Java进阶07 集合(续)
一、数据结构(树)
1、关于树
1.1 相关概念
-
节点:树中每个单独的分支
-
节点的度:每个节点的子节点数量
-
树高:树的总层数
-
根节点:最顶层节点
-
左子节点:左下方的节点
-
右子节点:右下方的节点
-
左子树:节点左下方连接的全部节点
-
右子树:节点右下方连接的全部节点
1.2 二叉树&二叉查找树
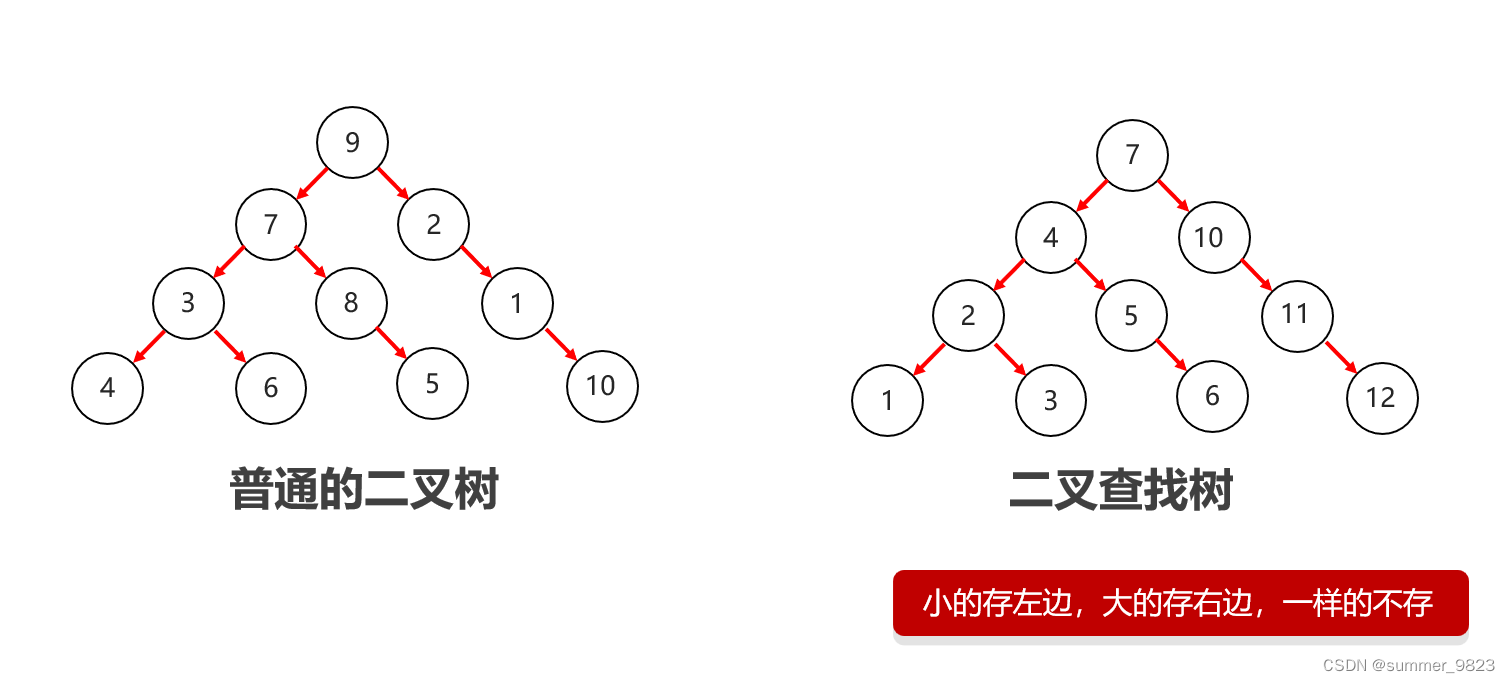
-
普通二叉树
树中任意节点的度都<=2
-
二叉查找树
又称二叉排序树、二叉搜索树。其特点是:①首先必须是二叉树;②任意节点左子树上的值均小于当前节点值;③任意节点右子树上的值都大于当前节点值;
二叉查找树的节点如果都挂在同一边,会产生瘸腿现象,那么它的查询效率就和普通的单链表一样了,为了解决这个问题,引入平衡二叉树
1.3 平衡二叉树
在是二叉查找树的前提下,任意节点的左右子树高度差不超过1,即为平衡二叉树。由于平衡二叉树的这个特点,每次往该树中加入新的节点时,就可能会对其平衡性有影响。当添加了某个节点后,改变了该树的平衡性,则会触发旋转机制来保证平衡性。
-
旋转规则
确定支点:从添加的结点开始,不断往父节点找不平衡的节点,这个点就是支点
-
左旋(右右加入造成不平衡)
case1.支点没有左子节点
把支点左旋降级,变成左子节点;晋升原来的右子节点
case2.支点有左子节点
将根节点的右侧往左拉;原先的右子节点变成新的父节点,并把多余的左子节点让出,给已经降级的根节点当右子节点
-
右旋(左左加入造成不平衡)
case1.支点没有右子节点
把支点右旋降级,变成右子节点;晋升原来的左子节点
case2.支点有右子节点
将根节点的左侧往右拉;原先的左子节点变成新的父节点,并把多余的右子节点让出,给已经降级的根节点当左子节点
-
-
需要旋转的四种情况
左左意思为根节点的左子树的左子树加入导致的不平衡,其余三种情况类似
-
左左:一次右旋
-
左右:先局部左旋,再整体右旋
-
右右:一次左旋
-
右左:先局部右旋,再整体左旋
-
2、红黑树
2.1 红黑树的概念
红黑树是一种自平衡的二叉查找树,是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色,节点颜色非黑即红。红黑树不是高度平衡的,它的平衡是通过”红黑规则“实现的。
2.2 红黑规则
①每一个节点是红色或黑色
②根节点必须是黑色
③如果一个节点没有子节点或父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
④如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个相邻的红节点)
⑤对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
助记口诀:左根右、根叶黑、不红红、黑路同
-
左根右:左子树节点值<=根节点值<=右子树节点值
-
根叶黑:根节点和叶节点(外部节点Nil)均是黑色的
-
不红红:不能出现两个相邻的红节点
-
黑路同:从某个节点出发,一条路走到黑(即走到它的后代叶节点上)经过的黑色节点数都相同
2.3 添加节点规则
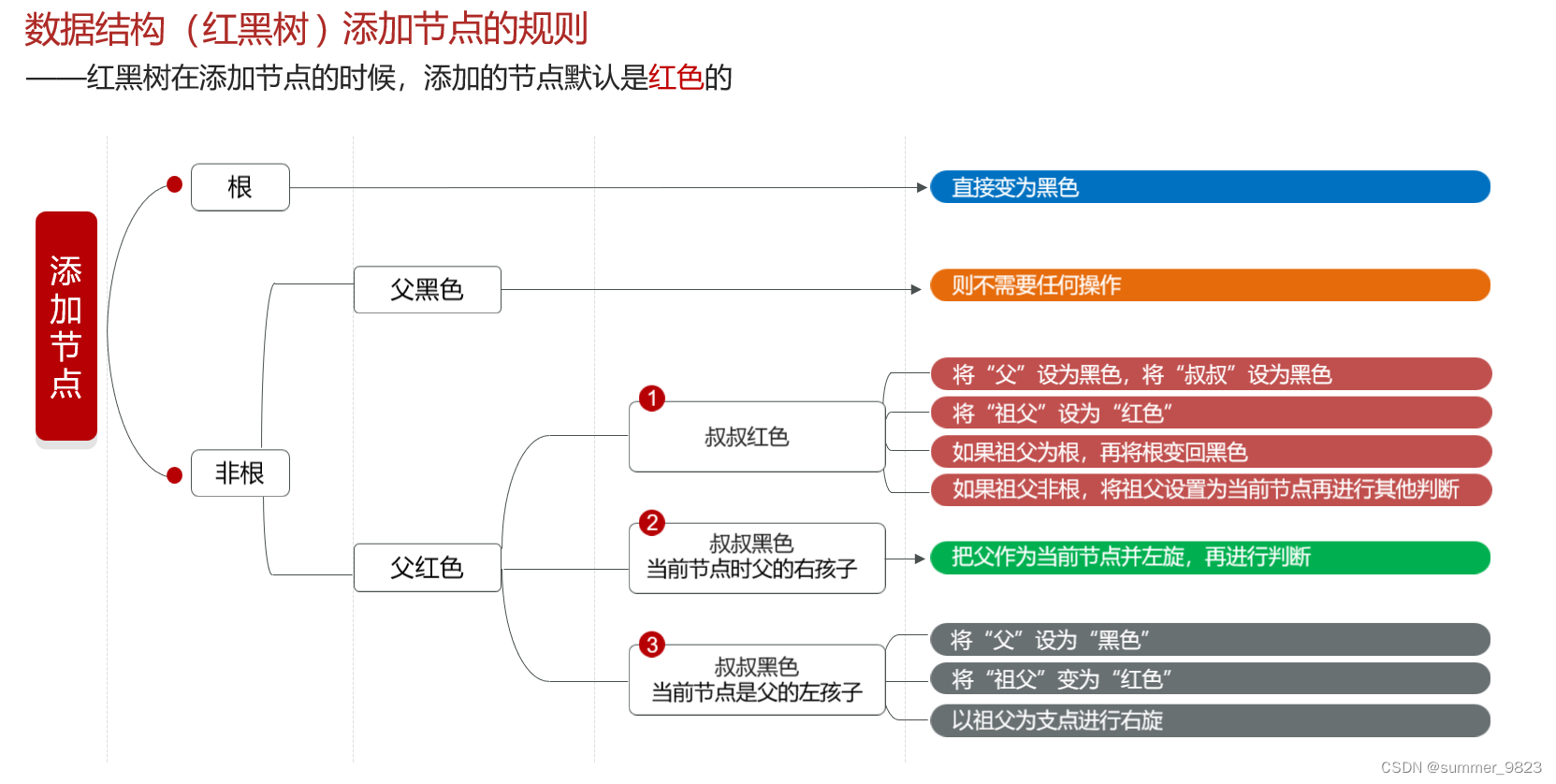
3、动画演示网站
Data Structure Visualization (usfca.edu)
二、TreeSet集合
1、作用
对集合中的元素进行排序操作(底层红黑树实现);且属于Set派系,不允许存储重复数据,可以去重
1.1 综合案例
需求:键盘录入一个字符串,对字符串中的字符去重,并排序
public class TreeSetTest1 {
public static void main(String[] args) {
System.out.println("请输入:");
String content = new Scanner(System.in).nextLine();
//1、将字符串拆分为字符数组,方便获取每一个字符
char[] chars = content.toCharArray();
//2、准备TreeSet集合用于排序和去重
TreeSet<Character> set = new TreeSet<>();
//3、遍历字符数组,并将每一个字符添加到集合
for (char c : chars) {
set.add(c);
}
//4、多次拼接且不知道拼接次数,创建StringBuilder拼接
StringBuilder sb = new StringBuilder();
//注意:Set集合遍历方式只有三种(迭代器、增强for、foreach方法)
set.forEach(c->sb.append(c));
//展示拼接后的内容
System.out.println(sb);
}
}2、排序方式
2.1 默认排序方式
-
Integer类,默认按数值大小排序
-
String类,默认按照其对应的编码表中的整数值逐个比较,均相同的会按照长度比较,短的在前
TreeSet<String> set1 = new TreeSet<>(); set1.add("aaa"); set1.add("aaaa"); set1.add("aab"); set1.add("cde"); System.out.println(set1); //排序结果为:aaa aaaa aab cde
2.2 自然排序
-
类实现Comparable接口
-
重写CompareTo方法
-
根据方法的返回值,来组织排序规则(返回负数往左,返回正数往右,返回0不存)
public class TreeSetDemo2 { public static void main(String[] args) { TreeSet<Student> set = new TreeSet<>(); set.add(new Student("张三",23)); set.add(new Student("李四",24)); set.add(new Student("王五",25)); System.out.println(set); } } //Student类要实现Comparable接口,重写compareTo方法的内部逻辑,此处年龄为主要排序依据,姓名为次要排序依据 @Override //年龄正序 public int compareTo(Student o) { int ageResult = this.age-o.age; //按年龄正序排列 倒序为o.age-this.age int nameResult = ageResult == 0 ? this.name.compareTo(o.name) : ageResult; //同名同年龄的需要保留,返回1或-1都无所谓,因为内容一样,谁前谁后不重要 return nameResult == 0 ? 1 : nameResult; }
2.3 比较器排序(覆盖自然排序)
-
在TreeSet的构造方法中,传入Compartor接口的实现类对象
-
重写compare方法
-
根据方法的返回值,来组织排序规则(返回负数往左,返回正数往右,返回0不存)
public class TreeSetDemo3 { /* 需求:对字符串进行排序,根据字符串的长度,从大到小排序 */ public static void main(String[] args) { //String类为Java写好的类,已具备自然排序,但不是我想要的排序规则,需要比较器排序 TreeSet<String> set = new TreeSet<>(new Comparator<String>() { //重写compare方法 @Override public int compare(String o1, String o2) { //按长度倒序排列 o1.xxx-o2.xxx 正序 int lengthResult = o2.length()-o1.length(); return lengthResult==0?o2.compareTo(o1):lengthResult; } }); set.add("aaa"); set.add("aa"); set.add("bbbb"); set.add("bb"); set.add("aaaa"); System.out.println(set); } }
3、排序如何选择
Java已经写好的类(如String、Integer、Double...)大多数都具有自然排序的规则(String默认按字典顺序、Integer默认升序、Double默认升序),这些规则放在源码中,我们无法修改其比较规则,如果我们要实现的排序规则跟自然排序不一样,此时需要使用比较器排序来覆盖自然排序规则。因为当同时具备自然排序和比较器排序时,会优先按照比较器进行排序操作;
4、利用TreeSet集合降序排列ArrayList
| 方法 | 说明 |
|---|---|
| static <T> void sort(T[] a,Comprtor<? super T> c) | 根据指定比较器产生的顺序对指定对象数组进行排序 |
public class ArraysDemo {
public static void main(String[] args){
//利用集合TreeSet集合方法对数组降序排列
Integer[] arr3 ={11,55,33,22,44};
Arrays.sort(arr3, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1; //o2-o1降序
}
});
System.out.println(Arrays.toString(arr3));
}
}三、HashSet集合
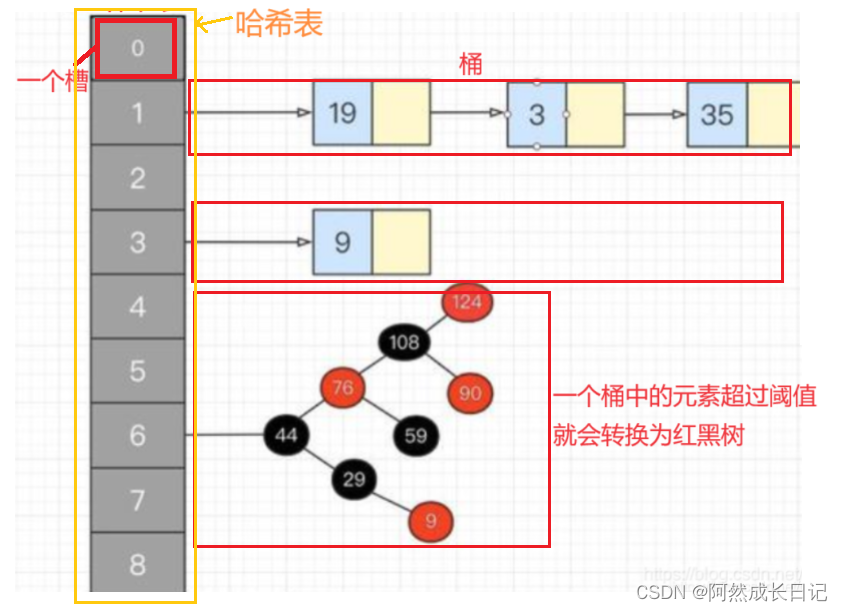
1、关于HashSet底层
集合底层采取哈希表存储数据,JDK8之前的哈希表是数组+链表;JDK8之后的哈希表是数组+链表+红黑树。哈希表是一种对于增删改查数据性能都比较好的结构。
2、配合去重
HashSet特点就是去重。为了保证元素唯一,必须同时重写HashCode和equals方法!!!
2.1 配合去重流程
往集合中添加对象→→→调用对象的HashCode方法**,计算出一个应存入的索引地址→→→查看该位置上是否已存在元素→→→不存在则直接存;存在,调用equals方法比较内容→→→内容不同,存入集合;内容相同,不存入。
2.2 HashCode方法
-
该方法底层调用了C++代码计算出一个随机数(常被人称为地址值)
-
是JDK根据某种规则算出来的int类型的整数
-
我们不必太过关注其内部实现,可以把它简单的理解为会计算出某个对象对应的整数值
-
为了避免存入的时候元素都堆积在同一个索引位置,因此hashcode方法的重写就显得格外重要
⭐重写改造原则(降低索引冲突)⭐
将对象的所有属性值都带入运算
-
对象的属性相同,返回哈希值一定相同
-
对象的属性不同,返回哈希值尽量不同
-




![[华为OD]C卷 BFS 亲子游戏 200](https://img-blog.csdnimg.cn/direct/d9a99602098143ac9abae9d622b49866.png)