文章目录
- 前言
- 一、Kafka
- 1、什么是消息队列
- offset
- 2、高性能
- topic
- partition
- 3、高扩展
- broker
- 4、高可用
- replicas、leader、follower
- 5、持久化和过期策略
- 6、消费者组
- 7、Zookeeper
- 8、架构图
- 二、安装Zookeeper
- 三、安装Kafka
- 四、Java中使用Kafka
- 1、引入依赖
- 2、生产者
- 3、消费者
- 4、运行效果
前言
Kafka消息中间件
一、Kafka
1、什么是消息队列
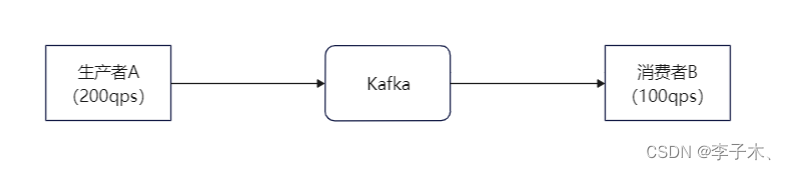
假设我们有两个服务:生产者A每秒能生产200个消息,消费者B每秒能消费100个消息。

那么B服务是处理不了A这么多消息的,那么怎么使B不被压垮的同时还能处理A的消息呢,我们引入一个中间件,即Kafka。(当然着并不能使消费者的处理速度上升)
offset
那么我们可以在B服务中加入一个队列,也就是一个链表,链表的每个节点相当于一条消息,每个节点有一个序号即offset,记录消息的位置。
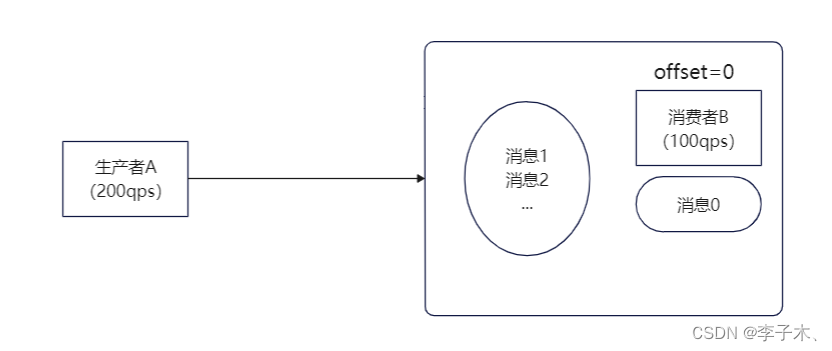
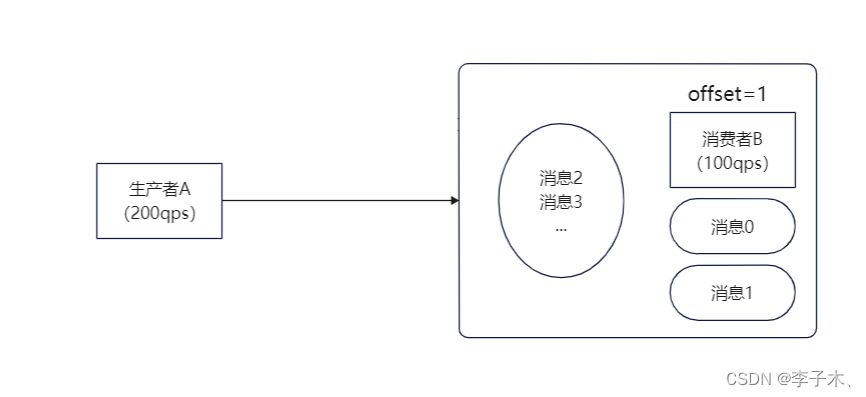
但是这样也会有个问题,还没有处理的消息是存储在内存中的,如果B服务挂掉,那么消息也就丢失了。
所以我们可以把队列移出,变成一个单独的进程,即使B服务挂掉,消息也不会丢失。
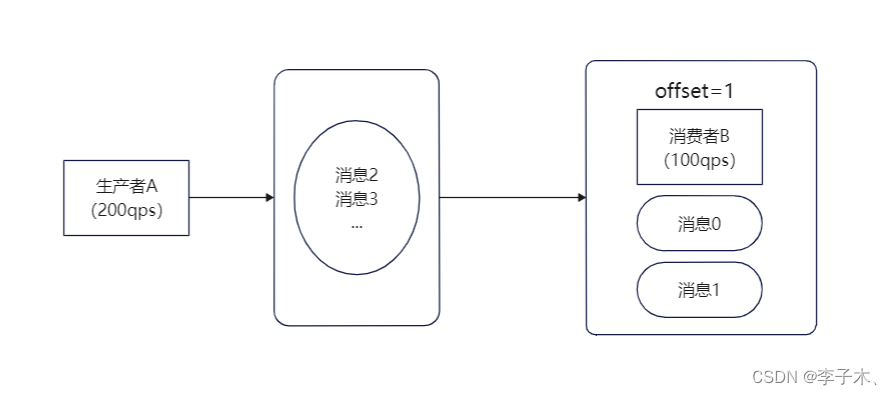
2、高性能
B服务由于性能差,队列中未处理的消息会越来越多,我们可以增加更多的消费者来处理消息,相对的也可以增加更多的生产者来生成消息。
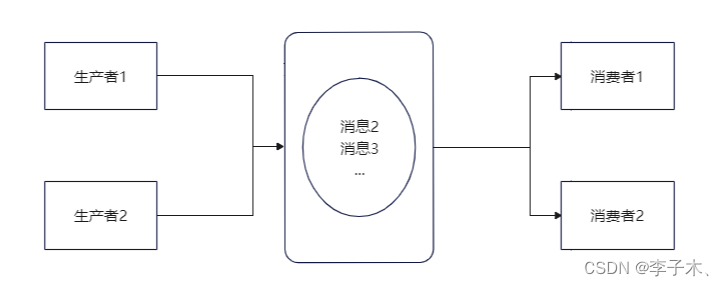
topic
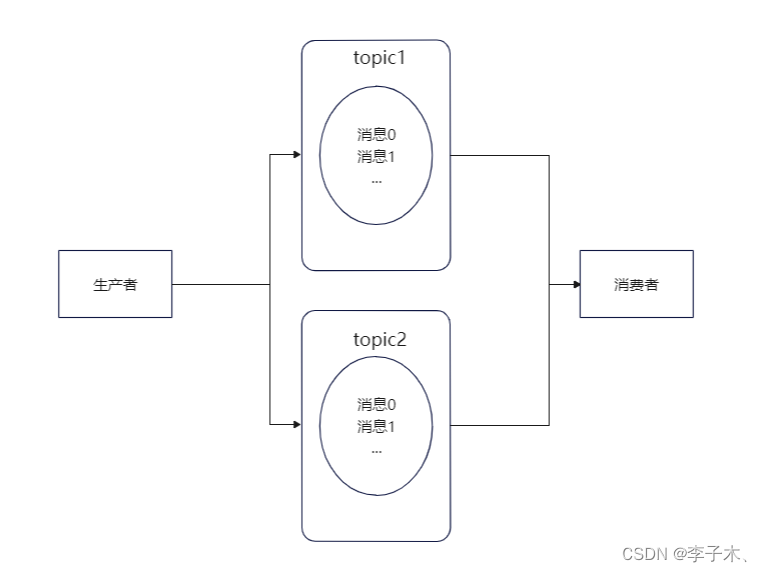
但是,生产者与消费者会争抢同一个队列,没有抢到就要等待,那么怎么解决呢?
我们可以将消息进行分类,每一类消息是一个topic,生产者按消息的类型投递到不同的topic中,消费者也按照不同的topic进行消费。
partition
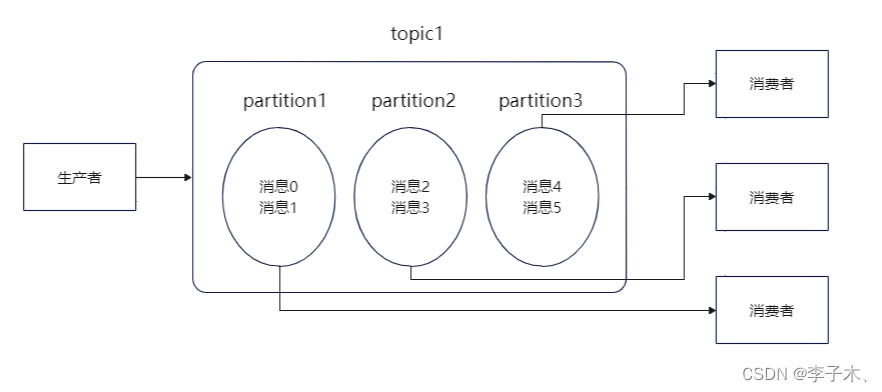
但是单个topic的消息还是有可能过多,我们可以将单个队列拆分,每段是一个partition分区,每个消费者负责一个partition。
3、高扩展
broker
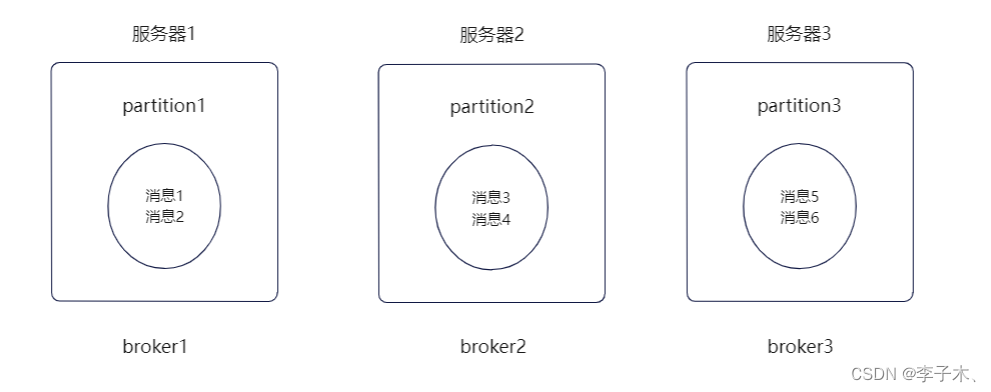
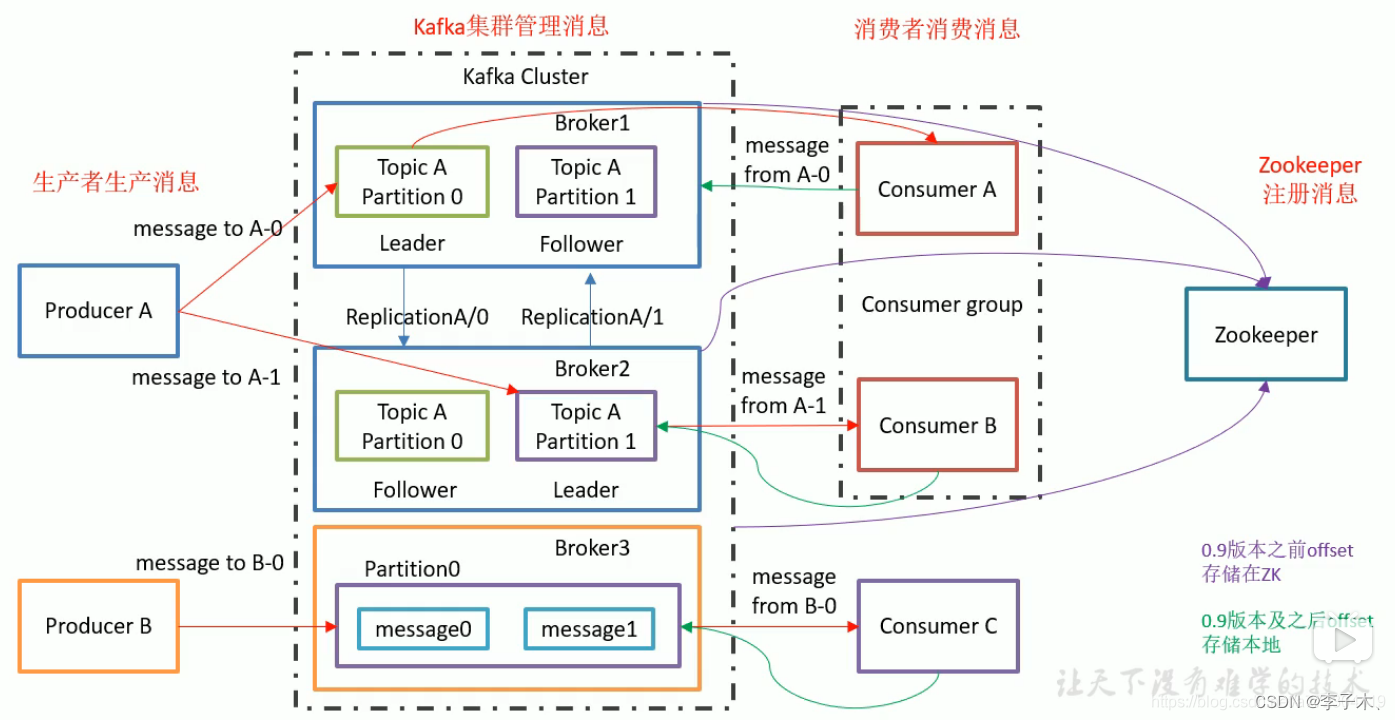
随着partition过多,所有的partition都在同一个机器上,就可能会导致单机的cpu和内存过高,影响性能,那么我们可以使用多台机器,将partition分散部署在不同的机器上。每台机器就代表一个broker。
我们可以增加broker来缓解服务器的cpu过高的性能问题。
4、高可用
replicas、leader、follower
假如某个broker挂了, 那么其中partition中的消息也就都丢失了,那么这个问题怎么解决呢?
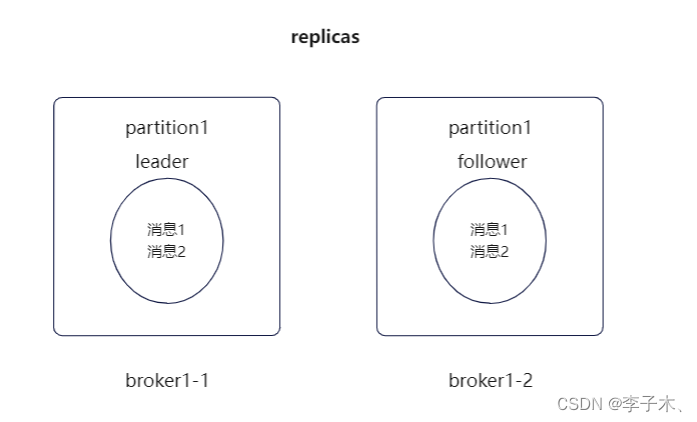
我们可以给partition多加几个副本,统称replicas,并将它们分为leader和follower。
leader负责生产者和消费者的读写,follower只负责同步leader的数据。假如leader挂了,也不会影响follower,随后在follower中选出一个leader,保证消息队列的高可用。
5、持久化和过期策略
在上面讲述了leader挂掉的情况,如果所有的broker都挂了,消息不就都丢失了?
为了解决这个问题,就不能只把数据存在内存中,也要存在磁盘中。
但是如果所有消息一直保存在磁盘中,那磁盘也会被占满,所以引入保留策略。
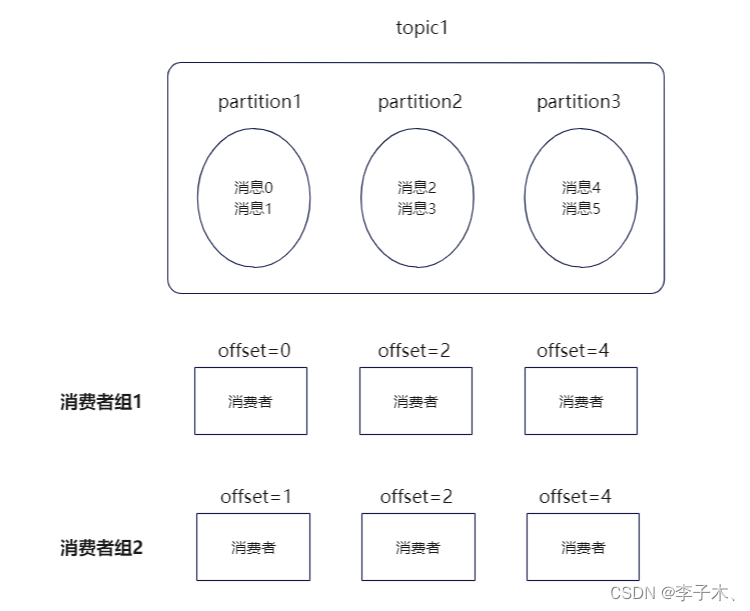
6、消费者组
如果我想在原有的基础上增加一个消费者,那么它只能跟着最新的offset接着消费,如果我想从某个offset开始消费呢?
我们引入消费者组,实现不同消费者维护自己的消费进度。
7、Zookeeper
上面介绍了很多的组件,每个组件都有自己的状态信息,那么就需要有一个组件去统一维护这些组件的状态信息,于是引入了Zookeeper组件,它会定期与broker通信,获取Kafka集群的状态,判断哪些broker挂了,消费者组消费到哪了等等。
8、架构图
二、安装Zookeeper
1、官网地址
https://zookeeper.apache.org/
2、下载
选择稳定版本下载
3、解压,修改配置文件
解压后,复制 zoo_sample.cfg,重命名为 zoo.cfg
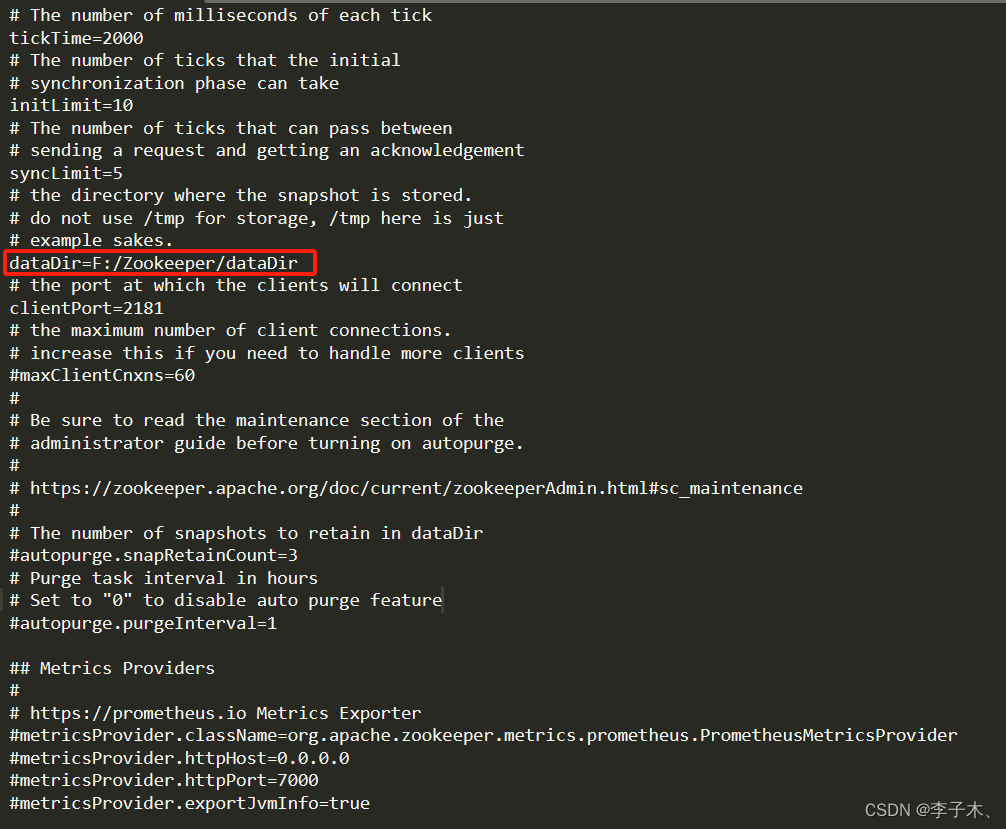
修改数据文件目录位置
4、启动
我们是在windows系统下安装的,运行 bin 目录下的 zkServer.cmd
三、安装Kafka
1、官网地址
https://kafka.apache.org/
2、下载
3、解压,修改配置文件
修改 config 目录下 server.properties 文件
修改日志文件位置,其他参数(如zookeeper端口,根据需要修改)

4、启动
bin\windows\kafka-server-start.bat config\server.properties
四、Java中使用Kafka
1、引入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
2、生产者
public static void main(String[] args) throws InterruptedException {
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.ACKS_CONFIG, "all");
prop.put(ProducerConfig.RETRIES_CONFIG, 0);
prop.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
prop.put(ProducerConfig.LINGER_MS_CONFIG, 1);
prop.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
String topic = "hello";
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>(topic, Integer.toString(2), "hello kafka" + i));
System.out.println("生产消息:" + i);
Thread.sleep(1000);
}
producer.close();
}
3、消费者
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"127.0.0.1:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "con-1"); // 消费者组
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); //自动提交偏移量
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000); //自动提交时间
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
ArrayList<String> topics = new ArrayList<>();
//可以订阅多个消息
topics.add("hello");
consumer.subscribe(topics);
try {
while(true) {
ConsumerRecords<String, String> poll = consumer.poll(Duration.ofSeconds(10));
for (TopicPartition topicPartition : poll.partitions()) {
// 通过TopicPartition获取指定的消息集合,获取到的就是当前topicPartition下面所有的消息
List<ConsumerRecord<String, String>> partitionRecords = poll.records(topicPartition);
// 获取TopicPartition对应的主题名称
String topic = topicPartition.topic();
// 获取TopicPartition对应的分区位置
int partition = topicPartition.partition();
// 获取当前TopicPartition下的消息条数
int size = partitionRecords.size();
System.out.printf("--- 获取topic: %s, 分区位置:%s, 消息总数: %s%n",
topic,
partition,
size);
for(int i = 0; i < size; i++) {
ConsumerRecord<String, String> consumerRecord = partitionRecords.get(i);
// 实际的数据内容
String key = consumerRecord.key();
// 实际的数据内容
String value = consumerRecord.value();
// 当前获取的消息偏移量
long offset = consumerRecord.offset();
// 表示下一次从什么位置(offset)拉取消息
long commitOffser = offset + 1;
System.out.printf("消费消息 key:%s, value:%s, 消息offset: %s, 提交offset: %s%n",
key, value, offset, commitOffser);
Thread.sleep(1500);
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
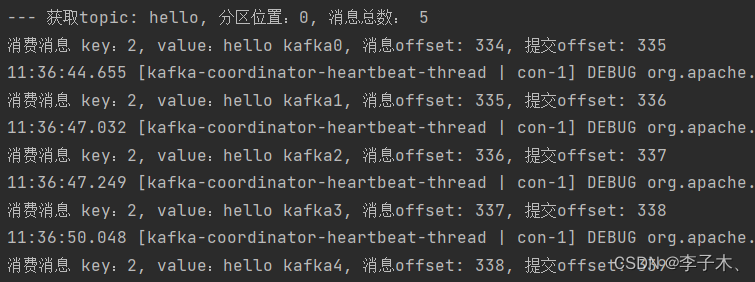
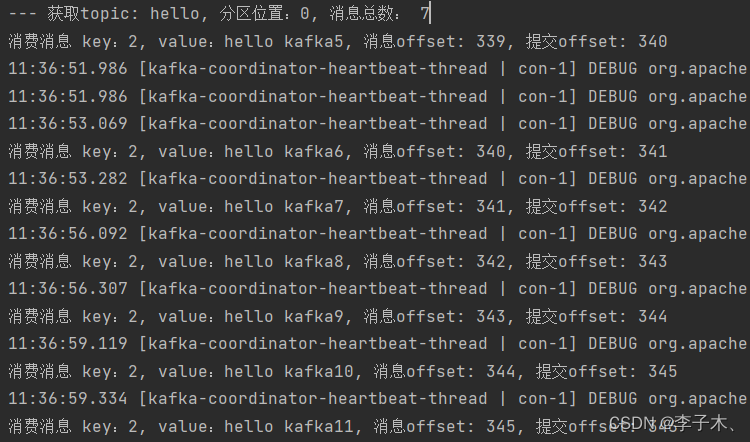
4、运行效果
生产消息

消费消息