现对应的功能:
int main()
{
int x = 10, y = 20;
auto swap = [&x, &y]() //传引用捕捉
{
int tmp = x;
x = y;
y = tmp;
};
swap();
cout << x << " " << y << endl;
return 0;
}
运用场景举例
实现这样的一个程序,在这个程序中创建线程池,使得每个线程都能够执行打印特定数字的功能:
#include <thread>
#include <vector>
using namespace std;
int main()
{
int n = 0;//创建n个线程
cin >> n;
vector<thread> thds(n); //创建n个默认构造线程
for (int i = 0; i < n; i++)
{
size_t m = 0;
cin >> m; //输入打印数的范围
//创建线程池,使每个线程执行打印功能
thds[i] = thread([i, m]() //移动赋值,创建的匿名线程是将亡值
{
for (int j = 0; j < m; j++)
{
//打印对应线程编号与数字
cout << this_thread::get_id() << ":" << j << endl;
}
cout << endl;
});
}
//等待线程池
for (auto& th : thds)
th.join(); //这里必须传引用,线程没有拷贝构造(没有意义)
return 0;
}
lambda表达式 与 函数对象
先来介绍一下函数对象:函数对象,又被称为仿函数。实现一个类,在这个类中实现一个 operator() 运算符重载。实例化出这个类对象,在调用 operator() 时,就像调用函数那般。就被称为仿函数。
下面实现一个仿函数 和 lambda 表达式,实现的功能都类似:
class Rate
{
public:
Rate(double rate)
: _rate(rate)
{}
double operator()(double money, int year)
{
return _rate * money * year;
}
private:
double _rate;
};
int main()
{
//函数对象
double rate = 0.49;
Rate r1(rate);//构造
r1(1000, 2);
//lambda表达式
auto r2 = [=](double money, int year)->double
{
return money * year * rate;
};
r2(1000, 2);
return 0;
}
在VS2022调试下,查看反汇编:
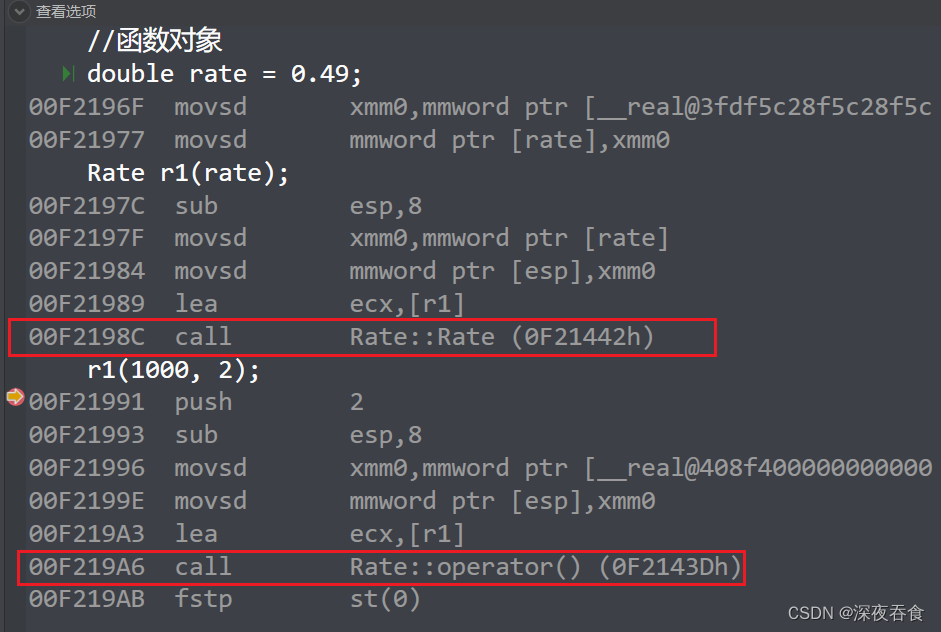
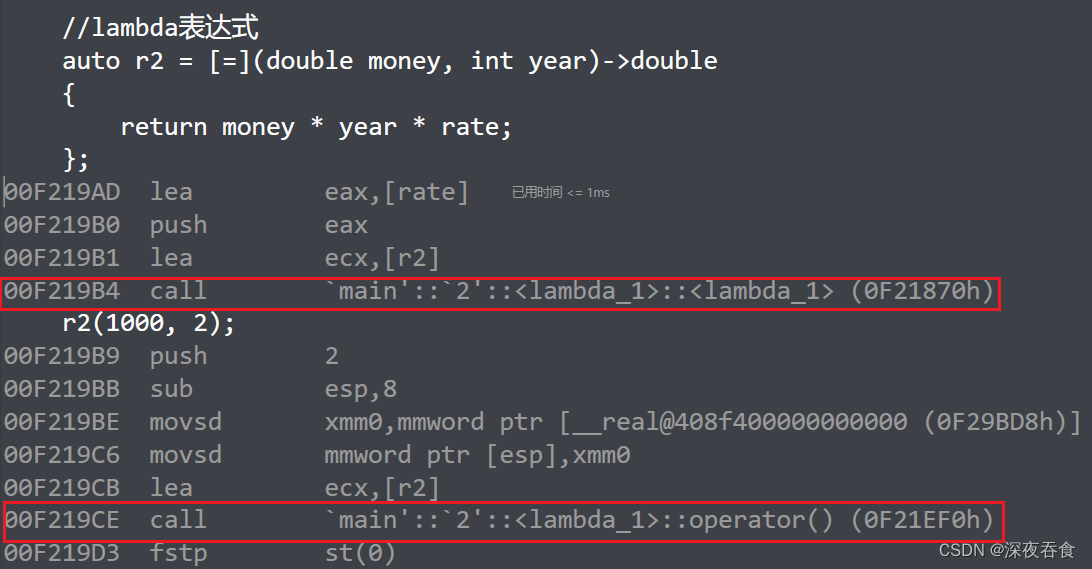
下面再来计算一下仿函数的大小和 lambda表达式的大小,还是拿上面的例子:
class Rate
{
public:
Rate(double rate)
: _rate(rate)
{}
double operator()(double money, int year)
{
return _rate * money * year;
}
private:
double _rate;
};
int main()
{
double rate = 0.49;
auto r2 = [=](double money, int year)->double
{
return money * year * rate;
};
cout << sizeof Rate << endl; //查看Rate类的大小
cout << sizeof r2 << endl; //查看r2的lambda表达式的大小
return 0;
}
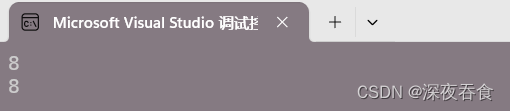
反观底层,仿函数和lambda表达式都是类似的汇编调用方式。而且,如果 lambda表达式捕获的变量 与 仿函数类中的成员一样,那么计算的大小都是一样的。
可以这样说:在编译器眼里,lambda表达式就是仿函数。只不过在用户表面看来,两个表达式方式是那么的不一样。
lambda 表达式就介绍到这里。
C++11新增的语法当然还不止这些,如果对 C++11 还感兴趣的老铁,可以看看小编的另一篇文章:C++入门语法介绍