论文地址:https://ojs.aaai.org/index.php/AAAI/article/view/20680
论文源码:无
会议:The Thirty-Sixth AAAI Conference on Artificial Intelligence

这篇论文名为《Towards a Rigorous Evaluation of Time-Series Anomaly Detection》,由Siwon Kim、Kukjin Choi、Hyun-Soo Choi、Byunghan Lee 和 Sungroh Yoon 共同撰写。这项研究主要关注时间序列异常检测(TAD)领域中现有评估方法的问题,并提出了新的评估基准和协议来改进这一领域的研究。
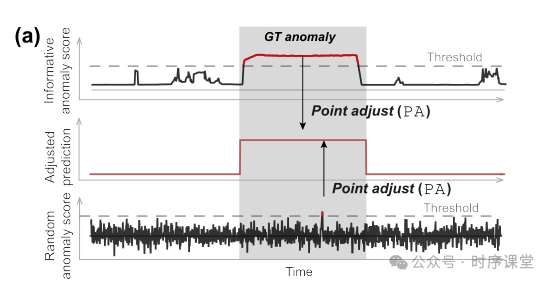
论文的核心观点是,当前时间序列异常检测的评估协议,特别是点调整(Point Adjustment, PA)方法,可能会导致对模型性能的过度估计。作者通过理论分析和实验结果表明,即使是随机生成的异常分数,在应用PA后也能被错误地视为先进的异常检测方法。这种情况下,PA协议的应用可能会误导方法的比较和评估。
进一步地,研究指出,当禁止使用PA时,未经训练的模型与现有方法在性能上可达到相似的水平,这进一步质疑了现有TAD方法的有效性。基于这些发现,作者提出了一种新的基线和评估协议,希望通过更严格的评估促进未来在时间序列异常检测研究中的改进和发展。
这篇论文对时间序列异常检测领域的研究方法提出了重要的质疑和改进建议,对该领域的研究者具有较高的参考价值。

数据集:
实验使用了几个广泛认可的时间序列异常检测基准数据集,包括SWaT、WADI、SMD、MSL和SMAP。这些数据集涵盖了从水处理系统到服务器机房以及NASA的太空探测任务的多种应用场景,具有不同的异常类型和挑战。
实验设计:
基线模型:作者提出并测试了一种新的基线,即未经训练的模型(例如单层LSTM的未训练自编码器),用于生成异常得分。
随机异常得分:实验还包括了使用从均匀分布中随机生成的异常得分来评估PA协议可能导致的性能过度估计。
评估指标:
传统F1分数:在应用和未应用PA协议的情况下分别计算F1分数。
新评估协议:实验中引入了PA%K协议,这是一个修改版的PA,只在检测到的异常在某个段落中的比例超过阈值K时才将整个段落标记为异常。这样的设置旨在减少PA可能导致的过度估计问题。
实验过程:
分别对每种方法和基线进行了测试,计算并比较了它们在不同数据集上的性能。
对比了传统PA评估和新提出的PA%K评估的结果,以展示新协议在减少评估误差方面的效果。
统计和可视化:
利用统计方法分析了各种方法的性能表现。
使用t-distributed Stochastic Neighbor Embedding (t-SNE)等工具对异常检测结果进行了可视化,以直观展示模型对异常和正常模式的区分能力。

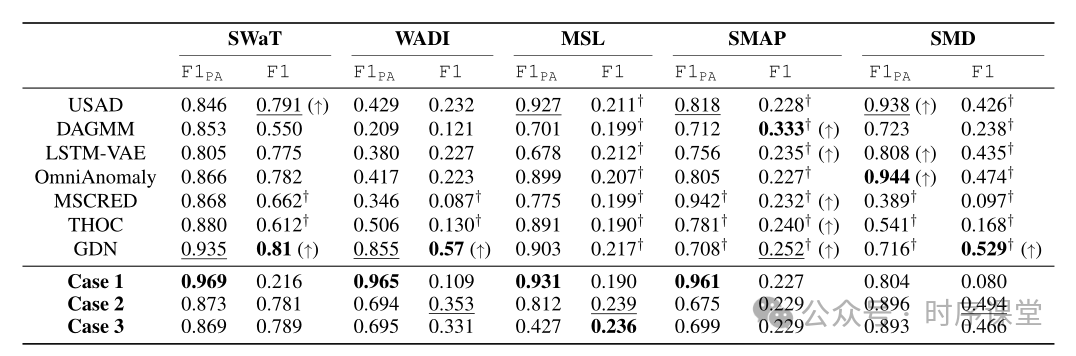

评估方法的问题:研究指出,当前时间序列异常检测中普遍使用的点调整(Point Adjustment, PA)评估协议可能会导致对模型性能的过度估计。该协议允许即使是随机生成的异常得分,在应用PA后也可能被视为高效的检测方法。
新的评估基准:论文通过实验表明,即使在禁用PA协议的情况下,一个未经训练的模型也能达到与现有方法相当的检测性能。基于这一发现,作者提出了新的评估基准,旨在更加严格地评估TAD方法的真实效能。
新的评估协议:为了克服传统评估方法的缺陷,论文提出了一个新的评估协议,旨在提供更准确和公平的性能比较方式。这一新协议考虑了模型在没有PA支持下的性能,以及与新基线的相对比较。
未来研究方向:论文最后提出了对未来时间序列异常检测研究的几点建议,包括发展更为精细的评估标准和改进现有的数据集,以更好地反映真实世界中的异常情况。









![[Linux深度学习笔记5.9]](https://img-blog.csdnimg.cn/direct/34a048ce5f8a478bb4997f2046efbe56.jpeg)