前馈全连接神经网络
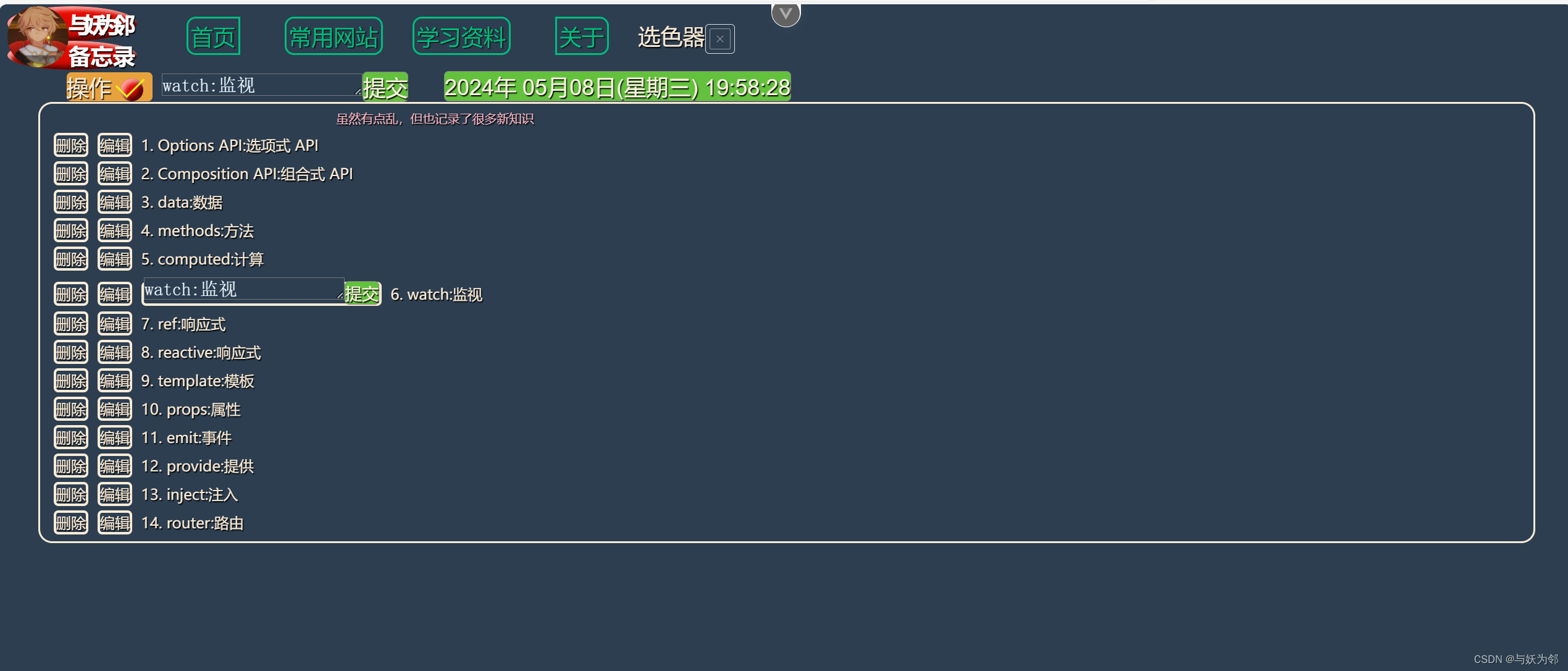
- 1.导入需要的工具包
- 2.数据导入与数据观察
- (1)读取csv的文件信息:
- (2)训练数据前5行
- (3)打印第一个图
- (4)观察数据中的信息
- (5)查看维度
- 3.数据预处理
- (1)分离标签
- (2)归一化
- (3)分样本
- 4.前馈全连接神经网络(Sequential模型)
- (1)导入需要的包
- (2)定义全连接神经网络模型
- 知识点;
- (3)权重和偏执
- (4)打印模型的摘要信息
- (5)编译网络
- (6)训练网络
- (7)二维数据表格
- (8)绘图
- (9)查看准确率
1.导入需要的工具包
1.numpy是科学计算基础包,主要应用于python中的元素级计算和执行数学运算;
2.pandas能方便处理结构化数据和函数;
3.matplotlib主要用于绘制图表。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
2.数据导入与数据观察
如果需要csv文件请在资源中查找,名字是前馈全连接神经网络csv文件。
(1)读取csv的文件信息:
mport pandas as pd
train_Data = pd.read_csv('mnist_train.csv',header = None)
test_Data = pd.read_csv('mnist_test.csv',header = None)
print('Train data:')
train_Data.info()
print('\nTeat data:')
test_Data.info()
运行结果:

可以发现训练数据中包含60000个数据样本,维度785,包括标签信息与784个特征维度;测试数据中包含10000个样本,维度785,包括标签信息与784个特征维度。
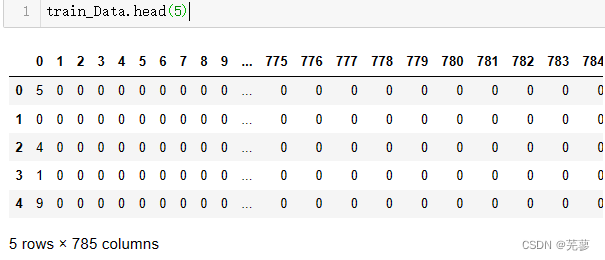
(2)训练数据前5行
train_Data.head(5)
运行结果:
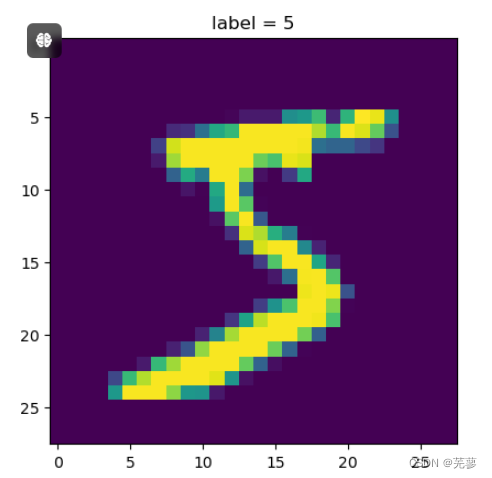
(3)打印第一个图
x = train_Data.iloc[0] # 取第一行数据
y = x[0] #标签信息
img = x[1:].values.reshape(28,28) #将1*784转换成28*28
plt.imshow(img) #画图
plt.title('label = '+ str(y))
plt.show()
运行结果:
(4)观察数据中的信息
#从sklearn中导入数据
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, parser='auto')
#观察数据
mnist.keys()

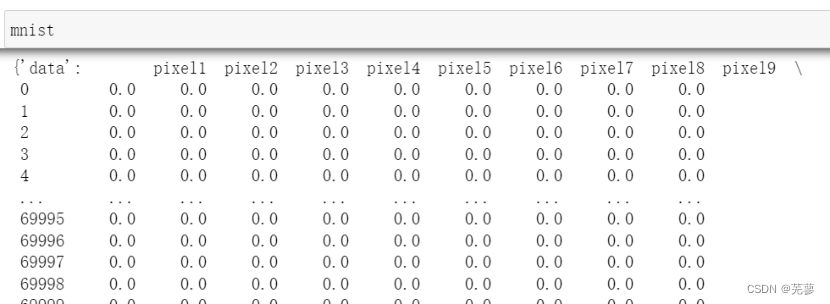
可以发现从sklearn中导入的数据包括所有训练与测试样本信息,共计70000个,对应的数据信息是mnist[‘data’],数据维度是70000$$784;标签信息是mnist[‘target’],对应维度是784
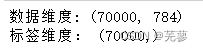
(5)查看维度
data,label = mnist["data"],mnist["target"]
print('数据维度:',data.shape)
print('标签维度:',label.shape)
3.数据预处理
(1)分离标签
将train_Data样本中数据与标签分开,其中X对应样本数据,y对应样本标签
X = train_Data.iloc[:,1:].values
y = train_Data.iloc[:,0].values
print('数据X中最大值:', X.max())
print('数据X中最小值:', X.min())

此时数据X,y都是array格式,观察数据X中的数值,发现最大值是255,最小值是0,可以考虑对X进行归一化
(2)归一化
#归一化
X=X/255
#此时将数值大小缩小在[0,1]范围内,重新观察数据中的最大,最小值
print(‘数据X中最大值:’,X.max())
print(‘数据X中最小值:’,X.min())

(3)分样本
将所有训练样本分为55000个样本的训练集(X_train, y_train)与5000个样本的验证集(X_valid, y_valid)
X_valid,X_train = X[:5000],X[5000:]
y_valid,y_train = y[:5000],y[5000:]
X_test,y_test = test_Data.iloc[:,1:].values/255,test_Data.iloc[:,0].values
4.前馈全连接神经网络(Sequential模型)
(1)导入需要的包
tensorflow:这是Google开发的一个开源机器学习库,它支持从简单的线性回归到复杂的神经网络的多种机器学习模型。
keras:这是TensorFlow的一个高级API,它提供了一个更简单、更直观的接口来构建和训练复杂的神经网络。
import tensorflow as tf
from tensorflow import keras
(2)定义全连接神经网络模型
#使用了Keras的Sequential API来定义一个简单的全连接神经网络模型。Sequential模型是一个线性堆叠的模型
model = keras.models.Sequential([
# 第一个层:Flatten层,它将输入数据的形状从二维转换为一维。
# 参数input_shape=[784]指定了输入数据的形状,对于MNIST数据集,这通常是(28, 28),
# 但由于MNIST图像数据在加载时被扁平化为一个一维数组,所以输入形状是(784,)。
keras.layers.Flatten(input_shape=[784]),
# 第二个层:Dense层,它是一个全连接层,每个神经元都与其他所有神经元相连。
# 参数300指定了该层有300个神经元。
# 参数activation='relu'指定了每个神经元的激活函数是ReLU。
keras.layers.Dense(300,activation='relu'),
# 第三个层:Dense层,同样是一个全连接层,但这个层有100个神经元。
keras.layers.Dense(100,activation='relu'),
# 第四个层:Dense层,这是一个输出层,有10个神经元。
# 参数activation='softmax'指定了输出层的激活函数是softmax,
# 这是一个用于多类别分类的函数,它会将每个神经元的输出压缩到0到1之间,并且所有神经元的输出之和为1
keras.layers.Dense(10,activation='softmax')
])
知识点;
这个层是一个全连接层(Dense层),它具有以下属性:
Layer:这是一个Keras层,它表示神经网络的一个基本构建块。
name:这是层的名称,它可以帮助您在模型中唯一地标识这个层。在您提供的代码中,这个层的名称可能是自动生成的,例如dense_1。
output:这是层的输出张量,它是通过前一个层的输出(或者输入层的输入)计算得出的。在这个全连接层中,输出张量的大小取决于层的神经元数量。
input:这是层的输入张量,它是下一个层的输入。对于全连接层,输入张量的大小取决于前一个层的输出大小。
config:这是一个字典,它包含了层的配置信息,例如神经元数量、激活函数等。
weights:这是一个列表,包含了层的权重张量。对于全连接层,权重张量是一个矩阵,它将输入数据映射到输出数据。
trainable:这是一个布尔值,表示层的权重是否可以被训练。在训练模型时,您需要将所有层的trainable属性设置为True。
(3)权重和偏执
model.layers[1]:这行代码首先访问模型中的第二个层。在Keras中,模型是由多个层组成的,每个层都是模型的一个部分,负责处理输入数据并将其传递到下一个层。
model.layers[1].get_weights():这行代码调用第二个层的get_weights()方法。这个方法返回一个列表,其中包含两个张量:第一个张量是权重(weights),第二个张量是偏置(biases)。
权重张量的大小取决于层的配置,例如神经元数量和输入数据的形状。
偏置张量的大小与权重张量相同,但形状不同。
weights_1, bias_1 = …:这行代码将返回的权重和偏置张量分配给变量weights_1和bias_1。这样,您就可以直接访问和操作这些权重和偏置张量了。
#模型的第二个层
model.layers[1]
#get_weights()函数用于获取层的权重和偏置
weights_1,bias_1 = model.layers[1].get_weights()
print(weights_1.shape)
print(bias_1.shape)

(4)打印模型的摘要信息
下是model.summary()函数的一些主要信息:
层数:模型包含的层数。
输入形状:模型输入层的形状。
输出形状:模型输出层的形状。
层类型:模型中每个层的类型(例如,全连接层、卷积层、批量归一化层等)。
层参数数量:每个层包含的参数数量。参数数量通常是层的大小乘以输入形状的大小。
总参数数量:模型中所有层的参数数量之和。
计算图:模型的计算图,这是一个图表示模型中的层如何相互连接。
#用于打印模型的摘要信息
model.summary()
运行结果:

(5)编译网络
model.compile():用于指定模型的损失函数、优化器和评估指标
loss='sparse_categorical_crossentropy':模型的损失函数为
optimizer=‘sgd’:这行代码指定模型的优化器为sgd
metrics=[‘accuracy’]:这行代码指定模型的评估指标为accuracy
model.compile(loss='sparse_categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
(6)训练网络
model.fit()是一个函数,用于使用训练数据来训练模型
X_train:训练数据的输入特征,
y_train:训练数据的标签
batch_size=32:每次梯度下降更新时使用的样本数量
epochs=30:训练过程将运行的完整周期数。
validation_data=(X_valid, y_valid):验证数据的输入特征和标签。
h = model.fit(X_train,y_train,batch_size=32,epochs=10,validation_data=(X_valid,y_valid))

(7)二维数据表格
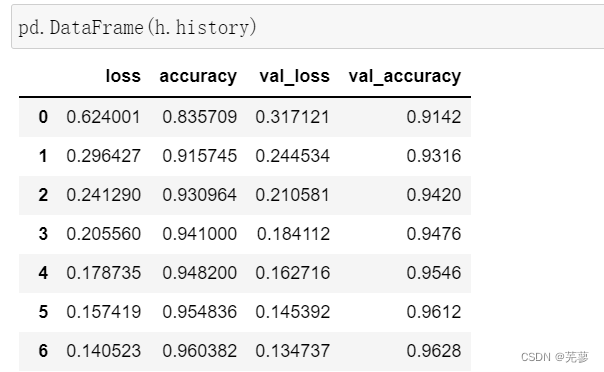
随着迭代次数的增加,损失函数的数值loss越来越小,而在验证集上的准确率accuracy越来越高,这些信息都保存在h.history中。
pd.DataFrame(h.history)
(8)绘图
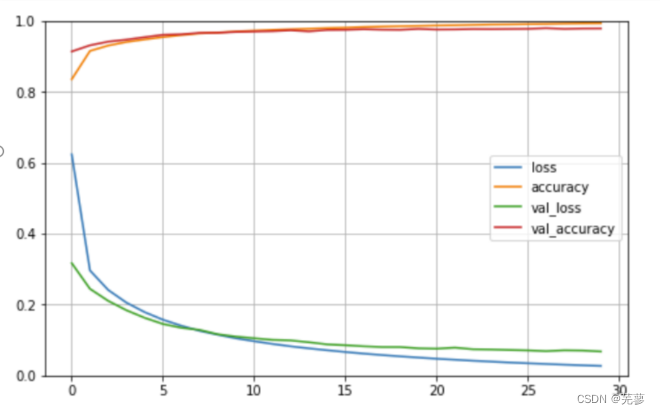
首先将h.history字典转换为一个Pandas DataFrame。
h.history通常包含在训练过程中收集的损失(loss)和准确度(accuracy)等指标,它们是训练周期的迭代结果。
figsize=(8,5)指定了图表的尺寸,其中8表示宽度,5表示高度。
pd.DataFrame(h.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,3)
plt.show()
(9)查看准确率
model.evaluate()是一个函数,用于评估模型的性能
X_test:这是测试数据的输入特征
y_test:这是测试数据的标签
batch_size=1:这行代码指定评估过程中每次评估的样本数量。
model.evaluate(X_test,y_test,batch_size=1)
运行结果: