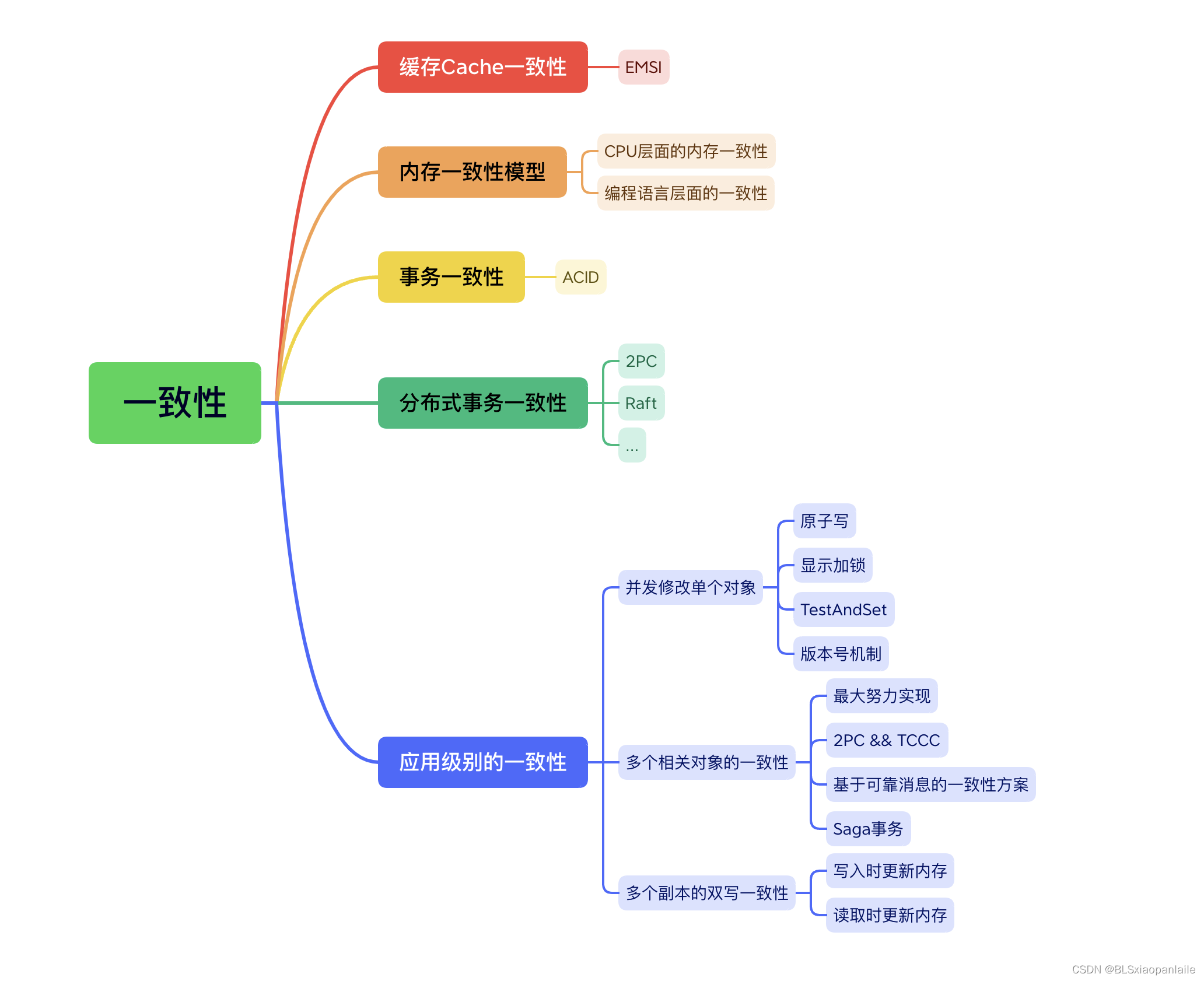
智慧之网:深度探索关系型数据库的数学奥秘与实战技艺

1. 引言
1.1 数据时代的基石
在数字化的浪潮中,数据已成为新时代的石油,而关系型数据库则是这座数据矿藏的精炼厂。自E.F. Codd在1970年提出关系模型以来,关系型数据库以其坚实的数学基础和高效的数据处理能力,稳坐数据管理领域的王座。它们不仅支撑着金融交易、电子商务等关键业务,还在大数据、云计算等新兴技术中扮演着核心角色。
关系型数据库的核心在于其结构化数据存储和操作的能力。在数学的视角下,一个关系可以被视为一个二维表,其中每一行是一个元组(tuple),每一列是一个属性(attribute)。这种结构化的数据模型,使得数据的查询、插入、更新和删除操作变得高效而直观。
1.2 数学的智慧
关系型数据库的设计与操作,无处不体现着数学的智慧。从集合论到代数,从逻辑学到图论,数学理论为数据库提供了坚实的理论基础。例如,关系代数为SQL语言提供了理论支撑,使得复杂的查询可以通过一系列代数操作来实现。函数依赖理论则指导着数据库的规范化设计,确保数据的一致性和完整性。
数学公式在这里扮演着至关重要的角色。例如,关系代数中的选择操作(σ)可以用数学公式表示为:
σ P ( R ) = { t ∈ R ∣ P ( t ) } \sigma_{P}(R) = \{t \in R \mid P(t)\} σP(R)={t∈R∣P(t)}
其中, R R R 是一个关系, t t t 是关系中的一个元组, P P P 是一个谓词,用于选择满足条件的元组。
1.3 探索之旅
本篇博客将带领读者踏上一场深入关系型数据库数学奥秘的探索之旅。我们将从关系模型的集合论基础出发,深入探讨函数依赖的逻辑网络,解析ACID原则的数学保障,以及SQL语言与关系代数的交响曲。我们将通过实例代码和可视化图表,将抽象的数学理论转化为具体的实战技艺。
在接下来的章节中,我们将逐步揭开关系型数据库的神秘面纱,展示数学理论如何与数据库技术交织融合,共同构建起这座智慧之网。让我们一起,从数学的角度,重新认识和理解关系型数据库,探索其在现代数据管理中的无限可能。

2. 关系型数据库的理论与数学基石
2.1 关系模型的集合论之根
在关系型数据库的宏伟殿堂中,集合论是其坚实的基石。关系模型,作为数据库理论的瑰宝,其核心概念——关系、属性、元组和键,无不深深植根于集合论的沃土之中。
关系:数据的集合
在集合论的视角下,一个关系(Relation)可以被视为一个集合,其元素是元组(Tuple)。每个元组由一组有序的属性(Attribute)值组成,这些属性定义了关系的结构。关系可以表示为:
R = { t 1 , t 2 , . . . , t n } R = \{t_1, t_2, ..., t_n\} R={t1,t2,...,tn}
其中, R R R 是关系名, t i t_i ti 是第 i i i 个元组。每个元组 t i t_i ti 可以表示为:
t i = { a i 1 , a i 2 , . . . , a i m } t_i = \{a_{i1}, a_{i2}, ..., a_{im}\} ti={ai1,ai2,...,aim}
其中, a i j a_{ij} aij 是元组 t i t_i ti 的第 j j j 个属性值。
属性:数据的维度
属性定义了关系的维度,它们是数据的基本描述符。在数学上,属性可以被视为一个映射,将每个元组映射到其对应的属性值。例如,在一个学生关系中,属性可能包括“学号”、“姓名”、“年龄”等。
元组:数据的实例
元组是关系中的具体数据实例,它们是属性的具体化。在集合论中,元组可以被视为有序对的扩展,其中每个元素对应一个属性。例如,一个学生元组可能是:
t = { 学号 : 123456 , 姓名 : 张三 , 年龄 : 20 } t = \{\text{学号}: 123456, \text{姓名}: \text{张三}, \text{年龄}: 20\} t={学号:123456,姓名:张三,年龄:20}
键:数据的标识
键(Key)是关系中用于唯一标识元组的属性或属性组合。在集合论中,键可以被视为一个特殊的谓词,它定义了元组集合上的一个等价关系。例如,“学号”属性可能被定义为学生关系的主键,因为它能够唯一标识每个学生。
实例:学生信息系统
考虑一个简单的学生信息系统,其中包含一个名为“Students”的关系。该关系可能包含以下属性:“学号”、“姓名”、“年龄”、“专业”。一个可能的元组集合如下:
Students = { { 学号 : 123456 , 姓名 : 张三 , 年龄 : 20 , 专业 : 计算机科学 } , { 学号 : 234567 , 姓名 : 李四 , 年龄 : 21 , 专业 : 数学 } , . . . } \text{Students} = \{ \{\text{学号}: 123456, \text{姓名}: \text{张三}, \text{年龄}: 20, \text{专业}: \text{计算机科学}\}, \{\text{学号}: 234567, \text{姓名}: \text{李四}, \text{年龄}: 21, \text{专业}: \text{数学}\}, ... \} Students={{学号:123456,姓名:张三,年龄:20,专业:计算机科学},{学号:234567,姓名:李四,年龄:21,专业:数学},...}
在这个例子中,“学号”属性被定义为主键,因为它确保了每个元组的唯一性。
数学公式的推导
在关系模型中,我们可以通过集合论的运算来推导出各种数据库操作。例如,选择操作(Selection)可以表示为:
σ P ( R ) = { t ∈ R ∣ P ( t ) } \sigma_{P}(R) = \{t \in R \mid P(t)\} σP(R)={t∈R∣P(t)}
其中, P P P 是一个谓词,用于选择满足特定条件的元组。这个操作可以看作是在关系 R R R 上应用一个过滤器,只保留满足谓词 P P P 的元组。
小结
关系模型的集合论基础为我们提供了一个强大的框架,用于理解和操作数据库中的数据。通过深入理解关系、属性、元组和键的集合论本质,我们能够更加精确地设计和管理数据库系统,确保数据的完整性和一致性。在接下来的章节中,我们将继续探索关系型数据库的数学奥秘,揭示函数依赖、ACID原则以及SQL语言与关系代数的交响曲。让我们继续这场智慧的探索之旅,深入数学的海洋,挖掘数据库技术的无限潜能。
2.2 函数依赖的逻辑之网
在关系型数据库的宏伟蓝图中,函数依赖犹如一张精密的逻辑之网,它定义了数据之间的内在联系,是数据库设计中不可或缺的理论基石。函数依赖的精确定义及其在数据库设计中的应用,是我们今天要深入探讨的主题。
2.2.1 函数依赖的定义
函数依赖(Functional Dependency,FD)是关系模式中属性之间的一种约束关系,它描述了当给定一个属性的值时,另一个属性的值是如何被唯一确定的。数学上,我们可以用以下方式来表达函数依赖:
X → Y X \rightarrow Y X→Y
其中, X X X 和 Y Y Y 是关系模式中的属性集。这个表达式读作“ X X X 函数决定 Y Y Y”或“ Y Y Y 函数依赖于 X X X”。它意味着在任何时刻,对于关系中的任意两个元组,如果它们在属性集 X X X 上的值相等,那么它们在属性集 Y Y Y 上的值也必须相等。
2.2.2 函数依赖的应用
函数依赖在数据库设计中扮演着至关重要的角色。它不仅是规范化理论的核心,也是确保数据一致性和减少冗余的关键。通过识别和分析函数依赖,我们可以设计出更加合理和高效的数据库结构。
例如,考虑一个简单的学生选课关系模式,包含属性:学生ID(StudentID)、课程ID(CourseID)、教师ID(TeacherID)。在这个模式中,我们可以识别出以下函数依赖:
- 学生ID → \rightarrow → 学生姓名(StudentName)
- 课程ID → \rightarrow → 课程名称(CourseName)
- 教师ID → \rightarrow → 教师姓名(TeacherName)
这些函数依赖表明,学生的姓名由其ID唯一确定,课程的名称由其ID唯一确定,教师的姓名由其ID唯一确定。这样的设计避免了在多个元组中重复存储相同的信息,从而减少了数据冗余。
2.2.3 函数依赖的推理规则
函数依赖的推理规则是分析和验证函数依赖的重要工具。最著名的推理规则集是阿姆斯特朗公理(Armstrong’s axioms),它包括自反律、增广律和传递律:
- 自反律(Reflexivity):如果 Y ⊆ X Y \subseteq X Y⊆X,则 X → Y X \rightarrow Y X→Y。
- 增广律(Augmentation):如果 X → Y X \rightarrow Y X→Y,则 X Z → Y Z XZ \rightarrow YZ XZ→YZ。
- 传递律(Transitivity):如果 X → Y X \rightarrow Y X→Y 且 Y → Z Y \rightarrow Z Y→Z,则 X → Z X \rightarrow Z X→Z。
这些规则构成了函数依赖推理的基础,通过这些规则,我们可以从已知的函数依赖推导出新的函数依赖,从而更全面地理解数据之间的依赖关系。
2.2.4 函数依赖与规范化
规范化理论是基于函数依赖的数据库设计方法论。它通过一系列的范式(Normal Forms, NF)来指导我们如何组织关系模式,以减少数据冗余和提高数据一致性。从第一范式(1NF)到第五范式(5NF),每一级范式都对应着不同的函数依赖要求。
例如,第二范式(2NF)要求非键属性完全函数依赖于主键。这意味着如果一个关系模式的主键由多个属性组成,那么任何非键属性都不能只依赖于主键的一部分。通过将不符合2NF的关系模式分解为符合2NF的子模式,我们可以消除部分函数依赖,从而减少数据冗余。
2.2.5 小结
函数依赖是关系型数据库理论中的一个核心概念,它不仅定义了数据之间的逻辑关系,也为数据库设计提供了理论指导。通过深入理解函数依赖及其在数据库设计中的应用,我们可以构建出更加健壮、高效和易于维护的数据库系统。在接下来的章节中,我们将继续探讨函数依赖在规范化理论中的应用,以及如何通过SQL语言实现这些理论在实践中的应用。让我们一起深入这张逻辑之网,探索数据库设计的无限可能。
2.3 ACID原则的数学保障
在关系型数据库的世界里,ACID原则是确保数据完整性和系统稳定性的基石。ACID,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),这四个特性构成了事务处理的黄金标准。下面,我们将深入探讨这些原则背后的数学原理与实现。
原子性(Atomicity)
原子性要求事务被视为不可分割的最小工作单元,事务中的所有操作要么全部完成,要么全部不完成,不会停滞在中间某个环节。在数学上,我们可以将原子性类比于集合论中的“全集”概念,即一个事务要么是全集,包含所有操作,要么是空集,不包含任何操作。
在数据库系统中,原子性的实现通常依赖于日志记录(logging)和恢复机制(recovery mechanisms)。例如,使用预写式日志(Write-Ahead Logging, WAL)来确保在事务提交之前,其所有变更都被记录在日志中,这样即使在系统崩溃后,也能通过日志恢复到事务开始前的状态。
一致性(Consistency)
一致性确保事务将数据库从一个一致状态转换到另一个一致状态。这意味着事务的执行不会违反任何数据完整性约束。在数学上,一致性可以看作是数据库状态转换的等价关系,即事务执行前后的状态在逻辑上是等价的。
一致性的实现依赖于数据库的约束(constraints)和触发器(triggers)。例如,通过定义主键、外键、唯一性约束等,数据库系统可以在事务执行过程中自动检查并维护数据的一致性。
隔离性(Isolation)
隔离性要求并发执行的事务之间相互隔离,每个事务都感觉不到其他事务的存在。在数学上,隔离性可以类比于集合的互斥性,即每个事务的操作集合与其他事务的操作集合是不相交的。
隔离性的实现通常通过锁(locking)和多版本并发控制(Multi-Version Concurrency Control, MVCC)等机制来实现。例如,数据库系统可以在事务开始时对所需资源加锁,确保其他事务不能同时修改这些资源,从而实现隔离性。
持久性(Durability)
持久性保证一旦事务被提交,其结果将永久保存在数据库中,即使系统崩溃也不会丢失。在数学上,持久性可以看作是数据库状态的不可逆性,即一旦事务提交,其状态变化就是永久性的。
持久性的实现依赖于持久化存储设备(如硬盘)和日志记录。例如,数据库系统会将事务的变更和提交记录写入到非易失性存储中,确保即使在系统故障后,这些信息也不会丢失。
在实际应用中,ACID原则的实现往往需要权衡性能和复杂性。例如,为了提高并发性能,数据库系统可能会采用更复杂的隔离级别,如可串行化(Serializable)、可重复读(Repeatable Read)等,这些隔离级别在数学上对应于不同的并发控制模型。
通过上述分析,我们可以看到ACID原则不仅仅是数据库设计的规范,它们背后蕴含着深刻的数学原理。这些原理通过各种数据库技术和算法得以实现,确保了数据库系统的稳定性和可靠性。在接下来的章节中,我们将继续探讨SQL语言与关系代数的交响曲,以及更多关系型数据库设计的数学模型。
2.4 SQL语言与关系代数的交响曲
结构化查询语言(SQL)是关系型数据库的主要接口,能够实现数据的查询、插入、更新和删除等操作。关系代数是描述和处理关系的一种数学工具,是关系型数据库理论的基石。在本节,我们将探索SQL语言的发展与核心结构,及其与关系代数的紧密联系。
2.4.1 SQL的基本结构
SQL语言的核心结构可以被分解为几个主要部分:数据定义语言(DDL)、数据操作语言(DML)、数据控制语言(DCL)和事务控制语言(TCL)。这四者共同构成了SQL语言的基础,使得我们能够通过命令行或者图形界面与数据库进行交互。
2.4.2 SQL与关系代数的交集
SQL语言的设计理念强烈地受到了关系代数的影响。在关系代数中,我们用基本操作如并集、交集和差集来处理关系。这些基本操作在SQL中同样存在,它们分别对应于SQL的UNION、INTERSECT和EXCEPT操作。
同样,关系代数的投影和选择操作也在SQL中有对应的实现。在SQL中,我们使用SELECT语句对属性进行投影操作,并使用WHERE子句实现选择操作。例如,我们可以使用以下SQL语句查询所有年龄大于30岁的员工的姓名:
SELECT name
FROM Employee
WHERE age > 30;
在这个示例中,SELECT name对应于关系代数的投影操作,WHERE age > 30对应于关系代数的选择操作。
2.4.3 SQL的进阶工具:连接操作
SQL提供了多种连接操作,使得我们能够在单个查询中处理多个关系。这些连接操作的数学基础同样源于关系代数。
例如,笛卡尔积操作是关系代数的基本操作之一。它将两个关系的所有可能的元组组合起来。在SQL中,我们可以使用CROSS JOIN操作来计算两个表的笛卡尔积。
同时,SQL还提供了多种更高级的连接操作,如内连接(INNER JOIN)、左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)和全外连接(FULL OUTER JOIN)。这些连接操作的数学基础是关系代数的自然连接、左外连接、右外连接和全外连接操作。
2.4.4 SQL与关系代数的同构理论
SQL语言和关系代数之间的联系并不仅限于它们的操作有一一对应的关系。更深入地说,任何一个SQL查询都可以被转换为一系列关系代数操作的组合,反之亦然。这意味着SQL语言和关系代数在本质上是同构的。
这个同构性不仅能够帮助我们理解SQL语言的内部工作原理,也能够指导我们写出更高效的SQL查询。因为关系代数操作的组合可以被数据库管理系统优化为一个执行计划,这个执行计划决定了查询的执行效率。通过理解SQL语言和关系代数的同构性,我们可以将复杂的SQL查询分解为一系列关系代数操作,然后优化这些操作的组合,从而提高查询的执行效率。
2.4.5 数学在SQL中的应用
在SQL语言中广泛使用了许多数学概念,包括但不限于集合论、逻辑运算、关系代数和事务理论。这些数学知识为我们提供了在数据管理领域解决问题的强大工具。
例如,在SQL中,我们经常需要使用到集合论的知识。SQL中的每个表都可以看作是一个集合,表中的每一行就是集合中的一个元素。通过使用集合运算,我们可以进行复杂的查询操作,如求并集、交集、差集等。
同样,逻辑运算也在SQL中起着非常重要的作用。在SQL中,我们可以使用逻辑运算符(如AND、OR和NOT)来组合或否定条件,从而实现更复杂的查询。
总的来说,数学在SQL语言中的应用是无处不在的,通过深入理解这些数学知识,我们可以更好地理解和使用SQL语言,从而更有效地处理和分析数据。

3. SQL语言的实战演练与数学应用
3.1 查询的艺术:SELECT语句的精妙运用与关系代数的对应关系
在关系型数据库的世界里,SELECT语句是查询的灵魂,它不仅仅是一系列命令的组合,更是一门艺术,一门将数据从关系表中提取出来的艺术。SELECT语句的精妙之处在于它与关系代数的紧密对应,这种对应关系使得我们可以用数学的严谨性来指导和优化我们的查询。
首先,让我们回顾一下关系代数的基本操作:
-
选择(Selection):用数学符号表示为σ条件®,其中σ代表选择操作,条件是一个逻辑表达式,R是关系表。选择操作返回满足条件的元组集合。
-
投影(Projection):用数学符号表示为π属性列表®,其中π代表投影操作,属性列表是需要提取的属性名,R是关系表。投影操作返回指定属性的元组集合。
-
联接(Join):用数学符号表示为⋈条件(R1, R2),其中⋈代表联接操作,条件是联接条件,R1和R2是关系表。联接操作返回两个表中满足联接条件的元组集合。
现在,让我们看看这些操作是如何在SQL的SELECT语句中体现的:
-
选择操作:在SQL中,我们可以通过WHERE子句来实现选择操作。例如,如果我们有一个名为
Employees的表,我们可以使用以下SQL语句来选择所有年龄大于30的员工:SELECT * FROM Employees WHERE Age > 30;这对应于关系代数中的σAge > 30(Employees)。
-
投影操作:在SQL中,我们可以通过指定列名来实现投影操作。例如,如果我们只对员工的姓名和工资感兴趣,我们可以使用以下SQL语句:
SELECT Name, Salary FROM Employees;这对应于关系代数中的πName, Salary(Employees)。
-
联接操作:在SQL中,我们可以通过JOIN子句来实现联接操作。例如,如果我们有两个表
Employees和Departments,我们可以使用以下SQL语句来联接这两个表:SELECT * FROM Employees JOIN Departments ON Employees.DepartmentID = Departments.ID;这对应于关系代数中的⋈Employees.DepartmentID = Departments.ID(Employees, Departments)。
通过这些例子,我们可以看到SQL的SELECT语句是如何与关系代数的操作相对应的。这种对应关系不仅帮助我们理解SQL语句的本质,还为我们提供了一种优化查询的数学工具。在实际应用中,我们可以利用关系代数的理论来分析和改进我们的SQL查询,从而提高查询效率,减少不必要的计算。
在接下来的章节中,我们将深入探讨数据操作的集合论视角和事务的逻辑控制,以及它们与数学原理的联系。我们将继续探索SQL语言的实战演练,以及如何将数学理论应用于数据库的实际操作中。让我们一起继续这场智慧之网的探索之旅。
3.2 数据操作的集合论视角:INSERT、UPDATE、DELETE的实战技巧与集合操作的数学原理
3.2.1 集合论基础与数据操作
在关系型数据库中,数据操作的核心是INSERT、UPDATE、DELETE,这些操作本质上是对数据库表这一集合的元素进行增、改、删。集合论是数学的一个基础分支,它研究集合的性质和集合之间的关系。在数据库操作中,我们可以将表视为一个集合,其中的行(记录)是集合的元素。
3.2.2 INSERT操作的集合论原理
INSERT操作对应于集合论中的并集操作。当我们向表中插入新记录时,实际上是在原有的记录集合上进行并集运算。假设我们有一个表T,其原有的记录集合为R,插入的新记录为r,那么插入操作可以表示为:
T ′ = T ∪ { r } T' = T \cup \{r\} T′=T∪{r}
这里,T’表示插入新记录后的表。这个操作的数学原理保证了新记录的唯一性,即不会插入重复的记录。
3.2.3 UPDATE操作的集合论原理
UPDATE操作涉及到集合的差集和并集操作。当我们更新表中的记录时,首先需要找到需要更新的记录集合,然后从原表中移除这些记录,最后将更新后的记录插入。假设我们有一个表T,需要更新的记录集合为U,更新后的记录集合为U’,那么更新操作可以表示为:
T ′ = ( T − U ) ∪ U ′ T' = (T - U) \cup U' T′=(T−U)∪U′
这里,T’表示更新后的表。这个操作的数学原理保证了更新的一致性,即只有被标记为更新的记录才会被修改。
3.2.4 DELETE操作的集合论原理
DELETE操作对应于集合论中的差集操作。当我们从表中删除记录时,实际上是在原有的记录集合上进行差集运算。假设我们有一个表T,需要删除的记录集合为D,那么删除操作可以表示为:
T ′ = T − D T' = T - D T′=T−D
这里,T’表示删除记录后的表。这个操作的数学原理保证了删除的准确性,即只有被标记为删除的记录才会被移除。
3.2.5 实战技巧与集合操作的数学原理
在实际操作中,我们需要注意以下几点:
- 唯一性保证:在INSERT操作中,确保新记录不与现有记录冲突,这通常通过主键或唯一约束来实现。
- 一致性维护:在UPDATE操作中,确保更新后的记录仍然满足数据库的约束条件,如外键约束、完整性约束等。
- 准确性执行:在DELETE操作中,确保只删除那些确实需要被移除的记录,避免误删重要数据。
3.2.6 示例:学生信息表的操作
假设我们有一个学生信息表Student,包含字段ID(主键)、Name、Age。
- INSERT操作:插入一个新学生记录,ID为101,Name为“张三”,Age为20。
INSERT INTO Student (ID, Name, Age) VALUES (101, '张三', 20);
- UPDATE操作:将ID为101的学生年龄更新为21。
UPDATE Student SET Age = 21 WHERE ID = 101;
- DELETE操作:删除ID为101的学生记录。
DELETE FROM Student WHERE ID = 101;
在这些操作中,我们运用了集合论的原理,确保了数据操作的正确性和一致性。通过这些操作,我们不仅能够有效地管理数据,还能够深入理解数据库操作背后的数学原理。
3.2.7 小结
数据操作是关系型数据库管理的核心,而集合论为我们提供了理解和执行这些操作的数学工具。通过集合论的视角,我们能够更加深刻地认识到INSERT、UPDATE、DELETE操作的本质,从而在实际应用中更加得心应手。在接下来的章节中,我们将继续探讨事务的逻辑控制,以及如何将这些理论知识应用于实际的数据库设计和优化中。
3.3 事务的逻辑控制:BEGIN、COMMIT、ROLLBACK的实际应用与逻辑控制的数学模型
3.3.1 事务的定义与重要性
在关系型数据库的世界里,事务是一系列操作的集合,这些操作要么全部执行,要么全部不执行。这种特性被称为原子性,是ACID原则中的A。事务的重要性在于它确保了数据库的一致性,即使在面对系统崩溃或并发操作时也是如此。
3.3.2 BEGIN:事务的起点
当我们使用BEGIN语句时,我们标志着事务的开始。在数学模型中,我们可以将事务视为一个状态转换函数,它接受当前数据库状态作为输入,并输出一个新的状态。BEGIN可以被看作是这个函数的初始化步骤,它设置了一个状态转换的起点。
3.3.3 COMMIT:事务的确认
COMMIT语句用于确认事务中的所有操作,使得这些操作对其他事务可见,并且持久化到数据库中。在数学模型中,COMMIT可以被视为一个确认信号,它触发状态转换函数的最终执行,确保所有操作都被应用到数据库状态上。
3.3.4 ROLLBACK:事务的回滚
当遇到错误或异常情况时,ROLLBACK语句用于撤销事务中的所有操作,将数据库恢复到事务开始前的状态。在数学模型中,ROLLBACK可以被看作是一个撤销操作,它将状态转换函数重置到初始状态,确保数据库的一致性不受破坏。
3.3.5 逻辑控制的数学模型
事务的逻辑控制可以通过数学模型来精确描述。我们可以使用状态机理论来建模事务的生命周期。一个事务可以被视为一个有限状态机(FSM),它有三个主要状态:开始(BEGIN)、执行(IN_PROGRESS)和结束(COMMIT或ROLLBACK)。
FSM = ( Q , Σ , δ , q 0 , F ) \text{FSM} = (Q, \Sigma, \delta, q_0, F) FSM=(Q,Σ,δ,q0,F)
其中:
- Q Q Q 是状态的集合,包括 q B E G I N q_{BEGIN} qBEGIN, q I N _ P R O G R E S S q_{IN\_PROGRESS} qIN_PROGRESS, q C O M M I T q_{COMMIT} qCOMMIT, q R O L L B A C K q_{ROLLBACK} qROLLBACK。
- Σ \Sigma Σ 是输入符号的集合,包括事务操作(如UPDATE, DELETE, INSERT)。
- δ \delta δ 是状态转移函数,定义了在给定输入下状态之间的转移。
- q 0 q_0 q0 是初始状态,即 q B E G I N q_{BEGIN} qBEGIN。
- F F F 是接受状态的集合,包括 q C O M M I T q_{COMMIT} qCOMMIT 和 q R O L L B A C K q_{ROLLBACK} qROLLBACK。
状态转移函数 δ \delta δ 可以定义为:
δ ( q B E G I N , operation ) = q I N _ P R O G R E S S δ ( q I N _ P R O G R E S S , COMMIT ) = q C O M M I T δ ( q I N _ P R O G R E S S , ROLLBACK ) = q R O L L B A C K \delta(q_{BEGIN}, \text{operation}) = q_{IN\_PROGRESS} \\ \delta(q_{IN\_PROGRESS}, \text{COMMIT}) = q_{COMMIT} \\ \delta(q_{IN\_PROGRESS}, \text{ROLLBACK}) = q_{ROLLBACK} δ(qBEGIN,operation)=qIN_PROGRESSδ(qIN_PROGRESS,COMMIT)=qCOMMITδ(qIN_PROGRESS,ROLLBACK)=qROLLBACK
3.3.6 实例分析
让我们通过一个具体的例子来理解事务的逻辑控制。假设我们有一个银行数据库,我们需要从一个账户转账到另一个账户。
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE account_id = 123;
UPDATE accounts SET balance = balance + 100 WHERE account_id = 456;
COMMIT;
在这个例子中,如果两个UPDATE语句都成功执行,事务将通过COMMIT语句确认。如果任何一个UPDATE语句失败,事务将通过ROLLBACK语句回滚,确保两个账户的余额保持一致。
3.3.7 并发控制与隔离性
在多用户环境中,事务的并发执行可能会导致数据不一致的问题。为了解决这个问题,数据库系统提供了隔离性,这是ACID原则中的I。隔离性可以通过锁机制或多版本并发控制(MVCC)来实现。在数学模型中,我们可以将隔离性视为一个额外的状态转移规则,它限制了事务之间的相互作用,确保每个事务都像是在独立运行。
3.3.8 持久性与恢复
持久性是ACID原则中的D,它确保一旦事务被提交,其结果将永久保存在数据库中,即使系统发生故障。在数学模型中,持久性可以被视为一个持久化函数,它将事务的结果从内存状态转移到持久存储中。数据库恢复技术,如日志记录和检查点,提供了在系统崩溃后恢复事务的能力。
3.3.9 小结
事务的逻辑控制是关系型数据库管理的核心,它通过BEGIN、COMMIT、ROLLBACK等语句确保了数据的一致性和完整性。通过数学模型,我们可以更深入地理解事务的运作机制,以及如何通过并发控制和恢复技术来维护数据库的稳定性和可靠性。在实际应用中,正确地使用事务控制语句是每个数据库开发者和管理员必备的技能。
4. 关系型数据库设计的数学模型
4.1 实体-关系模型的图论视角
4.1.1 ER图的绘制:构建数据库的蓝图
在数据库设计的舞台上,实体-关系模型(ER模型)扮演着至关重要的角色。它通过图形化的方式,将现实世界的复杂关系抽象为简洁的图表,为数据库的构建提供了清晰的蓝图。ER图的绘制,是一场将实体、属性、关系编织成网的创作过程。
实体(Entity)是现实世界中可识别的对象,如学生、课程。属性(Attribute)则是描述实体特征的数据项,如学生的姓名、年龄。关系(Relationship)则展现了实体间的互动,如学生选修课程。在ER图中,实体通常用矩形表示,属性用椭圆,而关系则用菱形。
例如,我们考虑一个简单的学校数据库,其中包含学生和课程两个实体。学生实体可能具有属性:学号、姓名、年龄;课程实体可能具有属性:课程号、课程名、学分。学生与课程之间的关系“选修”,可以用菱形表示,连接学生和课程实体。
4.1.2 数据库模式转换:从概念到逻辑
ER图绘制完成后,下一步是将这个概念模型转换为数据库的逻辑模式。这一过程涉及到将ER图中的实体、属性和关系映射到数据库中的表、字段和外键。
数学公式在此过程中发挥着重要作用。例如,考虑两个实体A和B,它们之间存在一个M:N的关系R。在数据库中,这意味着我们需要创建三个表:A、B和R。表R将包含两个外键,分别指向A和B的主键。这一映射过程可以用以下公式表示:
R ( a _ i d , b _ i d ) R(a\_id, b\_id) R(a_id,b_id)
其中, a _ i d a\_id a_id是A表的主键, b _ i d b\_id b_id是B表的主键。
4.1.3 图论的基本概念:关系的数学语言
图论是研究图(由节点和边组成的结构)的数学分支。在ER模型中,图论的基本概念帮助我们更深入地理解实体间的关系。
- 节点(Node):在ER图中,实体和关系都可以被视为节点。
- 边(Edge):连接节点的线,代表实体间的关系。
- 路径(Path):一系列相连的边,表示实体间的一系列关系。
- 连通性(Connectivity):图中任意两个节点间是否存在路径。
例如,在上述学校数据库的ER图中,学生和课程通过“选修”关系相连,形成了一条边。如果我们考虑一个学生选修多门课程,那么这个学生节点将有多条边连接到不同的课程节点。
图论的数学语言不仅帮助我们描述和分析ER图,还为数据库的优化提供了理论基础。例如,通过分析图的连通性和路径长度,我们可以优化数据库的查询效率。
在数据库设计的旅途中,ER模型和图论的结合,为我们提供了一双洞察数据关系的慧眼。通过精确的数学语言和图形化的表达,我们能够构建出既美观又高效的数据库结构,为数据的管理和分析奠定了坚实的基础。
4.2 规范化理论的函数依赖解析
在关系型数据库的设计中,规范化理论是一块不可或缺的基石。它通过一系列的范式来确保数据库结构的最优化,减少数据冗余,提高数据的一致性和完整性。本节将深入探讨从第一范式(1NF)到第五范式(5NF)的演进过程,以及函数依赖在其中的数学表达。
第一范式(1NF)
第一范式要求关系中的每个属性都是原子的,即不可再分。这意味着在一个属性中不允许存在多个值。例如,一个学生表中的“联系方式”属性如果包含了电话和邮箱,那么它就不符合1NF。我们需要将其拆分为“电话”和“邮箱”两个独立的属性。
第二范式(2NF)
第二范式建立在1NF的基础上,要求非键属性完全依赖于主键。这意味着如果一个表有复合主键,那么非键属性不能只依赖于复合主键的一部分。例如,一个订单表中,如果主键是(订单号,产品号),而“产品价格”只依赖于“产品号”,那么它就不符合2NF。解决方法是将其拆分为两个表,一个订单表和一个产品表。
第三范式(3NF)
第三范式要求非键属性之间不存在传递依赖。也就是说,如果A决定B,B决定C,但B不决定A,那么C就是通过B传递依赖于A。在3NF中,这种依赖是不允许的。例如,一个员工表中,如果“部门名称”依赖于“部门号”,而“部门号”又依赖于“员工号”,那么它就不符合3NF。解决方法是将其拆分为员工表和部门表。
巴斯-科德范式(BCNF)
巴斯-科德范式是3NF的加强版,它要求对于任何函数依赖A→B,A都必须是超键。这意味着如果A决定B,那么A必须包含候选键。例如,一个学生选课表中,如果“课程号”决定“教师号”,而“课程号”不是超键,那么它就不符合BCNF。解决方法是将其拆分为学生表、课程表和教师表。
第四范式(4NF)
第四范式处理的是多值依赖问题。多值依赖是指一个属性值的集合完全独立于另一个属性值的集合。例如,一个员工表中,如果“员工号”同时决定“技能”和“语言”,而“技能”和“语言”之间没有依赖关系,那么它就不符合4NF。解决方法是将其拆分为员工表、技能表和语言表。
第五范式(5NF)
第五范式,也称为投影-连接范式(PJNF),它要求关系在投影到它的每个候选键上后,再通过自然连接恢复原关系时,不会丢失信息。这意味着关系中的每个连接依赖都是由候选键决定的。5NF是规范化理论中的最高范式,它确保了数据库设计的最终优化。
函数依赖的数学表达
函数依赖可以用数学符号表示为X→Y,其中X和Y是属性集。这意味着在任何时候,如果两个元组在X上的值相等,那么它们在Y上的值也必须相等。函数依赖是关系模式设计中的基本概念,它决定了数据的完整性和一致性。
函数依赖的公理系统由Armstrong公理构成,包括自反律、增广律和传递律。通过这些公理,我们可以推导出闭包、覆盖和最小覆盖等概念,这些都是规范化过程中的重要工具。
例如,给定一个关系R(A, B, C),如果存在函数依赖A→B和B→C,那么我们可以推导出A→C,这是传递律的应用。通过计算属性集A的闭包A+,我们可以确定A决定的所有属性,从而判断关系是否满足某个范式。
在规范化过程中,我们不仅要理解每个范式的要求,还要掌握函数依赖的数学表达和推导方法。这样,我们才能设计出既高效又可靠的关系型数据库。
在接下来的章节中,我们将通过具体的实例和图表,进一步展示规范化过程的实际应用,以及如何通过函数依赖图来分析和优化数据库设计。让我们继续这场智慧与实践的交响曲,探索数据库设计的深层次奥秘。
4.3 数据库设计的优化之道:数学之光下的数据架构艺术
4.3.1 需求分析:数据库设计的启明星
在数据库设计的征途上,需求分析是我们的启明星。它指引我们理解业务逻辑,捕捉数据流动的脉络,以及预测未来数据的增长。在这一阶段,我们运用数学中的逻辑学和概率论,通过建立数据模型来预测和分析数据需求。例如,我们可以使用概率分布来估计数据量的增长,或者利用逻辑回归来分析数据间的依赖关系。
4.3.2 数据库模式的数学构建
数据库模式的设计是数学构建的过程,它要求我们运用关系代数和集合论的知识来定义表结构、键和索引。在这一过程中,我们不仅要确保数据的完整性和一致性,还要考虑查询的效率。例如,通过计算关系的基数和选择性,我们可以优化索引的设计,以减少查询时的磁盘I/O操作。
选择性 = 唯一值的数量 总记录数 \text{选择性} = \frac{\text{唯一值的数量}}{\text{总记录数}} 选择性=总记录数唯一值的数量
选择性越高,索引的效率通常越好。
4.3.3 规范化与反规范化的数学权衡
规范化是数据库设计中的一个重要步骤,它通过消除冗余和依赖问题来提高数据的一致性和完整性。然而,过度的规范化可能导致查询性能下降。反规范化则是一种牺牲空间效率以换取查询性能的策略。在这一过程中,我们需要运用数学中的优化理论,如线性规划,来权衡规范化与反规范化的利弊。
4.3.4 查询优化的数学策略
查询优化是数据库设计中的核心环节,它要求我们运用关系代数和图论的知识来分析查询计划,选择最优的执行路径。在这一过程中,我们可以使用代价模型来评估不同查询计划的性能,例如,通过计算磁盘I/O、CPU时间和网络传输的代价来选择最佳的查询策略。
代价 = α × 磁盘I/O + β × CPU时间 + γ × 网络传输 \text{代价} = \alpha \times \text{磁盘I/O} + \beta \times \text{CPU时间} + \gamma \times \text{网络传输} 代价=α×磁盘I/O+β×CPU时间+γ×网络传输
其中, α \alpha α、 β \beta β 和 γ \gamma γ 是权重因子,反映了不同资源的重要性。
4.3.5 性能监控与调优的数学工具
性能监控与调优是数据库设计的持续过程,它要求我们运用统计学和概率论的知识来分析性能数据,识别瓶颈。在这一过程中,我们可以使用统计模型来预测系统的性能趋势,或者利用概率分布来评估系统在不同负载下的表现。
4.3.6 数据库设计的未来:数学与人工智能的融合
随着人工智能技术的发展,数据库设计正迎来新的变革。机器学习模型可以用于预测数据访问模式,自动优化查询计划,甚至自动调整数据库配置。在这一过程中,我们需要运用数学中的机器学习理论,如梯度下降、神经网络,来实现智能化的数据库设计。
在数据库设计的优化之道上,数学不仅是我们的工具,更是我们的指南。它帮助我们理解数据的本质,优化数据的结构,提升数据的价值。让我们在数学的光辉下,继续探索数据库设计的无限可能。

5. 实例代码与可视化图表的数学透视
5.1 SQL查询的效率之舞:高效SQL查询的编写技巧与关系代数的应用
在关系型数据库的广阔舞台上,SQL查询的编写不仅仅是技术操作,更是一场关于效率与智慧的舞蹈。每一次的查询,都是对数据深层结构的探索,对信息海洋的精准捕捞。本节将带领读者深入探讨高效SQL查询的编写技巧,以及如何运用关系代数的理论来优化查询过程。
5.1.1 查询优化的数学基础
在SQL查询的世界里,效率往往取决于查询语句的编写方式。一个高效的查询,就像是一位舞者,在数据的舞台上轻盈跳跃,优雅而迅速。为了达到这样的效果,我们需要理解查询背后的数学原理,特别是关系代数。
关系代数是SQL查询的数学基础,它提供了一套操作符来处理关系(即表)。这些操作符包括选择(σ)、投影(π)、并(∪)、差(-)、笛卡尔积(×)和连接(⋈)等。通过这些操作符的组合,我们可以构建出复杂的查询逻辑。
例如,考虑一个简单的查询,我们想要从“员工”表中找到所有工资大于5000的员工的名字和部门。在关系代数中,这个查询可以表示为:
π 姓名, 部门 ( σ 工资 > 5000 ( 员工 ) ) \pi_{\text{姓名, 部门}} (\sigma_{\text{工资} > 5000} (\text{员工})) π姓名, 部门(σ工资>5000(员工))
这里, π \pi π 表示投影操作,选择出我们需要的列; σ \sigma σ 表示选择操作,过滤出满足条件的行。
5.1.2 索引的数学原理
索引是提高查询效率的重要手段。在数学上,索引可以看作是对数据的一种预处理,通过建立某种数据结构(如B树或哈希表),使得查询操作可以更快地定位到所需的数据。
例如,如果我们在“员工”表的“工资”列上建立了索引,那么对于上述查询,数据库可以迅速地通过索引找到所有工资大于5000的员工记录,而不需要扫描整个表。
5.1.3 查询优化的实战技巧
在实际编写SQL查询时,有一些技巧可以帮助我们提高效率:
- **避免使用SELECT ***:明确指定需要的列,减少不必要的数据传输。
- 使用JOIN代替子查询:在某些情况下,JOIN操作比子查询更高效。
- 合理使用WHERE子句:尽量使用索引列进行过滤,减少数据扫描的范围。
- 优化查询逻辑:通过分析查询计划,调整查询语句的逻辑顺序,使得查询更加高效。
例如,考虑以下查询:
SELECT E.姓名, D.部门名称
FROM 员工 E
JOIN 部门 D ON E.部门ID = D.部门ID
WHERE E.工资 > 5000;
这个查询使用了JOIN操作来关联“员工”和“部门”表,同时在WHERE子句中使用了索引列“工资”进行过滤,这样的编写方式通常比使用子查询更加高效。
5.1.4 查询性能的数学分析
查询性能的分析往往涉及到时间复杂度的计算。在关系型数据库中,一个查询的时间复杂度取决于多种因素,包括表的大小、索引的使用、查询的复杂度等。
例如,一个简单的SELECT查询,如果没有使用索引,其时间复杂度可能是O(n),其中n是表中的记录数。而如果使用了索引,时间复杂度可能会降低到O(log n)或更低。
通过数学分析,我们可以预测不同查询的性能,并据此进行优化。例如,如果一个查询的时间复杂度很高,我们可能需要考虑增加索引,或者重新设计查询逻辑。
在SQL查询的效率之舞中,每一次的跳跃都充满了智慧与技巧。通过深入理解关系代数的原理,合理运用索引,以及精心编写查询语句,我们可以在数据的舞台上跳出优雅而高效的舞步。让我们继续探索,将数学的智慧与数据库的实战技艺完美结合,共同编织出数据时代的智慧之网。
5.2 ER图的案例分析
5.2.1 ER图的基本构成与数学基础
在深入案例分析之前,我们先回顾一下ER图(实体-关系图)的基本构成及其背后的数学基础。ER图是数据库设计中的一个关键工具,它通过图形化的方式来表示实体、实体间的联系以及实体的属性。在ER图中,我们通常用矩形表示实体,用菱形表示联系,用椭圆表示属性,而实体与联系之间的连线则表示它们之间的关系。
从数学的角度来看,ER图实际上是一种特殊的图,它属于图论的研究范畴。在图论中,图是由顶点(或称为节点)和连接这些顶点的边(或称为弧)组成的集合。在ER图中,实体对应于图的顶点,联系对应于图的边。这种对应关系为我们提供了一种分析ER图的数学工具。
5.2.2 案例背景介绍与ER图的绘制
假设我们正在设计一个图书馆管理系统,该系统需要记录图书、读者以及借阅记录。在这个系统中,图书和读者是两个核心实体,而借阅记录则是它们之间的联系。我们的任务是绘制一个ER图,以清晰地展示这些实体及其关系。
首先,我们定义实体及其属性:
- 图书(Book):书号(book_id,主键)、书名(title)、作者(author)、出版社(publisher)、出版日期(publication_date)。
- 读者(Reader):读者号(reader_id,主键)、姓名(name)、性别(gender)、年龄(age)、联系方式(contact)。
接下来,我们定义实体之间的联系:
- 借阅(Borrow):这是一个多对多的联系,因为一个读者可以借阅多本书,而一本书也可以被多个读者借阅。在ER图中,我们用菱形表示这个联系,并标注其属性,如借阅日期(borrow_date)和应还日期(due_date)。
绘制ER图时,我们遵循以下步骤:
- 绘制实体矩形,并在其中列出所有属性。
- 绘制联系菱形,并标注联系的名称和属性。
- 使用直线连接实体和联系,并在直线上标注联系的类型(如1:1、1:N、M:N)。
5.2.3 图论分析方法在ER图中的应用
图论提供了一系列分析工具,可以帮助我们理解ER图的结构和特性。例如,我们可以使用图的邻接矩阵来表示实体之间的联系。对于我们的图书馆管理系统,邻接矩阵将是一个二维数组,其中行和列分别代表图书和读者,矩阵元素表示两者之间的借阅关系。
A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ] A = \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{bmatrix} A= a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn
其中, a i j = 1 a_{ij} = 1 aij=1 表示第 i i i 本书被第 j j j 个读者借阅, a i j = 0 a_{ij} = 0 aij=0 表示没有借阅关系。
此外,图论中的路径搜索算法,如深度优先搜索(DFS)和广度优先搜索(BFS),可以用来分析实体之间的可达性和联系的复杂度。例如,我们可以使用DFS来找出所有可能的借阅路径,或者使用BFS来找出最短的借阅路径。
5.2.4 案例分析的数学透视
在案例分析中,我们不仅关注ER图的绘制,还关注其背后的数学模型和分析方法。通过将ER图视为图论中的图,我们可以利用图论的丰富理论来优化数据库设计,提高系统的性能和可维护性。
例如,我们可以使用图的着色问题来优化数据库的索引策略。在图着色问题中,我们试图用最少的颜色给图的顶点着色,使得任意两个相邻的顶点颜色不同。在数据库索引中,我们可以将不同的属性视为图的顶点,将属性之间的函数依赖视为图的边,然后使用图着色算法来确定哪些属性应该被索引,以最小化索引的数量并提高查询效率。
5.2.5 小结
通过本节的案例分析,我们不仅展示了ER模型的应用,还揭示了图论分析方法在数据库设计中的重要性。数学不仅为我们提供了理论基础,还为我们提供了强大的工具,帮助我们理解和优化复杂的数据库系统。在未来的数据库设计和优化中,我们应该继续探索数学与数据库技术的结合,以实现更加高效和智能的数据管理。
5.3 规范化过程的图解之旅
在关系型数据库设计中,规范化过程是至关重要的一环。这一过程涉及对数据库结构的调整,以减少数据冗余、避免异常操作,并提高数据一致性。今天,我们将通过图表来解释规范化过程中的数据结构变化,同时展示如何绘制函数依赖图。
5.3.1 函数依赖的数学语言
在深入图解之前,我们首先需要理解函数依赖的数学表达。假设有属性集合 U U U 和它的两个子集 X X X 和 Y Y Y,我们说 “ Y Y Y 函数依赖于 X X X”,如果对于任何 U U U 的一个实例, X X X 的值都能唯一确定 Y Y Y 的值。数学上,我们表示为:
X → Y X \rightarrow Y X→Y
5.3.2 规范化过程概览
规范化通常分为几个阶段——第一范式(1NF)、第二范式(2NF)、第三范式(3NF)和博耶-科得范式(BCNF)。每个阶段都对应着对数据结构的特定调整,和对应的函数依赖的满足条件。
5.3.3 第一范式(1NF)
我们从一个非规范化的表开始,该表中包含了重复的组和列。
例子:
设想一个订单系统中的表,每个订单包含多个产品,产品由其产品ID、名称和价格定义。
非规范化表可能如下:
| OrderID | ProductIDs | ProductNames | ProductPrices |
|---|---|---|---|
| 1001 | 1,2 | Book, Pen | 15, 1.5 |
| 1002 | 3 | Notebook | 7 |
为了达到1NF,我们需要消除重复的组,使每个属性都包含不可分割的数据项。
转化为1NF后的表:
| OrderID | ProductID | ProductName | ProductPrice |
|---|---|---|---|
| 1001 | 1 | Book | 15 |
| 1001 | 2 | Pen | 1.5 |
| 1002 | 3 | Notebook | 7 |
5.3.4 第二范式(2NF)
为了达到2NF,我们需要解决部分函数依赖,当且仅当非主属性完全函数依赖于候选键时,关系才处于2NF。
例子:
在1NF的基础上,如果ProductPrice依赖于ProductID而不是整个OrderID, ProductID组合,则存在部分函数依赖。
为了解决这个问题,我们会将表分解为两个表:
订单表:
| OrderID | ProductID |
|---|---|
| 1001 | 1 |
| 1001 | 2 |
| 1002 | 3 |
产品表:
| ProductID | ProductName | ProductPrice |
|---|---|---|
| 1 | Book | 15 |
| 2 | Pen | 1.5 |
| 3 | Notebook | 7 |
5.3.5 第三范式(3NF)
为了达到3NF,我们需要解决传递函数依赖,即一个非主属性依赖于另一个非主属性。
例子:
如果在产品表中,ProductName决定了ProductPrice,存在传递函数依赖。
我们将产品表再次分解:
产品信息表:
| ProductID | ProductName |
|---|---|
| 1 | Book |
| 2 | Pen |
| 3 | Notebook |
价格表:
| ProductName | ProductPrice |
|---|---|
| Book | 15 |
| Pen | 1.5 |
| Notebook | 7 |
5.3.6 函数依赖图的绘制
函数依赖图是一个非常有用的工具,可以帮助我们可视化属性之间的依赖关系。在图中,每个节点代表一个属性,箭头从决定属性指向被决定属性。
考虑到前面的产品和价格表,我们可以这样画出它们的函数依赖图:
- 从
ProductID箭头指向ProductName - 从
ProductName箭头指向ProductPrice
这样的图形表达使得依赖关系一目了然。
通过今天的探索,我们见证了如何将数据规范化理论与实际的数据库设计相结合,并图形化地表示函数依赖。这不仅加深了我们对规范化的理解,更为数据库设计的优化提供了清晰的指引。当然,每一个范式都有其数学基础,在实践中,为了平衡理论与实际的需求,最佳的数据库设计可能会是一个折中的结果。

6. 结语
在我们深入探索了关系型数据库的核心理论和数学基础之后,我们站在了智慧之网的临界点,准备迈向实践的殿堂。关系型数据库不仅仅是数据时代的基石,更是智慧的结晶,融合了数学的严谨与计算机科学的创造力。在本篇博客中,我们已经一步步探索了从基础的集合论到复杂的规范化理论,从抽象的数学公式到实际的SQL命令,每一步都是对智慧的深层探索和实践的准备。
智慧的结晶:在这一旅程中,我们首先理解了关系模型是如何用集合论的基础概念来描述数据结构的,其中关系、属性、元组和键的定义是其中的关键。举例来说,一个关系可以看作是一组元组的集合,其中每个元组可以表示为 R ( a 1 , a 2 , . . . , a n ) R(a_1, a_2, ..., a_n) R(a1,a2,...,an),这里的 R R R 是关系名,而 a 1 , a 2 , . . . , a n a_1, a_2, ..., a_n a1,a2,...,an 是属性值。
随后,我们探索了函数依赖和ACID原则,它们的数学保障是数据库系统完整性和可靠操作的基础。例如,我们可以用逻辑表达式 ∀ x , y ∈ T , ( x . A = y . A ) ⇒ ( x . B = y . B ) \forall x,y \in T, (x.A = y.A) \Rightarrow (x.B = y.B) ∀x,y∈T,(x.A=y.A)⇒(x.B=y.B) 来表达属性A对属性B的函数依赖,这里的 T T T 代表一个关系表。
接着,我们深入研究了SQL语言与关系代数的密切联系,并通过实例展示了查询、数据操作和事务控制的集合论与逻辑基础。
实践的呼唤:理论的掌握仅仅是成功的一半,它的真正价值在于应用于实际问题。我们已经看到了ER图和规范化理论在数据库设计中的实际指导作用,以及优化理论的数学基础。为了将这些理论付诸实践,我鼓励每一位读者去尝试编写自己的SQL查询,绘制ER图,甚至尝试解构与重构数据模型以更好地理解规范化的过程。在数据库的设计和优化过程中,不断回顾并应用这些数学概念,可以帮助我们建立更加高效、稳定、可扩展的数据库系统。
在你的实践中,当你遇到性能瓶颈或设计难题时,可以回到这些数学原理中寻找答案。例如,当一个SQL查询执行效率不高时,回顾关系代数的优化原则,如选择操作的早执行和连接操作的顺序选择,可能会提供性能改善的线索。用数学的语言,加入索引相当于在集合上定义了一个偏序关系,这可以显著提高搜索速度。
总之,无论是作为数据库的设计者、开发者还是学者,理解并应用这些数学理论,都是至关重要的。它们不仅仅是学术概念,而是工具,帮助我们在这个由数据驱动的世界中找到方向、作出决策,并最终创造新的可能。
在未来的道路上,随着技术的不断发展,我们可以预见到更为复杂的数据模型和查询语言的出现,数学作为这一领域的通用语言,其重要性将会日益凸显。因此,保持对数学原理的好奇心和对数据库技术的热情,将是我们持续进步的动力源泉。
在这里,我们的探索之旅不是结束,而是一个新起点。正如数学公式的简洁和优雅激励着我们去探究它们背后的真理,我希望这篇博客能够激励你去追求与数据库技术和数学更深的融合,去探索它们在真实世界中的无限可能。愿你的数据库之旅,充满智慧与发现。