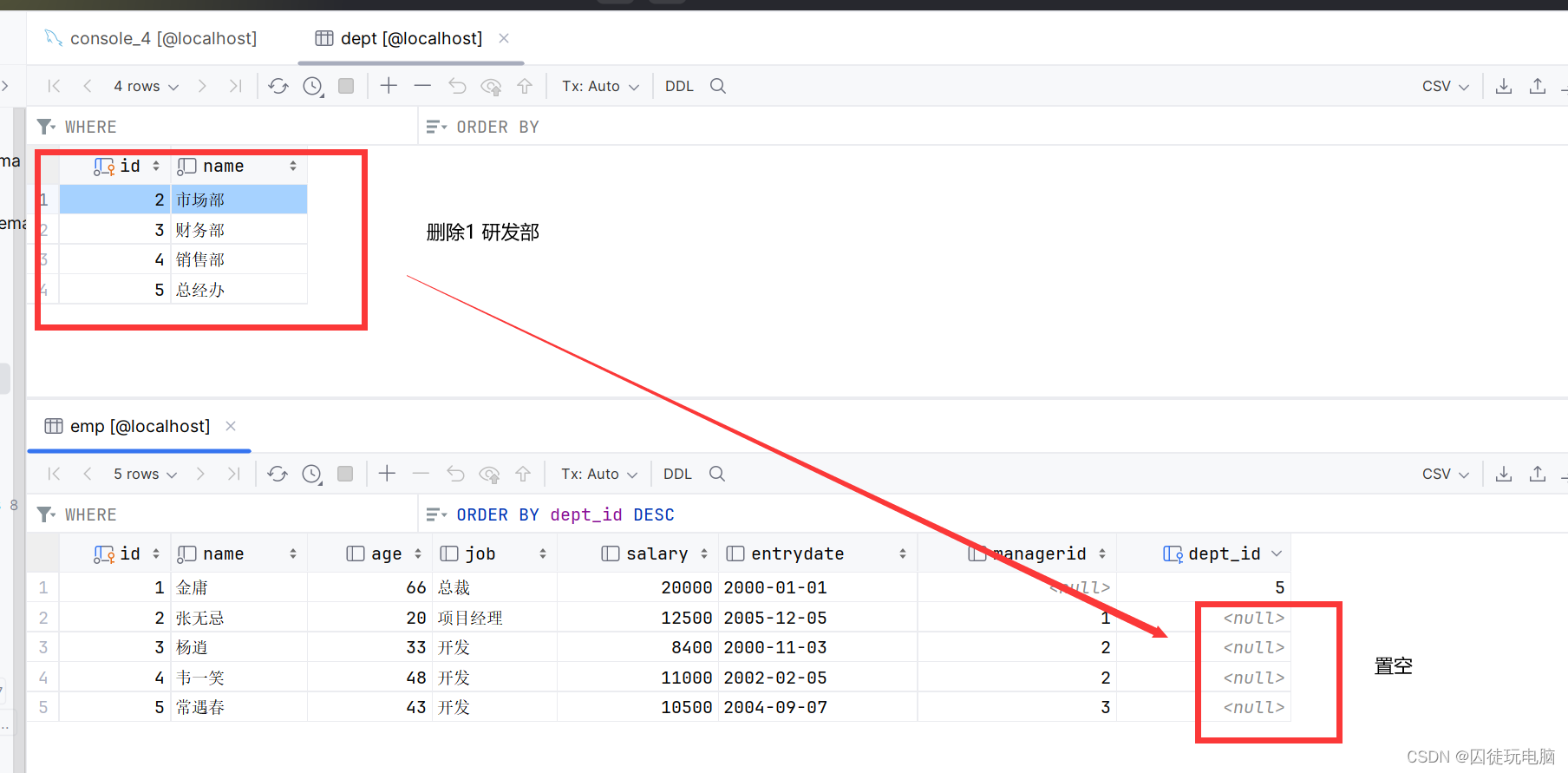
1、前言
好了,那接下来看一下whisper开源库的介绍
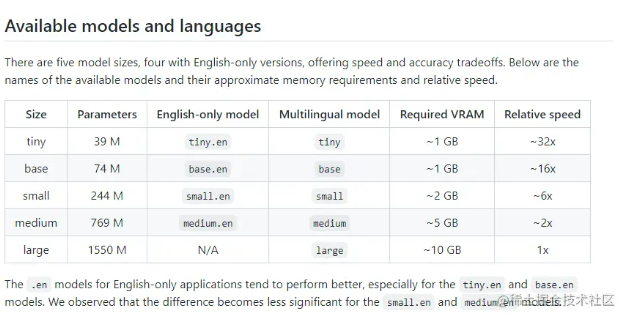
有五种模型大小,其中四种仅支持英语,提供速度和准确性的权衡。上面便是可用模型的名称、大致的内存需求和相对速度。如果是英文版的语音,直接想转换为英文。
本来我是想直接在我的本地电脑上安装环境的,也就是无非安装python、ffmpeg、以及whisper,但是发现电脑配置太低了,而且我想测试一下large模型,CPU 肯定是不行,但是如果用本机的 GPU也是快不到哪里去的。 所以这里我想到谷歌的colab.research.google.com 免费在线运行,而且我可以启用GPU硬件加速,感觉上还是非常快的,当然如果需要你还可以购买。
下面是我的免费配置 colab.research.google.com
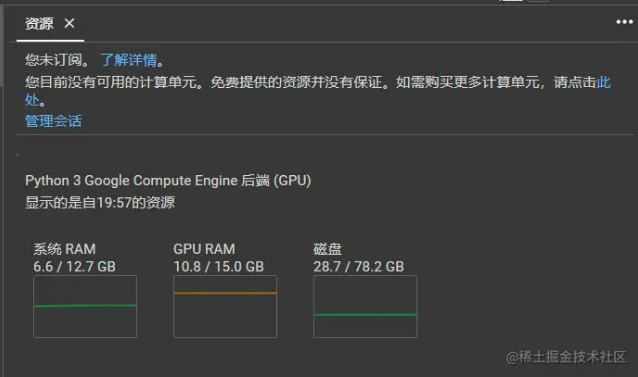
运行起来还是非常流畅,真的香喷喷,如果需要我都想付费了。
可以应用于那些场景
- 会议记录: 直接将录音转换为文字
- 个人视频制作: 很多时候都希望有字幕的效果,听说剪映的效果都没有这个好
- 课堂记录转写:将课堂上的内容记录下来,这样后面直接查看文字版本也是非常方便
- 通话记录:有些重要的电话可将其录音,转换为文字以备后面查询也是非常不错的
- 字幕组:这个就不用说了 有可能还涉及到多语言,准备率很高的话 可以省很多事情
- 实时语音翻译:这个服务器配置够高的话,理论上就非常快速
2、开始实践
2.1、检查colab环境
!nvidia-smi -L !nvidia-smi
运行两个指令结果如下:
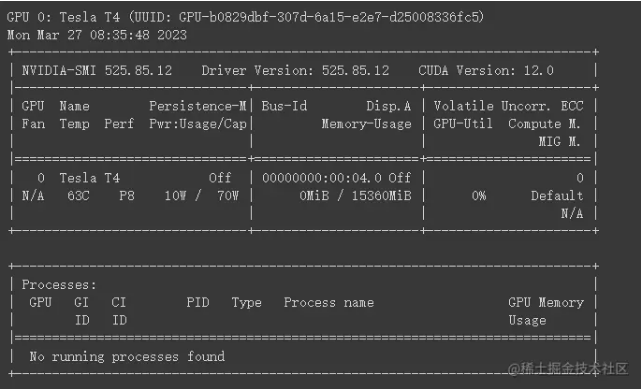
1.!nvidia-smi -L:-L 参数用于列出系统上安装的所有 NVIDIA GPU 设备。运行此命令后,您将看到关于可用 GPU 的信息,包括其型号和 UUID。
2.!nvidia-smi:不带任何参数运行 nvidia-smi 会显示有关 NVIDIA GPU 的详细信息,包括:
-
- GPU 设备的编号、名称、总内存和温度。
- GPU 使用率(如计算、内存和显存使用率)。
- 运行在 GPU 上的进程以及它们的相关信息(如进程 ID、显存占用等)。
只不过这里我还没开始使用GPU而已,所以显示的是空的。
2.2、安装whisper
!pip install requests beautifulsoup4
!pip install git+https://github.com/openai/whisper.git
import torch
import sys
device = torch.device('cuda:0')
print('正在使用的设备:', device, file=sys.stderr)
print('Whisper已经被安装请执行下一个单元')
这里主要就是安装whisper

2.3、 whisper模型选择
#@markdown # ** whisper Model选择** 🧠
Model = 'large-v2' #@param ['tiny.en', 'tiny', 'base.en', 'base', 'small.en', 'small', 'medium.en', 'medium', 'large', 'large-v2']
import whisper
from IPython.display import Markdown
whisper_model = whisper.load_model(Model)
if Model in whisper.available_models():
display(Markdown(
f"**{Model} model is selected.**"
))
else:
display(Markdown(
f"**{Model} model is no longer available.** Please select one of the following: - {' - '.join(whisper.available_models())}"
))
这里我选择的是最大的模型 large-v2,因为我要转换中文字幕,前面四个都只支持英文,这个在文章开头也说了的。
2.4、 开始音频转字幕
audio_path = "/content/downloads/test1.m4a"
audio_path_local = Path(audio_path).resolve()
transcription = whisper.transcribe(
whisper_model,
str(audio_path_local),
temperature=temperature,
**args,
)
# Save output
whisper.utils.get_writer(
output_format=output_format,
output_dir=audio_path_local.parent
)(
transcription,
title
)
我首先要准备一个m4a的音频文件,这里可以直接上传到colab
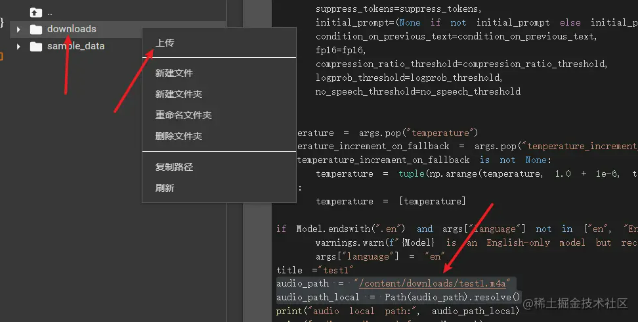
左侧当前目录是 content,然后右键新建文件夹downloads,然后在downloads文件夹上点击上传m4a文件
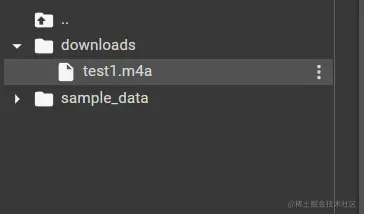
上传完毕后可以看到m4a文件已经在目录下了。
whisper.transcribe 方法有好多的参数
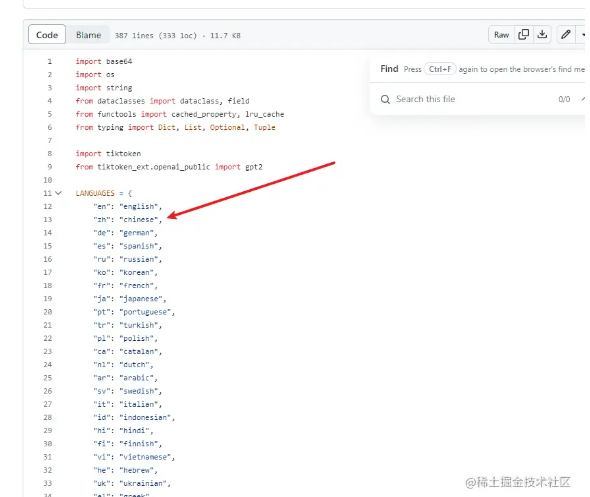
whisper_model主要是设置model模型output_format主要是设置字幕输出的文件格式temperature值设置的较低,那么表述相对精准一些,值越大表述可能更加抽象一点args中有一个language语言,比如这里我要将音频转换为中文字幕 设置为cn或者chinese这里主要可以查看 whisper/tokenizer.py at main · openai/whisper · GitHub
2.4、运行查看效果
点击运行后可以看到一段一段的在执行转换了,整体感觉运行还是非常流畅了,这比看别人在本地运行速度可是快多了
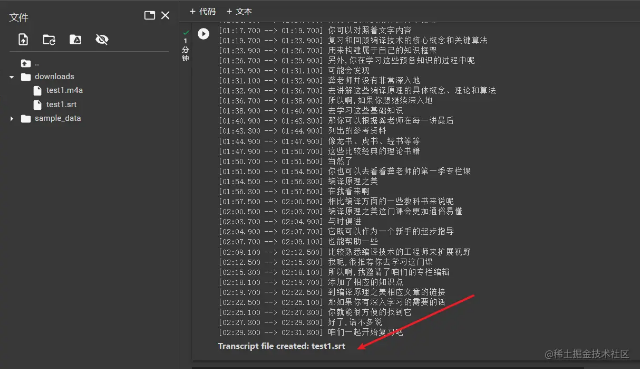
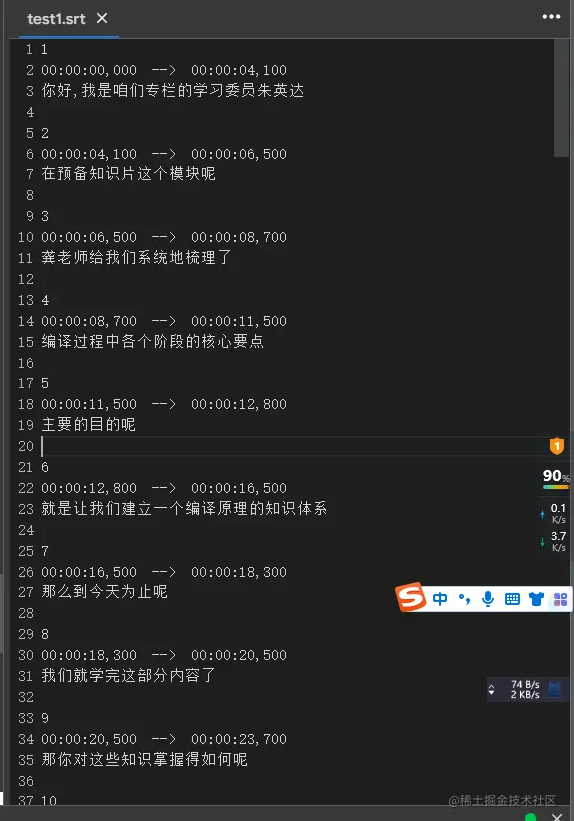
最后可以看到srt字幕文件也已经生成了,可以直接点击左侧文件点击下载即可。 生成的srt文件如下
3、总结
这个whisper相当于离线版本,可以自己部署到本地或者服务器提供给自己使用,相信后续OpenAI应该还会有更新,提供更多精彩的功能使用。
from:
5、ChatGPT开源的whisper音频生成字幕,可本地搭建环境运行,效果质量很棒-阿里云开发者社区
kkview远程控制 手机电脑看屏幕和摄像头