Redis的Set结构存储的数据和Java中的HashSet类似,都是无序且不重复的。其底层的数据结构有两种,一是当value为整数时,且数据量不大时采用intset来存储。其他情况使用dict字典存储。集合中最多存储232-1(40多亿)个数据。
1、常用命令
- sadd key v1[v2,v3]:向集合中添加一个或者多个元素。重复的元素将被忽略。如果key不存在,将创建一个新的key,并将数据保存到key里面。
- scard key:获取集合的数据量
- sdiff key1[key2]:返回第一个集合和其他集合的区别(即第一个集合独有的元素)。
- sdiffstore destionation key1[key2…]:返回第一个集合和其他集合的差集并存储在destination中。指定destination集合已存在将被覆盖。即原来的数据会被删除。
- sinter key1[key2…]:返回给定集合的所有交集。
- sinterstore destination key1[key2…]:返回指定集合的交集,并保存到destination中。如果destination已存在将会被覆盖。
- sismember key member:判断member元素是否是集合key的元素。
- smembers key:返回集合中的所有数据。
- smove source destination member:将member数据从source移动到destination中。smove是原子操作。
- 如果source集合不存在或者不存在指定的member元素,smove命令不进行任何操作,只是返回0。否则member元素从source集合中删除,并添加到destination集合中。
- 当destination集合中已存在member元素时,smove命令只是删除source集合中的数据。
- spop key:移出并返回集合中随机一个数据。
- srandmember key[count]:返回集合中一个或者多个随机数
- srem key member1[member2]:移出集合中一个或者多个元素,不存在则被忽略。
- sunion key1 [key2]:返回所有给定集合中的并集。
- sunionstore destination key1[key2]:所有给定集合的并集,并存储在destination中
- sscan key cursor [MATCH pattern][COUNT count]:迭代集合中的元素。
2、底层结构
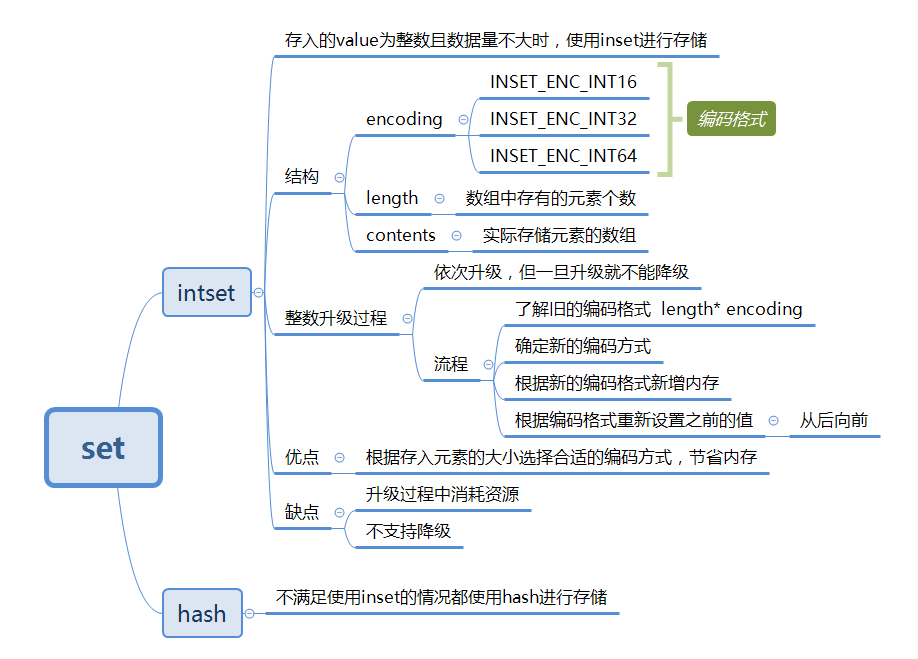
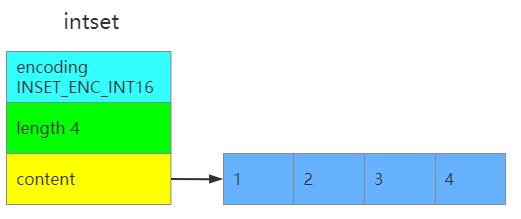
2.1、intset
结构
typedf struct intset{
unint32_t encoding;//编码方式 有三种 默认 INSET_ENC_INT16
unint32_t length;//集合元素的个数
int8_t contents[];//实际存储元素的数组
}intset;
length字段记录了保存数据的contents中公有多少个元素contents真正存数据的地方,数组都是按照从小到大有序排列的,并且不包含任何重复项
intset示意图如下:
使用条件
- 存储的数据都为整数
- 集合保存的数据个数不超过512个
以上任何一个条件不满足就会使用dict字典结构。
2.2、字典-dict
见Hash中的dict结构
3、总结