文章信息
文章题为“Do Transformers Really Perform Bad for Graph Representation?”,该文章发表于2021年NeurIPS会议上。文章提出Graphormer图预测任务。
摘要
Transformer架构已经成为许多领域的主导选择,例如自然语言处理和计算机视觉。此外,与主流GNN变体相比,它在流行的图级预测排行榜上的表现并不具有竞争力。因此,Transformer如何在图表示学习中表现良好仍然是一个谜。文章提出Graphormer来解决这个谜题,Graphormer建立在标准的Transformer架构之上,并且可以在广泛的图表示学习任务中获得出色的结果。文章为了将图的结构信息编码到模型中,提出了几种简单而有效的结构化编码方法,以帮助Graphormer更好地对图结构数据进行建模。此外,文章在数学上描述了Graphormer的表达能力,并展示了文章对图的结构信息进行编码的方法,许多流行的GNN变体都可以作为Graphormer的特殊情况。
具体而言,首先,文章提出了一种Graphormer中的中心性编码(Centrality Encoding)来捕获图中节点的重要性。在一个图中,不同的节点可能具有不同的重要性,例如,在社交网络中,名人被认为比大多数网络用户更有影响力。然而,这些信息并没有反映在自关注模块中,因为自关注模块主要使用节点语义特征来计算相似度。为了解决这个问题,我们提出在Graphormer中对节点中心性进行编码。特别地,文章利用度中心性进行中心性编码,其中根据每个节点的度分配一个可学习向量,并将其添加到输入层的节点特征中。
其次,文章提出了一种新的空间编码方法来捕捉节点之间的结构关系。区分图结构数据与其他结构化数据(语音、图像)的一个显著几何特性是,图结构数据中不存在嵌入图的规范网格。实际上,节点只能位于非欧几里得空间中,并且由边连接。为了对这些结构信息建模,文章根据每个节点对的空间关系分配一个可学习的嵌入。出于通用性的目的,文章选择任意两个节点之间最短路径的距离作为演示,这将被编码为softmax注意中的偏差项,并帮助模型准确地捕获图中的空间依赖性。此外,有时在边缘特征中还包含额外的空间信息,例如分子图中两个原子之间的键的类型。文章设计了一种新的边缘编码方法,进一步将这种信号带入Transformer层。
准备知识
图神经网络(GNN):设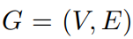 表示图结构,其中V为节点集,E为边集,每个结点的特征向量为
表示图结构,其中V为节点集,E为边集,每个结点的特征向量为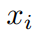 。GNN旨在学习图中每个节点的表示。通常而言通常,GNN遵循一种学习模式,通过聚合节点的第一阶或高阶邻居的表示来迭代更新节点的表示。该过程可以由下式表示:
。GNN旨在学习图中每个节点的表示。通常而言通常,GNN遵循一种学习模式,通过聚合节点的第一阶或高阶邻居的表示来迭代更新节点的表示。该过程可以由下式表示:
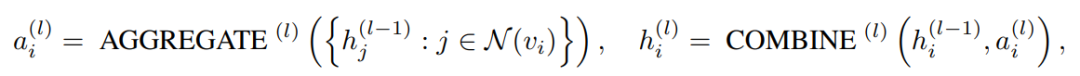
其中,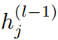 表示节点j在l-1层的节点表示,
表示节点j在l-1层的节点表示,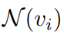 表示节点i的一阶或高阶邻居。此外,在图表示任务在,还会存在一个READOUT函数,用于聚合节点的特征并获得图最终的表示:
表示节点i的一阶或高阶邻居。此外,在图表示任务在,还会存在一个READOUT函数,用于聚合节点的特征并获得图最终的表示:
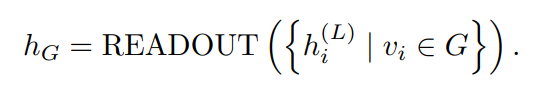
Transformer:Transformer架构由Transformer层的组合组成。每个Transformer层有两个部分:一个自关注模块和一个位置前馈网络(FFN)。其具体公式如下,与常见的Transformer相同此处不再赘述。
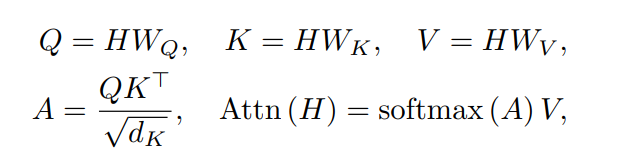
Graphormer
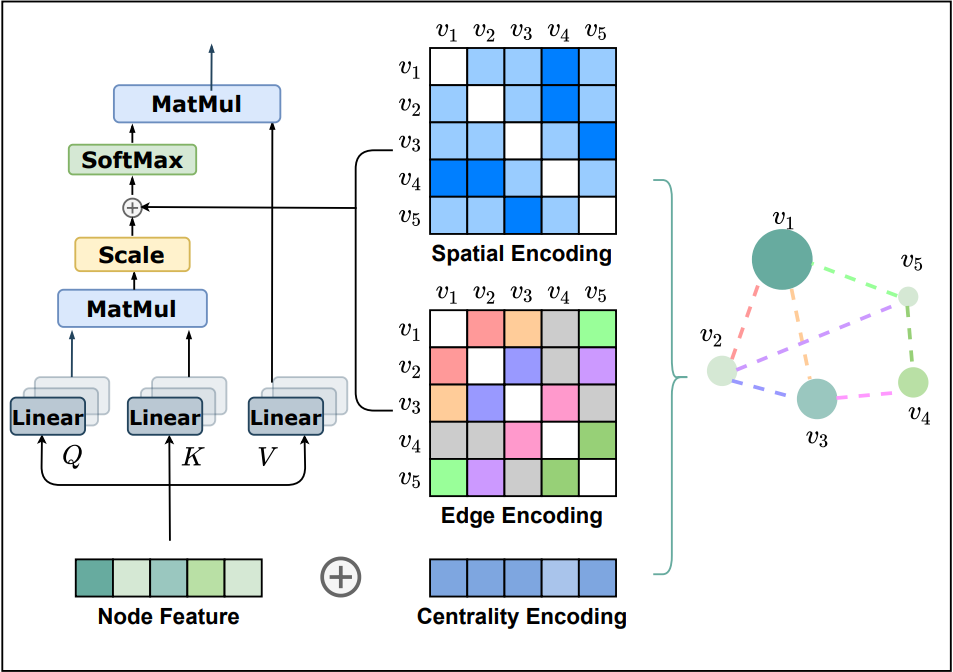
上图展示了Grpahormer的整体结构。文章在Transformer的Encoder基础上,添加了三种有效的编码方式,包括中心性编码、空间编码以及注意力机制中的边缘编码。
中心性编码:Transformer通过节点间的语义相关性计算注意力分布。然而,节点中心性能够衡量一个节点在图中的重要性,通常是模型理解图的一个重要信息。这些信息在当前的注意力计算中被忽略了,文章认为它应该是Transformer模型的一个有价值的信号。在Graphhormer中,文章使用了中心性度作为神经网络的附加信号。具体而言,文章提出了一种中心性编码,根据每个节点的入度和出度分配两个实值嵌入向量。当中心性编码应用于每个节点时,只需将其添加到节点特征中作为输入。
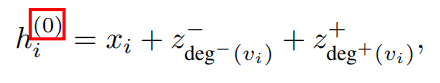
其中,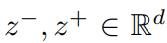 为可学习参数,分别通过节点的入度和出度进行具体化。对于无向图而言,上述两个参数可以简化为一个参数。通过在输入中使用中心性编码,softmax注意力机制可以捕获查询和键中的节点重要性信号。因此,该模型可以同时捕获注意机制中的语义相关性和节点重要性。
为可学习参数,分别通过节点的入度和出度进行具体化。对于无向图而言,上述两个参数可以简化为一个参数。通过在输入中使用中心性编码,softmax注意力机制可以捕获查询和键中的节点重要性信号。因此,该模型可以同时捕获注意机制中的语义相关性和节点重要性。
空间编码:Transformer的一个优势在于该模型有用全局接受域。在每个Transformer层中,每个token可以处理任何位置的信息,进而获得其表示。但该操作存在一个问题,即模型必须显式地指定层中的不同位置或编码位置依赖性。但对于图而言,然而,对于图,节点不是按顺序排列的。节点可以位于多维空间空间中,并由边缘连接。为了在模型中编码图的结构信息,文章提出了一种空间编码方法。具体地说,对于任意图G,文章考虑一个函数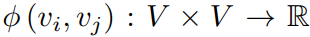 ,该函数衡量了在图G中两个节点之间的空间关系。文章选择两个节点之间最短路径的长度作为空间关系的衡量标准,如果两个节点是联通的则使用最短路径长度作为空间关系,否则为-1。文章为每个可行的输出值分配一个可学习的标量,该标量将作为自注意模块中的偏置项。
,该函数衡量了在图G中两个节点之间的空间关系。文章选择两个节点之间最短路径的长度作为空间关系的衡量标准,如果两个节点是联通的则使用最短路径长度作为空间关系,否则为-1。文章为每个可行的输出值分配一个可学习的标量,该标量将作为自注意模块中的偏置项。
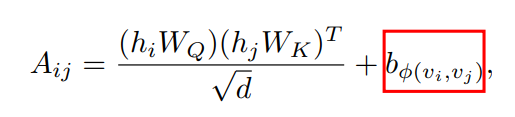
其中,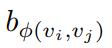 为可学习标量并且每层共享。进一步,文章讨论该方法的几个好处。首先,与传统GNN相比,传统的GNN接受域仅限于邻居,而在空间编码中,Transformer层提供了一个全局接受域,即每个节点可以关注图中的所有其他节点。其次,通过使用
为可学习标量并且每层共享。进一步,文章讨论该方法的几个好处。首先,与传统GNN相比,传统的GNN接受域仅限于邻居,而在空间编码中,Transformer层提供了一个全局接受域,即每个节点可以关注图中的所有其他节点。其次,通过使用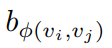 ,单个Transformer层中的每个节点可以根据图结构信息自适应地关注所有其他节点。
,单个Transformer层中的每个节点可以根据图结构信息自适应地关注所有其他节点。
注意力机制中的边缘编码:在许多图任务中,边也具有结构特征,这些特征对于图的表示非常重要,并且将它们与节点特征一起编码到网络中是必不可少的。在以往的工作中,主要采用了两种边缘编码方法。.第一种方法:将边缘特征添加到关联节点的特征中;第二种方法:对于每个节点,其关联边的特征将与聚合中的节点特征一起使用。然而,这种使用边缘特征的方法只是将边缘信息传播到其相关节点,这可能不是利用边缘信息表示整个图的有效方法。为了更好地将边缘特征编码到注意层中,文章提出了一种新的边缘编码方法。由于,注意机制需要估计每个节点对(vi, vj)的相关性,文章认为在相关性中应该考虑连接它们的边。对于每一个有序的节点对(vi, vj),文章找到(其中一条)最短路径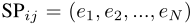 并计算边缘特征点积的平均值和沿路径的可学习嵌入。
并计算边缘特征点积的平均值和沿路径的可学习嵌入。
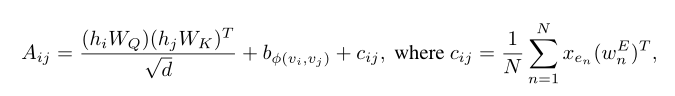
其中,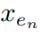 表示第n条边的特征,
表示第n条边的特征,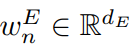 表示第n个权重的嵌入。
表示第n个权重的嵌入。
Grpahormer的应用:Graphormer基于经典Transformer的编码器构建。此外,文章在多头自注意力机制和前馈神经网络之前应用了层归一化(LN)。这种修改被所有当前的Transformer实现一致采用,因为它导致更有效的优化。特别是对于FFN子层,文章将输入、输出和内层的维数设置为与d相同的维数。Graphormer层形式化表征如下:
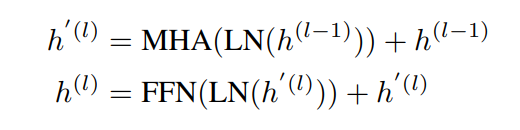
此外,在Graphormer中,文章在图中添加了一个特殊的节点[VNode],并在[VNode]和每个节点之间单独建立连接。在AGGREGATE-COMBINE步骤中,[VNode]的表示已经被更新为图中的普通节点,整个图的表示将是最后一层[VNode]的节点特征。从概念上讲,虚拟节点的好处是它可以聚合整个图的信息(如READOUT函数),然后将其传播到每个节点。
实验
文章首先在最近的OGB-LSC量子化学回归挑战(PCQM4M-LSC)上进行实验,该挑战是目前最大的图级预测数据集,总共包含超过380万个图。进一步,文章分析了其他三个流行任务:ogbg-molhiv、ogbg-molpcba和ZINC的结果。最后,文章总结了graphhormer的重要设计元素。
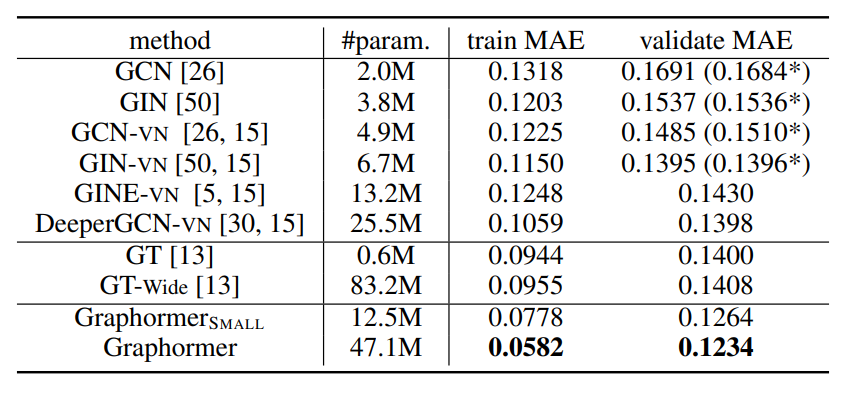
OGB-LSC(PCQM4M-LSC)数据集上的实验结果如下所示。该表总结模型的性能比较。从表中可以看出,与之前最先进的GNN架构相比,Graphormer明显超过了GIN-VN,例如,相对验证MAE下降了11.5%。此外,文章作者发现发现所提出的graphhormer不存在过度平滑的问题,即训练误差和验证误差随着模型深度和宽度的增长而不断减小。
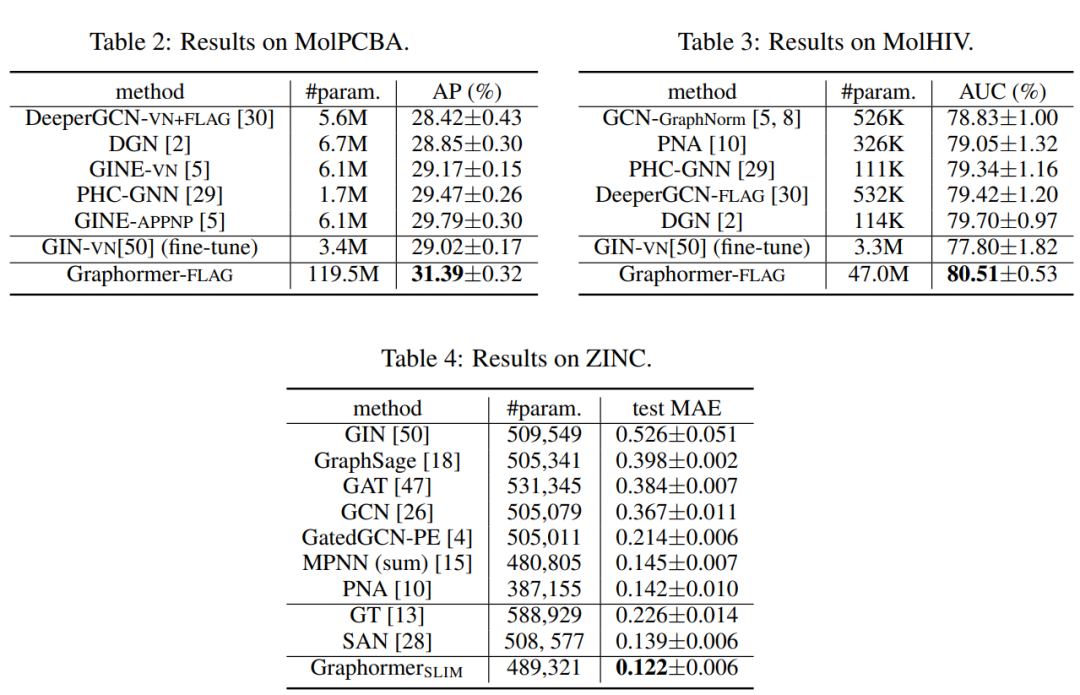
图表示学习:文章进一步研究了Graphormer在常用的流行排行榜的图形级预测任务上的性能,即OGBG-MolPCBA, OGBG-MolHIV和ZINC。实验结果如下所示。
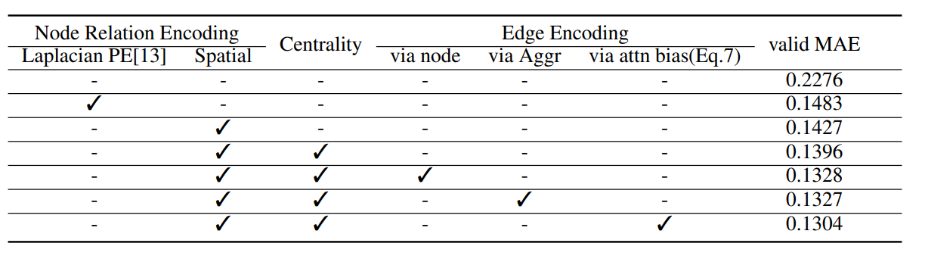
进一步,为验证模型有效性,文章进行消融实验,对所提出的三种方法进行处理。实验结果如下。在节点关系编码中,文章将先前使用的位置编码(PE)与所提出的空间编码进行了比较,这两种编码都旨在编码与Transformer有不同节点关系的信息。以前基于Transformer的GNN使用了各种PE,例如Weisfeiler-LehmanPE和Laplacian PE。文章选择了Laplacian PE的性能,因为该编码方式性能较好。
6 结论
文章探索了Transformer在图形表示中的直接应用。使用三种新颖的图结构编码,所提出的graphhormer在广泛的流行基准数据集上工作得非常好。虽然这些初步结果令人鼓舞,但仍存在许多挑战。最后,提出了一种适用于Graphormer节点表示提取的图采样策略。