💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤
📃个人主页 :阿然成长日记 👈点击可跳转
📆 个人专栏: 🔹数据结构与算法🔹C语言进阶🔹C++🔹Liunx
🚩 不能则学,不知则问,耻于问人,决无长进
🍭 🍯 🍎 🍏 🍊 🍋 🍒 🍇 🍉 🍓 🍑 🍈 🍌 🍐 🍍
文章目录
- 前言:
- 一、红黑树快速入门:
- 二、set系列:
- 1、什么是`set`
- (1)头文件
- (2)set的定义
- (3)set 的方法汇总
- (4)set总结
- (5)问题1:set中的元素不允许修改?
- 2、什么是`multiset`
- 三、 unordered_set系列
- 1、unordered_set是什么?
- (1)为什么要使用哈希表来作为底层存储逻辑?
- (2)std::unordered_set 相对于 std::set 具有几个优势:
- 2.unordered_multiset是什么?
- 四、map和unordered_map一起讲
- 1、map
- (1)头文件
- (2)什么是map?
- (3)特点:
- (4)接口使用
- (5)总结
- 2.mutlimap,unordered_map和unordered_multimap
- 五、逻辑图
前言:
本篇博客是对C++中的map和set做一个小小的总结,主要是学习之后的知识点,并会不会细节展开太多。后续会慢慢发布更多底层实现模拟等等更深入了解。
一、红黑树快速入门:
红黑树是一种自平衡的二叉搜索树,具有以下特性:
每个节点要么是红色,要么是黑色。 根节点是黑色的。 每个叶子节点(NIL 节点)是黑色的。
如果一个节点是红色的,则它的两个子节点都是黑色的。 对于每个节点,从该节点到其所有后代叶子节点的简单路径上,黑色节点的数目相同。
红黑树的自平衡性质保证了在插入或删除节点时,树的高度不会过高,从而保持了插入、删除和查找操作的时间复杂度为 O(log n)。当你向 std::set
插入元素时,底层红黑树会根据元素的自然顺序进行插入,并保持树的平衡。当你执行查找操作时,红黑树会按照二叉搜索树的方式进行搜索,以快速定位目标元素。
二、set系列:
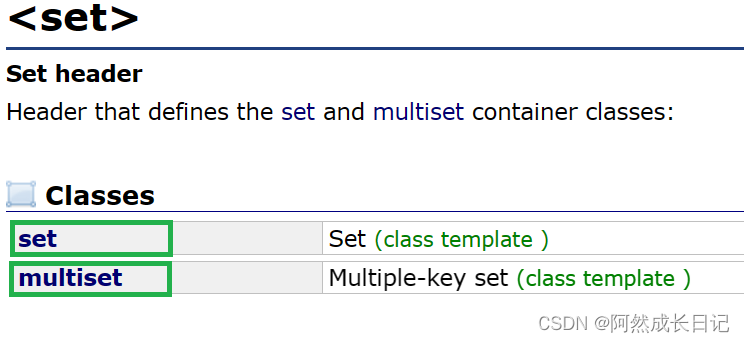
1、什么是set
(1)头文件
#include <set>
C++ 中的 std::set 是一个关联容器,它提供了一种存储唯一元素的方式,并按照元素的自然顺序进行排序。std::set 的底层通常使用红黑树(Red-Black Tree),以实现高效的插入、删除和查找操作,并确保元素的唯一性和有序性。
(2)set的定义
set<类型名> 变量名;
- 其中,类型名可以是 int、double、char、struct,也可以是 STL 容器:vector、set、queue。
(3)set 的方法汇总


这些方法也没什么可说的,之前string中基本都讲过,不知道怎么用的时候就去C++网站搜一下。
(4)set总结
- 1.set中只放
value,而map必须存放完整的<key,vlaue>,但set在底层实际存放的还是由<value, value>构成的键值对。只不过两者相同。 - 2.set中的元素
不可以重复(因此可以使用set进行去重)。 - 3.
有序存放,使用set的迭代器遍历set中的元素,可以得到有序序列 - 4.set中的元素默认按照小于来比较,这就导致一般都是
从小到大排序。 - 5.set中查找某个元素,时间复杂度为
O(log n),因为底层使用红黑树的缘故。 - 6.set中的元素
不允许修改(下面会讲解为什么?) - 7.set中的底层使用二叉搜索树(
红黑树)来实现。
(5)问题1:set中的元素不允许修改?
在 C++ 中,std::set 是一个关联容器,其中的元素是唯一的且按照一定顺序排列的。一旦将元素插入到 std::set 中,就不能直接修改这些元素。这是因为 std::set 使用红黑树等底层数据结构来维护元素的顺序和唯一性,直接修改元素可能会破坏这些结构。
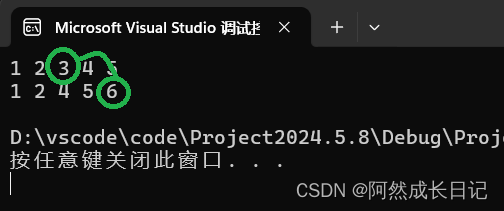
如果你想要修改 std::set 中的元素,通常的做法是先将要修改的元素从集合中移除,然后再插入修改后的值。这样可以保持 std::set 的有序性和唯一性。下面是一个简单的示例:【修改元素 3 为 6】
解决方法:先删除,再插入
在这个示例中,我们首先从集合中移除值为 3 的元素,然后再插入值为 6 的元素,以实现修改操作。
#include <iostream>
#include <set>
int main() {
std::set<int> mySet = {1, 2, 3, 4, 5};
// 修改元素 3 为 6
mySet.erase(3);
mySet.insert(6);
// 输出集合中的元素
for (const auto& elem : mySet) {
std::cout << elem << " ";
}
std::cout << std::endl;
return 0;
}
2、什么是multiset
multiset:多重集。
std::multiset 是 C++ 标准库中的另一个关联容器,与 std::set 类似,但允许存储重复的元素。它也是一个有序容器,底层通常使用红黑树来实现。
与set的区别:
- std::multiset 中的元素可以重复。这意味着在 std::multiset 中,相同的值可以出现多次,并且它们都会被保存下来。std::multiset 会保持元素的插入顺序,并且允许使用相同值插入多次,因此它不保证元素的唯一性,但仍然维护元素的有序性。
简单来说就是,multiset和set几乎一摸一样,只不过它可以重复存储相同。std::multiset 提供了与 std::set 相似的接口和功能,包括插入、删除、查找等操作。它是一个非常有用的容器,特别适用于需要存储重复元素并保持它们的顺序的情况。
#include <iostream>
#include <set>
int main() {
std::multiset<int> myMultiset;
// 插入元素
myMultiset.insert(10);
myMultiset.insert(20);
myMultiset.insert(30);
myMultiset.insert(20); // 允许重复元素
// 输出多重集合中的元素
for (const auto& elem : myMultiset) {
std::cout << elem << " ";
}
std::cout << std::endl;
return 0;
}
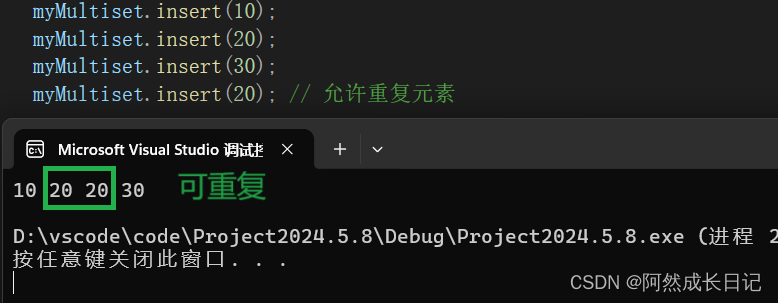
在这个示例中,我们创建了一个 std::multiset,并插入了几个元素,其中一个元素是重复的。最后,我们遍历并输出了多重集合中的元素,注意到重复元素被保留了下来。
三、 unordered_set系列
头文件
<unordered_set>
1、unordered_set是什么?
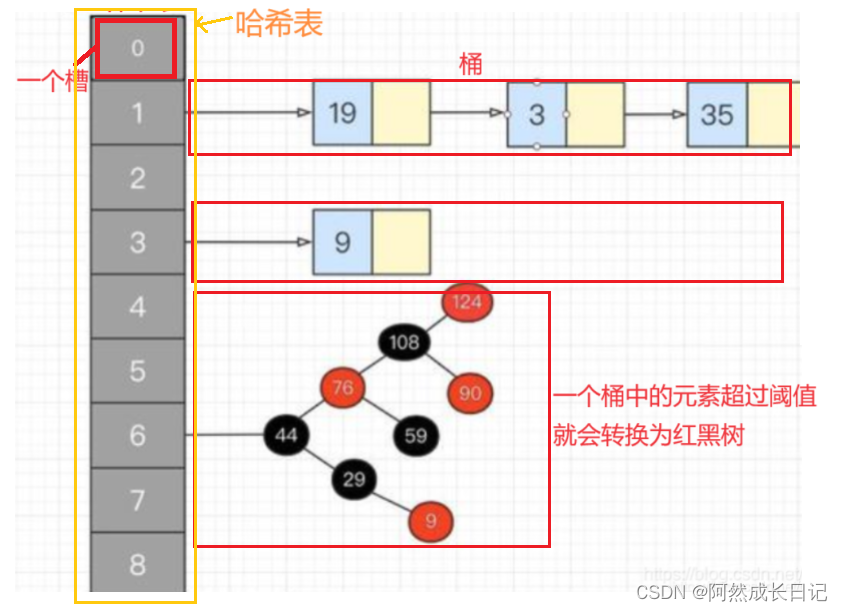
基本概念与set差不多,std::unordered_set 是 C++ 标准库中的一种关联容器,用于存储唯一的元素,其特点是不按照元素的插入顺序进行排序。相比于std::set 和 std::multiset 使用的红黑树等有序数据结构,std::unordered_set 使用哈希表作为底层数据结构。而它的优势就是插入、删除和查找元素的操作非常快速
哈希表的核心思想是将元素的键通过哈希函数映射到哈希表的一个位置上,这个位置称为槽(bucket)。当需要查找元素时,哈希表会使用相同的哈希函数计算键的哈希值,并根据哈希值找到对应的槽,然后在该槽中进行搜索。
(1)为什么要使用哈希表来作为底层存储逻辑?
使用哈希表作为底层存储逻辑有几个重要的优势:
快速的插入、删除和查找操作: 哈希表具有常数时间复杂度(O(1))的特性,这意味着在平均情况下,插入、删除和查找元素的操作非常快速。相比于使用基于比较的有序数据结构(如红黑树),哈希表可以提供更高效的操作性能。
适用于大型数据集合: 哈希表的效率与数据集合的大小基本无关,即使数据集合非常大,哈希表仍然可以保持较快的操作速度。这使得哈希表非常适合处理大规模的数据集合,如数据库索引、缓存系统等。
无序存储特性: 哈希表中的元素存储是无序的,与元素的插入顺序无关。在一些应用场景中,不要求元素有序可以降低数据结构维护的开销,并且可以更自由地处理数据。
灵活性: 哈希表可以通过哈希函数将键映射到哈希表的槽(bucket),这使得哈希表具有很高的灵活性。可以根据元素的特性设计不同的哈希函数,以适应不同类型的数据和应用场景。
(2)std::unordered_set 相对于 std::set 具有几个优势:
-
1.插入、删除、查找操作的平均时间复杂度更低: std::unordered_set 使用哈希表作为底层数据结构,这意味着在平均情况下,插入、删除和查找操作的时间复杂度为 O(1),即常数时间复杂度。而 std::set 使用红黑树作为底层数据结构,这些操作的时间复杂度为 O(log n),其中 n 是集合中的元素个数。因此,对于大型数据集合,std::unordered_set 的性能可能更好。
-
2.无序存储: std::unordered_set 中的元素存储是无序的,与元素的插入顺序无关。这对于不要求元素有序的应用场景来说是一个优势,同时也可以降低数据结构维护的开销。
-
3.自定义哈希函数: 使用 std::unordered_set 可以自定义哈希函数,以适应特定类型的元素。这使得 std::unordered_set 更加灵活,可以处理自定义类型或者用户自定义的类型。
-
4/适用于大型数据集合: 由于 std::unordered_set 的插入、删除和查找操作的时间复杂度较低,并且不会维护元素的顺序,因此它特别适用于处理大型数据集合,例如需要高效搜索和过滤大量数据的情况。
总的来说,std::unordered_set 在时间复杂度和存储特性上具有一些优势,尤其适用于不需要有序存储且需要快速插入、删除和查找操作的场景。而 std::set 则更适合需要有序存储且插入、删除操作不频繁的情况。
2.unordered_multiset是什么?
同理,multiset就是可以存储重复的值而已。底层还是和unodered_set都是使用哈希。
四、map和unordered_map一起讲
1、map
(1)头文件
#include<map>
(2)什么是map?
C++ 标准库中的 std::map 是一个关联容器,它提供了一种键值对的映射。std::map 的底层实现通常基于红黑树(Red-Black Tree),这是一种自平衡的二叉搜索树。
- 这里补充一下,除了红黑树,有些实现也可能使用其他数据结构来实现 std::map。例如,某些小型容器可能直接使用平衡二叉搜索树,而不是完整的红黑树实现。然而,无论底层数据结构是什么,std::map 都提供了类似的接口和保证的性能。
(3)特点:
-
map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。<key,value>
-
在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的
内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型 -
value_type绑定在一起,为其取别名称为pair: typedef pair<const key, T> value_type;
-
在内部,map中的元素总是按照
键值key进行比较排序的。 -
map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个
有序的序列)。 -
map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
-
map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
(4)接口使用
1.插入键值对: 使用 insert() 或 emplace() 方法插入键值对。
myMap.insert(std::make_pair(key, value));
// 或者
myMap.emplace(key, value);
2.访问元素: 使用键来访问 std::map 中的值。
意思就是通过map[key] 返回的是对应的vlaue
ValueType value = myMap[key];
3.遍历 std::map: 使用迭代器或范围-based for 循环遍历 std::map 中的键值对
for (auto it = myMap.begin(); it != myMap.end(); ++it) {
KeyType key = it->first;
ValueType value = it->second;
// 进行操作
}
// 或者使用范围-based for 循环
for (const auto& pair : myMap) {
KeyType key = pair.first;
ValueType value = pair.second;
// 进行操作
}
4.查找元素: 使用 find() 方法查找特定的键。
auto it = myMap.find(key);
if (it != myMap.end()) {
// 找到了
ValueType value = it->second;
} else {
// 未找到
}
5.删除元素: 使用 erase() 方法删除特定的键或范围内的元素。
myMap.erase(key); // 删除特定的键值对
// 或者
auto it = myMap.find(key);
if (it != myMap.end()) {
myMap.erase(it); // 删除迭代器指向的元素
}
(5)总结
1.map中的的元素是键值对<key,value>
2. map中的key是唯一的,并且不能修改,这也意味着key 相同就插入不进去。
3. 默认按照小于的方式对key进行比较,也就是升序
4. map中的元素如果用迭代器去遍历,可以得到一个有序的序列
5. map的底层为平衡搜索树(红黑树),查找效率比较高
O
(
l
o
g
2
N
)
O(log_2 N)
O(log2N)
6. 支持[]操作符,operator[]中实际进行插入查找。
2.mutlimap,unordered_map和unordered_multimap
与上面set同理。
五、逻辑图
一般喜欢使用的都是哈希set和map其实都是比较常用哈希的方式来存储,而且加入了红黑树进行调优。



![[华为OD]C卷 BFS 亲子游戏 200](https://img-blog.csdnimg.cn/direct/d9a99602098143ac9abae9d622b49866.png)