视频:https://www.bilibili.com/video/BV1QA4m1F7t4/
教程:https://github.com/InternLM/Tutorial/blob/camp2/huixiangdou/readme.md
作业:https://github.com/InternLM/Tutorial/blob/camp2/huixiangdou/homework.md
项目地址:https://github.com/InternLM/HuixiangDou
RAG技术简介
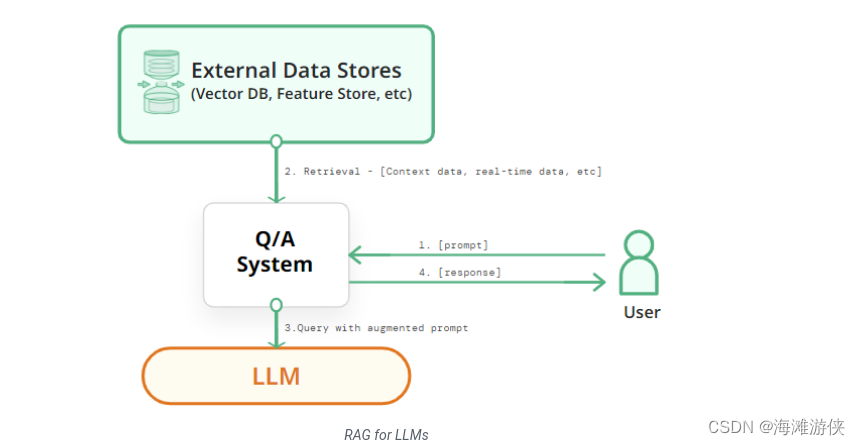
Retrieval Augmented Generation
Retrieval-augmented generation (RAG) for large language models (LLMs) aims to improve prediction quality by using an external datastore at inference time to build a richer prompt that includes some combination of context, history, and recent/relevant knowledge (RAG LLMs). RAG LLMs can outperform LLMs without retrieval by a large margin with much fewer parameters, and they can update their knowledge by replacing their retrieval corpora, and provide citations for users to easily verify and evaluate the predictions.
简单来说,RAG提供了一种更新大模型知识库的高效率方法。可以用来添加
- 实时信息
- 用户特定信息
项目内容
- 基础环境配置(基于conda完成)
2. 模型权重文件下载
使用下列链接
https://huggingface.co/maidalun1020/bce-embedding-base_v1/tree/main
3. 在此前的conda环境中,安装相关deps, 然后切换分支
4. 修改 embedding_model_path, reranker_model_path, local_llm_path
5.下载茴香豆的语料库,提取知识库特征,创建向量数据库。增加茴香豆相关的问题到接受问题示例中
6.再创建一个测试用的问询列表,用来测试拒答流程是否起效.在确定好语料来源后,创建 RAG 检索过程中使用的向量数据库。
7.最后运行茴香豆
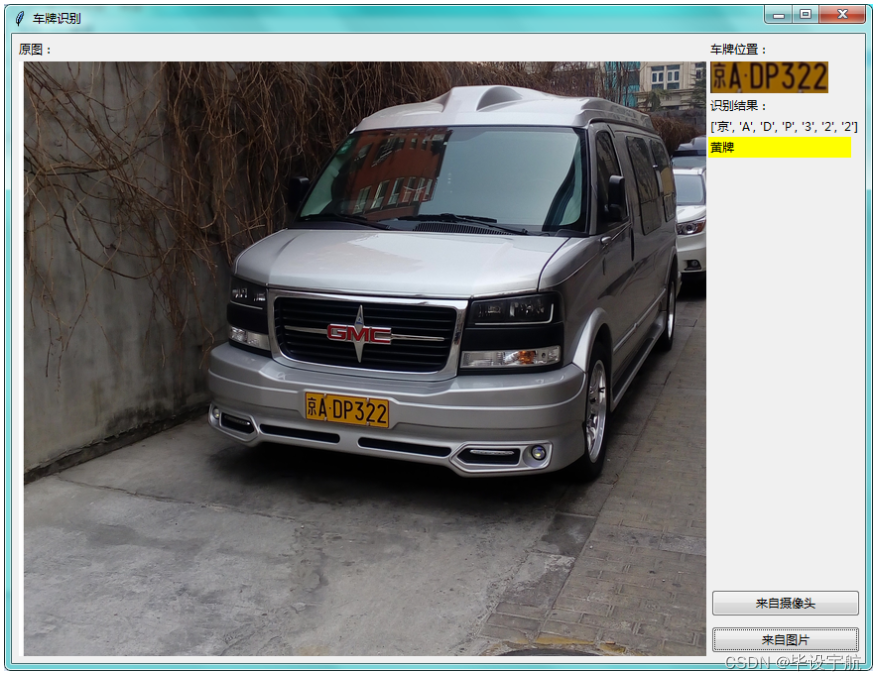
交互screnshot如下

参考链接:
What is Retrieval Augmented Generation (RAG) for LLMs? - Hopsworks