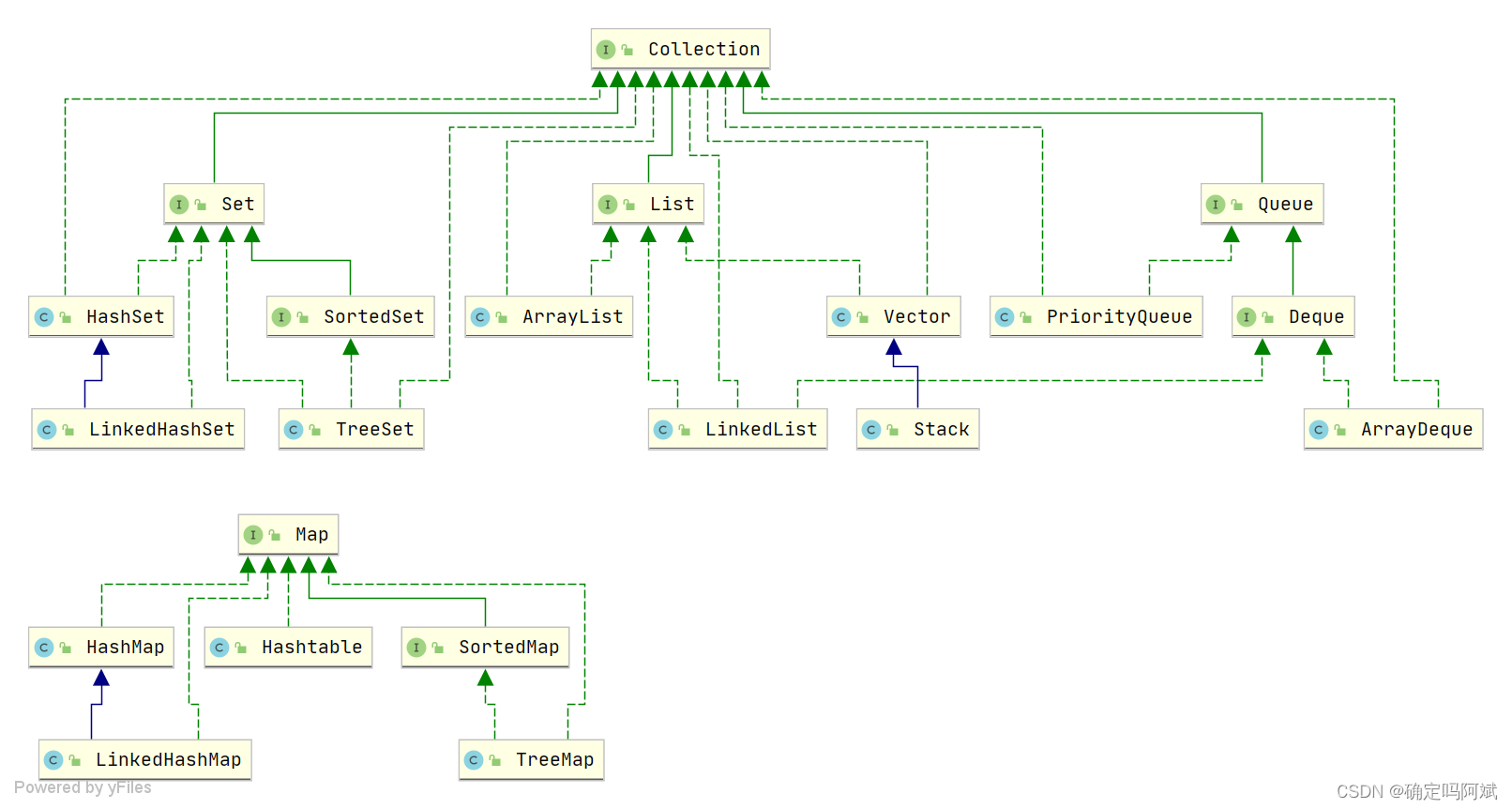
集合的整体框架
Java 的集合,也可以叫做容器,根据集合的整体框架可以看出,主要是两大集合接口:第一个是 Collection 接口,主要用来存放单一的元素对象;另一个是 Map 接口,主要用于存储键值对。
Collection 接口有三个子类,List、Set、Queue,下面是抽象类和具体实现类,主要说明具体实现类。常见的有 ArrayList、LinkedList、HsahSet、LinkedHashSet、HsahMap、LinkedHshMap等。
集合接口
| 接口 | 描述 |
| Collection 接口 | 最基本的集合几口,一个Collection 代表了一组 Object,即 Collection 的元素,Java 提供了继承于它的子接口List、Set、Queue。 存储一组不唯一,无序的对象。 |
| List 接口 | 特点:有序,不唯一。 使用此接口能精确控制每个元素插入的位置,能够通过索引(类似数组的下标)来访问集合中的元素,同样的,起始于元素索引为 0。 |
| Set 接口 | 特点:无序,唯一。 |
| Queue 接口 | 队列,按特定的排序规则来确定先后顺序,存放的元素是有序的、可重复的 |
| Map 接口 | 特点:存放键值对(key-value),key 无序且唯一,value 是无序不唯一的。 算法上常见用来统计数量。 |
List 和 Set 的区别
特点不同,list 存储的数据有序不唯一,set 存储的数据无序且唯一。
因为索引的存在,list 检索的效率比 set 高,但是 set 的删除和插入的效率高。List 插入元素会改变其他元素的位置。
list 和数组类似,可以动态增长,比如 ArrayList 。
List 接口的实现类
ArrayList
继承并实现了 List 接口,基于动态数组实现,相较于 Array(静态数组) 使用起来更加灵活。
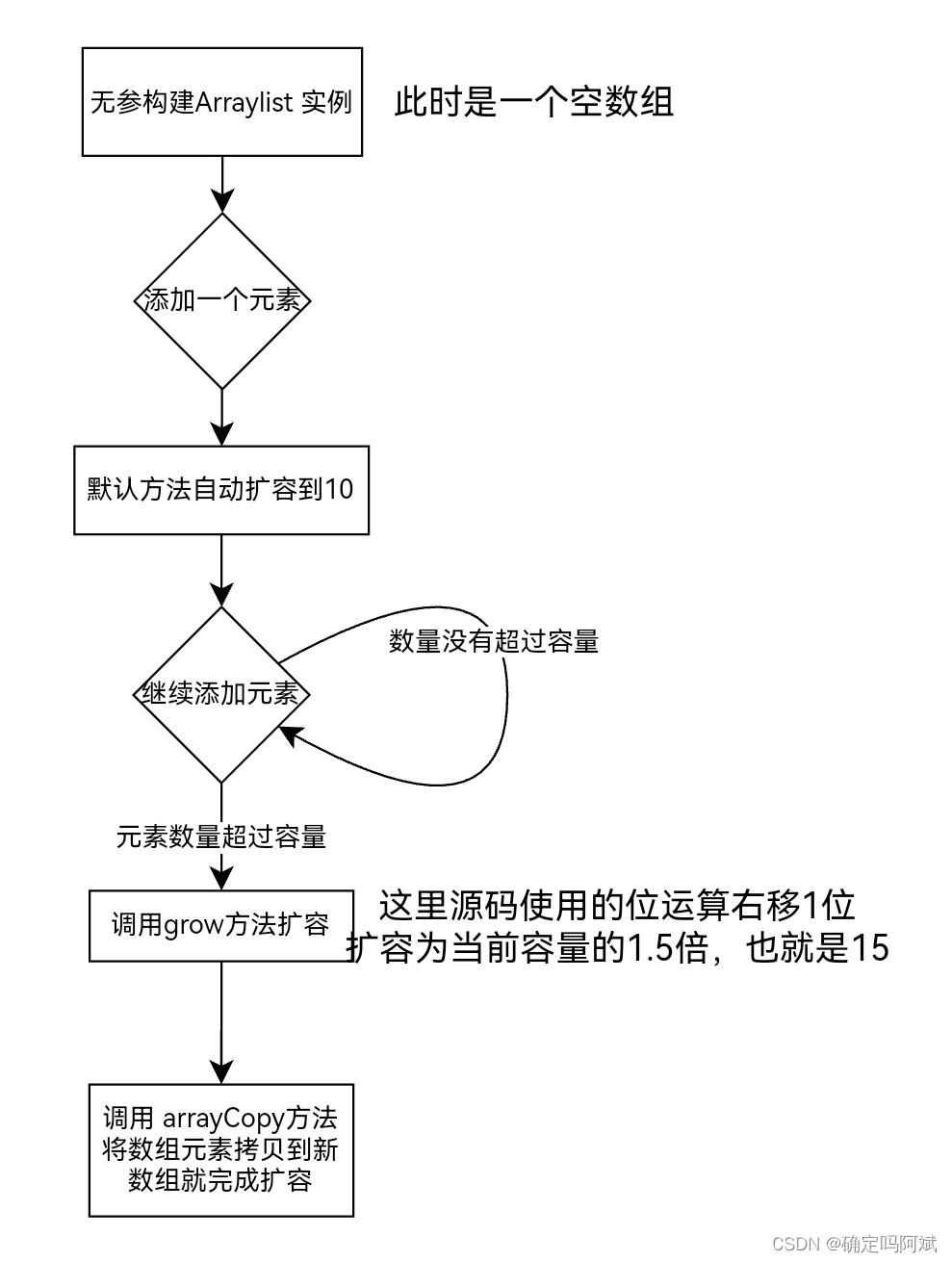
1. ArrayList 动态数组,会根据实际存储的元素动态扩容或缩容,而 Array 被创建之后就不能修改长度,这里涉及到知识点 ArrayList 动态扩容机制。
2. ArrayList 可以使用泛型来确定存储的类型,对于存储的基本数据类型,必须使用对应的包装类(int 的包装类 Integer)来存储。
顺带一提,常见的创建 Arraylist 的方法是
List<Integer> llist = new ArrayList<>();List 是接口,ArrayList 是具体实现。主要是为了灵活性和可扩展性,这里可以使用List已经定义的方法,不可以使用Arraylist自己的方法,当需要将ArrayList改成其他实现时,只需要将创建集合实例的代码改成想要创建的对象,不用在去修改其他方法代码。
ArrayList 扩容机制
LinkedList
不同于ArrayList,LinkedList 底层是双向链表。根据链表的特性,每个节点不仅保存了每个元素,还保存了下一个元素的引用。支持随机访问,因为提供了get方法,但是并不高效,假设数据量比较大,需要从首个元素开始遍历,然后查看节点对下一个元素的引用是否为需要的元素,一直循环。
Set 的实现类
对比HashSet、LinkedHashSet、TreeSet。最大的区别就是各自的底层实现不同,分别是哈希表(基于HashMap实现),链表哈希表和红黑树。
Queue
单列队列,遵循队列的先进先出原则,就像排队坐车,先来后到。
Map
HashMap的底层实现
这是一道经典的面试题。在JDK 1.8 以前,HashMap 的底层是数组+链表,通过 哈希函数激素那元素的哈希值,判断元素存储的位置。如果当前位置已经存在了元素,那么就进行判断是否相同,如果不同,就通过拉链法,在数组的后面加上链表来解决哈希冲突。
在JDK1.8之后,底层在数组和链表的基础上,为了解决因为哈希冲突导致链表深度过高的问题,引入了红黑树解决因为深度高导致的查询效率慢。
链表转红黑树:当链表长度大于8时,并且此时数组的容量不小于64时,会把链表转换为红黑树。
红黑树转链表:相反的,因为删除元素导致红黑树的节点不大于6个时,红黑树会重新转换为链表。
为什么选择8作为转换红黑树的阈值。因为根据测算,哈希冲突导致链表长度达到8的概率非常小,几乎到了百万分之一。
为什么选择6作为红黑树转换为链表的阈值。因为如果选取7为阈值,当出现相同元素频繁插入删除,会导致频繁转换,会影响性能。
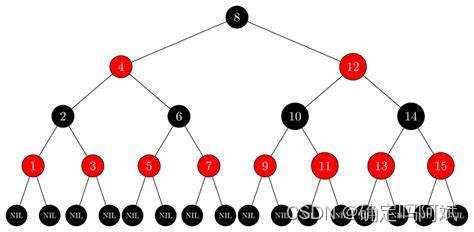
红黑树的特征
1. 节点颜色:每个节点的都有颜色,红色和黑色。
2. 根节点:根节点总是黑色的
3. 叶子节点:叶子节点都是空节点(NIL 节点)都是黑色。
4. 红色节点限制:不存在连续两个红的节点,红色节点都被黑色节点隔开
5. 路径的和节点:从任一个节点到其后代叶子节点的路径上,包含相同数目的黑色节点。
二叉查找树在一些极端的情况下会出现深度过高,退化成链表的情况,此时查询效率比较低。
之后又出现了自平衡的查找树,比如 AVL,红黑树等。通过定义一些性质,将任意节点的左右子树的高度差控制在规定范围内,达到平衡状态。
不过普通的平衡二叉树可能出现某个路径深度相较其他路径更高,同样会导致效率降低。
红黑树根据后两个而性质,将每个路径的深度差保证在一定范围内。最长的路径不会超过最短路径的两倍。
线程安全的集合
上述的集合都是线程不安全的。线程安全的集合常见的有 ConcurrentHashMap 和 Hashtable。
二者的区别:
首先是底层结构。ConcurrentHashMap 采用的和 HashMap 一样是 数组+链表(红黑树),Hashtable 使用的是 数组+链表 的形式。链表是为了解决哈希冲突存在的。
实现线程安全的方式
在 JDK1.7的时候,ConcurrentHashMap 对整个桶组进行了分割分段,然后对每段进行加锁,多线程访问不同数据段的数据。
在 JDK 1.8的时候,ConcurrentHashMap 使用 数组和链表红黑树来实现。并发控制使用 synchronized 和 CAS 算法来操作。
Hashtable 使用 synchronized保证线程安全,效率比较低,多个线程访问同一个方法是可能会出现阻塞。


![[Linux][网络][数据链路层][一][以太网][局域网原理]详细讲解](https://img-blog.csdnimg.cn/direct/1d1b3f9acd794e83ab068e1b3251c4d5.png)