hashtable
hashtable是通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,这样在查找的时候就可以很快的找到该元素。
哈希函数
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
常见的哈希函数
-
直接定制法:取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀 缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
-
除留余数法:设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
-
平方取中法:假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址 平方取中法比较适合:不知
道关键字的分布,而位数又不是很大的情况 -
折叠法:折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
-
随机数法:选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。通常应用于关键字长度不等时采用此法
-
数学分析法:设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出
现。可根据散列表的大小,选择其中各种符号分布均匀的若干位(很多不同的)作为散列地址。数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
哈希冲突
在哈希表中,不同的关键字值对应到同一个存储位置的现象。即当两个不同的对象通过哈希函数计算后得到相同的哈希值,这两个对象就被认为发生了哈希冲突。
解决哈希冲突有2种方式一种是闭散列,另一种是开散列。
闭散列
闭散列法不使用链表,而是直接在哈希表中为关键字寻找下一个空闲位置。当发生哈希冲突时,它会使用某种探测方法(如线性探测、二次探测、双重散列等)来寻找下一个空闲位置。
void conflict()
{
size_t start = hf(kv.first) % _table.size();
size_t index = start;
size_t i = 0;
while (_table[index]._status == EXIST)
{
i++;
index = start + i; //线性探测
//index = start + i*i; //二次探测
//不段循环,不会越界
index = index%_table.size();
}
_table[index]._kv = kv;
_table[index]._status = EXIST;
++_n;
}
性能特点
- 闭散列法节省了链表节点和指针的开销,因此空间效率较高
- 当哈希表的空间利用率较高时,容易发生数据“堆积”现象,导致查找效率降低。
- 如果空间效率要求高,且关键字分布均匀闭散列合适
闭散列模拟实现hashtable
namespace jt
{
//位置的状态,删除的话标记状态就可以不用删除数据
enum status
{
EMPTY,
EXIST,
DELETE
};
//节点
template<class K, class V>
struct HashDate
{
pair<K, V> _kv;
status _status = EMPTY; //给缺省值,默认状态为空
};
}
namespace jt
{
//key是整数时,直接返回
template<class K>
struct Hash
{
//size_t 正数和负数映射的位置不一样
size_t operator()(const K& key)
{
return key;
}
};
//key为string类型时调用这个HashFunc
//如果key为自定义类型再增加新的模板特化
template<>
struct Hash<string>
{
size_t operator()(const string& s)
{
size_t AsciiSum = 0;
for (auto e : s)
{
AsciiSum *= 31; //解决字符的冲突--有科学依据
AsciiSum += e;
}
return AsciiSum;
}
};
template<class K, class V, class HashFunc = Hash<K>>
class HashTable
{
public:
HashDate<K, V>* find(const K& key)
{
if (_table.size() == 0)
return nullptr;
HashFunc hf;
size_t start = hf(key) % _table.size();
size_t index = start;
size_t i = 0;
while (_table[index]._status != EMPTY)
{
if (_table[index]._status == EXIST && _table[index]._kv.first == key)
{
return &_table[index];
}
i++;
index = start + i;
//不段循环,不会越界
index = index % _table.size();
}
//找不到
return nullptr;
}
bool erase(const K& key)
{
HashDate<K, V> *ret = find(key);
if (ret)
{
ret->_status = DELETE;
--_n;
return true;
}
else
{
return false;
}
}
bool insert(const pair<K, V>& kv)
{
HashDate<K, V>* ret = find(kv.first);
if (ret)
{
return false; //存在就不能再插入
}
//第一次插入 / 载荷因子(填入表的个数/散列表长度)大于0.7 的时候 需要扩容
if (_table.size() == 0 || _n * 10 % _table.size() >= 7)
{
//定义一个哈希重新映射元素位置
HashTable<K, V> NewHT;
size_t NewSize = _table.size() == 0 ? 10 : _table.size() * 2;
NewHT._table.resize(NewSize);
//按NewSize把原来数据插入回NewHT中
for (size_t i = 0; i < _table.size(); i++)
{
if (_table[i]._status == EXIST)
NewHT.insert(_table[i]._kv);
}
//旧的自动销毁,换上新的
_table.swap(NewHT._table);
}
HashFunc hf;
//处理冲突
size_t start = hf(kv.first) % _table.size();
size_t index = start;
size_t i = 0;
while (_table[index]._status == EXIST)
{
i++;
index = start + i; //线性探测
//index = start + i*i; //二次探测
//不段循环,不会越界
index = index%_table.size();
}
_table[index]._kv = kv;
_table[index]._status = EXIST;
++_n;
return true;
}
private:
vector<HashDate<K, V>> _table;
size_t _n = 0; //有效数据个数
};
}
开散列
开散列法使用链表来解决哈希冲突。当两个或多个关键字哈希到同一个位置(哈希桶)时,这些关键字会被放在该哈希桶对应的链表中。哈希表实际上存储的是指向这些链表的指针。
性能特点
- 开散列法可以有效避免数据“堆积”,因为每个哈希桶都可以动态地增长其链表长度。
- 插入和删除操作相对简单,因为它们只需要在相应的链表上进行操作,但是,由于需要额外的空间来存储链表节点和指针,所以空间开销较大。
- 当关键字分布不均匀,或者哈希表的大小不能预先确定时,开散列法是一个较好的选择,它也适用于那些需要频繁进行插入和删除操作的应用场景。
拉链法实现hashtable
namespace jt
{
enum status
{
EMPTY,
DELETE,
EXIST
};
template<class K, class V>
struct HashNode
{
HashNode<K, V>* _next; //节点的指针
pair<K, V> _kv;
HashNode(const pair<K, V>& kv)
:_kv(kv)
, _next(nullptr)
{}
};
}
namespace jt
{
//key是整数时,直接返回
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
//key为string类型时调用这个Hash
//如果为自定义类型再增加新的模板特化
template<>
struct Hash<string>
{
size_t operator()(const string& s)
{
size_t AsciiSum = 0;
for (auto e : s)
{
AsciiSum *= 31; //让数据分布没那么集中
AsciiSum += e;
}
return AsciiSum;
}
};
template<class K, class V, class HashFunc = Hash<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
Node* find(const K& k)
{
if (_table.empty())
return nullptr;
HashFunc hf;
size_t index = hf(k) % _table.size();
Node* cur = _table[index];
//找同一条链上的
while (cur)
{
if (cur->_kv.first == k)
return cur;
else
cur = cur->_next;
}
return nullptr;
}
bool insert(const pair<K, V>& kv)
{
Node* ret = find(kv.first);
if (ret) return false;
HashFunc hf;
//负载因子等于1的时候扩容
//当一个桶超过一定的值会转化成红黑树
if (_n == _table.size())
{
size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
vector<Node*> NewTable;
NewTable.resize(newSize);
//把原Hash遍历一遍把有的数据拷贝到新的Hash上
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
//算出新位置
size_t index = hf(cur->_kv.first) % NewTable.size();
//头插
cur->_next = NewTable[index];
NewTable[index] = cur;
cur = next;
}
_table[i] = nullptr;
}
_table.swap(NewTable);
}
//头插法
Node* newnode = new Node(kv);
size_t index = hf(kv.first) % _table.size();
newnode->_next = _table[index];
_table[index] = newnode;
_n++;
return true;
}
bool erase(const K& k)
{
if (_table.empty())
return false;
HashFunc hf;
size_t index = hf(k) % _table.size();
Node* prev = nullptr;
Node* cur = _table[index];
while (cur)
{
if (cur->_kv.first == k)
{
//要删除第一个节点--头删
if (prev == nullptr)
{
_table[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
--_n;
delete cur;
return true;
}
//往桶下找
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
private:
vector<Node*> _table;
size_t _n = 0; //有效个数
};
}
hashtable.h
节点
namespace LinkHash
{
enum status
{
EMPTY,
DELETE,
EXIST
};
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};
}
hashtable
namespace LinkHash
{
template<class K,class T,class KeyOfT,class HashFunc>
class HashTable
{
typedef HashNode<T> Node;
template<class K,class T,class Ref,class Ptr,class KeyOfT,class HashFunc>
friend struct __HTIterator;
public:
typedef __HTIterator<K, T, T&, T*, KeyOfT, HashFunc> iterator;
HashTable(){}
HashTable(const HashTable<K, T, KeyOfT, HashFunc>& ht)
{
_table.resize(ht._table.size());
for (size_t i = 0; i < ht._table.size(); i++)
{
Node* cur = ht._table[i];
while (cur)
{
Node* copy = new Node(cur->_data);
copy->_next = _table[i]; //头插
_table[i] = copy;
cur = cur->_next;
}
}
}
~HashTable()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
HashTable<K, T, KeyOfT, HashFunc>& operator=(const HashTable<K, T, KeyOfT, HashFunc>& ht)
{
swap(_n, ht._n);
_table.swap(ht._table);
return *this;
}
iterator find(const K& k)
{
if (_table.empty())
return iterator(nullptr, this);
HashFunc hf;
KeyOfT kot;
size_t index = hf(k) % _table.size();
Node*cur = _table[index];
while (cur)
{
if (kot(cur->_data) == k)
return iterator(cur, this);
else
cur = cur->_next;
}
return end();
}
pair<iterator, bool> insert(const T& date)
{
KeyOfT kot;
iterator ret = find(kot(date));
if (ret != end())
return make_pair(ret, false);
HashFunc hf;
//负载因子等于1的时候扩容
if (_n == _table.size())
{
size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
vector<Node*> NewTable;
NewTable.resize(newSize);
//把原Hash遍历一遍把有的数据拷贝到新的Hash上
for (size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hf(kot(cur->_data)) % NewTable.size();
cur->_next = NewTable[index];
NewTable[index] = cur;
cur = next;
}
_table[i] = nullptr;
}
_table.swap(NewTable);
}
Node* newnode = new Node(date);
//这里的计算如果冲突的话就头插到冲突位置
//没用冲突的话就第一次插入
size_t index = hf(kot(date)) % _table.size();
newnode->_next = _table[index];
_table[index] = newnode;
_n++;
return make_pair(iterator(newnode, this), true);
}
bool erase(const K& k)
{
if (_table.empty())
return false;
HashFunc hf;
size_t index = hf(k) % _table.size();
Node*prev = nullptr;
Node*cur = _table[index];
while (cur)
{
//找到了
if (cur->_kv.first == k)
{
//头删
if (prev == nullptr)
{
_table[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
--_n;
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
iterator begin()
{
for (size_t i = 0; i < _table.size(); i++)
{
if (_table[i])
{
return iterator(_table[i], this);
}
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}
private:
vector<Node*> _table;
size_t _n = 0; //有效个数
};
}
iterator
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable;
//KeyOfT 来分 k/ pair
//HashFunc来分 int /string /自定义类型
template<class K, class T, class Ref, class Ptr, class KeyOfT, class HashFunc>
struct __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T, Ref, Ptr, KeyOfT, HashFunc> Self;
Node* _node;
HashTable<K, T, KeyOfT, HashFunc>* _pht;
//节点的指针,hash表指针
__HTIterator(Node* node, HashTable<K, T, KeyOfT, HashFunc>* pht)
:_node(node)
, _pht(pht)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator==(const Self& s)const
{
return _node == s._node;
}
bool operator!=(const Self& s)const
{
return _node != s._node;
}
Self& operator++()
{
//1.遍历同一条上的桶
if (_node->_next)
{
_node = _node->_next;
}
else
{
//2.同一条都遍历完了
KeyOfT kot;
HashFunc hf;
size_t index = hf(kot(_node->_data)) % _pht->_table.size();
++index;
//3.找下一个不为空的桶
while (index < _pht->_table.size())
{
if (_pht->_table[index])
{
break;
}
else
{
++index;
}
}
//再判断一次是break出来的返回这个节点
if (index == _pht->_table.size())
{
_node = nullptr;
}
else
{
_node = _pht->_table[index];
}
}
return *this;
}
};
unordered_map/set

- unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
- 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部unordered_map没有对<key, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
- 它的迭代器至少是前向迭代器。
unordered_map/set封装hashtable
namespace jt
{
template<class K, class hash = Hash<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename LinkHash::HashTable<K, K, SetKeyOfT, hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> insert(const K& key)
{
return _ht.insert(key);
}
private:
LinkHash::HashTable<K, K, SetKeyOfT, hash> _ht;
};
template<class K, class V, class hash = Hash<K>>
class unordered_map
{
struct MapKeyOfT
{
const K&operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename LinkHash::HashTable<K, pair<K, V>, MapKeyOfT, hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
V& operator[](const K& key)
{
auto ret = _ht.insert(make_pair(key, V()));
return ret.first->second;
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.insert(kv);
}
private:
LinkHash::HashTable<K, pair<K, V>, MapKeyOfT, hash> _ht;
};
}
哈希的应用
位图
位图(Bitset)是一种基于二进制位的数据结构,它通过二进制位的操作实现对大量数据的快速访问、修改和查询。
namespace jt
{
template<size_t N>
//所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。
//比如 比特位: 0000 0000
// 真实数字: 1234 5678
//通常是用来判断某个数据存不存在的
class bitset
{
public:
bitset()
{
_bit.resize(N / 8 + 1, 0); //char为8个字节 +1 开多一个char
}
//置为1
void set(size_t x)
{
size_t i = x / 8; //算出在第几个char
size_t j = x % 8; //算出在char的某个比特位
_bit[i] |= (1 << j);
}
//值为0
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bit[i] &= (~(1 << j)); //_bit[i] &= (0 << j)) error 将整个_bit[i]都清0了
}
//看是0还是1
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return _bit[i] & (1 << j);
}
private:
std::vector<char> _bit;
};
}
位图的应用
- 快速查找某个数据是否在一个集合中:位图可以用来表示一个集合,集合中的每个元素对应位图中的一个或多个位。通过检查对应位的状态(0或1),可以快速判断该元素是否存在于集合中。这种方法在处理大量数据时特别有效,因为它仅需要很少的存储空间(每个元素只占用一个或多个位),并且查询速度非常快。
- 排序:位图法通常不直接用于排序,但它在某些特定的排序场景下可以发挥优势。例如,当数据集非常稠密(即大部分数据都存在于一个较小的范围内)时,可以使用位图来记录每个值是否出现过,然后按照位图的顺序输出出现过的值,从而达到排序的目的。这种方法对于内存消耗较少且速度较快,但仅适用于特定情况。
- 求两个集合的交集、并集等:对于两个集合,可以将其分别映射到两个位图中。求交集时,只需将两个位图进行按位与操作,结果为1的位表示该元素在两个集合中都存在;求并集时,只需将两个位图进行按位或操作,结果为1的位表示该元素至少在一个集合中存在。这种方法可以高效地计算两个集合的交集和并集。
- 操作系统中磁盘块标记:位图在操作系统中用于标记磁盘块的使用情况。每个磁盘块对应位图中的一个位,0表示该磁盘块为空闲状态,1表示该磁盘块已被分配并正在使用。通过检查位图中对应位的状态,操作系统可以快速找到空闲的磁盘块进行写入操作,从而实现对磁盘空间的高效管理。此外,位图还可以用于存储空间的分配和回收,确保磁盘空间得到合理利用。
//给定100亿个整数,设计算法找到只出现一次的整数
//用2个位图 出现一次为00 两次为01 两次及两次以上用10
//2个位图可以表示 2^2=4种状
template<size_t N>
class two_bitset
{
public:
void set(size_t x)
{
//00--->01
if (!_bit1.test(x) && !_bit2.test(x))
{
_bit2.set(x);
}
//01--->10
else if (!_bit1.test(x) && _bit2.test(x))
{
_bit1.set(x);
_bit2.reset(x);
}
//2个及2个以上的不处理
}
//找出只出现一次的数
void PrintOnly()
{
for (size_t i = 0; i < N; i++)
{
if (!_bit1.test(i) && _bit2.test(i))
{
cout << i << endl;
}
}
}
private:
jt::bitset<N> _bit1;
jt::bitset<N> _bit2;
};
void test_twobitset()
{
two_bitset<100> tbs;
int a[] = { 1, 2, 3, 4, 5, 2, 3, 4, 5,1,10,12,99};
for (auto e : a)
{
tbs.set(e);
}
tbs.PrintOnly();
}
布隆过滤器
布隆过滤器(Bloom Filter)是一种高效的空间利用型概率数据结构,用于快速判断一个元素是否存在于一个集合中。它的主要特点是查询速度快、空间占用小,但存在一定的误判率。布隆过滤器由布隆在1970年提出,并在许多领域得到了广泛应用,如网页URL去重、垃圾邮件判别、集合重复元素判别等。
布隆过滤器主要由两部分组成:一个二进制向量(位数组)和一系列随机映射函数(哈希函数)。位数组中的所有位都初始化为0。当需要插入一个元素时,该元素通过多个哈希函数映射到位数组中的多个位置,并将这些位置上的位设置为1。当需要查询一个元素是否存在于集合中时,同样使用这些哈希函数找到对应的位,并检查这些位是否都为1。如果所有位都为1,则认为该元素可能在集合中(有误判可能);如果有任何一位为0,则确定该元素不在集合中。
哈希函数
//用多个哈希函数,将一个数据映射到位图结构中
//判断不在是准确的
struct BKDRHash
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (size_t i= 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
BloomFilter.h
//映射几个位置放多少个HashFunc1,我这里映射3个
template<size_t N, class K = string, class HashFunc1 = BKDRHash, class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
class BloomFilter
{
public:
void Set(const K& key)
{
size_t len = 4 * N;
size_t index1 = HashFunc1()(key) % len;
size_t index2 = HashFunc2()(key) % len;
size_t index3 = HashFunc3()(key) % len;
_bs.set(index1);
_bs.set(index2);
_bs.set(index3);
}
bool Test(const K& key)
{
size_t len = 4 * N;
size_t index1 = HashFunc1()(key) % len;
size_t index2 = HashFunc2()(key) % len;
size_t index3 = HashFunc3()(key) % len;
if (_bs.test(index1) == false)
return false;
if (_bs.test(index2) == false)
return false;
if (_bs.test(index3) == false)
return false;
return true;
}
private:
//封装个位图
bitset<4 * N> _bs;
};
void TestBloomFilter()
{
BloomFilter<100> bf;
bf.Set("张三");
bf.Set("李四");
bf.Set("牛魔王");
bf.Set("红孩儿");
bf.Set("eat");
cout << bf.Test("张三") << endl;
cout << bf.Test("李四") << endl;
cout << bf.Test("牛魔王") << endl;
cout << bf.Test("红孩儿") << endl;
cout << bf.Test("孙悟空") << endl;
cout << bf.Test("二郎神") << endl;
cout << bf.Test("猪八戒") << endl;
cout << bf.Test("ate") << endl;
}
布隆过滤器优缺点
优点:
- 空间效率高:相比于传统的链表、树等数据结构,布隆过滤器在存储空间和查询时间上都有很大的优势。
- 查询速度快:查询时间复杂度为O(k),其中k为哈希函数的个数,通常较小。
- 无需存储元素本身:在某些对保密要求较高的场合,布隆过滤器有很大的优势。
- 支持交、并、差运算:使用同一组哈希函数的布隆过滤器可以方便地进行集合运算。
缺点
- 误判率:布隆过滤器存在误判的可能性,即有可能将一个不存在的元素误认为在集合中。
- 一般不支持删除操作:由于位数组被多个元素共享,删除某个元素会影响其他元素的判断结果。
- 无法获取元素本身:布隆过滤器只能判断元素是否存在于集合中,无法获取元素本身的值。
海量数据处理
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 如何找到top K的IP?如何直接用Linux系统命令实现?
将100G的大文件分成500份,根据同一个哈希函数HashFunc将ip映射到向对应的文件(每个文件的大小可以在内存中处理)中,相同的ip一定会被放在同一个文件中。找出出现次数最多的ip直接遍历500个小文件就可以。如果需要找出topk,则需要以每个小文件中出现次数最多的ip建成一个最小堆,从而确定topK
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
2个文件用相同的hash函数映射到一个个小文件中,如果存在交集,那么2个文件相同的部分会映射到同一个小文件。求出相交小文件的个数就可以。
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
精确算法:
分治策略
- 将每个大文件分割成多个小文件,使得每个小文件都可以装入内存。
- 读取第一个大文件的一个小文件到内存中,然后遍历第二个大文件的所有小文件,在内存中查找交集,并将结果写入到输出文件中。
- 重复上述步骤,直到第一个大文件的所有小文件都被处理。
- 交换两个大文件的角色,并重复上述过程,但这次使用第一个大文件的交集结果来过滤第二个大文件的小文件,以避免重复计算。
近似算法
- 读取第一个文件的所有query,并使用这些query来填充布隆过滤器。由于内存限制,布隆过滤器可能会有一些误报率(即,它可能会错误地认为一个不在集合中的元素在集合中)。
- 遍历第二个文件的所有query,并检查它们是否在布隆过滤器中。如果在,则它可能是交集中的一部分。
哈希与加密
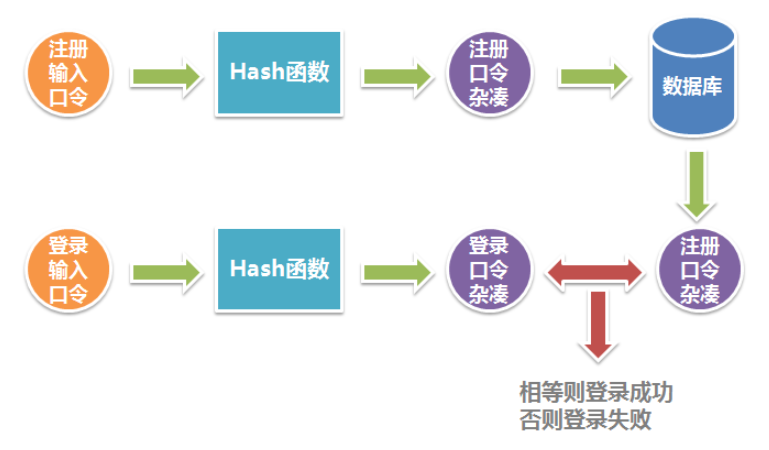
哈希与加密在现代工程领域应用非常广泛,在计算机领域也发挥了很大作用,这里我们仅仅讨论在平常的软件开发中最常见的应用——数据保护。
所谓数据保护,是指在数据库被非法访问的情况下,保护敏感数据不被非法访问者直接获取。这是非常有现实意义的,试想一个公司的安保系统数据库服务器被入侵,入侵者获得了所有数据库数据的查看权限,如果管理员的口令(Password)被明文保存在数据库中,则入侵者可以进入安保系统,将整个公司的安保设施关闭,或者删除安保系统中所有的信息,这是非常严重的后果。
但是,如果口令经过良好的哈希或加密,使得入侵者无法获得口令明文,那么最多的损失只是被入侵者看到了数据库中的数据,而入侵者无法使用管理员身份进入安保系统作恶。