组织好的,可重复利用的,用来实现单一,或相关联功能的代码段,避免重复造轮子,增加程序复用性。
定义方法为def 函数名 (参数)
参数可动态传参,即使用*args代表元组形式**kwargs代表字典形式,代替形参,函数的return返回值有多个时组织为元组返回。
函数操作
闭包函数
指内部函数包含对外部而非全局作用域变量的引用,示例如下段代码:
def out():
b=13
def out1(): # 闭包三要素,1,必须有内嵌函数
print( b) # 必须引用嵌套函数上一级变量
return out1# 必须返回嵌套函数
a=out()
print(a.__closure__) # 通过该方法判断函数是否闭包
(<cell at 0x7fb8ddf3b328: int object at 0x2539b48>,)# 执行结果中出现cell 判断为闭包函数
上述代码也揭示了函数名的实质,即内存地址,该函数方法的用途是在函数中封装一些预设数据或属性,一定程度上也能提高函数重复执行的效率,举例如下:
from urllib.request import urlopen
def fun(): # 获取网页内容的函数
content =urlopen("www.baidu.com").read.decode('UTF-8') # 获得网页内容
def fun1():
return content # 嵌套函数中返回网页内容
get_url=fun() # 实质等同于get_url=content
print(get_url())
经过一次闭包,执行时只需要打开一次访问url,保存内容到内部函数中,避免重复访问,这种方法当然可以通过其他方法实现,但更重要的是,输出内容由上级函数确定,实现了给函数提前预设数据,可这种目的仍有很多其他方法可以实现,闭包并没体会到什么妙处,可能接触的实践还是少吧,以后再补充。
作用域
经过闭包的学习我们可能想到,函数中的变量和主函数中的变量命名重复时,函数执行如何判断操作的到底是哪一个呢?由此引出了作用域。
函数内要修改全局变量,因为函数的作用域只在函数内部而无法访问函数外的部分,我们需要给变量添加global声明,来告诉函数该变量来自函数外的全局变量,相应的,声明该变量来自上一级,而非全局变量或局部变量,使用nonlocal来进行声明,虽然经过我的简单尝试,函数执行默认就找了最上一级的变量,而不用单独声明。
装饰器
在原函数代码不变动的前提下,给代码增加额外的功能,利用闭包实现,新函数内嵌原函数,并加了新功能,闭包方法实现如下:
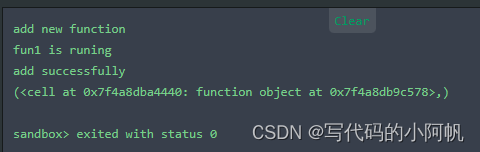
def fun1():
print("fun1 is runing")
def fun2(fun):# 原函数作为参数传入新函数
def fun3(): # 闭包函数
print("add new function")
fun() # 调用参数函数
print("add successfully")
return fun3 # 返回内嵌函数内存地址
fun1=fun2(fun1) # 即新的fun1=fun3
fun1()
print(fun1.__closure__)
输出结果如下图:
这么写更多的像是障眼法,只是用了新的函数覆盖了原有的函数名,python觉得这样不太优雅,创造了装饰器,来掩盖这一过程,使用装饰器的代码如下:
def fun2(fun):
def fun3():
print("add new function")
fun()
print("add successfully")
return fun3
@fun2 # 替换了fun1=fun2(fun1)语句
def fun1():
print("fun1 is runing")
fun1()
print(fun1.__closure__)
就是在被装饰函数的上方加@新函数名,实质就是替换了原有fun1=fun2(fun1这一函数名新旧覆盖的过程。
wrap装饰器
经过装饰器装饰后的函数,原本__doc__和__name__查看注释和函数名的方法也被更改,在新函数内部增加@wrap(原函数),在装饰代码中加wrap还原函数本质,也可通过在装饰器中设置参数来判断是否进行装饰。
装饰器主要解决函数的开放封闭原则,软件实体应该是可扩展但不可修改的,对扩展开放,对修改封闭。
迭代器
用于访问集合元素的一种形式,是一个可记住遍历位置的对象,isinstance(iterable)方法判断对象是否为可迭代类型,字符串,元组,字典和集合都可迭代。
本质是通过iter方法提供迭代器,对象先使用next方法获取下一个迭代器,通过迭代器获取每一个数据,for循环就是基于迭代器协议,提供一个统一的,可以遍历数据的方法。
生成器
常规函数定义方法,但使用yield返回结果,挂起函数状态,本质是一个迭代器,使用next方法继续向后执行,好处是不会一次在内存生成太多数据,示例代码如下:
def generate():
yield 1
yield 2
yield 3
g=generate()
print(next(g))
print(next(g))
输出为
1
2
获取生成器返回值也可以使用send方法,不同之处是该方法可以将参数传给上一个yield的位置,进行数据交互,示例代码如下:
content =yiled 1
g.send("hello") # 此时函数内content赋值为hello 此外迭代器的第一次生成不能send,或只能send None内容
推导式
把原本应该独立完成的函数封装的功能,写入到列表或字典中进行推导,如l=[i for i in range(10) 可加判断]多列表嵌套可用多次for循环推导,有点类似SQL语句。
函数的其他形态
内置函数
这部分很多很繁琐,直接贴个超链接,有事到这查。
匿名函数
临时使用的函数,无需指定函数名,规定方式为函数名=lambda 参数:函数体,只用于无需多次调用的,使用一句话实现的函数,用后销毁,节约资源。
递归函数
人用迭代,神用递归,说起来很简单,就是函数调用函数本身,关键在于递归无限进行,需要指定退出条件,递归深度最大约为997,可以通过import sys sys.setrecursionlimit(层数)的方式修改,但如果深度大于997还未解决,说明该问题不适合使用递归方法。
汉诺塔
来自印度神话,创世神梵天让谁把一摞黄金盘子通过三根钻石柱子转移到最后一根上,任何时候大的都不能放到小的上面,递归写法如下:
def move(n,a,b,c):#n个盘片,abc三根柱子
if n==1:a->c #只有一个盘子时拿过去就行了
else:
move(n-1,a,c,b) # 将最下方盘片上的盘子移动到b处
a->c # 此时只剩下最下方的大盘子,移动到c即可
move(n-1,b,a,c) #再调用自身,将余下的盘子从b移动到c
主要是把每一步移动思想的根找出来,重复调用自身即可。
不知道谁研究的这游戏,如果有64个盘片,一秒移动一次得用5845亿年,地球到现在也就活了45亿年,地外文明流传下的游戏吗?
模块
实现代码和功能的复用,为了避免臃肿,一般需要时才导入模块,使用import 模块名或from 模块名 import 函数名的方法实现,前者使用时需要对函数加模块名用于查找,即模块名.函数名,后者则当成本地函数来执行,导入后自动执行模块内的语句,有时函数名过长时可以使用import 模块名 as 别名的方法起别名,此时原模块名失效。
还有from ..import *导入所有函数的方法,这种一般不使用,因为一个模块可能太多函数,导入了影响本地函数命名空间,也可以使用__all__=[函数名]的方法加以限定,模块内的成员前加下划线_表示私有变量,导入后无法使用,用于限定主函数的__name__变量,在执行时为main,导入时为模块名。
模块的搜索路径为,内存区已加载的,自建文件夹,sys.path路径中包含的模块,为了提高加载速度。
python的编译
解释器在_pycache目录中缓存每个模块编译后的版本,文件以pyc结尾,学到这里有一个疑问,既然python是解释型语言,为什么还会有编译版本呢?经过简单查询大概了解为:解释器的确可以将源码解释为计算机可执行的语言,但为了避免每次都重复解释,解释器将翻译的字节码文件保存下来,如果源码没有更改(通过检查时间戳实现),则直接执行pyc文件,这种方法也能更好地保护源码,免得python代码以源码形式裸奔。
还有说法是python最后也是通过虚拟机实现的,那这Java,C++啥的语言感觉都没啥本质区别了,殊途同归,编译和第一次解释都要多花点时间,后面都通过执行机器码提高效率,语言本身的性能确实可以忽略不计了,对用户来说哪个开发效率高就用哪个。
包
包是模块的集合,包的集合是库,那模块就是函数的集合,包和库本质都是一种模块,导入时执行__init__文件内的代码,有绝对导入和相对导入两种方法,前者使用绝对路径,后者用.或..作为当下目录或上层目录的包。
常用模块
序列化
将原本字典,列表等内容转换为字符串的过程,因为前后端的语言可能不同,但传递参数等操作需要一个统一标准,目前为json,为了数据结构统一,持久化存储对象,使程序更具维护性,产生了序列化模块。
json模块主要有四种方法,分别为dumps序列化,dump文件序列化,loads反序列化,load文件反序列化,具体方法示例为json.dumps(dic)。
pickle模块,酸黄瓜用于python特有类型和python的数据类型之间的转换,转换只有python能够识别,方法与json相同,主要用于python数据的持久化中,保存的数据无法直接打开,必须通过python读取
shelve模块,该模块只有open和close方法,文件序列化后使用字典方式读写,不支持多个程序同时操作一个文件。
摘要算法
即哈希或散列算法,将任意长度的数据转换为长度固定的字符串,可通过hashlib模块实现,具体方法有MD5和SHA1,该方法单向不可逆,便于隐藏原文,只知哈希想逆推是不可能的,密码的比较就是比较哈希是否相同。
但目前却有很多所谓哈希解码的,大多是通过常用数据库碰撞的方法,就是把很多数据对应的哈希提前算好,输入哈希时匹配查找,针对一些常用的弱口令可行,这也解释了为什么设置密码要复杂,也不要通用,免得被加到数据库中。此外厂商大多也会对我们的口令进行加盐,这也给我们自己设置密码提供了思路,在已有口令中添加平台相关的字段,就能获得一个不重复且安全性高的口令。
具体方法示例如下:
import hashlib
if __name__ == "__main__":
md5=hashlib.md5() # 获取容器对象
s="hello"
md5.update(s.encode()) # 传入数据
print(md5.hexdigest()) # 获取数据
# 输出为5d41402abc4b2a76b9719d911017c592 此时解码网站可以解开
# sha方法与md5完全一致
尝试稍微加点盐s="hello@python5.5",查询结果为:
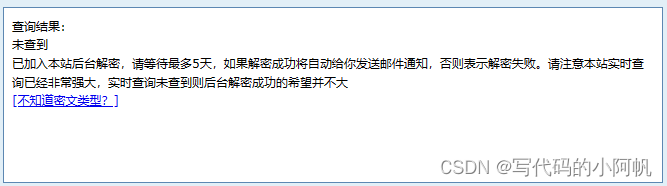
可见加上自己的特定标识后,口令破解就很困难了。
配置文件相关
configparser模块用于配置与ini文件类似的文件格式,使用方法为conf=configparser.configParser()打开文件,conf[键]={内容}。
logging模块用于日志相关配置,有logging、debug、info、warning、error、critical五种输出格式,其中后三种为显示输出信息。
正则表达式
re模块,用特殊含义的符号描述字符串的方法,
| \w | 字母、数字、中文、下划线 |
|---|---|
| \W | 非字母数字中文下划线的内容 |
| \s | 空白符,包括空格、tab、换行符 |
| \S | 除空白符外的字符 |
| \d | 数字 |
| \D | 非数字 |
| \A | 匹配开头 |
| \z | 结尾匹配 |
| \z | 结尾匹配 |
| ? | 左边出现一次或零次的字符 |
| […] | 字符组中的字符 |
| [^…] | 除字符组中的字符 |
| * | 多个左边字符 |
| n | 出现n次的左边字符 |
| () | 内表达式,表示一个组 |
该方法主要用于爬虫,可以通过正则匹配html,获取网页内容,具体使用方法有re.findall(规则,字符串)找到全部满足规则的内容,以列表形式返回,更多更详细的方法可自行查询。
需要对返回方法进行分组时使用()实现,限制输出,?:表示将整体匹配处理,而不只是()内的内容。
简单爬虫示例
import urllib,re
url=" "
# html=urlopen(url.read()) # 传递url打开网址,此时多半会拒绝,这是因为网页的反爬机制,验证了UA,获取电脑浏览器等用于表面身份的信息
user-agent=' '
req=Request(url.headers={'user-agent':user-agent}) # 传递ua信息
html=urlopen(req).read().decode('gbk') # 获取网址内容
list=re.findall(规则,html) # 多个元素返回列表
# 下载可以使用第三方库或二进制写入本地文件
for i in list:
req=Request(i,headers={'user-agent':user-agent}) # 获取对象
data=urlopen(req.read()) # 读取对象
with open(文件名称,‘wb’) as f:
f.write(data) # 直接写入文件,虽然没尝试,但想着如果下载游戏压缩包等大文件时大于内存可能就失败了,还需要自行处理或借助第三方库
user-agent可以自己编,也可以用自己真实的,任意网址按F12进入开发者模式后,真实的查找方式如下图:
示例Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0,其中组成为 Mozilla/5.0 (平台) 引擎版本 浏览器版本号,解读该ua为:win10的64位操作系统,AppleWebKit/537.36 (KHTML, like Gecko) 引擎版本,Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0内核浏览器。
其他模块
collections模块,在内置数据类型dict、list、set和tuple中增加新类型,
namedtuple生成可以使用名字访问元素内容的tuple
deque双端队列,可以快速从另外一侧追加和推出对象,list访问快,插入删除慢,线性存储,该方法实现双向列表,适用于队列和栈
Counter计数器,返回元素出现次数
OrderedDict有序字典,按插入顺序排列,3.5后python已经实现字典有序
defaultdict带默认值的字典
时间相关,time模块,time.time()时间戳,1970年1月1日零时至今的秒数
random随机模块,random.random(范围),范围内生成随机数,random.sample[]返回列表任意两个组合,random.choice([])列表随机读取。
os模块,与os交互的接口,os.getcwd获取当前工作目录,maedirs(' ')生成多层递归目录,remoivedirs目录为空则删除,remove()删除文件,system(" ")运行shell命令,直接显示,windows路径使用\,而linux使用/,可以使用sep输出合适的路径分隔符。
sys模块,与解释器交互的接口,platform返回os平台名称,version版本信息
异常处理
可以用if覆盖所有逻辑,但有遗漏时会出错,不执行后续代码,故标准异常处理结构为try: 代码 except 异常类型: 处理,该方式只能处理指定异常,同样可用多分支结构,也可使用万能异常Exception和as e后续输出错误信息,且不停止代码。
也可自定义异常,使用class 异常名(BaseException)定义,raise 内容手动抛出异常。
断言
assert 表达式表达式为真则继续执行,否则终止。
机制
垃圾回收机制
引用计数器为主,分代回收和标记清除为辅。
任何对象都存放在refchain的双向链表中,每个数据都有指向上下对象的指针,自身类型和引用个数,对象在创建,引用和作为参数在函数中传递时计数器加一,销毁或重新赋值时计数器减一,引用计数器为0时垃圾回收,双向链表中删除该节点,但该方式有问题,对象销毁后但计数器不为0(比如循环引用后销毁),就永远不会被回收,一直存在占用内存,也易引发内存泄漏。
由此引出标记清除法,python还维护了另一个列表,存放可能存在循环引用的双向链表,主要针对容器类型的数据存在循环引用时双方的计数器各自减一,抵消循环对计数器的影响,具体措施为借助有向图实现。
标记清除法效率低,清除非活动对象时要顺序扫描整个内存,由此产生分代回收机制。对象先在0代存储,存满700个后对对象扫描,有循环的减1,否则加入1代,0代扫描10次后再扫描1代,重复上述过程,无循环引用的存入2代,1代扫描10次后扫描一次2代对象,类似操作系统中的优先级调度,基于弱代假说,即年轻的对象死的快,年老的对象寿命长,将年老的对象降低扫描频率。
缓存机制
为了避免对象重复删除创建,python建立了缓存池机制,启动解释器时,会将常用的字符串在内存中创建好,输出不同字符的id时会发现256和257在内存的地址相差很多,而之前的数值距离较近,使用这些字符时无需创建对象,可加速运行。
python运行在交互模式和命令模式时变量的id会区别很大, 这是因为其运行的代码块不同,命令模式时函数,文件等作为代码块执行,交互模式时一行代码就是一个代码,同一代码块内有缓存机制,会复用已经存在的对象,比如数字和字符串,容器类型不适用。
垃圾回收时为了优化速度,不会立即将对象回收,而是加入free_list链表中,再创建对象时直接在链表中使用即可,默认容量为80,存满时才销毁对象。
总结
本节好像是大学中的前期课程,但其实不然,很多操作之前没用过,有返回函数内另一函数的闭包函数,该方法可以加速一些函数的执行过程,提前往其中传入参数,但最重要的是引出装饰器——不改变函数名而改变函数功能的操作,将原有函数和新操作作为闭包函数的返回值,返回给原函数名的对象进行接受,就实现了该功能,为了简化该覆盖功能使代码变得优雅,产生了装饰器。
生成器,迭代器,用于循环,推导式是写在列表或字典内的语句,此外还有只用一次的匿名函数,和自己调用自己捋不明白的递归函数。
python开发效率高我认为一在语法简洁,二就在丰富的模块,像是游戏的创意工坊,大家都上传模块让我们避免重复造轮子,正则表达式模块玩好了就能爬所有网站了。
最后是解释器对内存管理的工作流程,引用计数器为主,分代回收和标记清除,有向图找循环引用,划分优先级减少查找次数。
到这python基于函数和过程的部分就结束了,重点是闭包,装饰器,解释器内存管理。