目录
- 前言
- 0. 简述
- 1. 执行一下我们的python程序
- 2. ONNX是什么?
- 3. onnx中的各类Proto
- 3.1 理解onnx中的ValueInfoProto
- 3.2 理解onnx中的TensorProto
- 3.3 理解onnx中的NodeProto
- 3.4 理解onnx中的AttributeProto
- 3.5 理解onnx中的GraphProto
- 3.6 理解onnx中的ModelProto
- 4. 根据onnx中的Proto信息创建onnx
- 5. 根据onnx中的Proto信息读取onnx
- 6. 根据onnx中的Proto信息修改onnx
- 总结
- 参考
前言
自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习课程第三章—TensorRT 基础入门,一起来学习剖析 ONNX 并理解 Protobuf
课程大纲可以看下面的思维导图

0. 简述
本小节目标:学习 ONNX 的 Proto 架构,使用 onnx.helper 创建 onnx 修改 onnx
这节我们学习第三章节第五小节—剖析 onnx 架构并理解 ProtoBuf,我们上一节学习了 Pytorch 模型导出 ONNX,但如果我们想要更深层次的理解 ONNX 并创建 ONNX 修改 ONNX 的话就需要去理解 ONNX 数据结构是什么样子的,所以也就引出了去理解 Protobuf 这个东西
本次课程学习完之后希望大家能够理解 ONNX 中的 Proto 架构,并学会如何使用 onnx.helper 这个 Python API 去创建 ONNX、修改 ONNX
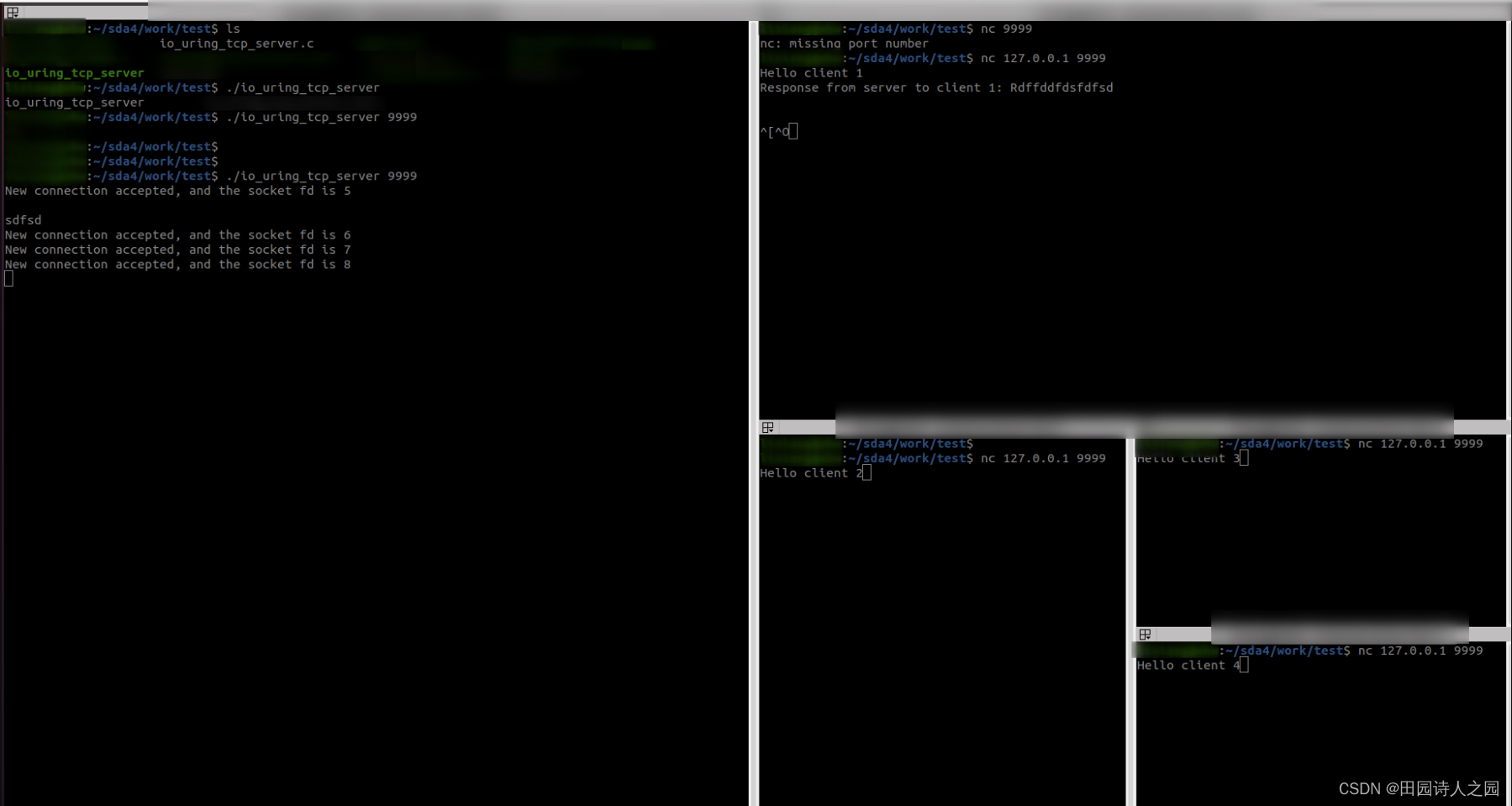
1. 执行一下我们的python程序
源代码获取地址:https://github.com/kalfazed/tensorrt_starter
这个小节的案例主要是 3.3-read-and-parse-onnx,如下所示:

代码执行结果的一部分展示如下:

在代码中我们会手动去创建一个 ONNX 而不是像之前那样导出 ONNX,此外我们会加载创建的 ONNX 并读取里面的相关信息,比如各个节点的权重信息,输入输出信息等等,实现一个简单的 parser 功能
2. ONNX是什么?
我们先来看下 ONNX 是什么东西,ONNX 是一种神经网络的格式,采用 Protobuf 二进制形式进行序列化模型。Protobuf 全称叫做 Protocal Buffer 是 Google 提出来的一套表示和序列化数据的机制,Protobuf 会根据用于定义的数据结构来进行序列化存储。

如果我们要用 protobuf 序列化存储数据的话,首先我们得去定义 proto 这个概念,它类似于一种数据结构,像 ONNX 里面就有 graph 的 proto,graph 里面就有各种节点 node 的 proto 还有输入输出的 value 的 proto。根据定义的这些 proto 然后编译之后进行序列化,这就是使用 protobuf 的整体的流程
言外之意就是说我们可以根据 ONNX 官方提供的数据结构信息去修改或者创建 onnx
下图是直接打印 ONNX 模型的 proto 信息,可以看到 graph 里面有 node,node 里面有 input、output、op_type 等等这些东西

3. onnx中的各类Proto
onnx 的各类 proto 的定义需要看官方文档 https://github.com/onnx/onnx/tree/main,这里面的 onnx/onnx.in.proto 定义了所有 onnx 的 Proto,而有关 onnx 的 IR(Intermediate Representation)信息可以查看 https://github.com/onnx/onnx/blob/main/docs/IR.md
onnx 中的组织结构可以分为如下几个层级:
- ModelProto:描述的是整个模型的信息
- GraphProto:描述的是整个网络的信息
- NodeProto:描述的是各个计算节点,比如 conv,linear
- TensorProto:描述的是 tensor 的信息,主要包括权重
- ValueInfoProto:描述的是 input/output 信息
- GraphProto:描述的是整个网络的信息
下图展示的更加直观:

我们先看下 GraphProto,它的定义可以在 onnx/onnx.in.proto#L455 中找到,如下图所示:

GraphProto 描述的是整个模型的图结构,可以看到它里面有 NodeProto、TensorProto、ValueInfoProto 等等,下面我们一个个简单介绍下各个 Proto
补充:IR (Intermediate Representation) 版本是什么意思呢?和指令集 opset_version 一样指的是算子版本吗?🤔
IR (Intermediate Representation) 版本和 opset_version 是 ONNX 模型中的两个不同的概念,分别代表不同的内容:(form ChatGPT)
IR (Intermediate Representation) 版本:
- 定义:IR 版本指定 ONNX 模型的整体格式版本。它描述了模型文件的结构和如何组织各个部分。
- 作用:它控制模型的元数据、图结构、节点之间的连接方式等。每次 ONNX 格式有较大改动时,IR 版本号就会增加。
- 更新:IR 版本的更新通常涉及对模型文件格式的改进,如支持新特性、增强兼容性或提升模型组织的灵活性。
- 影响:不同的 IR 版本可能影响模型的可读性和兼容性。例如,某些工具或运行时环境可能只支持较低的 IR 版本。
opset_version (操作集版本):
- 定义:opset_version 是 ONNX 中算子的版本号,它描述了每个操作符(算子)的具体版本。
- 作用:控制算子(如加法、卷积等)的行为定义。每次某个算子的功能或参数发生变化时,opset_version 就会增加。
- 更新:opset_version 的更新通常涉及特定算子的新特性、改进或修复。例如,一个算子在新版本中可能增加了新的参数或优化了性能。
- 影响:模型中的每个算子都有一个 opset_version,指定了该算子应遵循的版本定义。不同的 opset_version 可能影响模型的算子行为和兼容性。
总结起来:
- IR 版本:影响整个模型的组织结构和格式。
- opset_version:影响具体算子的定义和行为。
这两个版本是独立的,但都对模型的兼容性和功能有重要影响。在使用 ONNX 模型时,确保这两个版本与 ONNX Runtime 或其他工具的支持版本相匹配是很重要的。
3.1 理解onnx中的ValueInfoProto
首先我们来看 onnx 中的 ValueInfoProto 是什么,ValueInfoProto 一般用来定义网络的 input/output,会根据 input/output 的 type 来附加属性
大家可以在 onnx/onnx.in.proto#L188 中找到 ValueInfoProt 的定义,如下图所示:

它其实定义的内容比较少,有 name、type 等等,其中的 TypeProto 的定义如下:

补充:那其实我们在 ValueInfoProto 中还看到了 name = 1,type = 2,doc_string = 3,这些数字又代表什么含义呢?🤔
在 Protobuf 描述文件中,input = 1 和 output = 2 是字段的标识符,用于在二进制编码中标识字段的顺序和编号。这是 Protobuf 的一种机制,用来高效地序列化和反序列化数据。具体解释如下:(from ChatGPT)
-
input = 1和output = 2:- 这些数字是字段编号,用于在序列化时唯一标识字段。
input = 1表示input字段在 Protobuf 编码中会使用编号 1。output = 2表示output字段在 Protobuf 编码中会使用编号 2。
-
Protobuf 编码中的字段编号:
- 在 Protobuf 序列化过程中,每个字段都会被编码为一个键值对,其中键包括字段编号和字段类型。
- 这样设计的目的是使得序列化的数据紧凑且高效,便于解析和处理。
举例说明:
假设有一个 NodeProto 实例:
NodeProto {
input: "input_tensor"
output: "output_tensor"
name: "MyNode"
op_type: "Add"
}
在 Protobuf 二进制编码中,这些字段可能会被编码为类似于以下内容:
input字段会使用编号 1 编码,例如:1: "input_tensor"output字段会使用编号 2 编码,例如:2: "output_tensor"name字段会使用编号 3 编码,例如:3: "MyNode"op_type字段会使用编号 4 编码,例如:4: "Add"
这些编号是唯一且固定的,用于确保在序列化和反序列化过程中字段的正确映射和识别。
总结
input = 1 和 output = 2 是字段的标识符,表示这些字段在 Protobuf 编码中的编号。Protobuf 使用这些编号来有效地进行数据的序列化和反序列化。
3.2 理解onnx中的TensorProto
TensorProto 一般用来定义一个权重,比如 conv 的 weights 和 bias,dims 是 repeated 类型意味着是数组,raw_data 是 bytes 类型
我们可以在 onnx/onnx.in.proto#L498 找到它的定义,如下图所示:

3.3 理解onnx中的NodeProto
下一个是 NodeProto,NodeProto 一般用来定义一个计算节点比如 conv,linear,其中:
- input 是 repeated 类型,意味着是数组
- output 是 repeated 类型,意味着是数组
- attribute 有一个自己的 Proto
- op_type 需要严格根据 onnx 所提供的 Operators 写
我们可以在 onnx/onnx.in.proto#L207 找到它的定义,如下图所示:

具体的 op_type 在各个版本的算子支持可以参考: https://github.com/onnx/onnx/blob/main/docs/Operators.md

3.4 理解onnx中的AttributeProto
AttributeProto 一般用来定义一个 node 的属性比如说 kernel size、pad、stride 等等
我们可以在 onnx/onnx.in.proto#L121 找到它的定义,如下图所示:


3.5 理解onnx中的GraphProto
GraphProto 之前讲过它一般用来定义一个网络,包括:
- input/output
- input/output 是 repeated,所以是数组
- initializer
- 在 onnx 中一般表示权重信息,我们可以在 netron 看到
- initializer 是 repeated,所以是数组
- node
- node 是 repeated,所以是数组

3.6 理解onnx中的ModelProto
最后我们来看下 ModelProto,ModelProto 一般用来定义模型的全局信息比如 opset,graph 并不是 repeated,所以一个 model 对应一个 graph
我们可以在 onnx/onnx.in.proto#L356 找到它的定义,如下图所示:

4. 根据onnx中的Proto信息创建onnx
我们理解 onnx 中的各类 proto 信息之后再来创建一个 onnx 其实是一件特别简单的事情,onnx 官方提供了一些很方便的 api 来创建 onnx,例如:
- onnx.helper.make_tensor
- onnx.helper.make_tensor_value_info
- onnx.helper.make_attribute
- onnx.helper.make_node
- onnx.helper.make_graph
- onnx.helper.make_model
我们先来看 3.3-read-and-parse-onnx\src\create_onnx_linear.py 案例,代码如下所示:
import onnx
from onnx import helper
from onnx import TensorProto
# 理解onnx中的组织结构
# - ModelProto (描述的是整个模型的信息)
# --- GraphProto (描述的是整个网络的信息)
# ------ NodeProto (描述的是各个计算节点,比如conv, linear)
# ------ TensorProto (描述的是tensor的信息,主要包括权重)
# ------ ValueInfoProto (描述的是input/output信息)
# ------ AttributeProto (描述的是node节点的各种属性信息)
def create_onnx():
# 创建ValueProto
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
y = helper.make_tensor_value_info('y', TensorProto.FLOAT, [10, 10])
# 创建NodeProto
# op_type 不能随意写,需要跟 https://github.com/onnx/onnx/blob/main/docs/Operators.md 对齐
mul = helper.make_node('Mul', ['a', 'x'], 'c', "multiply")
add = helper.make_node('Add', ['c', 'b'], 'y', "add")
# 构建GraphProto
graph = helper.make_graph([mul, add], 'sample-linear', [a, x, b], [y])
# 构建ModelProto
model = helper.make_model(graph)
# 检查model是否有错误
onnx.checker.check_model(model)
# print(model)
# 保存model
onnx.save(model, "../models/sample-linear.onnx")
return model
if __name__ == "__main__":
model = create_onnx()
这段代码使用 onnx 库创建了一个简单的 ONNX 模型。首先定义了四个 TensorProto 类型的 ValueInfoProto,分别是输入张量 a 和 x,以及输出张量 b 和 y。接着创建了两个 NodeProto 节点:一个是 Mul 节点用于将 a 和 x 相乘得到中间张量 c,另一个是 Add 节点用于将 c 和 b 相加得到最终输出 y。然后通过 helper.make_graph 函数将这些节点和张量组合成一个 GraphProto,并进一步构建 ModelProto。最后,代码检查模型是否正确并将其保存为 sample-linear.onnx 文件。(from ChatGPT)
导出的 ONNX 如下图所示:

我们再来看 3.3-read-and-parse-onnx\src\create_onnx_convnet.py 案例,代码如下所示:
import numpy as np
import onnx
from onnx import numpy_helper
def create_initializer_tensor(
name: str,
tensor_array: np.ndarray,
data_type: onnx.TensorProto = onnx.TensorProto.FLOAT
) -> onnx.TensorProto:
initializer = onnx.helper.make_tensor(
name = name,
data_type = data_type,
dims = tensor_array.shape,
vals = tensor_array.flatten().tolist())
return initializer
def main():
input_batch = 1;
input_channel = 3;
input_height = 64;
input_width = 64;
output_channel = 16;
input_shape = [input_batch, input_channel, input_height, input_width]
output_shape = [input_batch, output_channel, 1, 1]
##########################创建input/output################################
model_input_name = "input0"
model_output_name = "output0"
input = onnx.helper.make_tensor_value_info(
model_input_name,
onnx.TensorProto.FLOAT,
input_shape)
output = onnx.helper.make_tensor_value_info(
model_output_name,
onnx.TensorProto.FLOAT,
output_shape)
##########################创建第一个conv节点##############################
conv1_output_name = "conv2d_1.output"
conv1_in_ch = input_channel
conv1_out_ch = 32
conv1_kernel = 3
conv1_pads = 1
# 创建conv节点的权重信息
conv1_weight = np.random.rand(conv1_out_ch, conv1_in_ch, conv1_kernel, conv1_kernel)
conv1_bias = np.random.rand(conv1_out_ch)
conv1_weight_name = "conv2d_1.weight"
conv1_weight_initializer = create_initializer_tensor(
name = conv1_weight_name,
tensor_array = conv1_weight,
data_type = onnx.TensorProto.FLOAT)
conv1_bias_name = "conv2d_1.bias"
conv1_bias_initializer = create_initializer_tensor(
name = conv1_bias_name,
tensor_array = conv1_bias,
data_type = onnx.TensorProto.FLOAT)
# 创建conv节点,注意conv节点的输入有3个: input, w, b
conv1_node = onnx.helper.make_node(
name = "conv2d_1",
op_type = "Conv",
inputs = [
model_input_name,
conv1_weight_name,
conv1_bias_name
],
outputs = [conv1_output_name],
kernel_shape = [conv1_kernel, conv1_kernel],
pads = [conv1_pads, conv1_pads, conv1_pads, conv1_pads],
)
##########################创建一个BatchNorm节点###########################
bn1_output_name = "batchNorm1.output"
# 为BN节点添加权重信息
bn1_scale = np.random.rand(conv1_out_ch)
bn1_bias = np.random.rand(conv1_out_ch)
bn1_mean = np.random.rand(conv1_out_ch)
bn1_var = np.random.rand(conv1_out_ch)
# 通过create_initializer_tensor创建权重,方法和创建conv节点一样
bn1_scale_name = "batchNorm1.scale"
bn1_bias_name = "batchNorm1.bias"
bn1_mean_name = "batchNorm1.mean"
bn1_var_name = "batchNorm1.var"
bn1_scale_initializer = create_initializer_tensor(
name = bn1_scale_name,
tensor_array = bn1_scale,
data_type = onnx.TensorProto.FLOAT)
bn1_bias_initializer = create_initializer_tensor(
name = bn1_bias_name,
tensor_array = bn1_bias,
data_type = onnx.TensorProto.FLOAT)
bn1_mean_initializer = create_initializer_tensor(
name = bn1_mean_name,
tensor_array = bn1_mean,
data_type = onnx.TensorProto.FLOAT)
bn1_var_initializer = create_initializer_tensor(
name = bn1_var_name,
tensor_array = bn1_var,
data_type = onnx.TensorProto.FLOAT)
# 创建BN节点,注意BN节点的输入信息有5个: input, scale, bias, mean, var
bn1_node = onnx.helper.make_node(
name = "batchNorm1",
op_type = "BatchNormalization",
inputs = [
conv1_output_name,
bn1_scale_name,
bn1_bias_name,
bn1_mean_name,
bn1_var_name
],
outputs=[bn1_output_name],
)
##########################创建一个ReLU节点###########################
relu1_output_name = "relu1.output"
# 创建ReLU节点,ReLU不需要权重,所以直接make_node就好了
relu1_node = onnx.helper.make_node(
name = "relu1",
op_type = "Relu",
inputs = [bn1_output_name],
outputs = [relu1_output_name],
)
##########################创建一个AveragePool节点####################
avg_pool1_output_name = "avg_pool1.output"
# 创建AvgPool节点,AvgPool不需要权重,所以直接make_node就好了
avg_pool1_node = onnx.helper.make_node(
name = "avg_pool1",
op_type = "GlobalAveragePool",
inputs = [relu1_output_name],
outputs = [avg_pool1_output_name],
)
##########################创建第二个conv节点##############################
# 创建conv节点的属性
conv2_in_ch = conv1_out_ch
conv2_out_ch = output_channel
conv2_kernel = 1
conv2_pads = 0
# 创建conv节点的权重信息
conv2_weight = np.random.rand(conv2_out_ch, conv2_in_ch, conv2_kernel, conv2_kernel)
conv2_bias = np.random.rand(conv2_out_ch)
conv2_weight_name = "conv2d_2.weight"
conv2_weight_initializer = create_initializer_tensor(
name = conv2_weight_name,
tensor_array = conv2_weight,
data_type = onnx.TensorProto.FLOAT)
conv2_bias_name = "conv2d_2.bias"
conv2_bias_initializer = create_initializer_tensor(
name = conv2_bias_name,
tensor_array = conv2_bias,
data_type = onnx.TensorProto.FLOAT)
# 创建conv节点,注意conv节点的输入有3个: input, w, b
conv2_node = onnx.helper.make_node(
name = "conv2d_2",
op_type = "Conv",
inputs = [
avg_pool1_output_name,
conv2_weight_name,
conv2_bias_name
],
outputs = [model_output_name],
kernel_shape = [conv2_kernel, conv2_kernel],
pads = [conv2_pads, conv2_pads, conv2_pads, conv2_pads],
)
##########################创建graph##############################
graph = onnx.helper.make_graph(
name = "sample-convnet",
inputs = [input],
outputs = [output],
nodes = [
conv1_node,
bn1_node,
relu1_node,
avg_pool1_node,
conv2_node],
initializer =[
conv1_weight_initializer,
conv1_bias_initializer,
bn1_scale_initializer,
bn1_bias_initializer,
bn1_mean_initializer,
bn1_var_initializer,
conv2_weight_initializer,
conv2_bias_initializer
],
)
##########################创建model##############################
model = onnx.helper.make_model(graph, producer_name="onnx-sample")
model.opset_import[0].version = 12
##########################验证&保存model##############################
model = onnx.shape_inference.infer_shapes(model)
onnx.checker.check_model(model)
print("Congratulations!! Succeed in creating {}.onnx".format(graph.name))
onnx.save(model, "../models/sample-convnet.onnx")
# 使用onnx.helper创建一个最基本的ConvNet
# input (ch=3, h=64, w=64)
# |
# Conv (in_ch=3, out_ch=32, kernel=3, pads=1)
# |
# BatchNorm
# |
# ReLU
# |
# AvgPool
# |
# Conv (in_ch=32, out_ch=10, kernel=1, pads=0)
# |
# output (ch=10, h=1, w=1)
if __name__ == "__main__":
main()
这段代码使用 onnx 库创建了一个简单的卷积神经网络(ConvNet)模型,并将其保存为 sample-convnet.onnx 文件。首先,定义了一个辅助函数 create_initializer_tensor,用于生成权重和偏置的初始化器,这些初始化器将作为 TensorProto 对象被添加到模型中。(from ChatGPT)
在主函数中,首先设置了输入和输出的形状信息,并使用 onnx.helper.make_tensor_value_info 创建了相应的 ValueInfoProto。接着,定义了第一个卷积层的节点,包括权重和偏置的初始化器,通过 onnx.helper.make_node 创建 NodeProto 节点,并指定了卷积操作的参数如核大小和填充方式。
随后,代码添加了一个 BatchNormalization(批归一化)节点,生成了对应的缩放、偏置、均值和方差的初始化器,并创建了 BatchNormalization 节点。紧接着,创建了一个 ReLU 激活层节点和一个全局平均池化层(GlobalAveragePool)节点,这些节点不需要额外的权重初始化器。
接下来,定义了第二个卷积层,类似于第一个卷积层,创建了其权重和偏置的初始化器以及对应的卷积节点。最后,所有节点和初始化器被组合成一个 GraphProto,并进一步构建 ModelProto。模型在进行形状推断和验证后,被保存为 ONNX 格式文件。整个流程展示了如何使用 ONNX API 从头构建一个基本的卷积神经网络模型。
导出的 ONNX 如下图所示:

5. 根据onnx中的Proto信息读取onnx
ONNX 创建成功后我们就想去读取创建的 ONNX 的相关信息
我们来看 3.3-read-and-parse-onnx\src\parse_onnx_linear.py 案例,代码如下所示:
import onnx
def main():
model = onnx.load("../models/sample-linear.onnx")
onnx.checker.check_model(model)
graph = model.graph
nodes = graph.node
inputs = graph.input
outputs = graph.output
print("\n**************parse input/output*****************")
for input in inputs:
input_shape = []
for d in input.type.tensor_type.shape.dim:
if d.dim_value == 0:
input_shape.append(None)
else:
input_shape.append(d.dim_value)
print("Input info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, input.type.tensor_type.elem_type, input_shape))
for output in outputs:
output_shape = []
for d in output.type.tensor_type.shape.dim:
if d.dim_value == 0:
output_shape.append(None)
else:
output_shape.append(d.dim_value)
print("Output info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, output.type.tensor_type.elem_type, input_shape))
print("\n**************parse node************************")
for node in nodes:
print("node info: \
\n\tname: {} \
\n\top_type: {} \
\n\tinputs: {} \
\n\toutputs: {}".format(node.name, node.op_type, node.input, node.output))
if __name__ == "__main__":
main()
这段代码通过 onnx 库加载并解析了一个名为 sample-linear.onnx 的 ONNX 模型,输出了模型的输入、输出信息和节点信息。首先,代码加载了 ONNX 模型并检查其有效性。接着,从模型中提取 graph 对象,并进一步提取图中的 nodes(计算节点)、inputs(输入)和 outputs(输出)。随后,代码遍历输入和输出,打印每个节点的名称、数据类型和形状信息。在形状解析中,将维度值为 0 的维度标记为 None。最后,代码遍历并打印每个计算节点的名称、操作类型、输入和输出信息,提供了对模型内部结构的详细解析。(from ChatGPT)
输出如下图所示:

我们再来看 3.3-read-and-parse-onnx\src\parse_onnx_convnet.py 案例,代码如下所示:
import onnx
def main():
model = onnx.load("../models/sample-convnet.onnx")
onnx.checker.check_model(model)
graph = model.graph
initializers = graph.initializer
nodes = graph.node
inputs = graph.input
outputs = graph.output
print("\n**************parse input/output*****************")
for input in inputs:
input_shape = []
for d in input.type.tensor_type.shape.dim:
if d.dim_value == 0:
input_shape.append(None)
else:
input_shape.append(d.dim_value)
print("Input info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, input.type.tensor_type.elem_type, input_shape))
for output in outputs:
output_shape = []
for d in output.type.tensor_type.shape.dim:
if d.dim_value == 0:
output_shape.append(None)
else:
output_shape.append(d.dim_value)
print("Output info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, output.type.tensor_type.elem_type, input_shape))
print("\n**************parse node************************")
for node in nodes:
print("node info: \
\n\tname: {} \
\n\top_type: {} \
\n\tinputs: {} \
\n\toutputs: {}".format(node.name, node.op_type, node.input, node.output))
print("\n**************parse initializer*****************")
for initializer in initializers:
print("initializer info: \
\n\tname: {} \
\n\tdata_type: {} \
\n\tshape: {}".format(initializer.name, initializer.data_type, initializer.dims))
if __name__ == "__main__":
main()
这个和之前的读取 ONNX 代码一样,只是计算节点的不同而已
输出如下图所示:

如果我们要经常读取 ONNX 信息的话,我们可以写一个函数来解析不同的 ONNX
我们再来看最后一个案例 3.3-read-and-parse-onnx\src\parse_onnx_cbr.py 案例,代码如下所示:
import torch
import torch.nn as nn
import torch.onnx
import onnx
from parser_custom import parse_onnx
from parser_custom import read_weight
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)
self.bn1 = nn.BatchNorm2d(num_features=16)
self.act1 = nn.LeakyReLU()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.act1(x)
return x
def export_norm_onnx():
input = torch.rand(1, 3, 5, 5)
model = Model()
model.eval()
file = "../models/sample-cbr.onnx"
torch.onnx.export(
model = model,
args = (input,),
f = file,
input_names = ["input0"],
output_names = ["output0"],
opset_version = 15)
print("Finished normal onnx export")
def main():
export_norm_onnx()
model = onnx.load_model("../models/sample-cbr.onnx")
parse_onnx(model)
initializers = model.graph.initializer
for item in initializers:
read_weight(item)
if __name__ == "__main__":
main()
其中的 parser_custom.py 实现如下:
import onnx
import numpy as np
# 注意,因为weight是以字节的形式存储的,所以要想读,需要转变为float类型
def read_weight(initializer: onnx.TensorProto):
shape = initializer.dims
data = np.frombuffer(initializer.raw_data, dtype=np.float32).reshape(shape)
print("\n**************parse weight data******************")
print("initializer info: \
\n\tname: {} \
\n\tdata: \n{}".format(initializer.name, data))
def parse_onnx(model: onnx.ModelProto):
graph = model.graph
initializers = graph.initializer
nodes = graph.node
inputs = graph.input
outputs = graph.output
print("\n**************parse input/output*****************")
for input in inputs:
input_shape = []
for d in input.type.tensor_type.shape.dim:
if d.dim_value == 0:
input_shape.append(None)
else:
input_shape.append(d.dim_value)
print("Input info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, input.type.tensor_type.elem_type, input_shape))
for output in outputs:
output_shape = []
for d in output.type.tensor_type.shape.dim:
if d.dim_value == 0:
output_shape.append(None)
else:
output_shape.append(d.dim_value)
print("Output info: \
\n\tname: {} \
\n\tdata Type: {} \
\n\tshape: {}".format(input.name, output.type.tensor_type.elem_type, input_shape))
print("\n**************parse node************************")
for node in nodes:
print("node info: \
\n\tname: {} \
\n\top_type: {} \
\n\tinputs: {} \
\n\toutputs: {}".format(node.name, node.op_type, node.input, node.output))
print("\n**************parse initializer*****************")
for initializer in initializers:
print("initializer info: \
\n\tname: {} \
\n\tdata_type: {} \
\n\tshape: {}".format(initializer.name, initializer.data_type, initializer.dims))
这段代码展示了一个从 PyTorch 模型到 ONNX 模型的完整导出和解析流程,并对模型的权重进行了读取和输出。首先,定义了一个包含卷积层、批归一化层和激活层的简单 PyTorch 模型 Model。在 export_norm_onnx 函数中,通过 torch.onnx.export 方法将 PyTorch 模型转换为 ONNX 格式,并保存为 sample-cbr.onnx 文件。(from ChatGPT)
在 main 函数中,首先调用 export_norm_onnx 函数进行模型导出,随后加载生成的 ONNX 模型,并使用 parse_onnx 函数解析模型结构,输出输入、输出节点信息以及计算节点信息。对于每个计算节点,打印其名称、操作类型、输入和输出。随后,遍历模型的初始化器(即权重和偏置),使用 read_weight 函数读取和打印每个初始化器的名称和数据内容。read_weight 函数将初始化器的字节数据转换为浮点数数组,并输出其形状和数据内容。
parser_custom 模块中,parse_onnx 函数详细解析了模型的图结构,输出了模型的输入、输出、节点和初始化器的详细信息,帮助全面理解 ONNX 模型的内部构成。
输出如下图所示:

6. 根据onnx中的Proto信息修改onnx
之前杜老师的课程中有提到使用 onnx 的 api 来修改 onnx,感兴趣的可以看下:4.5.tensorRT基础(1)-onnx文件及其结构的学习,编辑修改onnx
虽然 onnx 官方提供了一些 python api 来修改 onnx,但是韩君老师这里推荐大家使用 TensorRT 下的 onnxsurgeon,相关使用会在后面小节详细介绍
总结
本次课程我们主要学习了 ONNX 中的各种 Proto,ONNX 本质上是一个 Protobuf 文件,它由许多的 Proto 组成包括 ModelProto、GraphProto、NodeProto、TensorProto 等等。接着我们学习了如何利用 onnx 的 python api 去创建读取 onnx,只要知道了 Proto 的数据结构,我们就可以创建解析整个 onnx
OK,以上就是第 5 小节有关剖析 ONNX 架构并理解 Protobuf 的全部内容了,下节我们来学习 ONNX 注册算子的方法,敬请期待😄
参考
- https://github.com/kalfazed/tensorrt_starter
- https://github.com/onnx/onnx
- https://github.com/onnx/onnx/blob/main/docs/Operators.md
- 4.5.tensorRT基础(1)-onnx文件及其结构的学习,编辑修改onnx