1 网络爬虫
网络爬虫:是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
网络爬虫相关技术和框架繁多,针对场景的不同可以选择不同的网络爬虫技术。
2 Scrapy框架(Python)
2.1. Scrapy架构
2.1.1. 系统架构
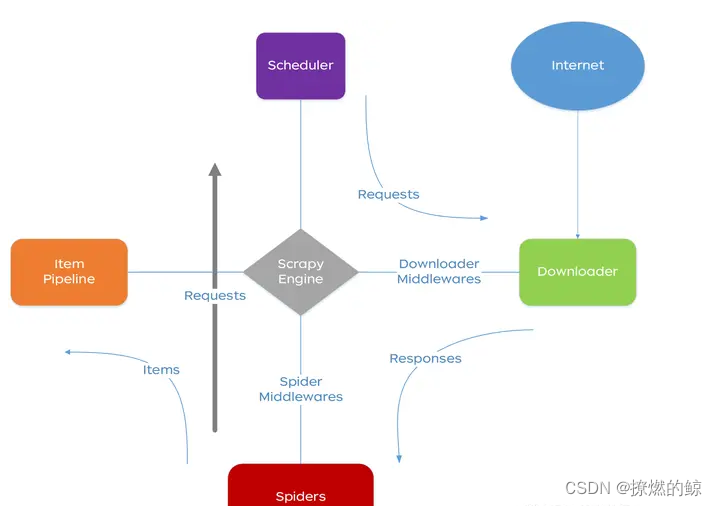
2.1.2. 执行流程
总结爬虫开发过程,简化爬虫执行流程如下图所示:
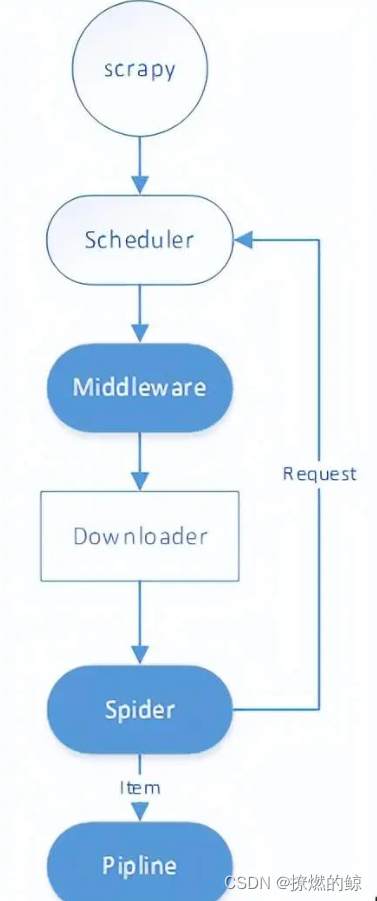
爬虫运行主要流程如下:
(1) Scrapy启动Spider后加载Spaider的start_url,生成request对象;
(2) 经过middleware完善request对象(添加IP代理、User-Agent);
(3) Downloader对象按照request对象下载页面;
(4) 将response结果传递给spider的parser方法解析;
(5) spider获取数据封装为item对象传递给pipline,解析的request对象将返回调度器进行新一轮的数据抓取;
2.2. 框架核心文件介绍
2.2.1. scrapy.cfg
scrapy.cfg是scrapy框架的入口文件,settings节点指定爬虫的配置信息,deploy节点用于指定scrapyd服务的部署路径。
| [settings]
default = sfCrawler.settings
[deploy]
url =http://localhost:6800/
project = jdCrawler
|
2.2.2. settings.py
settings主要用于配置爬虫启动信息,包括:并发线程数量、使用的middleware、items等信息;也可以作为系统中的全局的配置文件使用。
**注:**目前主要增加了redis、数据库连接等相关配置信息。
2.2.3. middlewares.py
middleware定义了多种接口,分别在爬虫加载、输入、输出、请求、请求异常等情况进行调用。
**注:**目前主要用户是为爬虫增加User-Agent信息和IP代理信息等。
2.2.4. pipelines.py
用于定义处理数据的Pipline对象,scrapy框架可以在settings.py文件中配置多个pipline对象,处理数据的个过程将按照settings.py配置的优先级的顺序顺次执行。
**注:**系统中产生的每个item对象,将经过settings.py配置的所有pipline对象。
2.2.5. items.py
用于定义不同种数据类型的数据字典,每个属性都是Field类型;
2.2.6. spider目录
用于存放Spider子类定义,scrapy启动爬虫过程中将按照spider类中name属性进行加载和调用。
2.3. 爬虫功能扩展说明
2.3.1. user_agents_middleware.py
通过procces_request方法,为request对象添加hearder信息,随机模拟多种浏览器的User-Agent信息进行网络请求。
2.3.2. proxy_server.py
通过procces_request方法,为reques对象添加网络代理信息,随机模拟多IP调用。
2.3.3. db_connetion_pool.py
文件位置
db_manager/db_connetion_pool.py,文件定义了基础的数据连接池,方便系统各环节操作数据库。
2.3.4. redis_connention_pool.py
文件位置db_manager/ redis_connention_pool.py,文件定义了基础的Redis连接池,方便系统各环节操作Redis缓存。
2.3.5. scrapy_redis包
scrapy_redis包是对scrapy框架的扩展,采用Redis作为请求队列,存储爬虫任务信息。
spiders.py文件:定义分布式RedisSpider类,通过覆盖Spider类start_requests()方法的方式,从Redis缓存中获取初始请求列表信息。其中RedisSpider子类需要为redis_key赋值。
pipelines.py文件:定义了一种简单的数据存储方式,可以直接将item对象序列化后保存到Redis缓存中。
dupefilter.py文件:定义数据去重类,采用Redis缓存的方式,已经保存的数据将添加到过滤队列中。
queue.py文件:定义几种不同的入队和出队顺序的队列,队列采用Redis存储。
2.4. 微博爬虫开发示例
2.4.1. 查找爬虫入口
2.4.1.1. 站点分析
网站一般会分为Web端和M端两种,两种站点在设计和架构上会有较大的差别。通常情况下Web端会比较成熟,User-Agent检查、强制Cookie、登录跳转等限制,抓取难度相对较大,返回结果以HTML内容为主;M端站点通常采用前后端分离设计,大多提供独立的数据接口。所以站点分析过程中优先查找M端站点入口。微博Web端及M端效果如图所示:
微博Web端地址:weibo.com/,页面显示效果如下图所…
注:图片来源于微博PC端截图