Apache Flume概述

1.Flume定义
Flume是cloudera(CDH版本的hadoop) 开发的一个分布式、可靠、高可用的海量日志收集系统。
它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到HDFS、Hbase,简单来说flume就是收集日志的。
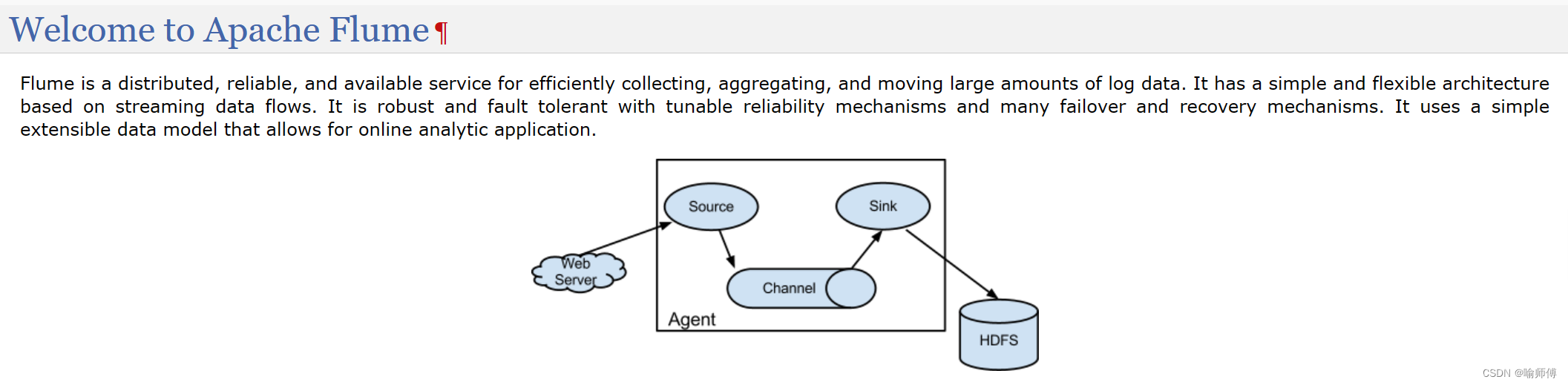
2.Flume基础架构
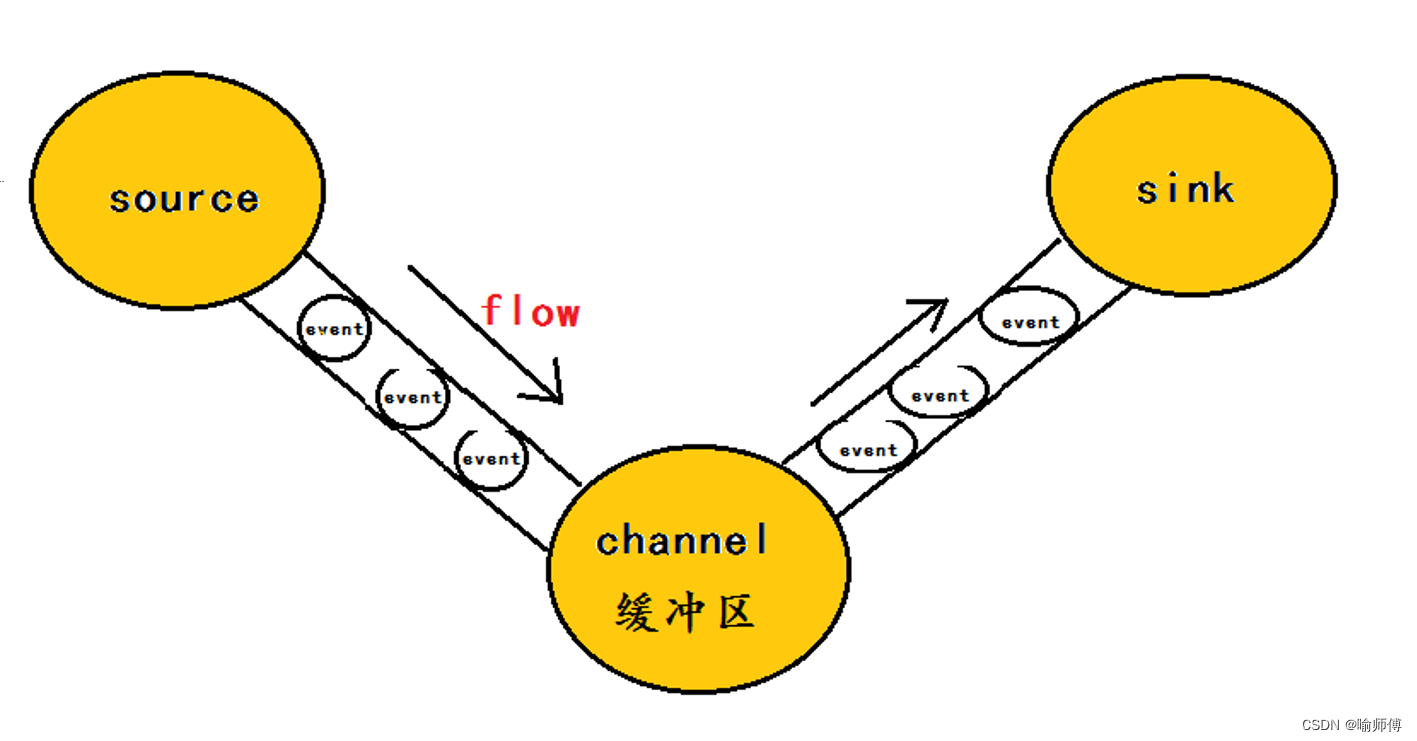
Flume 运行的核心是 Agent,Flume以agent为最小的独立运行单位,含有三个核心组件,分别是source、 channel、 sink。
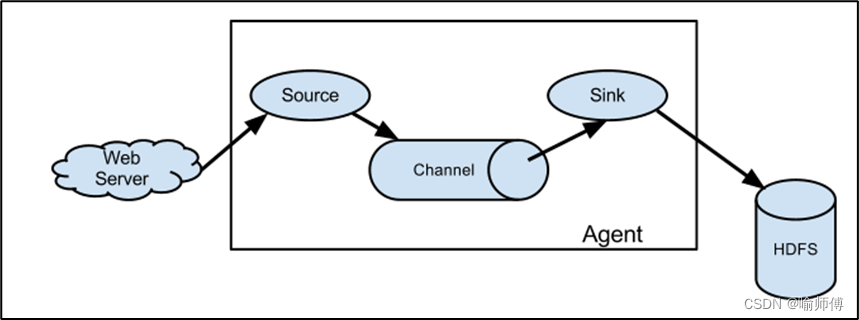
1. Agent(代理):
-
Agent 是 Flume 的基本工作单元,负责在节点上启动、运行和管理整个 Flume 进程。
-
Agent主要有3个部分组成,
Source、Channel、Sink。 -
Agent 可以包含一个或多个
Source、Channel和Sink,通过这些组件来实现数据的收集、传输和存储。 -
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的地。
-
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。

2. Source(数据源):
Source是Flume中用于接收数据的组件,负责从各种不同的数据源(如日志文件、网络端口、消息队列等)收集数据。Flume提供了多种不同类型的Source,用户可以根据需求选择合适的Source来收集数据。
| Source 类型 | 描述 |
|---|---|
| Avro Source | Avro Source 允许 Flume 接收 Avro 格式的数据,用于高性能数据交换。Avro 是一种基于二进制编码的数据序列化格式,通常用于跨语言的数据交换。 |
| Thrift Source | Thrift Source 允许 Flume 接收 Thrift 格式的数据,常用于构建高效的分布式系统。Thrift 是一个跨语言的远程服务调用框架,支持多种语言,用于定义和创建跨语言的服务。 |
| Netcat Source | Netcat Source 允许 Flume 通过网络接收数据,使用基于 TCP 或 UDP 协议的 Netcat 工具。它适用于通过网络实时传输数据的场景,如实时日志收集。 |
| Spooling Directory Source | Spooling Directory Source 允许 Flume 监听指定目录中的文件,实时收集文件内容并发送到 Channel 中。这种 Source 适用于监控文件系统中新增的文件,例如日志文件的收集。 |
| Exec Source | Exec Source 允许 Flume 执行外部命令,并将命令的输出作为数据源发送到 Channel 中。它可以用于收集各种类型的数据,例如运行 shell 脚本、调用其他程序的输出等。 |
| HTTP Source | HTTP Source 允许 Flume 监听指定的 HTTP 端口,接收通过 HTTP 协议发送的数据。这种 Source 适用于接收 Web 服务或其他应用程序通过 HTTP POST 请求发送的数据。 |
3. Channel(通道):
Channel是Flume中用于存储和传输数据的缓冲区,负责暂存从 Source 收集到的数据,以便后续传输给 Sink。- Flume 提供了多种不同类型的 Channel,如内存通道、文件通道等,用户可以根据需求选择合适的 Channel。

| Channel 类型 | 描述 |
|---|---|
| Memory Channel | 将事件存储在内存中,适用于快速数据传输和处理,但需要考虑内存限制。适用于数据流速较快、数据量较小的场景。 |
| File Channel | 将事件存储在磁盘文件中,适用于大容量数据和持久性需求。可以处理大量数据和长时间故障恢复。 |
| JDBC Channel | 将事件存储在关系型数据库中,适用于需要与现有数据库集成的场景。可以通过 JDBC 接口与各种数据库系统集成,方便数据存储和管理。 |
| Kafka Channel | 将事件存储在 Apache Kafka 中,适用于大规模分布式数据流处理。可以利用 Kafka 提供的高吞吐量和持久性来处理大量数据。 |
| Spillable Memory Channel | 是内存通道的改进版本,当内存不足时可以将事件溢出到磁盘上的临时文件中。结合了内存通道和文件通道的优点,适用于处理大量数据但又要求高性能的场景。 |
| HDFS Channel | 将事件存储在 Hadoop 分布式文件系统中,适用于与 Hadoop 生态系统集成的场景。可以实现数据持久性和容错性,并支持大规模数据存储和处理。 |
4. Sink(数据目的地):
Sink是Flume中用于发送数据的组件,负责将从Channel中取出的数据发送到指定的目的地(如 Hadoop HDFS、HBase、数据库等)。- Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
- 一个 Sink 只能从一个 Channel 读取数据,而一个 Channel 可以发送数据给多个 Sink。
- Flume 提供了多种不同类型的 Sink,用户可以根据需求选择合适的 Sink 来发送数据。
| Sink 类型 | 描述 | 示例 |
|---|---|---|
| HDFS Sink | 将数据写入 Hadoop 分布式文件系统(HDFS)中,适用于大规模数据存储和批量处理。 | 将日志数据写入 HDFS 中进行长期存储。 |
| Logger Sink | 将数据输出到标准输出或日志文件中,适用于调试和监控。 | 在开发和测试阶段,将数据打印到控制台进行调试。 |
| Avro Sink | 将数据以 Avro 格式发送到指定的 Avro 接收器,适用于实时数据传输和多语言支持。 | 将事件流发送到远程 Avro 服务器进行实时处理。 |
| Thrift Sink | 将数据以 Thrift 格式发送到指定的 Thrift 接收器,适用于跨语言数据交换。 | 将数据发送到使用 Thrift 协议的远程服务端进行处理。 |
| Kafka Sink | 将数据发送到 Apache Kafka 中,适用于大规模实时数据处理和流式计算。 | 将事件流发送到 Kafka 主题,供后续处理和分析。 |
| FlumeNG Sink | 将数据发送到另一个 Flume 代理,适用于构建复杂的数据流拓扑结构。 | 将数据流路由到不同的 Flume 代理进行分布式处理。 |
| ElasticSearch Sink | 将数据写入 ElasticSearch 中,适用于全文搜索和实时数据分析。 | 将日志数据索引到 ElasticSearch 中以便后续查询和分析。 |
| JDBC Sink | 将数据写入关系型数据库中,适用于数据持久化和集成到现有数据库系统中。 | 将数据写入 MySQL、Oracle 等关系型数据库进行存储。 |
5. 拦截器(Interceptors):
- 拦截器是 Flume NG 中的一种可选组件,用于对数据进行实时处理和转换。
- 用户可以通过配置拦截器来实现诸如数据过滤、数据格式转换等功能,从而更灵活地处理数据流。
6. 通道选择器(Channel Selectors):
- 通道选择器是 Flume NG 中的一种可选组件,用于将数据分发到不同的通道。
- 当一个 Agent 包含多个 Channel 时,可以通过配置通道选择器来决定如何将数据分发到这些通道中。
3.Flume两个版本的区别
Apache Flume 在演进过程中经历了从 Flume OG(Original)到 Flume NG(Next Generation)的重大改进。
-
Flume OG(原始版本):
- Flume OG 是 Apache Flume 最初的版本,其设计目标是简化大规模日志数据的收集和传输。
- 该版本的架构较为简单,主要由 agent、source、sink 和 channel 四个核心组件构成。
- Flume OG 的性能和可扩展性相对较低,且在处理大规模数据时可能出现性能瓶颈。
-
Flume NG(下一代版本):
- Flume NG 是对 Flume OG 的重大改进和升级,旨在提高性能、可靠性和可扩展性。
- 该版本引入了全新的架构,采用了事件驱动的设计模式,使得数据流能够更高效地处理和传输。
- Flume NG 的架构更为灵活,引入了更多的组件和插件,如拦截器(interceptors)、通道选择器(channel selectors)等,用户可以根据需求定制和扩展数据流处理逻辑。
- Flume NG 支持复杂的拓扑结构,允许用户构建多层级的数据流管道,从而实现更灵活的数据收集和传输。
- 此外,Flume NG 还引入了更多的性能优化和安全性功能,使得其适用于更广泛的使用场景,如大数据分析、日志监控等。