数据预处理
- 前言
- 一、查看数据
- 数据表的基本信息查看
- info()
- 示例
- 查看数据表的大小
- shape()
- 示例
- 数据格式的查看
- type()
- dtype()
- dtypes()
- 示例一
- 示例二
- 查看具体的数据分布
- describe()
- 示例
- 二、缺失值处理
- 缺失值检查
- isnull()
- 示例
- 缺失值删除
- dropna()
- 示例一
- 示例二
- 缺失值替换/填充
- fillna()
- interpolate()
- 示例一
- 示例二
- 示例三
- 示例四
- 三、重复值处理
- 查找重复值
- duplicated()
- 示例
- 重复值的处理
- 四、异常值的检测和处理
- 检测异常值
- query()
- boxplot()
- 示例
- 处理异常值
- drop()
- 示例
- 五、数据类型的转化
- 数据类型检查
- type()
- 示例
- 数据类型的转化
- astype()
- 强制类型转换
- 示例
- 六、索引设置
- 添加索引
- 示例
- 更改索引
- set_index()
- 示例
- 重命名索引
- reindex()
- 示例一
- 示例二
- 七、其他
- 大小写转换
- lower()
- upper
- 数据修改与替换
- 按列增加数据
- insert()
- loc()
- 示例
- 按行增加数据
- loc()
- append()
- iloc()
- 示例
- 数据删除
- 按列删除数据
- drop()
- 示例
- 按行删除数据
- 示例
前言
数据预处理是数据分析过程中不可或缺的一环,它的目的是为了使原始数据更加规整、清晰,以便于后续的数据分析和建模工作。在Python数据分析中,数据预处理通常包括数据清洗、数据转换和数据特征工程等步骤。
数据清洗是数据预处理的第一步,主要是为了解决数据中的缺失值、异常值、重复值等问题。Python提供了丰富的库和工具来处理这些问题,如pandas库可以帮助我们方便地处理数据框(DataFrame)中的缺失值和重复值。对于异常值,我们可以通过统计分析、可视化等方法来识别和处理。
数据转换是为了将数据转换成更适合分析的形式。常见的数据转换包括数据标准化、归一化、离散化等。例如,对于连续型变量,我们可以通过标准化或归一化将其转换到同一量纲下,以便于后续的比较和分析。对于分类变量,我们可以使用独热编码(One-Hot Encoding)将其转换为数值型数据。
数据特征工程则是为了从原始数据中提取出更多有用的信息,以提高模型的性能。特征工程通常包括特征选择、特征构造和特征降维等步骤。在Python中,我们可以使用scikit-learn等机器学习库来进行特征选择和降维,同时也可以利用自己的业务知识来构造新的特征。
在进行数据预处理时,我们还需要注意数据的质量和完整性。如果数据存在严重的质量问题或缺失过多,那么即使进行了再精细的数据预处理也难以得到准确的分析结果。因此,在进行数据分析之前,我们需要对数据的质量和完整性进行充分的评估和清理。
综上所述,数据预处理是Python数据分析中不可或缺的一环。通过数据清洗、数据转换和数据特征工程等步骤,我们可以使原始数据更加规整、清晰,为后续的数据分析和建模工作奠定坚实的基础。同时,我们也需要注意数据的质量和完整性,以确保分析结果的准确性和可靠性。
一、查看数据
数据表的基本信息查看
info()
在Python中,info()函数是pydoc模块中的一个函数,用于提供关于Python对象的详细信息的帮助文档。
info()函数的语法如下:
info(object, [maxwidth=80])
其中,object参数是要获取信息的Python对象。它可以是模块、类、函数、方法、数据或其他类型的对象。
可选的maxwidth参数用于指定输出的最大宽度,默认为80个字符。如果输出的文本超过最大宽度,则会自动换行。
当调用info()函数时,它会返回一个字符串,其中包含对象的文档字符串和其他相关信息。此信息通常包括对象的定义、属性、方法和基类等。
例如,调用info()函数以获取一个模块的信息:
import math
print(info(math))
输出的结果可能类似于:
This module provides mathematical functions. Available functions are:
acos(x) -- Return the arc cosine of x, in radians.
asin(x) -- Return the arc sine of x, in radians.
atan(x) -- Return the arc tangent of x, in radians.
...
info()函数对于快速查看对象的功能和用法非常有用,特别是当你需要了解一个模块的功能和可用的函数时。
示例
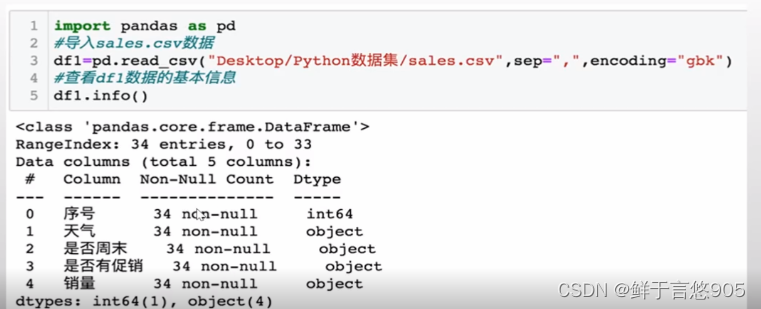
【例】餐饮企业的决策者想要了解影响餐厅销量的一些因素,如天气的好坏、促销活动是否能够影响餐厅的销量,周末和非周末餐厅销量是否有大的差别。
餐厅收集的数据存储在sales.csv中,前五行的数据如下所示。请利用Python查看数据集的基本信息。

关键技术:使用info()方法查看数据基本类型。
在该例中,首先使用pandas库中的read_csv方法导入sales.csv文件,然后使用info()方法,查看数据的基本信息,代码及输出结果如下:
import numpy as np
import pandas as pd
df = pd.read_excel("C:\\Users\\lenovo\\数据分析\\pydata02.xlsx")#读入excel表格
df


查看数据表的大小
shape()
在Python中,shape()函数是numpy库中的一个函数,用于获取数组的维度信息。它可以应用于numpy数组对象,返回一个表示数组形状的元组。
使用方法如下:
numpy.shape(arr)
参数说明:
arr:要获取形状的数组对象。
返回值:
shape()函数返回一个元组,元组的每个元素代表数组在对应维度上的大小。
下面是一些示例:
import numpy as np
arr1 = np.array([1, 2, 3, 4])
print(np.shape(arr1)) # 输出 (4,)
arr2 = np.array([[1, 2], [3, 4], [5, 6]])
print(np.shape(arr2)) # 输出 (3, 2)
arr3 = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print(np.shape(arr3)) # 输出 (2, 2, 2)
上述示例中,arr1是一个一维数组,shape()函数返回一个元组(4,),表示数组有4个元素。arr2是一个二维数组,shape()函数返回一个元组(3, 2),表示数组有3行2列。arr3是一个三维数组,shape()函数返回一个元组(2, 2, 2),表示数组有2个2x2的二维数组。
示例
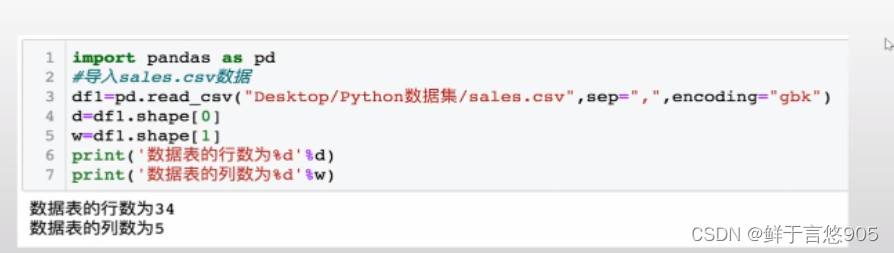
【例】请利用python查看上例中sales.csv文件中的数据表的大小,要求返回数据表中行的个数和列的个数。
关键技术:使用pandas库中DataFrame对象的shape()方法。
d = df.shape[0] #打印行数和列数
w = df.shape[1]
print("数据的行数%d "%d)
print('数据的列数 %d'%w)

数据格式的查看
type()
在Python中,type()函数是一个内置函数,用于返回一个对象的类型。
使用方法如下:
type(obj)
参数说明:
obj:要获取其类型的对象。
返回值:
type()函数返回一个表示对象类型的对象。
下面是一些示例:
num = 10
print(type(num)) # 输出 <class 'int'>
name = "Alice"
print(type(name)) # 输出 <class 'str'>
lst = [1, 2, 3]
print(type(lst)) # 输出 <class 'list'>
tup = (1, 2, 3)
print(type(tup)) # 输出 <class 'tuple'>
dct = {"A": 1, "B": 2}
print(type(dct)) # 输出 <class 'dict'>
flg = True
print(type(flg)) # 输出 <class 'bool'>
上述示例中,type()函数用于返回不同对象的类型。num是一个整数,type()函数返回<class 'int'>。name是一个字符串,type()函数返回<class 'str'>。lst是一个列表,type()函数返回<class 'list'>。tup是一个元组,type()函数返回<class 'tuple'>。dct是一个字典,type()函数返回<class 'dict'>。flg是一个布尔值,type()函数返回<class 'bool'>。
dtype()
dtype()函数是一种numpy库中的函数,用于返回给定数组的数据类型。
在NumPy中,dtype表示数组对象中元素的数据类型。dtype属性的语法如下:
array_name.dtype
array_name是你要获取数据类型的数组对象的名称。
dtype属性返回一个描述数组元素数据类型的dtype对象。dtype对象包含以下信息:
name:数据类型的字符串描述,例如int32,float64等。itemsize:数组中每个元素的字节大小。kind:数据类型的字符代码,表示数据类型的种类,比如i表示整数,f表示浮点数等。
以下是一个示例代码,展示了如何使用dtype属性获取数组元素的数据类型:
import numpy as np
# 创建一个整型数组
arr = np.array([1, 2, 3, 4, 5])
# 获取数组元素的数据类型
arr_dtype = arr.dtype
print(arr_dtype.name) # 输出: int32
print(arr_dtype.itemsize) # 输出: 4
print(arr_dtype.kind) # 输出: i
上述代码中,首先导入numpy库。然后创建一个整型数组arr。接下来,使用dtype属性获取数组元素的数据类型,并将其保存到变量arr_dtype中。最后,打印arr_dtype对象的name、itemsize和kind属性的值。
输出结果如下:
int32
4
i
从输出结果可以看出,arr数组的元素类型是int32,每个元素的大小是4字节,数据类型被表示为整数类型(i)。
dtypes()
在Python中,dtypes函数是numpy库中的一个函数,用于返回一个数组的数据类型。它可以应用于numpy数组对象,并返回该数组中元素的数据类型。
语法:
numpy.dtypes(arr)
参数说明:
arr:要检查的数组。
返回值:
dtypes函数返回一个描述数组中元素数据类型的字符串。
示例:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(np.dtypes(arr)) # 输出int32
arr = np.array([1.0, 2.5, 3.7, 4.2, 5.9])
print(np.dtypes(arr)) # 输出float64
注意:dtypes函数只适用于numpy的数组对象,不适用于Python的列表和元组等其他数据类型。
示例一
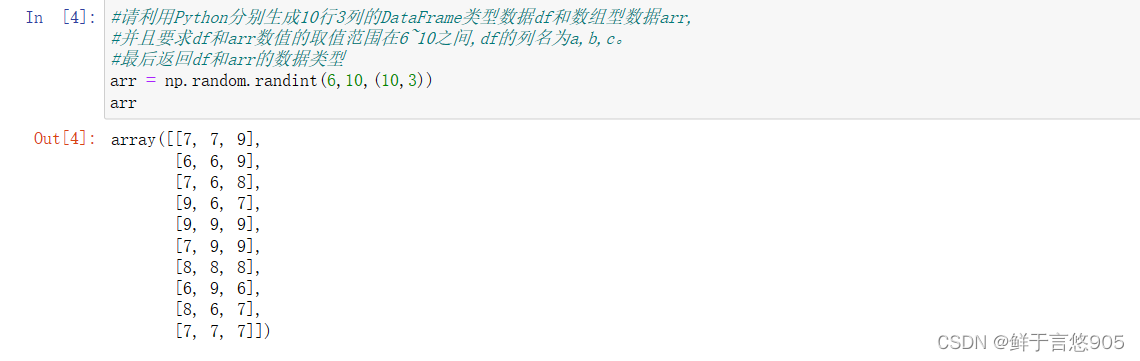
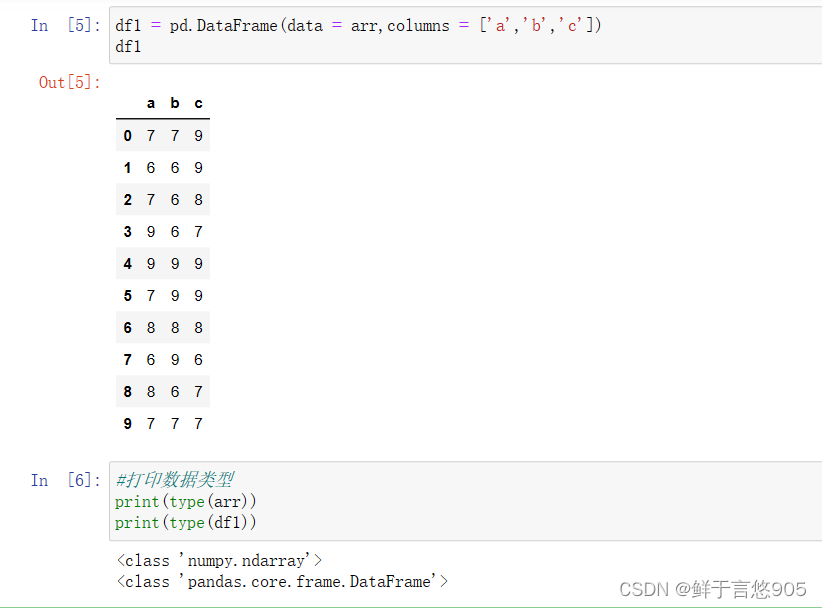
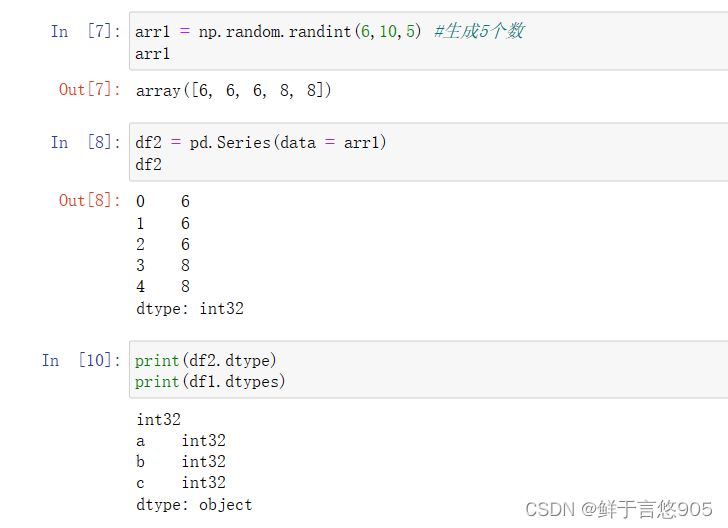
【例】请利用Python分别生成10行3列的DataFrame类型数据df和数组型数据arr,并且要求df和arr数值的取值范围在6~10之间,df的列名为a,b,c。最后返回df和arr的数据类型。
关键技术:type()方法。
示例二
【例】同样对于前一个例题给定的数据文件,读取后请利用Python查看数据格式一是字符串还是数字格式。
关键技术: dtype属性和dtypes属性
在上例代码的基础上,对于series数据可以用dtype查看,对于dataframe数据可以用dtypes查看,程序代码如下所示:
查看具体的数据分布
describe()
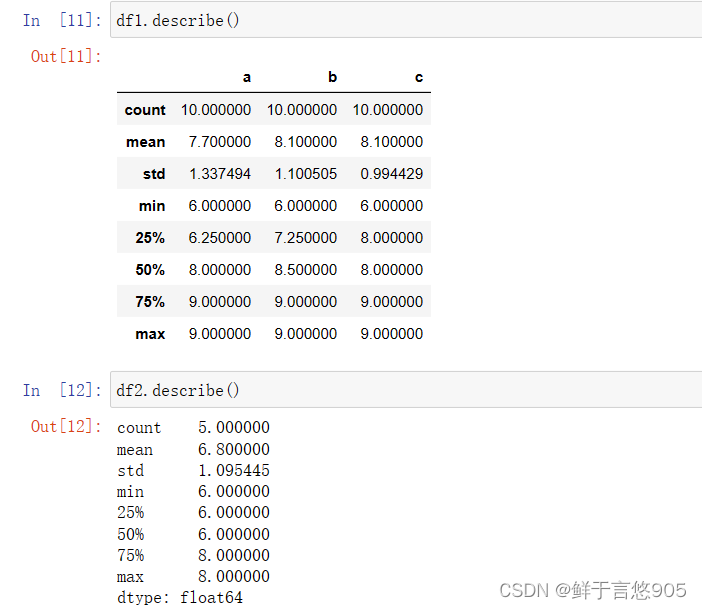
在Python中,没有名为describe()的内置函数。但是,在pandas库中有一个describe()函数,它用于生成数值列的统计摘要。
describe()函数是一个Series和DataFrame对象的方法,它提供了一些常见的统计信息,如计数、均值、标准差、最小值、最大值以及上下四分位数。
下面是一个使用describe()函数的示例:
import pandas as pd
data = {
'Name': ['Tom', 'Nick', 'John', 'Jerry', 'Kevin'],
'Age': [28, 34, 29, 42, 39],
'Height': [172, 178, 165, 180, 175],
'Weight': [68, 80, 72, 85, 79]
}
df = pd.DataFrame(data)
print(df.describe())
输出结果如下:
Age Height Weight
count 5.000000 5.000000 5.000000
mean 34.400000 174.000000 76.800000
std 5.507571 6.324555 6.680123
min 28.000000 165.000000 68.000000
25% 29.000000 172.000000 72.000000
50% 34.000000 175.000000 79.000000
75% 39.000000 178.000000 80.000000
max 42.000000 180.000000 85.000000
describe()函数返回一个包含所有列统计信息的DataFrame,其中count表示非缺失值的数量,mean表示平均值,std表示标准差,min表示最小值,25%表示下四分位数,50%表示中位数,75%表示上四分位数,max表示最大值。
该函数对于了解数据的分布、识别异常值等很有帮助。
示例
在进行数据分析时,常常需要对对数据的分布进行初步分析,包括统计数据中各元素的个数,均值、方差、最小值、最大值和分位数。
关键技术: describe()函数。在做数据分析时,常常需要了解数据元素的特征,describe()函数可以用于描述数据统计量特征
二、缺失值处理
缺失值检查
isnull()
在 pandas 库中,isnull() 函数用于检查数据是否为空值(NaN)。
语法:
pandas.isnull(obj)
参数:
obj:待检查的数据对象,可以是Series、DataFrame或Panel对象。
返回值:
- 返回一个与
obj相同大小的布尔类型的对象,其中为True的位置表示对应位置的值为空值,为False的位置表示对应位置的值不为空值。
示例:
import pandas as pd
data = pd.Series([1, 2, None, 4, None])
print(pd.isnull(data))
输出:
0 False
1 False
2 True
3 False
4 True
dtype: bool
在上述示例中,isnull() 函数用于检查 Series 对象 data 中的每个元素是否为空值,返回一个布尔类型的 Series 对象。输出结果显示第 2 和第 4 个位置的值为 True,表示对应位置的值为空值。
示例
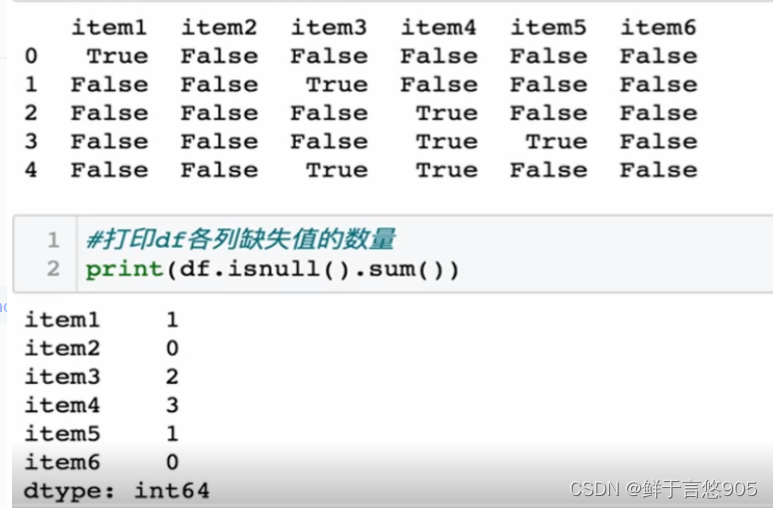
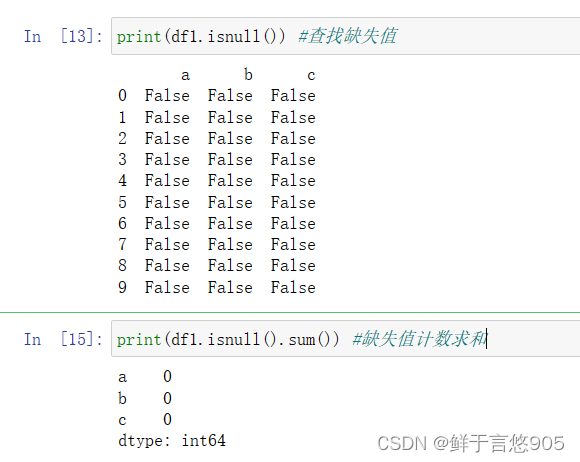
【例】若某程序员对淘宝网站爬虫后得到原始数据集items.csv,文件内容形式如下所示。请利用Python检查各列缺失数据的个数,并汇总。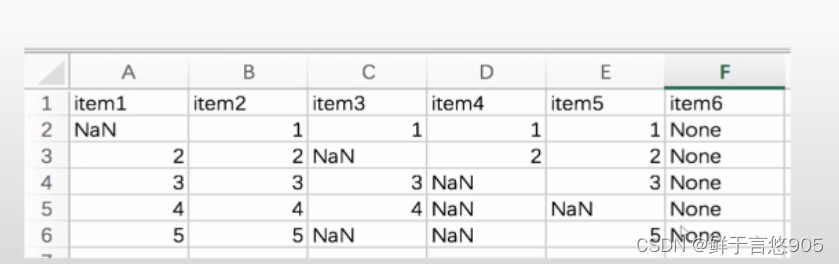
关键技术: isnull()方法。isnull()函数返回值为布尔值,如果数据存在缺失值,返回True;否则,返回False。

缺失值删除
dropna()
dropna函数是pandas库中的一个函数,用于从Series、DataFrame或Panel对象中删除缺失值。
函数语法为:
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:可选参数,默认为0,表示按行删除含有缺失值的行;若设为1,则按列删除含有缺失值的列。how:可选参数,默认为’any’,表示只要有一个缺失值就删除该行或列;若设为’all’,则只有全部为缺失值时才删除该行或列。thresh:可选参数,默认为None,表示保留至少含有非缺失值的行或列的个数,小于该值的行或列将被删除。subset:可选参数,默认为None,表示只在指定的列或行中查找缺失值并删除,可以是列名或行标签。inplace:可选参数,默认为False,表示不对原数据进行修改,返回一个新的数据;若设为True,则直接在原数据上进行修改,不返回新的数据。
返回值:
- 返回一个新的
Series、DataFrame或Panel对象,其中已删除包含缺失值的行或列。
示例:
import pandas as pd
data = {'A': [1, 2, np.nan, 4],
'B': [np.nan, 2, 3, 4],
'C': [1, 2, 3, np.nan]}
df = pd.DataFrame(data)
# 删除含有缺失值的行
df.dropna()
# 删除含有缺失值的列
df.dropna(axis=1)
# 至少保留2个非缺失值的行
df.dropna(thresh=2)
# 只在'A'列和'B'列中查找并删除缺失值
df.dropna(subset=['A', 'B'])
示例一
【例】当某行或某列值都为NaN时,才删除整行或整列。这种情况该如何处理?
关键技术: dropna()方法的how参数。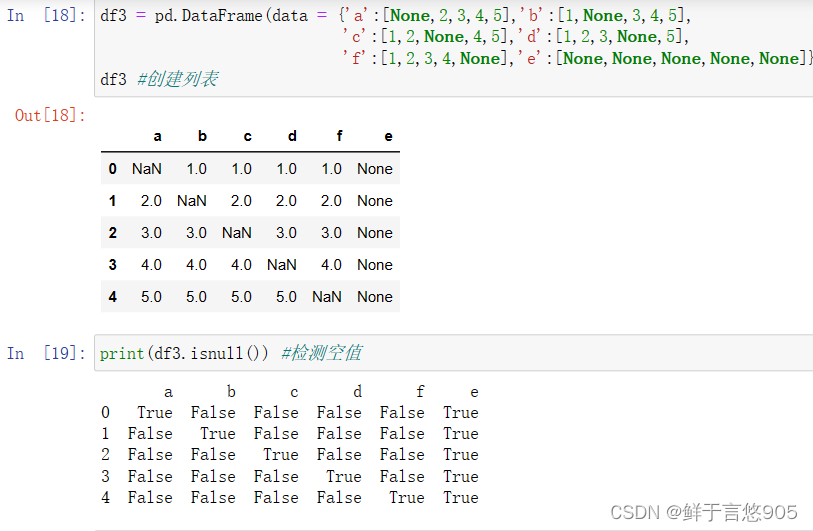

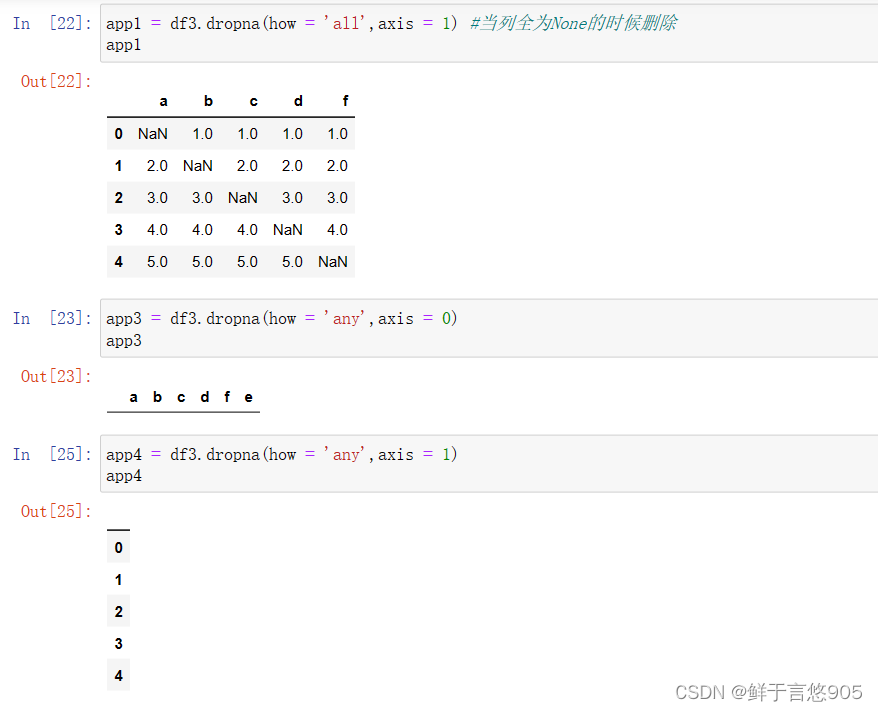
示例二
【例】当某行有一个数据为NaN时,就删除整行和当某列有一个数据为NaN时,就删除整列。遇到这两周种情况,该如何处理?
关键技术: dropna()方法的how参数dropna(how= 'any' )。
缺失值替换/填充
对于数据中缺失值的处理,除了进行删除操作外,还可以进行替换和填充操作,如均值填补法,近邻填补法,插值填补法,等等。本文介绍填充缺失值的fillna()方法。
fillna()
在Python中,fillna()函数是一个pandas库中的函数,用于填充缺失值。该函数可以用于Series对象和DataFrame对象。
对于Series对象,fillna()函数可以用来填充缺失值或者替换特定的值。
对于DataFrame对象,fillna()函数可以用来填充DataFrame中的所有缺失值或者指定列中的缺失值。
函数的语法如下:
Series.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
参数说明:
value:用于填充缺失值的值,可以是一个标量、一个映射字典、一个Series对象、一个DataFrame对象或者一个函数。method:填充缺失值的方法,可以是ffill(用前一个非缺失值填充)、bfill(用后一个非缺失值填充)或者None(不填充)。axis:指定填充的轴,可以是行轴(0)或者列轴(1)。inplace:是否在原对象上进行操作,默认为False。limit:指定填充的连续缺失值的最大数量。downcast:用于优化数据类型的参数。
示例代码:
import pandas as pd
# 创建一个Series对象
s = pd.Series([1, None, 3, 4, None, 6])
# 用0填充缺失值
s.fillna(0, inplace=True)
print(s)
# 创建一个DataFrame对象
df = pd.DataFrame({'A': [1, None, 3, None, 5],
'B': [None, 2, 3, None, 5]})
# 用均值填充所有缺失值
df.fillna(df.mean(), inplace=True)
print(df)
输出结果:
0 1.0
1 0.0
2 3.0
3 4.0
4 0.0
5 6.0
dtype: float64
A B
0 1.0 3.333333
1 3.0 2.000000
2 3.0 3.000000
3 3.0 3.333333
4 5.0 5.000000
interpolate()
在Python中,interpolate方法用于插值数据。插值是一种估计未知数据点的方法,它根据已知的数据点之间的关系来推断缺失的数据点。interpolate方法内置于pandas库中的DataFrame对象中。
它的参数如下:
-
x:表示用于插值的数据点的 x 坐标。可以是一个单独的数值或一个数组。 -
y:表示用于插值的数据点的 y 坐标。可以是一个单独的数值或一个数组。 -
x_new:表示要在其上进行插值的新 x 坐标。可以是一个单独的数值或一个数组。 -
method:表示选择插值算法的方法。可以是以下选项之一:-
'linear':使用线性插值方法。 -
'nearest':使用最近邻插值方法。 -
'zero':使用零阶插值方法。 -
'slinear':使用一次样条插值方法。 -
'quadratic':使用二次样条插值方法。 -
'cubic':使用三次样条插值方法。 -
'previous':使用前一个插值方法。 -
'next':使用后一个插值方法。 -
'pchip':使用 PCHIP 插值方法。 -
'akima':使用 Akima 插值方法。 -
'cubicspline':使用立方样条插值方法。
默认值为
'linear'。 -
-
extrapolate:表示是否允许在给定的数据范围之外进行插值。可以是以下选项之一:-
'continuous':在给定的范围外进行插值,但结果可能不准确。 -
'zeros':在给定的范围外进行插值,并将范围外的值设为零。 -
'nan':在给定的范围外进行插值,并将范围外的值设为 NaN。 -
None:不允许在给定的范围外进行插值。
默认值为
None。 -
函数会返回在给定的新 x 坐标上进行插值的值。
interpolate方法有一个可选的order参数,用于指定插值的类型。order参数可以是以下几个值之一:
1:线性插值。使用线性函数来估计未知数据点。2:二次插值。使用二次函数来估计未知数据点。3:三次插值。使用三次函数来估计未知数据点。4:四次插值。使用四次函数来估计未知数据点。
默认情况下,order参数的值为1,即线性插值。如果不指定order参数,则使用默认值进行插值。
下面是一个使用interpolate方法进行插值的示例:
import pandas as pd
data = {'A': [1, np.nan, 3, np.nan, 5]}
df = pd.DataFrame(data)
# 线性插值
df['A_linear_interpolated'] = df['A'].interpolate()
print(df)
# 二次插值
df['A_quadratic_interpolated'] = df['A'].interpolate(order=2)
print(df)
# 三次插值
df['A_cubic_interpolated'] = df['A'].interpolate(order=3)
print(df)
# 四次插值
df['A_quartic_interpolated'] = df['A'].interpolate(order=4)
print(df)
这个示例中,我们创建了一个包含缺失值的DataFrame对象。然后,我们使用interpolate方法进行线性、二次、三次和四次插值,并将插值结果存储在新的列中。最后,我们打印整个DataFrame对象,以查看插值结果。
请注意,interpolate方法还可以接受其他参数,用于自定义插值行为,例如limit参数用于限制插值的最大连续缺失值数量。有关更多详细信息,请参阅pandas文档中关于interpolate方法的说明。
示例一
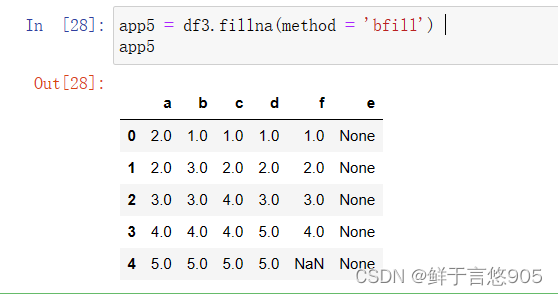
【例】使用近邻填补法,即利用缺失值最近邻居的值来填补数据,对df数据中的缺失值进行填补,这种情况该如何实现?
关键技术: fillna()方法中的method参数。
在本案例中,可以将fillna()方法的method参数设置为bfill,来使用缺失值后面的数据进行填充。代码及运行结果如下:
示例二
【例】若使用缺失值前面的值进行填充来填补数据,这种情况又该如何实现?
本案例可以将fillna()方法的method参数设置设置为ffill,来使用缺失值前面的值进行填充。
代码及运行结果如下:

示例三
【例】请利用二次多项式插值法对df数据中a列的缺失值进行填充。
关键技术: interpolate方法及其order参数。
在该案例中,将interpolate方法中的参数order设置为2即可满足要求。
具体代码及运行结果如下:
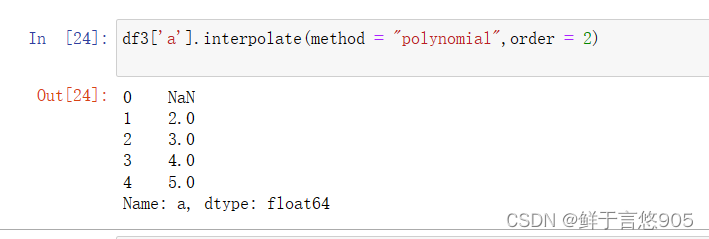
示例四
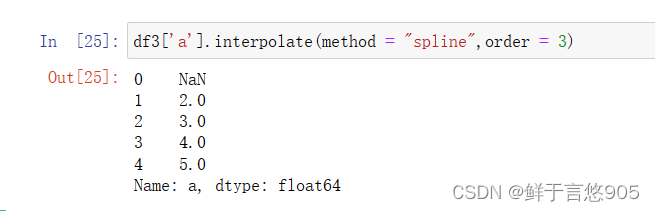
【例】请使用Python完成对df数据中a列的三次样条插值填充。
关键技术:三次样条插值,即利用一个三次多项式来逼近原目标函数,然后求解该三次多项式的极小点来作为原目标函数的近似极小点。
在该案例中,将interpolate方法的method参数设置为spline,将order参数设置为3,具体代码及运行结果如下:
三、重复值处理
在数据的采集过程中,有时会存在对同一数据进行重复采集的情况,重复值的存在会对数据分析的结果产生不良影响,因此在进行数据分析前,对数据中的重复值进行处理是十分必要的。
本节主要从重复值的发现和处理两方面进行介绍。
查找重复值
duplicated()
Python的duplicated函数是pandas库中的一个函数,用于判断DataFrame或Series中的元素是否重复。这个函数返回一个布尔类型的值,表示每个元素是否是重复的。如果元素是重复的,则为True;否则为False。
函数的语法如下:
duplicated(self, subset=None, keep='first')
参数说明:
subset:可选参数,用于指定在哪些列中判断重复,默认为None,表示在所有列中判断重复。可以传入一个或多个列的名称或索引。如果指定了subset参数,那么只有在指定的列中的值相同的行才会被判断为重复。keep:可选参数,用于指定保留哪些重复值。默认值为’first’,表示保留第一个重复值,将其它重复值标记为True。可以设置为’last’,表示保留最后一个重复值,将其它重复值标记为True。还可以设置为False,表示将所有重复值都标记为True。
示例:
import pandas as pd
data = {'A': [1, 2, 3, 4, 5],
'B': [1, 1, 2, 2, 3]}
df = pd.DataFrame(data)
result = df.duplicated()
print(result)
输出结果为:
0 False
1 False
2 False
3 False
4 False
dtype: bool
这表示DataFrame中的所有元素都不是重复的。
示例
【例】请使用Python检查df数据中的重复值。
关键技术: duplicated方法。
利用duplicated()方法检测冗余的行或列,默认是判断全部列中的值是否全部重复,并返回布尔类型的结果。对于完全没有重复的行,返回值为False。对于有重复值的行,第一次出现重复的那一行返回False,其余的返回True。本案例的代码及运行结果如下: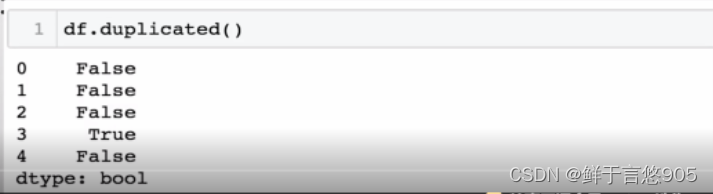

重复值的处理
在Python中,可以使用pandas库来处理数据分析中的重复值。下面是一些常用的处理方法:
-
检查重复值:使用
.duplicated()方法可以检查DataFrame中的重复行。例如,df.duplicated()返回一个布尔型的Series,指示每一行是否重复。 -
删除重复值:使用
.drop_duplicates()方法可以删除DataFrame中的重复行。例如,df.drop_duplicates()返回一个没有重复行的新DataFrame。 -
替换重复值:使用
.replace()方法可以将DataFrame中的重复值替换为其他值。例如,df.replace('重复值', '替换值')将DataFrame中的所有’重复值’替换为’替换值’。 -
统计重复值:使用
.value_counts()方法可以统计DataFrame中每个值出现的次数。例如,df['列名'].value_counts()返回一个Series,其中包含每个值及其出现次数。 -
标记重复值:使用
.duplicated()方法结合布尔索引可以标记重复行。例如,df['is_duplicate'] = df.duplicated()将在DataFrame中添加一个名为’is_duplicate’的新列,指示每一行是否重复。 -
分组处理:使用
.groupby()方法可以按照指定的列对DataFrame进行分组,并进行相关的处理。例如,df.groupby('列名').agg({'聚合列':'方法'})可以对指定列进行聚合操作,例如求和、计数等。
这些方法可以根据具体情况进行灵活应用,以便处理重复值。
四、异常值的检测和处理
检测异常值
query()
query() 函数是pandas库中DataFrame对象的一个方法,用于按照一定的条件从DataFrame中筛选数据。它提供了一种简洁而灵活的方式来进行数据筛选操作。
.query() 函数的基本语法如下:
df.query(expr, inplace=False)
其中,expr 是一个字符串表达式,表示筛选的条件,inplace 是一个布尔值,表示是否对原始的DataFrame进行就地修改。默认情况下,inplace 的值为 False,即生成一个新的DataFrame。
下面是一些关于 .query() 函数的详细解释:
-
表达式语法:在表达式中,你可以使用列名引用
DataFrame的列,并使用常规的布尔运算符(如==、!=、>、<、>=、<=)进行比较。你还可以使用布尔运算符and、or和not进行复合条件判断。 -
引用列名:在表达式中,可以使用列名直接引用
DataFrame的列。例如,df.query('age > 30')将返回age列中大于30的所有行。 -
字符串引号:在表达式中,可以使用单引号或双引号来引用字符串值。例如,
df.query("name == 'Tom'")将返回name列中等于’Tom’的所有行。 -
外部变量引用:可以在表达式中使用外部变量。在表达式中,可以使用
@符号引用外部变量。例如,name = 'Tom',然后使用df.query("name == @name")。 -
多条件筛选:可以使用
&表示“与”运算符,使用|表示“或”运算符。例如,df.query("age > 30 & name == 'Tom'")将返回age列大于30且name列等于’Tom’的所有行。 -
特殊字符转义:如果表达式中的字符串值包含特殊字符(如单引号或空格),可以使用反斜杠进行转义。例如,
df.query("name == 'Tom\'s House'")。 -
返回值:
.query()函数返回一个新的DataFrame,其中包含符合条件的所有行。
需要注意的是,.query() 函数只能用于筛选DataFrame对象,不能用于Series对象或其他类型的数据。此外,该函数在处理大型的DataFrame时,可能会比较耗时,因此,对于较大的数据集,最好考虑使用其他更高效的方法进行筛选操作。
boxplot()
boxplot函数是在Python的matplotlib库中用于绘制箱线图的函数。箱线图是一种用于显示数据集中的分布情况的统计图。
boxplot函数的详细用法如下:
matplotlib.pyplot.boxplot(x, notch=None, sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None, bootstrap=None, usermedians=None, conf_intervals=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, whiskerprops=None, flierprops=None, medianprops=None, capprops=None, whiskers=None, fliers=None, means=None, medians=None, caps=None, **kwargs)
参数说明:
x: 要绘制箱线图的数据集。notch: 是否在箱线图的盒形上绘制缺口,默认为None(不绘制)。sym: 指定离群点的样式,默认为None(使用matplotlib库的默认样式)。vert: 是否绘制垂直箱线图,默认为True(绘制垂直箱线图)。whis: 指定须的长度,默认为1.5(根据IQR计算,可以指定为float或list)。positions: 指定箱线图的位置,默认为None(将箱线图平均分布在x轴上)。widths: 指定箱线图的宽度,默认为0.5。patch_artist: 是否为盒形绘制填充色,默认为None(不填充)。bootstrap: 用于估计置信区间的抽样次数,默认为None(不进行bootstrap估计)。usermedians: 指定中位数的位置,默认为None(使用数据集的中位数)。conf_intervals: 指定置信区间,默认为None(使用默认的95%置信区间)。meanline: 是否绘制均值线,默认为False(不绘制)。showmeans: 是否显示均值点,默认为False(不显示)。showcaps: 是否显示顶端和底端的线段,默认为True(显示)。showbox: 是否显示箱线图的盒形,默认为True(显示)。showfliers: 是否显示箱线图的离群点,默认为True(显示)。boxprops: 盒形的属性字典,默认为None(使用默认字典)。whiskerprops: 须的属性字典,默认为None(使用默认字典)。flierprops: 离群点的属性字典,默认为None(使用默认字典)。medianprops: 中位数的属性字典,默认为None(使用默认字典)。capprops: 顶端和底端线段的属性字典,默认为None(使用默认字典)。
其他常用参数:
facecolor: 盒形的填充颜色。color: 箱线图的颜色。linewidth: 箱线图的线宽。linestyle: 箱线图的线型。marker: 离群点的标记类型。
示例代码:
import matplotlib.pyplot as plt
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
plt.boxplot(data)
plt.show()
运行以上代码将会生成一个简单的箱线图。
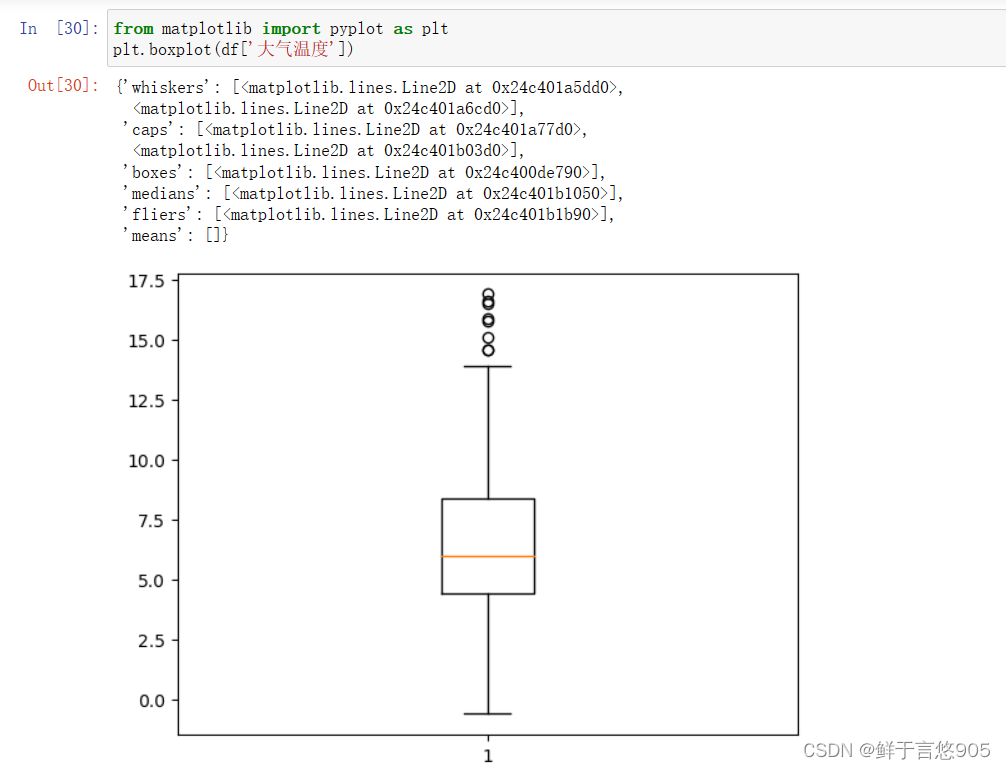
示例
【例】某公司的年度业务数据work.csv,数据形式如下所示。其中年度销售量应大于1000,请分别用判断数据范围方法和箱形图方法检测数据中的异常值。

关键技术: query方法和boxplot方法。
在该案例中,首先使用pandas库中的query方法查询数据中是否有异常值。然后通过boxplot方法检测异常值。
代码及运行结果如下: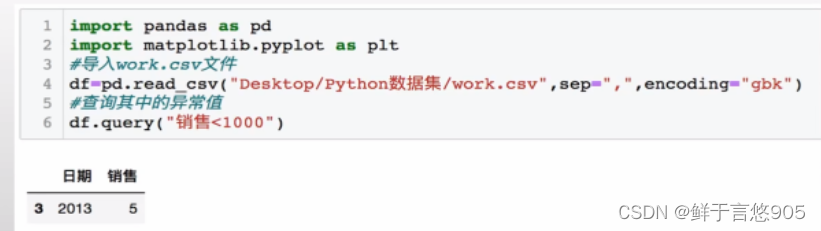
下面以箱形图的方法来进行异常值检测。
ps:下图示例不是上述数据的示例,上述数据的文件毁坏了,只能使用其他的
处理异常值
了解异常值的检测后,接下来介绍如何处理异常值。在数据分析的过程中,对异常值的处理通常包括以下3种方法:
- 最常用的方式是删除。
- 将异常值当缺失值处理,以某个值填充。
- 将异常值当特殊情况进行分析,研究异常值出现的原因。
drop()
在Python中,drop函数通常用于删除DataFrame或Series中的指定行或列。
在pandas库中,DataFrame是一个二维的数据结构,类似于表格,而Series则是一个一维的数据结构,类似于数组。
在DataFrame中,drop函数的语法如下:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
参数含义如下:
labels:要删除的行或列的标签列表或单个标签。可以是一个字符串,也可以是一个字符串列表。axis:指定删除行还是删除列。默认为0,表示删除行;1表示删除列。index:要删除的行的标签列表或单个标签。与labels参数功能相同,只是在不指定axis的情况下使用。如果同时指定了labels和index,则labels参数优先生效。columns:要删除的列的标签列表或单个标签。与labels参数功能相同,只是在axis=1的情况下使用。level:如果DataFrame具有多层索引,则指定要删除的索引级别。默认为None,表示删除所有级别。inplace:是否在原地修改DataFrame。如果为True,则原地修改DataFrame,即不会返回新的DataFrame;如果为False(默认值),则返回一个新的DataFrame。errors:指定如何处理未找到要删除的标签。默认为’raise’,表示引发一个异常;'ignore’表示忽略。
在Series中,drop函数的语法如下:
Series.drop(labels=None, axis=0, index=None, inplace=False, errors='raise')
参数含义与DataFrame中的参数含义相同。
使用drop函数可以按照指定的标签删除行或列。例如,可以通过以下方式删除DataFrame中的某些行和列:
df.drop(labels=['row1', 'row2'], axis=0, inplace=True)
df.drop(labels=['col1', 'col2'], axis=1, inplace=True)
使用drop函数时要注意,需要指定axis参数来指明删除行还是删除列,同时要根据实际需求选择合适的inplace参数值。
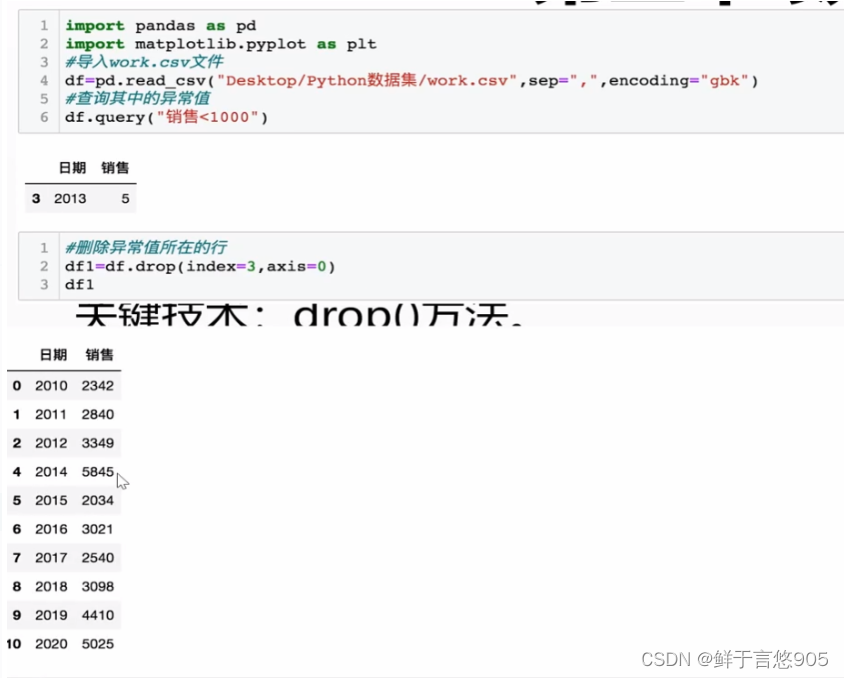
示例
【例】对于上述业务数据work.csv,若已经检测出异常值,请问在此基础上,如何删除异常值?
关键技术:drop()方法。
利用drop()方法,对work.csv文件中的异常值进行删除操作,代码及运行结果如下:
五、数据类型的转化
数据类型检查
type()
在Python中,type()函数是一个内置函数,用于返回一个对象的类型。
使用方法如下:
type(obj)
参数说明:
obj:要获取其类型的对象。
返回值:
type()函数返回一个表示对象类型的对象。
下面是一些示例:
num = 10
print(type(num)) # 输出 <class 'int'>
name = "Alice"
print(type(name)) # 输出 <class 'str'>
lst = [1, 2, 3]
print(type(lst)) # 输出 <class 'list'>
tup = (1, 2, 3)
print(type(tup)) # 输出 <class 'tuple'>
dct = {"A": 1, "B": 2}
print(type(dct)) # 输出 <class 'dict'>
flg = True
print(type(flg)) # 输出 <class 'bool'>
上述示例中,type()函数用于返回不同对象的类型。num是一个整数,type()函数返回<class 'int'>。name是一个字符串,type()函数返回<class 'str'>。lst是一个列表,type()函数返回<class 'list'>。tup是一个元组,type()函数返回<class 'tuple'>。dct是一个字典,type()函数返回<class 'dict'>。flg是一个布尔值,type()函数返回<class 'bool'>。
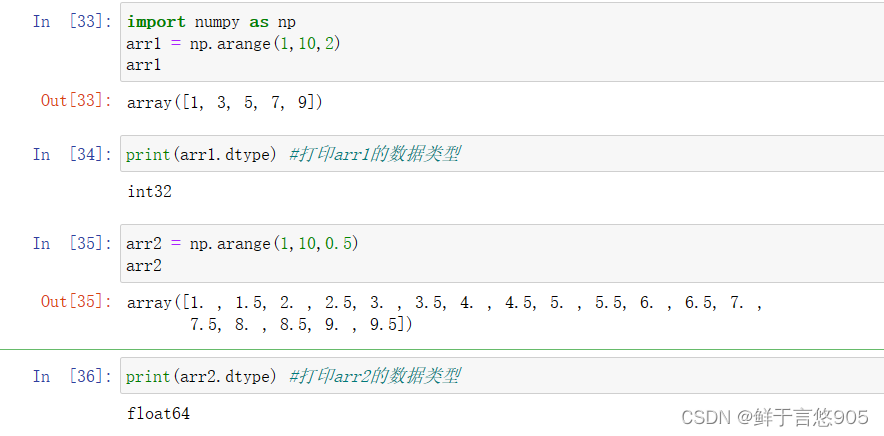
示例
【例】利用numpy库的arange函数创建一维整数数组,并查询数据的类型
关键技术: dtype属性。
在本案例中,首先使用arange方法创建数组arr,然后通过打属性查看数组的数据类型。代码及运行结果如下:
数据类型的转化
astype()
在Python中,astype()函数用于改变Series或DataFrame的数据类型。该函数可以在pandas库中使用。
Series.astype()函数将Series中的元素转换为指定的数据类型。
DataFrame.astype()函数将DataFrame中的某一列或多列转换为指定的数据类型,或将整个DataFrame转换为指定的数据类型。
astype()函数的语法如下:
Series.astype(dtype, copy=True, raise_on_error=True, impute_missing=False)
DataFrame.astype(dtype, copy=True, raise_on_error=True, impute_missing=False)
参数说明:
-
dtype:指定要转换为的数据类型。可以使用Python内置的数据类型,如int、float、str等,也可以使用numpy库中的数据类型,如np.int32、np.float64等。注意,dtype参数只能指定一个数据类型,无法同时转换多个数据类型。 -
copy:可选参数,默认为True。如果设置为True,则创建并返回一个新的Series或DataFrame,数据类型被转换为指定的数据类型。如果设置为False,则在原始Series或DataFrame上直接修改数据类型,返回修改后的Series或DataFrame。 -
raise_on_error:可选参数,默认为True。如果设置为True,则在数据类型转换时出现错误时,抛出异常;如果设置为False,则忽略错误,返回转换后的Series或DataFrame。 -
impute_missing:可选参数,默认为False。如果设置为True,则在转换数据类型时,自动填充缺失值。例如,将字符串类型转换为数值类型时,如果字符串中包含非数值字符,则自动将其填充为NaN。
示例:
import pandas as pd
# 示例1:转换Series的数据类型
s = pd.Series([1, 2, 3, 4])
s = s.astype(float)
print(s)
# 输出:0 1.0
# 1 2.0
# 2 3.0
# 3 4.0
# dtype: float64
# 示例2:转换DataFrame中的某一列数据类型
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]})
df['A'] = df['A'].astype(float)
print(df)
# 输出: A B
# 0 1.0 5
# 1 2.0 6
# 2 3.0 7
# 3 4.0 8
# 示例3:转换整个DataFrame的数据类型
df = df.astype(float)
print(df)
# 输出: A B
# 0 1.0 5.0
# 1 2.0 6.0
# 2 3.0 7.0
# 3 4.0 8.0
以上是astype()函数的简单用法和示例,你可以根据具体需求使用astype()函数来改变Series或DataFrame的数据类型。
强制类型转换
在Python中,可以使用强制类型转换来将一个对象转换为另一种数据类型。下面是几种常见的强制类型转换的方法:
int():将对象转换为整数类型。如果对象是浮点数,则将舍弃小数部分;如果对象是字符串,则要求字符串表示的是一个整数。
a = 10.5
b = int(a)
print(b) # 输出:10
c = "20"
d = int(c)
print(d) # 输出:20
float():将对象转换为浮点数类型。如果对象是整数,则转换为相应的浮点数;如果对象是字符串,则要求字符串表示的是一个数值。
a = 10
b = float(a)
print(b) # 输出:10.0
c = "20.5"
d = float(c)
print(d) # 输出:20.5
str():将对象转换为字符串类型。
a = 10
b = str(a)
print(b) # 输出:'10'
c = 20.5
d = str(c)
print(d) # 输出:'20.5'
bool():将对象转换为布尔类型。可以根据对象的真值来确定转换结果,非零、非空、非空字符串等都会转换为True,其他情况转换为False。
a = 0
b = bool(a)
print(b) # 输出:False
c = "hello"
d = bool(c)
print(d) # 输出:True
list():将对象转换为列表类型。可以将字符串、元组、字典等对象转换为列表。
a = "hello"
b = list(a)
print(b) # 输出:['h', 'e', 'l', 'l', 'o']
c = (1, 2, 3)
d = list(c)
print(d) # 输出:[1, 2, 3]
e = {"a": 1, "b": 2}
f = list(e)
print(f) # 输出:['a', 'b']
tuple():将对象转换为元组类型。可以将列表、字符串、字典等对象转换为元组。
a = [1, 2, 3]
b = tuple(a)
print(b) # 输出:(1, 2, 3)
c = "hello"
d = tuple(c)
print(d) # 输出:('h', 'e', 'l', 'l', 'o')
e = {"a": 1, "b": 2}
f = tuple(e)
print(f) # 输出:('a', 'b')
这些是Python中常见的强制类型转换方法,你可以根据具体的需求选择合适的方法进行类型转换。
示例
【例】利用numpy库的arange函数创建一维浮点数数组arr1,然后将arr1数组的数据类型转换为整型。
关键技术: astype函数。

六、索引设置
索引能够快速查询数据,本节主要介绍索引的应用。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容, Pandas库中索引的作用如下:
- 更方便地查询数据。
- 使用索引可以提升查询性能。
添加索引
直接在导入数据时设置
示例
【例】创建数据为[1,2,3,4,5]的Series,并指定索引标签为['a','b','c','d','e']。
关键技术: index方法设置索引。
该案例的代码及运行结果如下:
更改索引
set_index()
set_index()函数是pandas库中DataFrame对象的一个函数,用于重新设置DataFrame的索引。
语法:
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数说明:
keys:用于设置索引的列名或者列名列表。可以是单个列名的字符串,也可以是列名列表。drop:指示是否在新索引中保留原有的列。默认为True,表示将原有的列从DataFrame中删除。append:指示是否将新的索引添加到原有的索引之后。默认为False,表示不添加。inplace:指示是否在原DataFrame上进行修改。默认为False,表示返回一个新的DataFrame。verify_integrity:指示是否在设置完成后检查新的索引是否唯一。默认为False,表示不检查。
返回值:
返回一个新的DataFrame或者None,取决于参数inplace的设置。
示例:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)
df.set_index('A', inplace=True)
print(df)
df.set_index(['A', 'B'], append=True, inplace=True)
print(df)
在这个示例中,首先创建了一个DataFrame对象df,包含两列’A’和’B’。然后,使用set_index()函数将列’A’作为新的索引。最后,使用set_index()函数将列’A’和列’B’一起作为新的索引,并将新的索引添加到原有的索引之后。
示例
【例】某公司销售数据集"work.csv"内容如下,请设定日期为索引,并用Python实现。
方法一:
关键技术: set_index()函数,可以指定某一字段为索引。
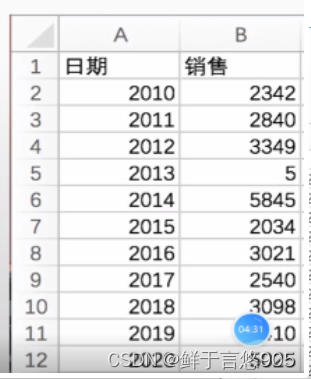
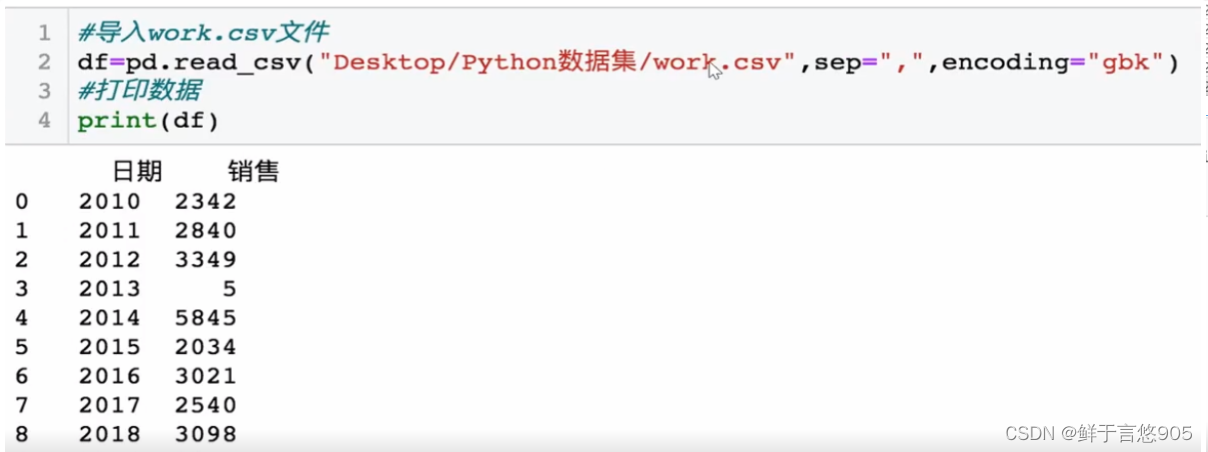
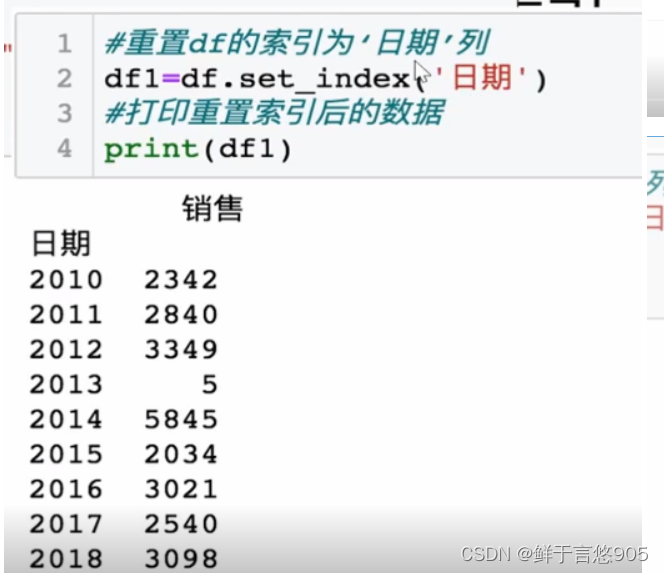
方法二:
在该案例中,除了可以用set_index方法重置索引外,还可以在导入csv文件的过程中,设置index_col参数重置索引,代码及结果如下:
重命名索引
reindex()
Python的reindex()函数用于重新索引DataFrame或Series。
DataFrame是一个二维数据结构,每个列可以有不同的数据类型。Series是一个一维数据结构,它的数据类型都相同。
reindex()函数的作用是返回一个指定轴的新对象,该对象的索引通过参数指定。如果某个索引值在原对象中不存在,reindex()会为该索引值插入缺失值(NaN或None)。
reindex()函数的语法如下:
DataFrame.reindex(index=None, columns=None, fill_value=None)
Series.reindex(index=None, fill_value=None)
参数:
index:重新索引的行索引。columns:重新索引的列索引。fill_value:NaN值替换的值。
示例:
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
# 重新索引行
df_reindexed = df.reindex([2, 1, 0])
# 重新索引列
df_reindexed = df.reindex(columns=['B', 'A', 'C'])
# 使用fill_value参数填充缺失值
df_reindexed = df.reindex(columns=['A', 'B', 'C', 'D'], fill_value=0)
以上示例分别演示了如何重新索引行、列以及如何填充缺失值。
示例一
【例】构建series对象,其数据为[88,60,75],对应的索引为[1,2,3]。请利用Python对该series对象重新设置索引为[1,2,3,4,5]。
关键技术: reindex()方法。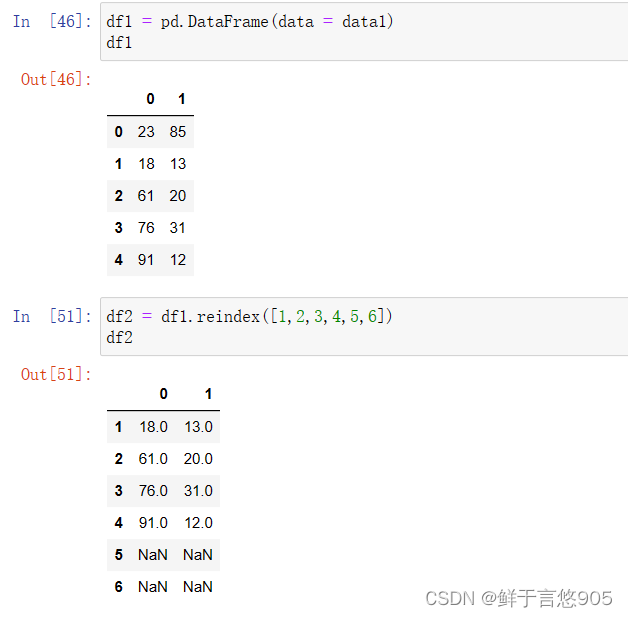
从运行结果中可以看出,对s1索引重置后,数据中出现了缺失值。若要对这些缺失值进行填补,可以设置reindex()方法中的method参数, method参数表示重新设置索引时,选择对缺失数据插值的方法。可以设置为None,bfill (向后填充)、ffill(向前填充)等。

示例二
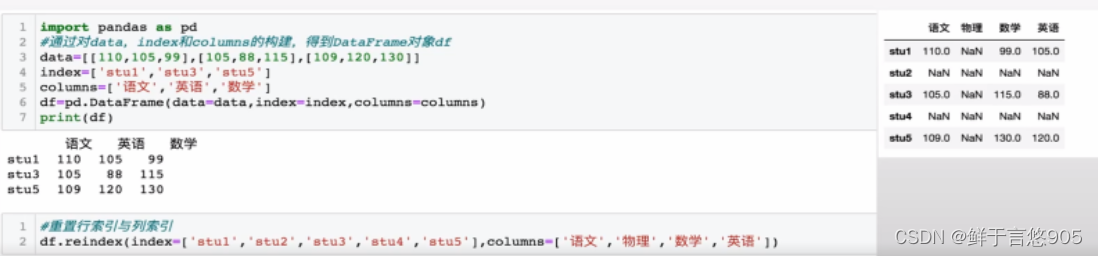
【例】通过二维数组创建如下所示的成绩表,并重置其行索引为stu1,stu2,stu3,stu4,stu5,重置其列索引为['语文', '物理','数学','英语']。
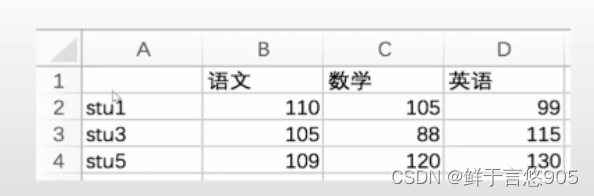
关键技术: reindex()方法中的index参数和columns参数。
在reindex()方法中, index参数表示重置的行索引, columns参数表示重置的列索引。
本案例的代码及运行结果如下。
七、其他
大小写转换
在数据分析中,有时候需要将字符串中的字符进行大小写转换。
在Python中可以使用lower()方法,将字符串中的所有大写字母转换为小写字母。也可以使用upper()方法,将字符串中的所有小写字母转换为大写字母。
lower()
lower()函数是Python中的一个内置函数,用于将字符串中的所有大写字母转换为小写字母,并返回转换后的字符串。
语法:
str.lower()
其中,str是要转换的字符串。
示例:
s = "Hello, World!"
print(s.lower())
输出结果为:
hello, world!
需要注意的是,lower()函数返回的是一个新的字符串,原字符串不会被改变。
此外,lower()函数只能应用于字符串,如果应用于其他类型的数据(如整数或浮点数),会抛出TypeError异常。如果要将其他类型的数据转换为小写字母,可以先将其转换为字符串,再使用lower()函数进行转换。
upper
upper()是Python中的一个字符串方法,用于将字符串中的所有小写字母转换为大写字母。其语法如下:
str.upper()
这里的str是要进行转换的字符串。upper()方法不会改变原始字符串,而是返回一个新的字符串,其中所有小写字母都被转换为大写字母。
下面是一些使用upper()方法的示例:
str1 = "hello world"
str2 = str1.upper()
print(str2) # 输出: "HELLO WORLD"
在上面的示例中,原始字符串"hello world"通过upper()方法转换为了全大写的字符串"HELLO WORLD",然后被赋值给了变量str2。
upper()方法还可以用于处理包含非英文字符的字符串,不仅仅局限于处理英文文本。例如:
str3 = "你好,世界"
str4 = str3.upper()
print(str4) # 输出: "你好,世界"
在上面的示例中,原始字符串"你好,世界"就不包含任何小写字母,因此upper()方法不会对其产生任何影响,返回的结果与原始字符串相同。
需要注意的是,upper()方法只会将小写字母转换为大写字母,对于非字母字符(如数字、标点符号等)不会产生任何影响。例如:
str5 = "123abc!@#"
str6 = str5.upper()
print(str6) # 输出: "123ABC!@#"
在上面的示例中,原始字符串"123abc!@#"中的小写字母"abc"被转换为大写字母"ABC",而数字和标点符号保持不变。
总而言之,upper()方法是一种方便的方法,可用于将字符串中的小写字母转换为大写字母。它可以用于处理各种类型的字符串,无论是纯英文文本还是包含非英文字符的文本。
数据修改与替换
按列增加数据
insert()
insert()是Python中的一个列表方法,用于在指定位置插入一个元素。其语法如下:
list.insert(index, element)
这里的list是要进行插入操作的列表,index是要插入元素的索引位置(从0开始),element是要插入的元素。
下面是一些使用insert()方法的示例:
lst = [1, 2, 3, 4, 5]
lst.insert(2, 10)
print(lst) # 输出: [1, 2, 10, 3, 4, 5]
在上面的示例中,原始列表[1, 2, 3, 4, 5]通过insert()方法在索引位置2处插入了元素10,结果列表变为[1, 2, 10, 3, 4, 5]。
需要注意的是,insert()方法会改变原始列表,而不是创建一个新的列表。如果希望在不改变原始列表的情况下插入元素,可以使用切片和拼接操作来实现。
如果指定的索引超出了列表的范围,insert()方法会将元素插入到列表的末尾。例如:
lst = [1, 2, 3, 4, 5]
lst.insert(10, 10)
print(lst) # 输出: [1, 2, 3, 4, 5, 10]
在上面的示例中,由于索引10超出了列表的范围,insert()方法将元素10插入了列表的末尾。
总而言之,insert()方法可用于在列表的指定位置插入一个元素。它是一种在列表中插入元素的常用方法,可以灵活地操作列表的内容。
loc()
在Python中,loc不是列表的内置函数,而是Pandas库中DataFrame和Series对象的方法之一。
loc函数用于基于标签定位和访问DataFrame或Series中的数据。它可以通过行标签和列标签来定位和访问数据,并支持切片操作。
以下是使用loc函数的一些示例:
import pandas as pd
# 创建一个DataFrame对象
data = {'Name': ['Tom', 'Nick', 'John', 'Alice'],
'Age': [20, 21, 22, 23],
'City': ['New York', 'Paris', 'London', 'Tokyo']}
df = pd.DataFrame(data, index=['A', 'B', 'C', 'D'])
# 使用loc函数定位和访问数据
print(df.loc['A']) # 输出: Name Tom
# Age 20
# City New York
# Name: A, dtype: object
print(df.loc[['A', 'C']]) # 输出: Name Age City
# A Tom 20 New York
# C John 22 London
print(df.loc['A', 'Age']) # 输出: 20
print(df.loc['B':'D', 'Name':'City']) # 输出: Name Age City
# B Nick 21 Paris
# C John 22 London
# D Alice 23 Tokyo
在上述示例中,我们首先创建了一个DataFrame对象df,然后使用loc函数在DataFrame中定位和访问数据。通过传递行标签和列标签,我们可以定向获取特定的数据。此外,loc函数还支持切片操作,可以选择特定的行和列范围。
总结起来,loc函数是Pandas中DataFrame和Series对象的方法之一,用于基于标签定位和访问数据。它提供了灵活的方式来选择和访问DataFrame或Series中的数据。
示例
【例】请创建如下所示的DataFrame数据,并利用Python对该数据的最后增加一列数据,要求数据的列索引为'four' ,数值为[9,10,24]。
若要在该数据的'two' 列和 ‘three'列之间增加新的列,该如何操作?






按行增加数据
loc()
在Python中,loc不是列表的内置函数,而是Pandas库中DataFrame和Series对象的方法之一。
loc函数用于基于标签定位和访问DataFrame或Series中的数据。它可以通过行标签和列标签来定位和访问数据,并支持切片操作。
以下是使用loc函数的一些示例:
import pandas as pd
# 创建一个DataFrame对象
data = {'Name': ['Tom', 'Nick', 'John', 'Alice'],
'Age': [20, 21, 22, 23],
'City': ['New York', 'Paris', 'London', 'Tokyo']}
df = pd.DataFrame(data, index=['A', 'B', 'C', 'D'])
# 使用loc函数定位和访问数据
print(df.loc['A']) # 输出: Name Tom
# Age 20
# City New York
# Name: A, dtype: object
print(df.loc[['A', 'C']]) # 输出: Name Age City
# A Tom 20 New York
# C John 22 London
print(df.loc['A', 'Age']) # 输出: 20
print(df.loc['B':'D', 'Name':'City']) # 输出: Name Age City
# B Nick 21 Paris
# C John 22 London
# D Alice 23 Tokyo
在上述示例中,我们首先创建了一个DataFrame对象df,然后使用loc函数在DataFrame中定位和访问数据。通过传递行标签和列标签,我们可以定向获取特定的数据。此外,loc函数还支持切片操作,可以选择特定的行和列范围。
总结起来,loc函数是Pandas中DataFrame和Series对象的方法之一,用于基于标签定位和访问数据。它提供了灵活的方式来选择和访问DataFrame或Series中的数据。
append()
在Python中,append是一个列表对象的方法,用于向列表的末尾添加一个元素。
append的用法如下:
list.append(element)
其中,list是列表对象,element是要添加的元素。
append方法会将element添加到list的末尾,并返回修改后的列表。这意味着list的长度增加了1,并且最后一个元素是element。
下面是一个示例:
my_list = [1, 2, 3, 4]
my_list.append(5)
print(my_list) # 输出: [1, 2, 3, 4, 5]
在上面的例子中,我们创建了一个列表my_list,然后使用append方法将数字5添加到末尾。最后,我们打印修改后的列表,它包含了添加的元素。
iloc()
在Python中,iloc()函数是Pandas库中的一个用于根据索引位置选取数据的函数。iloc是"index location"的缩写。
iloc()函数的语法如下:
df.iloc[row_index, column_index]
其中,row_index为行索引位置,column_index为列索引位置。可以使用单个整数、整数切片或整数列表作为索引位置。
下面我们来详细解释iloc()函数的使用方法:
- 使用单个整数作为索引位置:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10],
'C': [11, 12, 13, 14, 15]})
# 选取第三行数据
print(df.iloc[2])
- 使用整数切片作为索引位置:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10],
'C': [11, 12, 13, 14, 15]})
# 选取第二行到第四行数据
print(df.iloc[1:4])
- 使用整数列表作为索引位置:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10],
'C': [11, 12, 13, 14, 15]})
# 选取第一行和第三行数据
print(df.iloc[[0, 2]])
- 同时选取行和列:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],
'B': [6, 7, 8, 9, 10],
'C': [11, 12, 13, 14, 15]})
# 选取第二行到第四行的第一列和第三列数据
print(df.iloc[1:4, [0, 2]])
需要注意的是,使用iloc()函数时,索引位置是从0开始计数的。
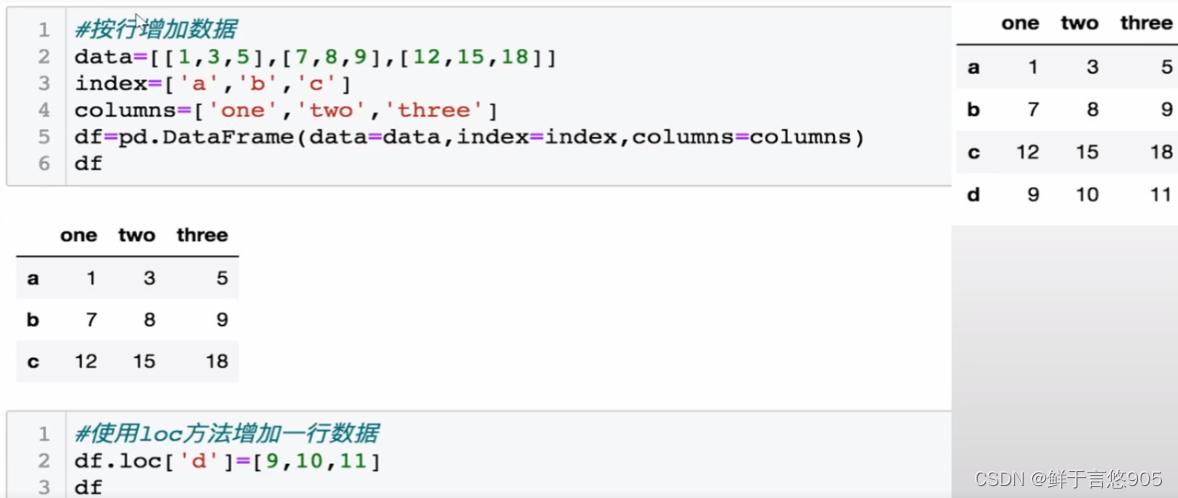
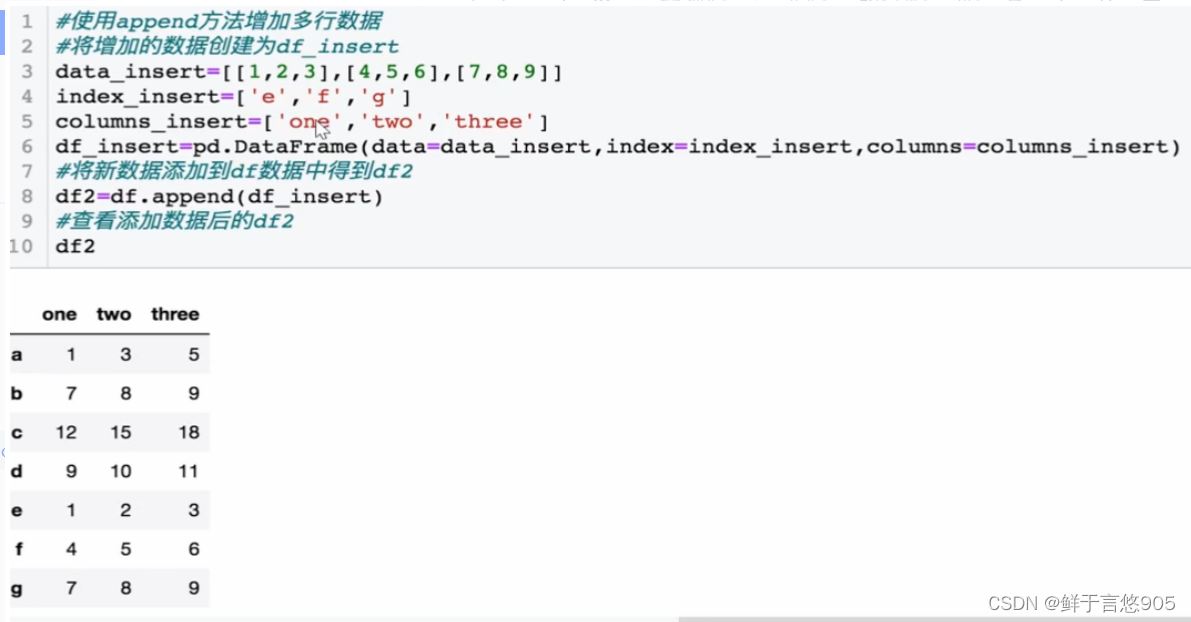
示例
【例】对于上例中的DataFrame数据,增加一行数据,数据行的索引为"d" ,数值为[9,10,11],请使用Python实现。
若要向df数据中再增加三行数据,索引分别为"e" , “f” , “g”,数值分别为[1,2,3], [4,5,6], [7,8,9],在Python中该如何实现?
关键技术: loc()方法和append()方法。
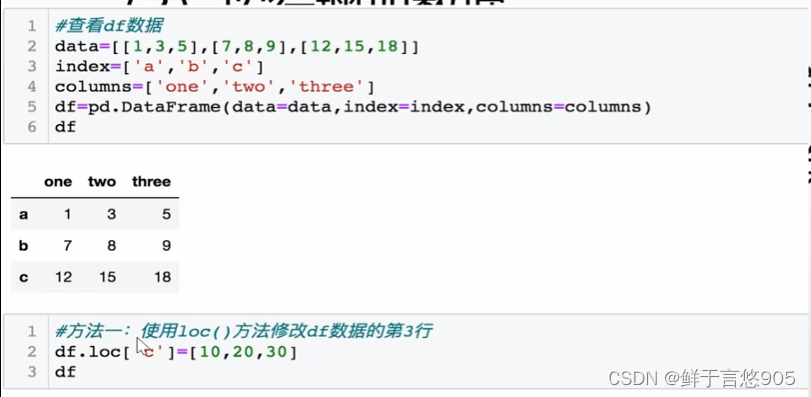
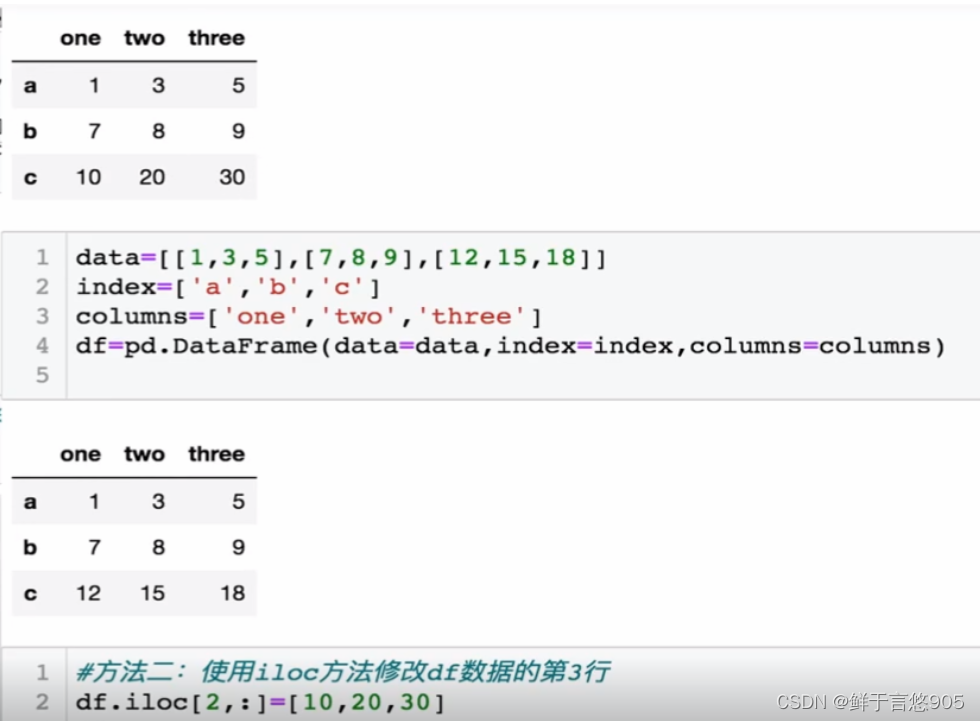
请利用Python将第三行数据替换为[10,20,30]
关键技术: loc()方法和iloc()方法。
数据删除
按列删除数据
drop()
在Python中,drop函数通常用于删除DataFrame或Series中的指定行或列。
在pandas库中,DataFrame是一个二维的数据结构,类似于表格,而Series则是一个一维的数据结构,类似于数组。
在DataFrame中,drop函数的语法如下:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
参数含义如下:
labels:要删除的行或列的标签列表或单个标签。可以是一个字符串,也可以是一个字符串列表。axis:指定删除行还是删除列。默认为0,表示删除行;1表示删除列。index:要删除的行的标签列表或单个标签。与labels参数功能相同,只是在不指定axis的情况下使用。如果同时指定了labels和index,则labels参数优先生效。columns:要删除的列的标签列表或单个标签。与labels参数功能相同,只是在axis=1的情况下使用。level:如果DataFrame具有多层索引,则指定要删除的索引级别。默认为None,表示删除所有级别。inplace:是否在原地修改DataFrame。如果为True,则原地修改DataFrame,即不会返回新的DataFrame;如果为False(默认值),则返回一个新的DataFrame。errors:指定如何处理未找到要删除的标签。默认为’raise’,表示引发一个异常;'ignore’表示忽略。
在Series中,drop函数的语法如下:
Series.drop(labels=None, axis=0, index=None, inplace=False, errors='raise')
参数含义与DataFrame中的参数含义相同。
使用drop函数可以按照指定的标签删除行或列。例如,可以通过以下方式删除DataFrame中的某些行和列:
df.drop(labels=['row1', 'row2'], axis=0, inplace=True)
df.drop(labels=['col1', 'col2'], axis=1, inplace=True)
使用drop函数时要注意,需要指定axis参数来指明删除行还是删除列,同时要根据实际需求选择合适的inplace参数值。
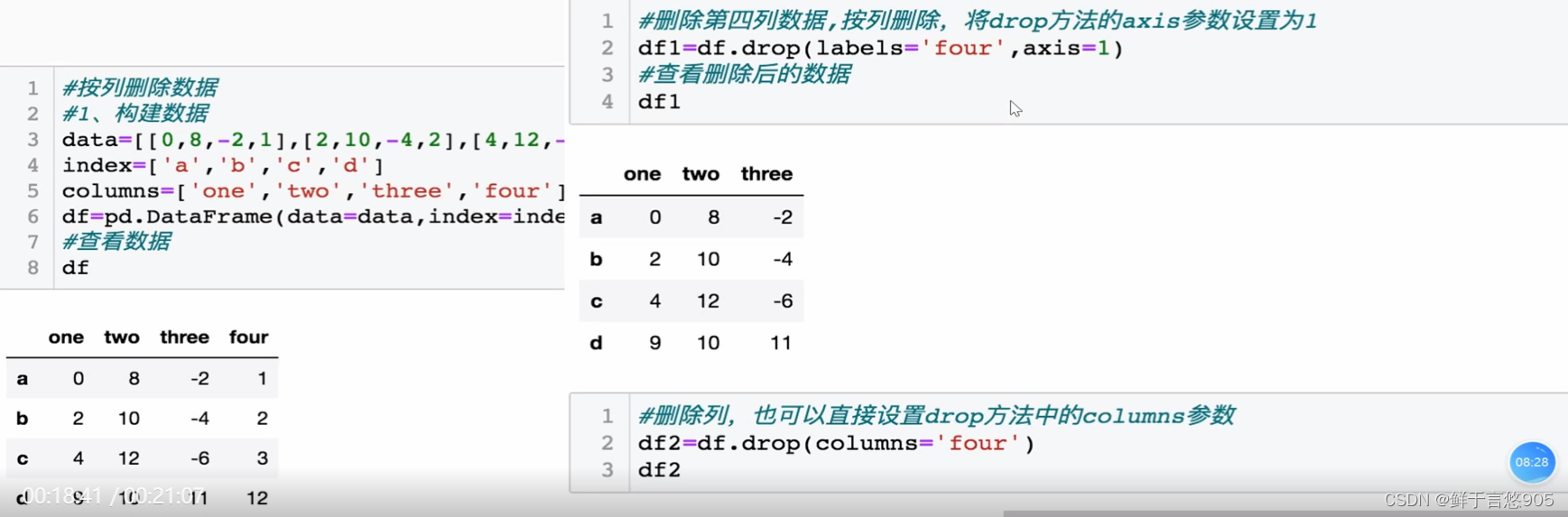
示例
【例】请构建如下DataFrame数据并利用Python删除下面DataFrame实例的第四列数据。
关键技术:该案例中,使用DataFrame的drop()方法,删除数据中某一列。
按行删除数据
示例
【例】对于上例中的DataFrame数据,请利用Python删除下面DataFrame实例的第四行数据。
关键技术:本案例可通过设置drop()方法的index参数, label参数实现,代码及运行结果如下。