Pandas库的引用,常用两大功能Series(一维)和DataFrame(二维和多维)
Pandas是Python第三方库,提供高性能易用数据类型的分析工具。
Pandas基于NumPy实现,常与NumPy和Matplotlib一起使用。
Numpy和Pandas的对比
| Nupmy | Pandas |
|---|---|
| 基础数据类型(主要是Ndarray数组类类型) | 扩展数据类型(包括Series和DataFrame) |
| 关注数据的结构表达 | 关注数据的应用表达(如何有效的清洗和运算) |
| 维度:数据间的关系 | 数据与索引间的关系 |
import pandas as pd
d=pd.Series(range(20))
d.cumsum()
Series类型
Series类型由一组数据与之相关的数据索引组成
Pandas既可以自动生成索引也可以自主定义索引。
Series的自动索引
import pandas as pd
d=pd.Series([9,8,7,6])
d

Series的自定义索引
import pandas as pd
b=pd.Series([9,8,7,6],index=['a','b','c','d'])
b

Series类型的创建
Series类型可以由如下类型创建
- Python列表
- 标量值
- Python字典
- ndarray
- 其他函数
1.从标量值创建Series类型
import pandas as pd
S=pd.Series(25,index=['a','b','c'])
S

2.从字典创建Series类型
2.1直接使用字典
import pandas as pd
d=pd.Series({'a':9,'b':8,'c':7})
d

2.2字典和索引结合式
e=pd.Series({'a':9,'b':8,'c':7},index=['c','a','b','d'])
e

3.从ndarray类型创建
import pandas as pd
import numpy as np
n=pd.Series(np.arange(5))
n

import pandas as pd
import numpy as np
a=pd.Series(np.arange(5),index=np.arange(9,4,-1))
a

Series类型生成总结
Series类型可以由如下类型创建
- Python列表,index与列表元素个数一致。
- 标量值,index表达Series类型的尺寸。
- Python字典,键值对中的“键”是索引,index从字典中进行选择操作。
- ndarray()索引和数据都可以通过ndarray类型创建。
- 其他函数,range()函数等。
Series类型的基本操作
- Series类型包括index和values两部分。
- Series类型的操作类似ndarray类型。
- Series类型的操作类似Python字典类型。
Series类型的操作类似ndarray类型
- 索引方法相同,采用[]。
- NumPy中运算和操作可用于Series类型。
- 可以通过自定义索引的列表进行切片。
- 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片。
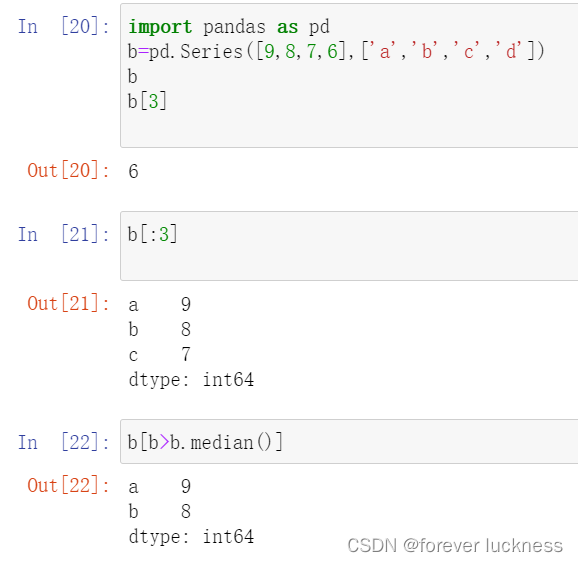
import pandas as pd
b=pd.Series([9,8,7,6],['a','b','c','d'])
b
b[3]##取索引为3的值
b[:3]##切片索引,得到的仍然是Series系列的数据
b[b>b.median()]##获取大于b中位数的系列
上述结果分别
Series类型的操作类似Python字典类型
- 通过自定义索引访问
- 保留字in操作
- 使用.get()方法
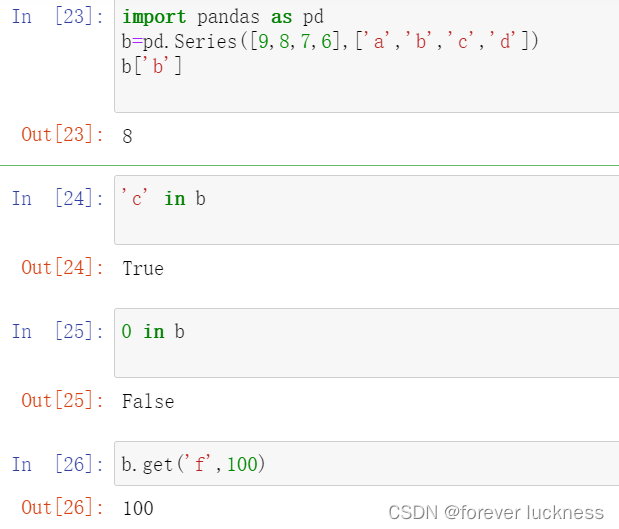
import pandas as pd
b=pd.Series([9,8,7,6],['a','b','c','d'])
b['b']##自定义索引
'c' in b##判断索引c是否在b的自定义索引里
0 in b##判断索引0是否存在b的索引里,注意这里只能判断自定义索引,对于默认索引不能判断
b.get('f',100)##为序列b添加元素
对应的结果
Series类型对其操作
import pandas as pd
a=pd.Series([1,2,3],['c','d','e'])
b=pd.Series([9,8,7,6],['a','b','c','d'])
a+b##对a和b中的数据索引对齐后在进行运算

Series类型的name属性
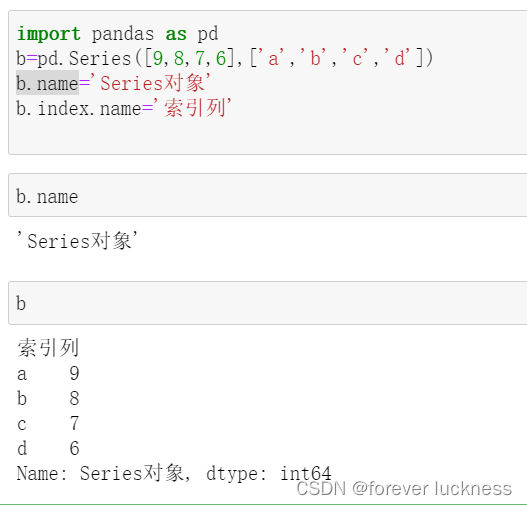
Series对象和索引都可以有一个名字,存储在属性.name中
import pandas as pd
b=pd.Series([9,8,7,6],['a','b','c','d'])
b.name='Series对象'
b.index.name='索引列'
Series类型的修改
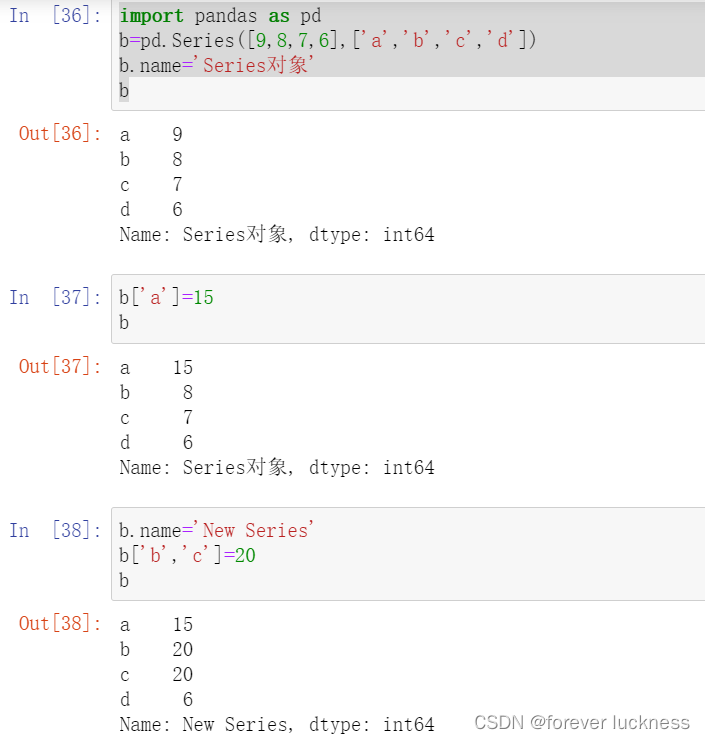
Series对象可以随时修改并即刻生效
import pandas as pd
b=pd.Series([9,8,7,6],['a','b','c','d'])
b['a']=15
b.name='Series对象'
b.name='New Series'
b['b','c']=20
b
操作结果:修改之后原来的数据立马被修改
对Series类型的总结
Series是一维带‘标签’的数组
index_0 对应data_a
Series基本操作类似ndarray和字典,根据索引对齐。
Pandas库的DataFrame类型
- DataFrame类型由共用相同索引的一组列组成。
- DataFrame是一个表格型的数据类型,每列值类型可以不同。
- DataFrame既有行索引,也有列索引。
- DataFrame用于表达二维数据,但可以表达多维数据。

DataFrame类型的创建 - 二维ndarray对象。
- 由一维ndarray\列表、字典、元组或Series构成的字典。
- Series类型。
- 由其他的DataFrame类型。
1.从二维ndarray对象创建
import pandas as pd
import numpy as np
d=pd.DataFrame(np.arange(10).reshape(2,5))
d

2.从一维ndarray对象字典创建
import pandas as pd
dt={'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([9,8,7,6],index=['a','b','c','d'])}
d=pd.DataFrame(dt)
d

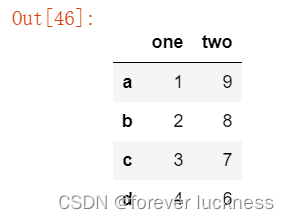
3.从列表类型的字典创建
import pandas as pd
d1={'one':[1,2,3,4],'two':[9,8,7,6]}
d=pd.DataFrame(d1,index=['a','b','c','d'])
d
import pandas as pd
d1={'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d=pd.DataFrame(d1,index=['c1','c2','c3','c4','c5'])
d
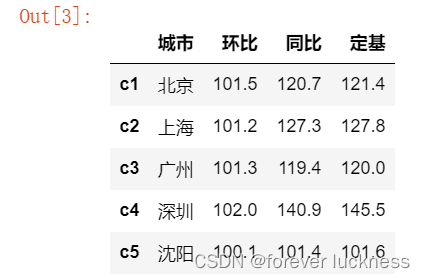
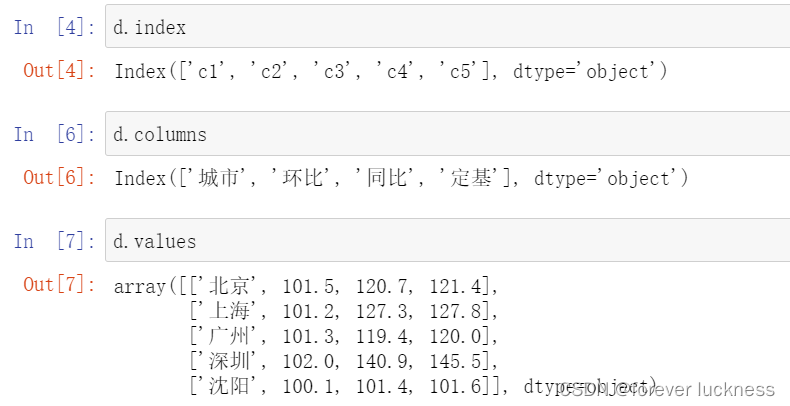
DataFrame类型
DataFrame是二维带”标签“的数组,其操作类似Series,依据行列索引。
数据类型操作
如何改变Series和DataFrame对象?
增加或重排:重新索引
删除:drop
重新索引
.reindex()能够改变或重拍Series和DataFrame索引
import pandas as pd
d1={'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d=pd.DataFrame(d1,index=['c1','c2','c3','c4','c5'])
d=d.reindex(index=['c5','c4','c3','c2','c1'])
d
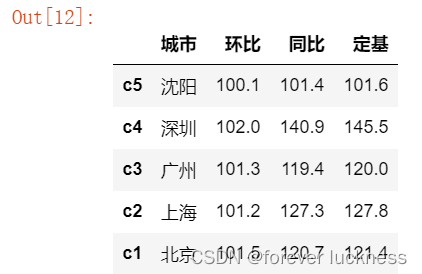
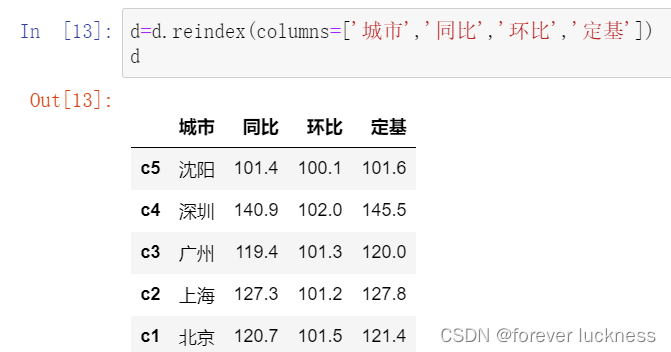
d=d.reindex(columns=['城市','同比','环比','定基'])
d
重新索引
.reindex(index=None,columns=None,…)的参数
| 参数 | 说明 |
|---|---|
| index,columns | 新的行列自定义索引 |
| fill_value | 重新索引中,用于填充确实位置的值 |
| method | 填充方法,ffill当前值向前填充,bfill向后填充 |
| limit | 最大填充量 |
| copy | 默认True,生成新的对象,False时,新旧相等不复制 |
关于columns重新索引
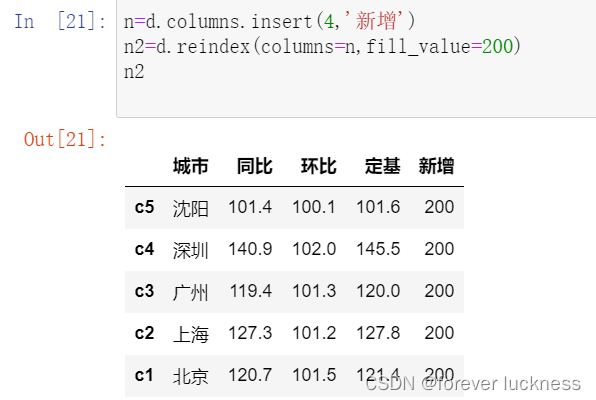
n=d.columns.insert(4,'新增')
n2=d.reindex(columns=n,fill_value=200)
n2
Pandas的索引类型
- Series和DataFrame的索引是Index类型
- Index对象是不可修改类型
索引类型的常用方法
| 方法 | 说明 |
|---|---|
| .append(idx) | 连接另一个Index对象,产生新的Index对象 |
| .diff(idx) | 计算差集,产生新的Index对象 |
| .intersection(idx) | 计算交集 |
| .union(idx) | 计算并集 |
| .delete(loc) | 删除loc位置处的元素 |
| .insert(loc,e) | 在loc位置增加一个元素 |
例子
import pandas as pd
d1={'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d=pd.DataFrame(d1,index=['c1','c2','c3','c4','c5'])
d
nc=d.columns.delete(2)
nc
ni=d.index.insert(5,'c0')
ni
nd=d.reindex(index=ni,method='ffill')
nd
删除指定索引对象
.drop()能够删除Series和DataFrame指定行或列索引
a=pd.Series([9,8,7,6],indes=['a','b','c','d'])
a
a.drop(['b','c'])##不改变原来a的元素,若需要删除后的数据,需要新赋值

d.drop('c5')##删除第五行
d.drop('定基',axis=1)##删除列中的定基

Pandas算术运算法则
- 算术运算根据行列索引,补齐后运算,运算默认产生浮点数。
- 补齐时缺项填充NaN(空值)
- 二维和一维、一维和零位空间为广播运算。
- 采用±*/符号进行的二元运算产生新的对象。
import pandas as pd
import numpy as np
a=pd.DataFrame(np.arange(12).reshape(3,4))
a
b=pd.DataFrame(np.arange(20).reshape(4,5))
b
a+b
a*b


数据类型的算术运算/方法形式运算
| 方法 | 说明 |
|---|---|
| .add(d,**argws) | 类型间加法运算,可选参数 |
| .sub(d,**argws) | 类型间减法运算,可选参数 |
| .mul(d,**argws) | 类型间的乘法运算 |
| .div(d,**argws) | 类型间除法运算,可选参数 |
import pandas as pd
import numpy as np
a=pd.DataFrame(np.arange(12).reshape(3,4))
a
b=pd.DataFrame(np.arange(20).reshape(4,5))
b
b.add(a,fill_value=100)##表示b+a运算,然后a不足的部分,用100为基数进行运算,相加
a.mul(b,fill_value=0)##表示a*b,不足的部分用0计算

不同维度间为广播运算,一维Series默认在轴1参与运算。
比较运算法则
- 比较运算只能比较相同索引的元素,不进行补齐。
- 二维和一维、一维和零维间为广播运算。
- 采用>,<,>=,<=,==,!=等符号进行的二元运算产生布尔对象。
同纬度运算,尺寸一致,若不同维度,由于不能自动对齐,因此将会报错。
不同维度,广播运算,默认在1轴。
Pandas入门小结
- Series=索引+一维数据
- DataFrame=行列索引+二维数据
- 理解数据类型与索引的关系,操作索引即操作数据。
- Pandas数据的操作:重新索引、数据删除、算术运算、比较运算。
- 像对待单一数据一样对待Series和DataFrame对象。