简介
首先postgresql是支持python的,在安装postgresql数据库的时候需要执行python支持。可以使用python进行写fundcation 自然也就可以自定义funcation去读取HDFS文件,以此替换掉hive的,省去中间频繁切换服务器的麻烦。
安装postgresql
useradd postgres --创建用户(此时会默认指定的用户组,这个用户名称建议保持一致)
cd /home/postgres/ --进入新建用户指定目录
curl -O https://ftp.postgresql.org/pub/source/v15.3/postgresql-15.3.tar.gz --下载安装包
tar -zxvf postgresql-15.3.tar.gz --解压压缩包
yum install -y bison flex readline-devel libicu-devel zlib-devel zlib zlib-devel gcc gcc-c++ openssl-devel python3-devel python3 --下载安装数据库基本依赖包,postgresql从14开始需要python3以上版本的支持
cd postgresql-15.3
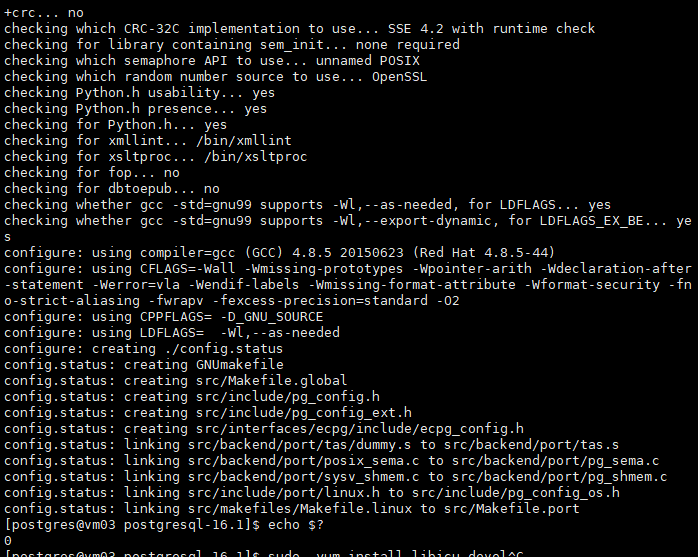
./configure --prefix=/home/postgres/pg --with-openssl --with-python #拟安装至/home/postgres/pg
编译完成之后,使用echo $? 返回值为0 表示编译无报错信息
初始化数据库
mkdir /home/postgres/pg --创建装载所需文件夹
sudo chown -R postgres:postgres /home/postgres/pg --进行授权
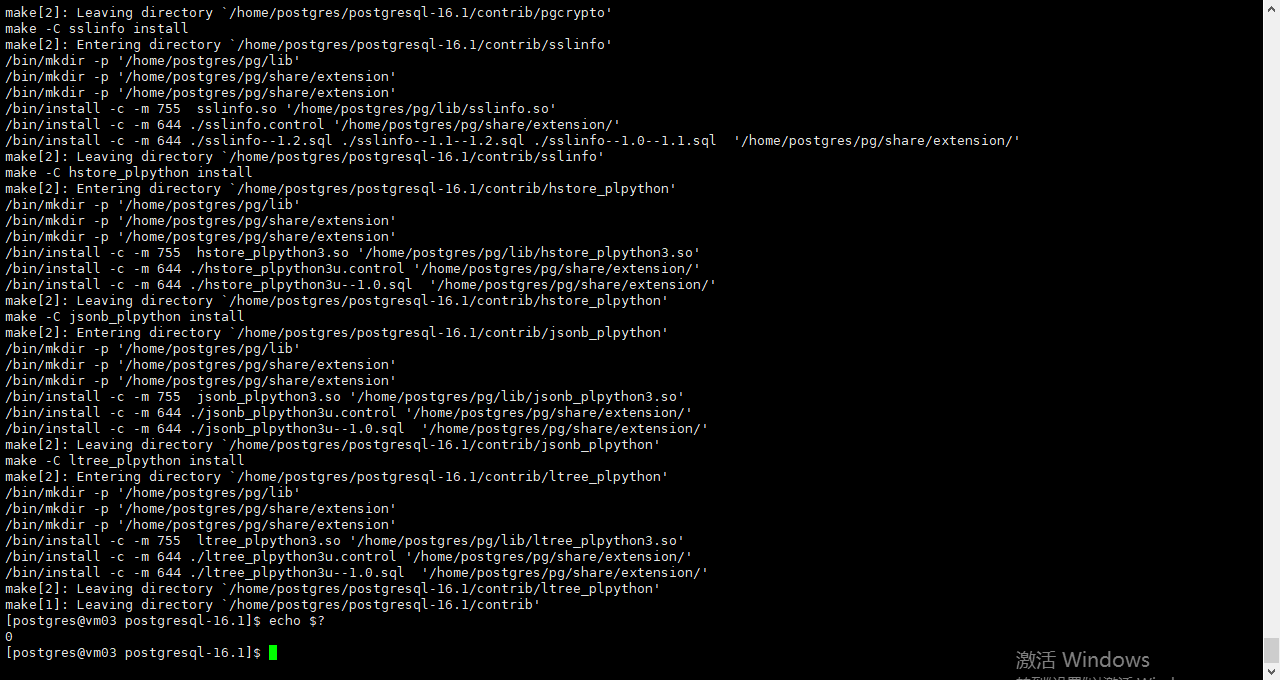
make world && make install-world
同样在构建完成之后使用echo $? 查看是否有报错信息返回值为0 继续执行一下操作
vi ~/.bash_profile
export PATH=/home/postgres/pg/bin:$PATH --指定bin文件路径 确保准备
export PGDATA=/home/postgres/pg/data --指定data文件路劲 在初始化时会将data装载这个路径
source ~/.bash_profile --加载环境变量内容
cd /home/postgres/pg/bin --进入指令包
./initdb -D $PGDATA -U postgres -W --初始化数据库指定超级用户名和密码
pg_ctl start --启动数据库
pg_ctl status --查看数据库运行状态
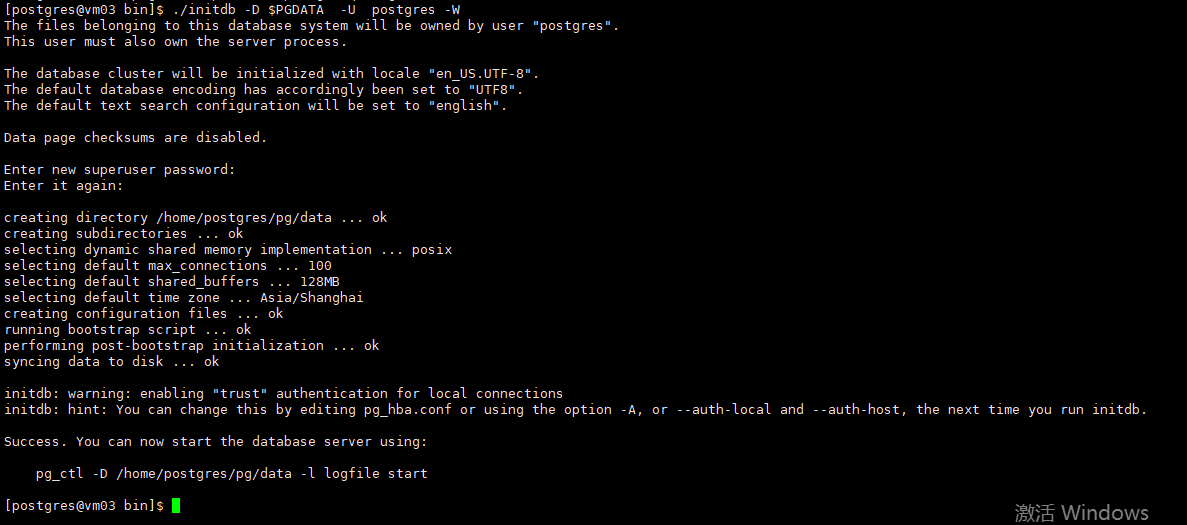
如果需要外部数据库连接器链接到PG请自行修改防火墙文件和监听参数,此处不再累述。
创建支持读取HDFS文件的fundcation
python有多个moudle可以支持读取hdfs文件内容
首先在postgresql创建python3的拓展
CREATE EXTENSION plpython3u CASCADE;
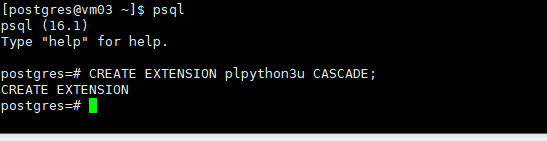
在postgresql创建一个测试数据库表,然后将其推送到HDFS上去
CREATE TABLE pg_hdfs AS SELECT id ,md5(id::varchar) FROM generate_series(1,1000000) AS id ;
再讲表数据copy出来,
postgres=# copy pg_hdfs to '/home/postgres/pg_hdfs.csv' DELIMITER ',' CSV HEADER;
COPY 1000000
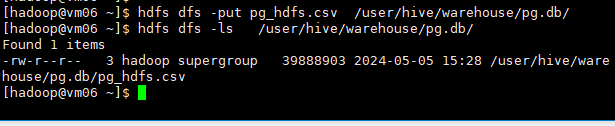
将数据推送到HDFS文件系统
[hadoop@vm06 ~]$ hdfs dfs -put pg_hdfs.csv /user/hive/warehouse/pg.db/
[hadoop@vm06 ~]$ hdfs dfs -ls /user/hive/warehouse/pg.db/
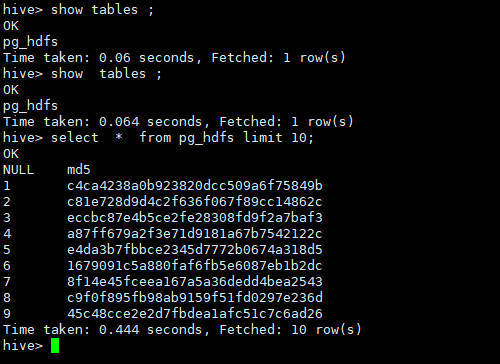
通过load 加载数据此时的hive 是可以正常查看该文件内容
hive> CREATE TABLE IF NOT EXISTS pg_hdfs(
> id int,
> md5 string)
> row format delimited
> fields terminated by ',';
OK
Time taken: 0.829 seconds
hive> load data inpath '/user/hive/warehouse/pg.db/pg_hdfs.csv' into table pg.pg_hdfs;
Loading data to table pg.pg_hdfs
OK
Time taken: 1.289 seconds
此时得hive 是可以读取到pg_hdfs.csv文件内容得。
安装对应读取hdfs的包,本文使用spark进去读取该文件内容
pip3 install --upgrade pip
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
创建可接受远程hdfs文件的的type
保持和表结构一致,
CREATE TYPE public.hdfs AS
(
id integer,
md5 character varying(200)
);
创建可读取hdfs的function
CREATE OR REPLACE FUNCTION pg_hdfs(host varchar(2000))
RETURNS SETOF hdfs
AS $$
from pyspark.sql import SparkSession
def read_hdfs_file():
spark = SparkSession \
.builder \
.master("local[1]") \
.appName("PySpark read HDFS file") \
.getOrCreate()
df = spark.read.load(f"{host}",
format="csv", sep=",", inferSchema="true", header="true")
# 获取 id 和 md5 列数据,并逐个返回
id_md5_data = df.select("id", "md5").collect()
for row in id_md5_data:
yield (row["id"], row["md5"])
spark.stop()
# 调用函数并返回结果
if __name__ == '__main__':
for result_id_md5 in read_hdfs_file():
yield result_id_md5
$$ LANGUAGE plpython3u;
关于yield关键字:
yield :yield 用于生成迭代器,并可以逐个地生成值,而不是一次性生成所有值。追行抓取保证数据的一一对应。
RETURNS SETOF hdfs:是指向返回数据记录。
此时的funcation可以像表一直执行关联和函数过滤
select * from pg_hdfs('hdfs://10.0.0.107:8020//user/hive/warehouse/pg.db/pg_hdfs/pg_hdfs.csv') where id < 10
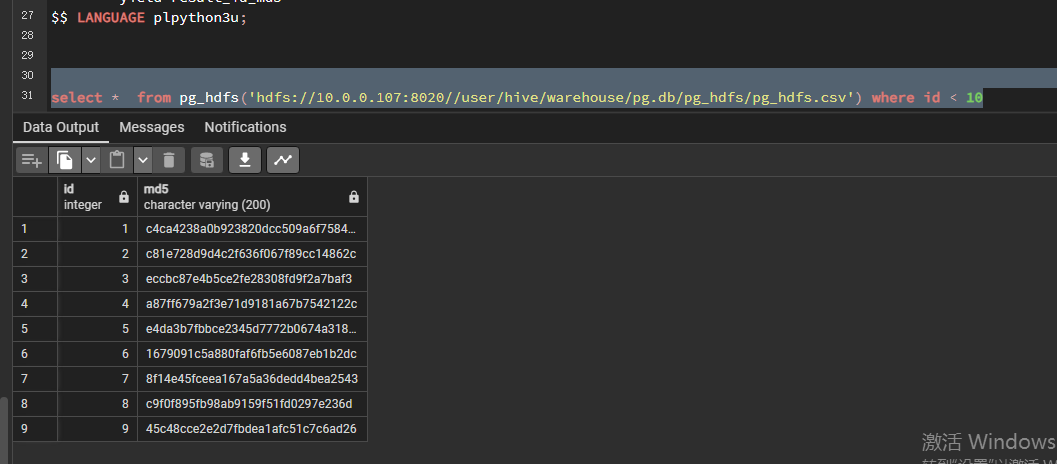
测试用于表关联
select a.id , b.id from pg_hdfs('hdfs://10.0.0.107:8020//user/hive/warehouse/pg.db/pg_hdfs/pg_hdfs.csv') as a
left join public.pg_hdfs b
on a.id = b.id
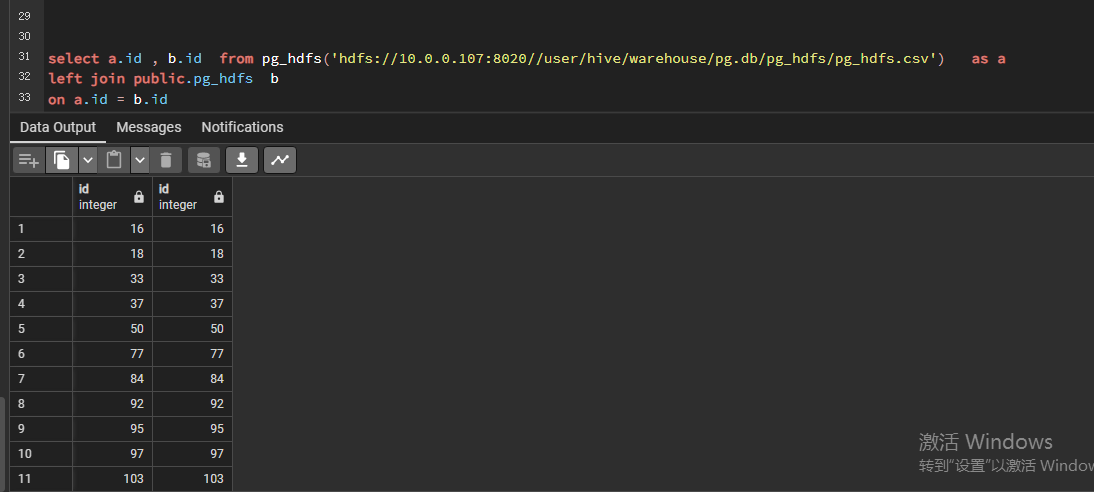
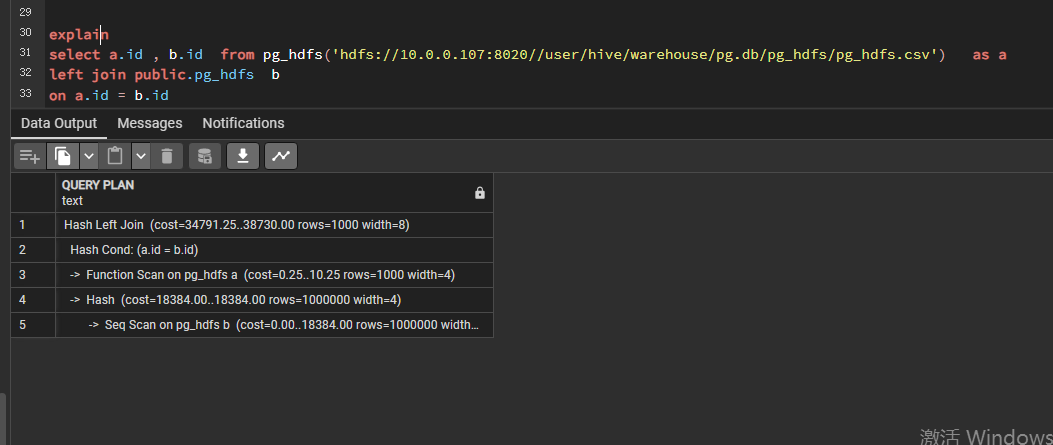
查看执行计划
此方法对于比较喜欢使用python进行编程的小伙伴比较友好,使用FDW也可以,对于对postgresql不是很熟悉的博主认为操作还是比较繁琐。
这个方法的缺点就是性能还是比较差。