网络爬虫概述与原理
- 网络爬虫简介
- 狭义上理解
- 功能上理解
- 常见用途
- 总结
- 网络爬虫分类
- 通用网络爬虫
- 聚焦网络爬虫
- 增量网络爬虫
- 深度网络爬虫
- 网络爬虫流程
- 网络爬虫采集策略
- 深度有限搜索策略
- 广度优先搜索策略
网络爬虫简介
通过有效地获取网络资源的方式,便是网络爬虫。网络爬虫(Web Crawler)又被称为网络蜘蛛(Web Spider)或Web信息采集器,是一种按照指定规则、自动抓取或下载网络资源的计算机程序或自动化脚本。
狭义上理解
利用标准网络协议(HTTP、HTTPS),根据网络超链接和信息检索方法(深度优先)遍历网络数据的软件程序。
功能上理解
确定待采集的URL队列,获取每个URL对应的网页内容(如HTML和JSON),根据用户要求解析网页中的字段(如标题),并存储解析得到的数据。
常见用途
大数据环境下舆情分析与监测
政府或企业基于网络爬虫技术,采集论坛评论、在线博客、新闻媒体和微博等网站中的海量数据,采用数据挖掘相关方法(如实体识别、词频统计、文本情感计算、主题识别与演化等),发掘舆情热点、跟踪目标话题,并根据一定的标准采取相应的舆情控制与引导措施。
大数据环境下的用户分析
企业利用网络爬虫技术,采集用户基本信息、用户对企业或商品的看法、观点以及态度等数据、用户之间的互动信息等。基于这些信息,企业可以对用户进行画像,如用户基本属性画像、用户产品特征画像、用户互动那个特征画像等,发掘用户对产品的个性化偏好与需求。同时,也可以分析企业自身产品的优势与顾客反馈情况等。
科研需求
针对网络大数据驱动、多源异构数据驱动的科学研究,必然涉及网络数据采集技术。例如,针对网络中的多源异构数据(如数字、文本、图片和视频等),如何更好地管理与存储所采集的数据、如何进行数据的过滤与融合、如何对数据的可用性进行评估、如何将数据应用到商业分析中等。
总结
网络爬虫技术在搜索引擎中扮演着信息采集器的角色,是搜索引擎模块中的最基础的部分。搜索引擎Google、百度、必应(Bing)都采用网页爬虫技术采集海量的互联网数据。大致结构如下:

- 利用网络爬虫技术自动化地采集互联网中的网页信息
- 存储采集的信息,在存储过程中,往往需要检测重复内容,从而避免大量重复信息的采集;同时,玩也之间的链接关系也需要存储;原因是链接关系可用来计算网页内容的重要性。
- 数据预处理操作,即提取文字、分词、消除噪音以及链接关系计算等。
- 对预处理的数据建立索引库,方便用户快速查找,常用的索引方法有后缀数组、签名文件和倒排文件。
- 基于用户检索的内容(如用户输入的关键词),搜索引擎从网页索引库中查找符合该关键词的所有网页(结果集),通过对结果集的排序,将最相关的网页返回给用户
网络爬虫分类
网络爬虫按照系统结构和实现技术,可分为4类,即通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫
通用网络爬虫
又称为全网网络爬虫,其在采集数据时,由部分种子URL扩展到整个网络的全部页面,主要应用于搜索引擎数据的采集。这类网络爬虫的数据采集范围较广,数据采集量巨大,对数据采集的速度和存储空间有较高的要求,通常需要深度遍历网站的资源。例如,Apache的子项目Nutch就是一个高效的通用网络爬虫框架,其使用分布式的方式采集数据。
聚焦网络爬虫
又称为主题网络爬虫,是指选择性地采集那些与预先定义好的主题相关的页面。相比于通用网络爬虫,聚焦网络爬虫采集的网页资源少,主要用于满足特定人群对特定领域信息的需求。在聚焦网络爬虫中,需要设计过滤策略,即过滤与所定主题无关的页面。
增量网络爬虫
指对已下载网页采取增量式更新,只采集新产生的或者已发生变化网页的爬虫。增量网络爬虫能够在一定程度上避免了重复采集数据,历史已经采集过的页面不重复采集。增量网络爬虫避免了重复采集数据,可以减少时间和空间上的耗费。针对小规模特定网站的数据采集,在设计网络爬虫时,可构建一个基于时间戳判断是否更新的数据库,通过判断时间戳的先后,判断程序是否继续采集,同时更新数据库中的时间戳信息。
深度网络爬虫
Deep Web爬虫,指对大部分内容不能通过静态链接获取,只有用户提交表单信息才能获取Web页面的爬虫。
网络爬虫流程

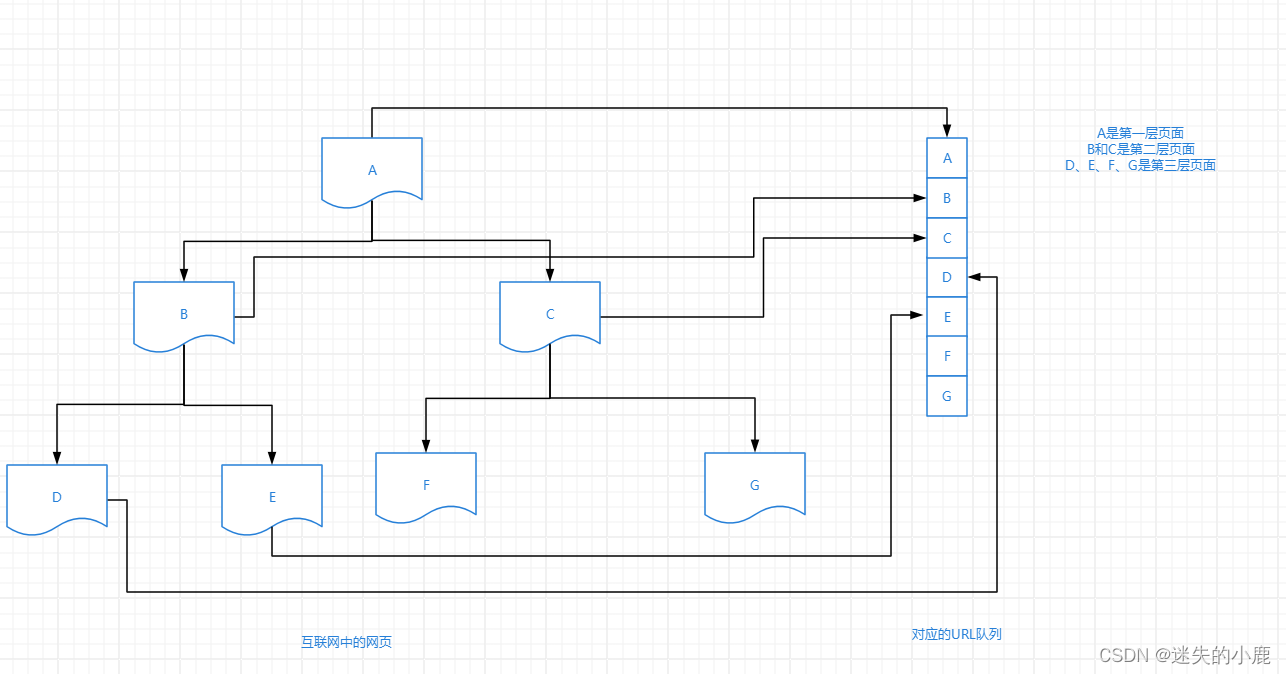
- 选取部分种子URL(初始URL),将其放入待采集的队列中。如在java中,可以放入List、LinkedList及Queue中
- 判断URL队列是否为空,如果为空则结束程序的执行,否则执行下一步
- 从待采集的URL队列中取出一个URL,获取URL对应的网页内容。在此步骤中需要使用HTTP响应状态码(200和403)判断是否成功获得了数据,如响应成功则执行解析操作;如响应不成功,则将其重新放入待采集URL队列(这里需要过滤掉无效URL)
- 响应成功后获取的数据,执行源码解析操作。此步骤根据用户需求获取网页内容中的部分字段,如论坛帖子的id、标题和发表时间等
- 对解析后的数据进行数据存储操作
网络爬虫采集策略
深度有限搜索策略
Depth-First Search,从根节点开始,根据优先级向下遍历该根节点对应的子节点。当访问到某一子节点时,以该子节点为入口,继续向下层遍历,直到没有新的子节点可以继续访问为止。接着使用回溯法,找到没有被访问的节点,以类似的方式进行搜索。
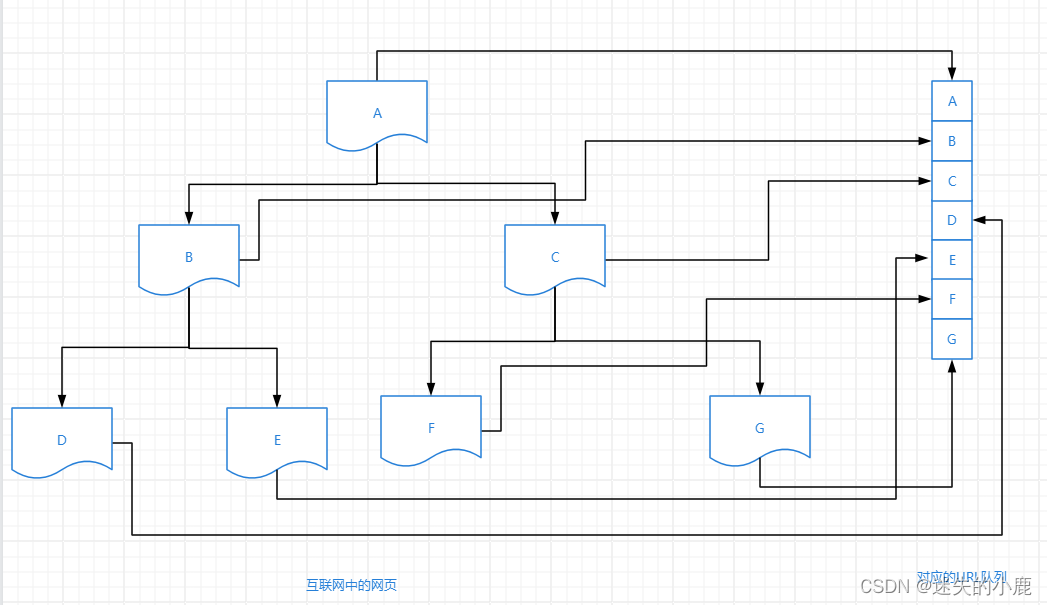
广度优先搜索策略
又称为宽度优先搜索策略,从根节点开始,沿着网络的宽度遍历每一层的节点,如果所有节点均被访问,则终止程序。