大家好,随着人工智能(AI)的蓬勃发展,一个新兴领域语言模型运维(LLMOps)正逐渐成为关注的焦点。LLMOps专注于对大型语言模型(LLMs),例如OpenAI的GPT系列,进行全生命周期的管理,确保高效运作和持续优化。
本文将介绍LLMOps的核心理念,包括其重要性、构成要素、挑战和未来前景,并分析其在AI快速发展的大背景下所扮演的关键角色。
1.LLMOps简介
LLMOps,即语言模型运维,指的是管理和部署像OpenAI的GPT系列这样的大型语言模型(LLMs)所涉及的实践和流程。LLMOps包含一系列活动,包括:
-
模型训练和开发:包括收集和准备数据集,在这些数据集上训练模型,并根据性能指标迭代改进模型。
-
模型部署:将LLMs部署到生产环境中,用户可以访问或集成到应用程序中。
-
监控和维护:持续监控生产中LLMs的性能,确保它们按预期运行,并根据需要进行维护。
-
扩展和优化:扩展基础设施以支持LLMs的使用,并优化模型和基础设施以提高性能和成本效率。
-
伦理和法律合规:确保LLMs的使用遵守伦理标准并符合法律规范,特别是在隐私、偏见和公平性等方面。
-
版本控制和模型管理:管理不同版本的语言模型,包括用新数据或改进更新模型和管理每个模型版本的生命周期。
总的来说,LLMOps是一个端到端的过程,涵盖了语言模型从开发初期到部署阶段,再到生产环境中的运维管理,贯穿了整个生命周期的每一个环节。
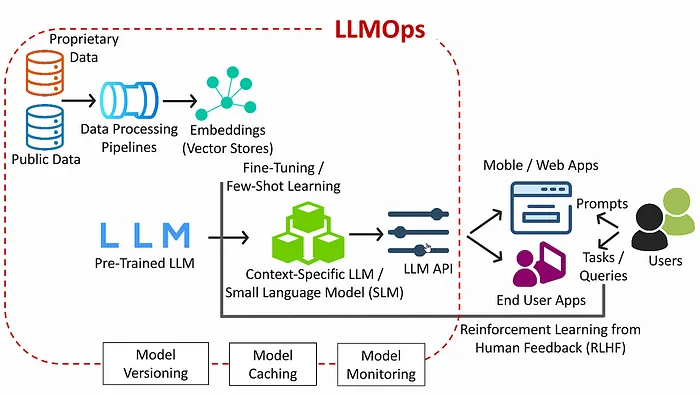
2.重要性
LLMOps之所以至关重要,是因为关系到大型语言模型(LLMs)在技术、医疗保健、金融和教育等多个领域的迅猛增长和广泛应用。LLMs已经成为推动自然语言处理(NLP)能力发展的核心力量,为会话AI、情感分析、内容生成和语言翻译等提供了创新的解决方案。随着这些模型规模的不断扩大和复杂度的日益增加,如何高效管理它们的生命周期变得尤为关键。这不仅能够充分发挥LLMs的巨大潜力,同时也能有效降低与模型部署和使用相关的风险。
3.核心要素
3.1 模型开发与训练
这是构建语言模型的基石,包括数据的收集、模型架构的设计以及训练过程的执行。在这一阶段,确保训练数据的高质量和多样性是关键,有助于减少偏见,提升模型的准确性和公平性。
3.2 部署与集成
将语言模型(LLMs)通过API接口或嵌入应用程序的方式,使其对最终用户开放使用。这一步骤要求有坚实的基础设施支撑,以应对计算需求,同时保证模型的高效集成,为用户提供无缝体验。
3.3 监控与维护
在生产环境中对LLMs进行持续监控,对于及时发现并解决性能问题、异常情况以及伦理问题(如偏见和滥用)非常重要。维护工作包括模型的更新、微调和软件依赖的修复。
3.4 扩展与优化
随着AI服务需求的增加,扩展基础设施和优化性能成为必要。这不仅有助于控制成本,还能提升服务效率,需要在计算资源、降低延迟和算法优化之间找到平衡。
3.5 伦理与合规管理
遵循伦理准则和法律标准是LLMOps不可或缺的一部分。这涉及到确保模型的操作和决策过程在隐私保护、公平性、透明度和可问责性方面都符合要求。
3.6 版本控制与生命周期管理
对不同版本的LLMs及其生命周期进行有效管理,对于保持系统的稳定性和实现持续改进至关重要。这包括对模型版本的控制、模型的退役以及向新模型过渡的平滑处理。
4.挑战
LLMOps在实践中面临着众多挑战,主要归因于大型语言模型(LLMs)本身的复杂性以及人工智能(AI)技术的快速进步。其中一些挑战包括:
-
数据隐私与安全:在管理海量数据的同时,确保隐私和安全是一大难题,尤其是需要面对GDPR、CCPA等严格的数据保护法规。
-
偏见与公平性:要打造无偏见、公平的模型,需要持续不断地进行监控、评估,并利用多样化的数据集对模型进行再训练。
-
资源管理:随着大型语言模型规模的不断扩大,如何有效管理计算资源,以平衡性能和成本,成为一个持续的挑战。
-
人工智能技术的迅速发展要求LLMOps必须保持高度警觉,快速适应新技术,以确保运维实践的时效性和有效性。
5.前景展望
语言模型运维(LLMOps)的未来发展前景乐观,其发展特点预计将集中在三个方面:对自动化技术的进一步应用,对人工智能伦理问题的持续关注,促进不同学科领域间更紧密的合作。
自动化技术的融入将极大简化语言模型从训练到部署的流程,提升效率并降低人为错误。同时,AI伦理将持续成为焦点,推动开发更多保障语言模型负责任使用的框架和工具。此外,数据科学、软件工程、伦理学等不同领域的专家需要紧密合作,这对于塑造LLMOps的未来具有重大意义,这种跨界合作能够促进技术合理性与伦理责任感的增强,推动创新的同时确保技术的健康发展。简言之,LLMOps的未来将是技术与伦理并重,自动化与合作共进的时代。
6.构建LLMOps流程
在Python中创建一个完整的LLMOps流程涉及多个步骤,首先要生成合成数据集,然后训练模型,接着用相关指标对模型进行评估,之后绘制评估结果,最后对这些结果进行解释。下面逐一解析这些步骤,用一个简化的示例以展示整个过程。
6.1 创建合成数据集
在本示例中,将生成一个文本分类任务的合成数据集。
import pandas as pd
import numpy as np
# 生成合成数据
np.random.seed(42)
data_size = 1000
text_data = ['Sentence ' + str(i) for i in range(data_size)]
labels = np.random.randint(0, 2, size=data_size)
# 创建一个DataFrame
df = pd.DataFrame({'text': text_data, 'label': labels})
6.2 预处理与模型训练
为了演示,使用一个简单的模型,如逻辑回归分类器。
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(df['text'], df['label'], test_size=0.2, random_state=42)
# 向量化文本数据
vectorizer = CountVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
# 训练模型
model = LogisticRegression(random_state=42)
model.fit(X_train_vec, y_train)
6.3 评估模型
使用准确率和混淆矩阵作为评估模型的指标。
from sklearn.metrics import accuracy_score, confusion_matrix
# 预测和评估
predictions = model.predict(X_test_vec)
accuracy = accuracy_score(y_test, predictions)
conf_matrix = confusion_matrix(y_test, predictions)
print(f"准确率:{accuracy}")
print(f"混淆矩阵:\n{conf_matrix}")
6.4 结果可视化
可以通过绘制混淆矩阵来直观地表示模型的性能。
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(conf_matrix, annot=True, fmt='g')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('混淆矩阵')
plt.show()
6.5 结果解读
解释将取决于模型的性能指标。具体来说:
-
准确率表明了模型的整体正确性。
-
混淆矩阵显示了真正例、真负例、假正例和假负例的预测数量,为深入理解模型的分类行为提供了直观的视角。
在实际LLMOps应用场景中,模型的解释与评估仅是整个流程的一部分。这个完整的流程还涵盖模型版本控制、持续集成与持续部署(CI/CD)的实践、以及对模型进行持续监控和根据新数据或性能指标进行更新等环节。
本示例只是提供了一个简化的视角,而在实际生产环境中,LLMOps的实施需要更复杂的数据处理、模型训练、评估和运维策略,以确保系统的稳定性和高效性。






![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-15.5讲 GPIO中断实验-通用中断驱动编写](https://img-blog.csdnimg.cn/direct/c1b62563d3d046d0a6d37536970f031f.png)