Elasticsearch入门基础和集群部署
- 简介
- 基础概念
- 索引(Index)
- 类型(Type)(逐步弃用)
- 文档(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shard)
- 副分片(Replica)
- 集群和节点(Cluster&Node)
- DSL(Domain Specific Language,领域特定语言)
- 请求过程
- 对比关系型数据库
- 部署安装
- 单机部署
- 集群部署
简介
ElasticSearch 是一个开源的 分布式、支持RESTful 搜索和分析引擎,可以用来解决使用数据库进行模糊搜索时存在的性能问题,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
ElasticSearch 使用 Java 语言开发,基于 Lucene。ES 早期版本需要 JDK,在 7.X 版本后已经集成了 JDK,已无需第三方依赖。
结构图:
基础概念
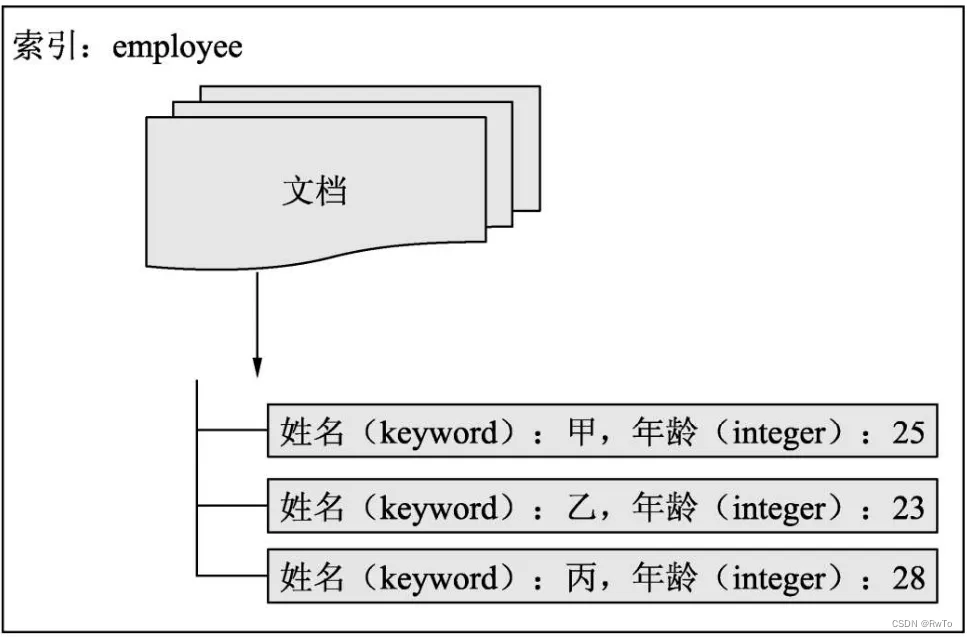
索引(Index)
等价于关系型数据库中的数据库
存储文档信息,是一系列文档的集合。
类型(Type)(逐步弃用)
为了与 关系数据库中的 表 对应
ES设计之初,每个文档都存储在一个索引中,并分配了一个映射类型。
然而,
关系型数据库中的表是独立存储的,不同的表字段相互独立,互不干扰。而ES中同一个Index中的不同Type是存储于同一个索引文件(Lucene索引文件)中的。
因此同一个Index中 不同Type中 相同名字的 字段的映射(Mapping)必须相同。
同时 不同类型的字段存储于同一个索引中,会造成数据稀疏,影响Lucene压缩文档的能力。
所以 ES自6.0 开始,Type被逐步弃用,7.0开始一个索引只能创建一个Type: _doc 。8.0之后,Type被完全删除。
官方解释:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/removal-of-types.html
文档(Document)
相当于关系型数据库中的表记录(行)。
ES的文档可以有一个或多个字段,每个字段可以是各种类型,是用户操作的最小单位。
ES中文档自带版本的概念,初始版本为1,每次写操作都会使版本号+1。
(ES不支持事务,版本号机制用来实现乐观锁,以此来保证数据的一致性)
每次查询文档,ES返回用户最新版本的文档。
字段(Field)
相当于关系型数据库中的 表字段。
一个文档可以包含一个或多个字段,每个字段都有一个类型与之对应。
ES提供了多种数据类型,常用的有:字符串,文本,数值。同时还提高数组,经纬度,IP地址等类型。
对于不同的类型,ES支持不同的搜索功能,例如:对于文本类型ES可以按照某种分词方式对数据进行搜索。并可以设定打分因子来影响最终的排序。
下图为索引,文档,字段之间的关系。
映射(Mapping)
相当于关系型数据库中的表结构。
建立索引时需要定义文档的数据结构,这个结构叫做映射。
在映射中,文档的字段类型一旦设定后就不能更改,因为字段类型定义后,ES已经针对定义的类型建立了特定的索引结构(倒排索引),这种结构不能更改。
ES提供了自动映射功能,即在添加数据时,如果该字段没有定义类型,ES会更加用户提供的字段的真实数据猜测可能的类型,从而自动进行定义。
分片(Shard)
Index 被分为多个碎片存储在不同的Node节点上的分片中,以此来提高性能和吞吐量。
为了实现ES集群,需要将数据切分,并存储到不同的计算机中。
在ES中,一个分片对应一个Lucene索引,每个分片可以设置多个副分片,当主分片发生故障,副分片会充当主分片继续工作。
索引的分片个数只能设置一次,之后不能更改。(因为路由规则的限制,下面有介绍)
默认情况下,ES 6.X 每个索引有5个主分片,1个副分片,ES 7.X 每个索引有 1个主分片 ,1个副分片
副分片(Replica)
每个分片可以设置多个副分片,当主分片发生故障,副分片会充当主分片继续工作。
在一个索引中,副分片是没有限制的,用户可以按需设置。
默认情况下,ES默认副分片数为1。副分片数是可以修改的。
一个分片的主分片和副分片分别存储于不同的节点上。
ES不允许Primary和它的Replica放在同一个节点中,
并且同一个节点不接受完全相同的两个Replica
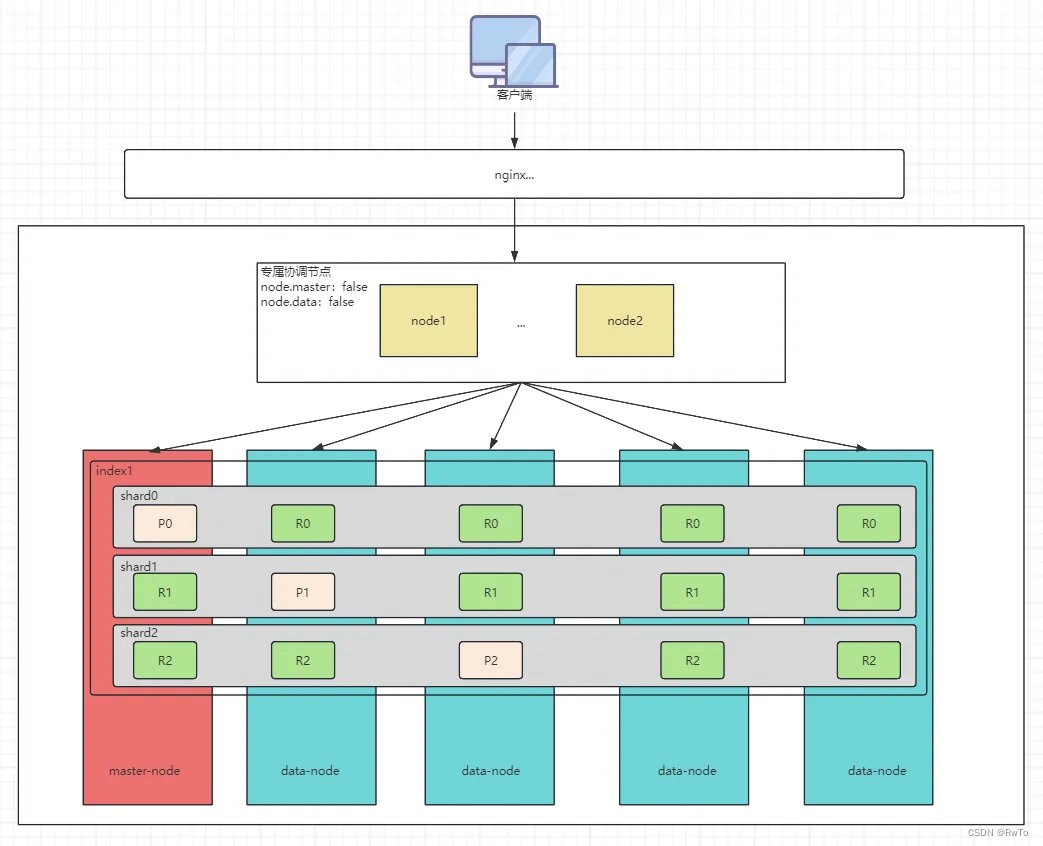
集群,节点,分片,副分片的关系 见 下图
某个索引设置了三个分片,编号分别为0,1,2。P代表主分片,R代表副分片

集群和节点(Cluster&Node)
一个节点等价于一个ES实例。
ES节点分为三类:
- master 节点:
集群中的一个节点会被选为 master 节点,负责管理集群范畴的变更
例如创建或删除索引,添加节点到集群或从集群删除节点。
master 节点无需参与文档层面的变更和搜索,这意味着仅有一个 master 节点并不会因流量增长而成为瓶颈。
配置node.master 为 true(默认)的节点都可能成为master节点。
- data 节点:
持有数据和倒排索引,操作文档数据,对内存和IO消耗较大。
每个节点都可通过配置文件中的 node.data 属性为 true (默认)成为数据节点。
- 协调 节点:
协调节点负责将请求转发给其他节点,并最终将结果汇总给客户端。
默认情况下,任意节点都可以是协调节点。
它的生命周期是一个单独的ES请求。也就是说,当客户端向集群中某个节点发送请求后,这个节点就是当前请求的协调节点,当请求结束后,协调节点的生命周期也结束。
为了 降低集群的负载,可以设置某些节点为单独的协调节点。
将 node.master 属性和 node.data 属性全部设置为 false,那么该节点就是一个协调节点,扮演一个负载均衡的角色,只负责将到来的请求路由到集群中的各个节点。如下图

多个节点构成一个ES集群,这些节点在同一个网络内,集群名字需要相同。
在分布式系统中,为了完成海量数据的存储和计算,同时提高系统的高可用,需要多台计算机集成在一起协作,这种形式成为集群。目的是解决单台计算机存储和性能的瓶颈。
DSL(Domain Specific Language,领域特定语言)
DSL是在特定领域执行特定任务的语言,例如:HTML,CSS,DSL。
ES中的DSL使用JSON进行表达。简单明了,同时屏蔽了各种编程语言之间数据通信的差异。
请求过程
协调节点内部会维护一份分片-节点路由表,记录着分片和节点的对应关系。
当客户端将请求发送到协调节点后,ES经过路由算法,找到对应的主分片序号,根据分片-节点路由表找到对应的节点,执行相应的任务
- 读请求:使用随机轮询算法,从主/副分片中 选择一个 进行数据读取。(增加副分片可以提高读请求的吞吐量)
- 写请求:主分片处理写请求,同时将请求同步给副分片,所有分片都写成功后,返回请求给客户端。(副分片越多,写入越慢)
路由算法:
shard=hash(routing) % number_of_primary_shards
路由公式参数说明:
shard:最终选择分片序号
routing:路由ID,不指定则为文档ID
number_of_primary_shards:主分片数量
上述公式中,对主分片数量取余,所以主分片数量确定后,就不能修改,否则会导致数据找不到
对比关系型数据库
-
索引方式:
关系型数据库大多使用B+树,ES使用倒排索引。
倒排索引:ES在数据分词后 记录每个词 对应的文档id。

-
事务:
ES不支持事务。ES在更新文档时,先读取文档再进行修改,然后再为文档重建索引。
ES使用乐观锁解决并发问题。每次更新先增加文档版本号,增加成功才进行下一步操作。 -
SQL 和 DSL
DSL 可以支持更复杂的查询 -
扩展
关系型数据库的扩展,需要借助第三方组件进行分库分表。
ES本身就支持分片集群。 -
查询速度和实时性
ES基于倒排索引实现,对于模糊查询明显快于关系型数据库
ES在内存和磁盘之间有一层系统缓存。ES写入数据后,会先存储在内存中,此时数据还不能被搜索到,内存中每隔一段时间(默认1s)刷新到系统缓存,此时才能被搜索到,因此ES的写入是准实时的。
部署安装
官网下载:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-10-2
出于安全性考虑,ES不允许root账户启动,应该创建其他账户启动ES
# 增加组
groupadd es
# 创建用户es 并将用户添加到es组
useradd es -g es
# 设置密码
passwd es
# 切换用户
su es
# 上传es压缩包并解压
tar -zxvf elasticsearch-7.10.2-linux-x86_64.tar.gz
# 如果提示缺少权限的使用chmod 添加相应权限
解压后各目录见下图:

单机部署
ES进程比较吃内存,默认占用内存为1G。如果机器内存较小,可以修改config/jvm.options的配置文件
修改其中的-Xms 和-Xmx参数
vim config/jvm.options
-Xms256m
-Xmx256m
修改完成后,执行bin目录下elasticsearch命令即可启动ES。
# 前台启动
./elasticsearch
# 后台启动
./elasticsearch -d
ES启动完成后,在安装目录下会多一个data目录,用于存放索引数据文件
使用 curl 127.0.0.1:9200验证是否启动完成

自此便完成了ES的单机部署。
集群部署
这里使用一台计算机部署伪集群,实际效果和集群相同。
# 若部署多台计算机实例的,可以省略下面步骤
# 创建集群目录
mkdir -p es-cluster/es0
mkdir -p es-cluster/es1
mkdir -p es-cluster/es2
# 复制配置文件到 集群配置目录下
cp -r elasticsearch-7.10.2/* es-cluster/es0/
cp -r elasticsearch-7.10.2/* es-cluster/es1/
cp -r elasticsearch-7.10.2/* es-cluster/es2/
分别修改各节点配置文件 config/elasticsearch.yml
es0
# 集群名称,同一个集群要求集群名称相同
cluster.name: es-cluster
# 节点名称,同一集群不同实例名称不能相同
node.name: es0
# 指定该节点是否存储索引数据,默认为true。
node.data: true
# 指定该节点是否有资格被选举成为node 默认是true
node.master: true
# 数据存储位置
path.data: /opt/work/es-cluster/es0/data
# 日志存储位置
path.logs: /opt/work/es-cluster/es0/logs
# 锁定物理内存,防止操作系统将内存交换到磁盘上
bootstrap.memory_lock: true
# 网络访问的IP
network.host: 127.0.0.1
# HTTP访问的端口
http.port: 9200
# 集群内部通信的端口
transport.tcp.port: 9300
# 当节点启动时,传递一个初始主机列表来执行发现
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
# 写入候选主节点的设备地址,来开启服务时就可以被选为主节点
cluster.initial_master_nodes: ["es0", "es1", "es2"]
es1
cluster.name: es-cluster
node.name: es1
node.data: true
node.master: true
path.data: /opt/work/es-cluster/es1/data
path.logs: /opt/work/es-cluster/es1/logs
bootstrap.memory_lock: true
network.host: 127.0.0.1
http.port: 9201
transport.tcp.port: 9301
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
cluster.initial_master_nodes: ["es0", "es1", "es2"]
es2
cluster.name: es-cluster
node.name: es2
node.data: true
node.master: true
path.data: /opt/work/es-cluster/es2/data
path.logs: /opt/work/es-cluster/es2/logs
bootstrap.memory_lock: true
network.host: 127.0.0.1
http.port: 9202
transport.tcp.port: 9302
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
cluster.initial_master_nodes: ["es0", "es1", "es2"]
启动集群
# 分别启动三台ES实例
./elasticsearch -d
特别提醒:如果之前使用单机启动过,记得删除已经生成的data/目录
启动成功后,使用 curl http://127.0.0.1:9200/_cat/nodes?v 命令查看节点信息

自此ES集群搭建成功