文章目录
- 前言
- Nodejs的事件驱动机制
- EventLoop vs NSRunLoop
- NSRunLoop
- ios next runloop
- 异步/事件循坏机制的那些坑
- 批量迁移数据
- 原子性
- 参考文献
前言
这篇文章还是从一个在写Node.js程序中遇到的问题说起。本周在做数据库迁移的时候,写了下面一段代码,目的是遍历从sqlite读出的数据,再插入mongodb,简化后如下:
for (var i=0; i<7; i++) {
connectDB(function (db) {
var collection = db.collection(mockItemCol);
print(i);
// insert itemList[i]
collection.insert(itemList[i], function(err) {
});
})
}
又被Node.js的异步特性坑了,以为print(i)会打印为0, 1, 2, 3, 4, 5, 6 么,其实是7, 7, 7, 7, 7, 7, 7;
Nodejs的事件驱动机制
Node.js正是使用了异步的I/O机制,所以使得面对高并发的请求到来时能够有很好的性能。只有一个线程的Node利用了事件循环机制来处理外部事件,并把他们转化为异步的回调,这些外部事件包括了Timer到达后的触发调用,socket数据到来,文件读写等等。
EventLoop vs NSRunLoop
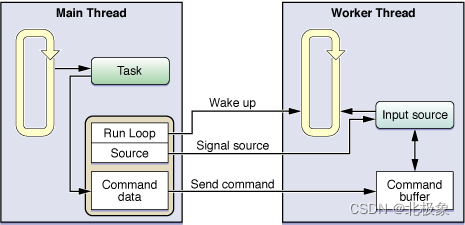
下面这张图解释Node.js使用的Event Loop运行机制:
在用户线程,也就是我们说的单线程Node.js提供的那个唯一线程,运行了一个Loop;
这个Loop负责不断循环并接受用户Application的request加入EventQueue;
当Loop的每一个Tick到来时,取出event并执行,这里的event可能是一个I/O事件,也可能是一个timer event;
这些Event会调用 Posix worker threads来做相应的I/O操作;
Event执行完成后,会把callback也包装成一个event放入queue,等待下一个tick到来调用这个event异步通知用户程序;
通过上图的分析,Node.js 的 Event Loop机制通过libuv来完成的,我们说的单线程Node.js是指用户Application是单线程,但是在Loop处理event的时候,libuv还是会调用多个Posix worker threads来工作,这已经是Internal C/C++ thread pool的事情了,不要和用户侧搞混了。
所以在libuv中,其实还是多线程环境的,大概YY下libuv对于EventLoop的实现:
用户侧的request到来或者WorkerThreads完成操作,都会产生新的event:
lock (queue) {
queue..push(event);
}
EventLoop的循环:
while (true) {
// tick到来
lock(queue) {
// 取出event queue中所有事件;
tickEvents = queue.allEvents;
// 清空event queue
queue.popAll();
}
for (event in tickEvents) {
event.invoke();
}
// tick 结束
}
每一个tick到来时候都会执行queue中的所有事件,而不是只执行一个,这个event有用户的request和Posix thread的回调方法,包括:
- Timer Event
- process.nextTick
- I/O event
- libuv调用的C++ thread方法回调等;
NSRunLoop
作为一个ios码农,写到这里必须是要对比一下NSRunloop,ios/Mac开发中的事件循环Loop。NSRunLoop的定义几乎和Node.js的EventLoop一模一样,不同的是ios程序不是单一线程的,主线程是默认启动NSRunLoop的,而用户创建的子线程可以手动启动NSRunLoop来做事件监听;
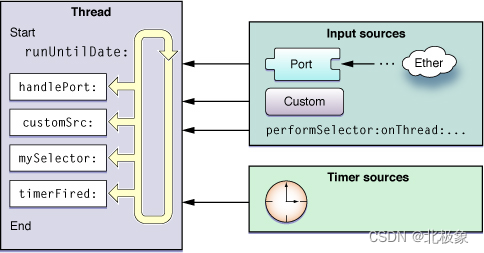
可以看到,NSRunLoop处理的source大体上分为两种,一种是input source 还有一种是time source。而且对于自己启动的NSRunLoop来说,这些事件源是需要自己手动加入的,并且NSRunLoop不是自动run起来的,如果需要一个线程的runloop一直循环监听事件,是需要手动调用run方法,具体的使用方法可以参考苹果官方文档。
while(running){
[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDate distantFuture]];
}
process.nextTick()
在介绍Node.js的Event Loop时提到tick的概念,EventLoop是以tick为单位来做事件的批处理,当用户提交一个I/O异步操作时,event loop就把这个事件加入queue,并等待下一个tick到来时处理。那么如果想要主动把一个方法放在下一tick使用,可以通过调用 process.nextTick()来实现。
举几个例子说明要用到process.nextTick()的场景:
- 保证事件的时序正确
var EventEmitter = require('events').EventEmitter;
function StreamLibrary(resourceName) {
this.emit('start');
// read from the file, and for every chunk read, do:
this.emit('data', chunkRead);
}
var stream = new StreamLibrary('fooResource');
stream.on('start', function() {
console.log('Reading has started');
});
stream.on('data', function(chunk) {
console.log('Received: ' + chunk);
});
上面这段代码中,console.log(‘Reading has started’); 将不会执行,因为在stream构造的时候就已经发出start事件了,而此时回调函数还没有注册。使用process.nextTick()来改写事件触发的过程:
function StreamLibrary(resourceName) {
var self = this;
process.nextTick(function() {
self.emit('start');
});
// read from the file, and for every chunk read, do:
this.emit('data', chunkRead);
}
- 交错执行CPU密集的代码段
因为Node是单线程的,所以CPU一旦陷入密集的计算中,所有的事件都不能得到处理,可以通过把密集的计算代码使用process.nextTick()来做交错的执行,代码如下:
function compute() {
// performs complicated calculations continuously
// ...
process.nextTick(compute);
}
这样在compute的分段计算之间就可以处理其他的事件,而不至于让compute独占CPU。
- 保持函数异步回调的原则
因为Node.js的异步编程特性,所以在设计回调函数时候要遵守异步调用的原则。
function asyncCall(data, callback) {
callback();
var counter = 0;
return counter;
}
var a = asyncCall("data", function() {
a++;
print(a);
});
为了说明这个例子,写了上面这段代码,稍微有点奇怪凑活看吧。因为callback是同步调用的,所以在执行callback时候变量 a 是undefined的。为了遵守异步编程,应该设计成这样的:
function asyncCall(data, callback) {
process.nextTick(function() {
callback();
});
var counter = 0;
return counter;
}
ios next runloop
在开发ios程序时候我们经常会看到类似这样的代码:
...
[self performSelector:@selector(actuallySavePhoto:) withObject:photo afterDelay:0];
...
这样写的目的和process.nextTick()是异曲同工的,就是放到下一个runloop去执行,通常是在主线程上使用,保证UI处理延续性,而把这个actuallySavePhoto放到下一个runloop再处理。
苹果的文档中也有相关的描述:
Specifying a delay of 0 does not necessarily cause the selector to be
performed immediately. The selector is still queued on the thread’s run loop and performed as soon as possible.
另外关于ios中如何进行next runloop的讨论还可以参考这篇:Perform on Next Run Loop: What’s Wrong With GCD?
异步/事件循坏机制的那些坑
批量迁移数据
开头为提到的那个问题,之所以没有如我所想顺序打印0到6,原因还是在于我还是没有理解Node的处处都是异步调用,因为connectDB的callback参数是被异步回调,所以这7次callback很可能都是在下一个tick中被同时调用的,而在当前tick中i已经完成了从0到6的7次循环++了,等到下一个tick时i的值已经是7了。所以最终的打印结果是7, 7, 7, 7, 7, 7, 7。
for (var i=0; i<7; i++) {
connectDB(function (db) {
var collection = db.collection(mockItemCol);
print(i);
// insert itemList[i]
collection.insert(itemList[i], function(err) {
});
})
}
对这个程序做改进有两种方法,思路都是使用第三方的库来帮忙:
- 使用Async提供的each调用:
var arr = [1, 2, 3, 4, 5, 6, 7];
async.each(arr, function(item, callback) {
connectDB(function (db) {
var collection = db.collection(mockItemCol);
print(item);
});
}, function(err, results) {
});
- 使用上一篇提到的Fiber:
Fiber(function(){
var fiber = Fiber.current;
for (var i=0; i<7; i++) {
connectDB(function (db) {
print(i);
fiber.run();
});
Fiber.yield();
}
}).run();
原子性
在做数据DAO的时候,有这样的一个需求,我简化一点描述下:MockCaseCollection中存放的是MockItem,MockItem有OwnerName,OperationType,mockData以及enable字段,对于同样OperationType的多条记录,只能有一条是enable的。所以在做insert数据,或者update时,如果被操作的item是enable的,那么首先需要把表中其他相同ownerName和operationType的items的enable都置为false。这个DAO的add方法我是这么写的:
addMockItem: function (item, callback) {
var self = this;
connectDB(function (db) {
var collection = db.collection(mockItemCol);
if (item.enable) {
// 首先 update enable 的为 disable
collection.update(
{ownerName:item.ownerName, operationType:item.operationType, enable:true},
{$set: {enable:false}},
{multi:true}, function (err, result) {
if (err) {
callback(err);
return;
} else {
// insert here
collection.insert(item, function (err, result) {
callback(err);
});
}
}
)
}
})
}
这个add的dao方法其实执行两条数据库操作,暂且分别定义为updateDisable和insertEnable;那么如果用户连续滴啊用了addMockItem两次;
addMockItemA {
updateDisableA;
insertEnableA;
}
addMockItemB {
updateDisableB;
insertEnableB;
}
因为updateDisable和insertEnable都是异步调用,所以我们并不知道他们是在哪一个tick上被执行的,上述的调用流程很可能是这样的:
updateDisableA;
updateDisableB;
updateDisableA;
updateDisableB;
那么问题来了,因为执行顺序的问题,现在数据表中应该有两条数据都是enable的了,显然addMockItem的原子性被破坏了,而根本原因正是异步编程导致的乱序执行。
可能有的小伙伴们会说,这个原子性应该使用数据库的transaction来做啊,然而我们使用的是mongodb不支持事务。再者这只是一个例子,同样的问题也会出现在其他业务中,所以就需要开发者自己来保证原子操作不能涉及到EventLoop,以避免乱序执行带来的原子破坏问题。
面对这个问题,我现在只想说:我从来没有如此怀念过多线程的锁!
Node.js如何处理CPU密集型任务
Node.js的单线程 + EventLoop 机制保证了可以高效的处理并发I/O,然而单线程最大的命门就在于无法充分利用CPU的多和性能。很多人在争论PHP与Node孰优孰劣时,都把Node的单线程作为主要攻击点。
在EventLoop的一个tick到来时,需要对所有的event处理,并且在任意一个event处理完成前,其他的callback都没法执行。所以一旦在callback中做了CPU密集型的大量计算,event loop就无法继续运转。
下面用一个例子来说明这种情况:
- 高频次的CPU-unbound任务
var spinForever = function() {
process.stdout.write(".");
process.nextTick(spinForever);
};
- CPU-bound 任务,低效的Fibonacci实现:
function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
var fiboLoop = function() {
process.stdout.write(fibo(100).toString());
process.nextTick(fiboLoop);
};
那么当下面一段代码运行时,只有等到fiboLoop运算完成后才会执行spinForever任务,如上图所示,大量的easy task被一个difficult task 阻塞了。
fiboLoop();
spinForever();
PS:上面那段Fibonacci的实现是为了举栗子,实际项目中要是这么写会被喷死的;
如何利用闲置的CPU内核
在单线程Node.js的中,可以用以下的集中方法来实现多进程/多线程:
- fork分配子进程
Node.js通过child_process模块来管理子进程,使用fork()方法来创建一个新的Node程序实例。
在主进程中使用 child.send(message)发现消息给子进程,用child.on(“message”, callback)监听子进程来的消息;
在子进程中用process.send(message)通知主进程,用process.on(“message”, callbakc)监听主进程来的消息;
之前那个例子用fork子进程的方式来改造后为:
主进程代码:
var cp = require('child_process');
var child = cp.fork(__dirname+'/forkChild.js');
child.on('message', function(m) {
process.stdout.write(m.result.toString());
});
(function fiboLoop () {
child.send({v:40});
process.nextTick(fiboLoop);
})();
(function spinForever () {
process.stdout.write(".");
process.nextTick(spinForever);
})();
子进程代码:
function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
process.on('message', function(m) {
process.send({ result: fibo(m.v) });
});
父子进程之间的通信是同步的,并且fork()得到的是一个新的Node程序实例,所以新fork()一个进程的开销还是很大的。
- cluster实现多进程
使用cluster模块可以充分利用多核CPU资源,在Node.js的0.6版被纳入核心模块,但目前(V0.10.26)仍处于实验状态。借助cluster模块,Node.js程序可以同时在不同的内核上运行多个”工人进程“,每个”工人进程“做的都是相同的事情,并且可以接受来在同一个TCP/IP端口的请求。相对于在Ngnix或Apache后面启动几个Node.js程序实例而言,cluster用起来更加简单便捷。虽然cluster模块繁衍线程实际上用的也是child_process.fork,但它对资源的管理要比我们自己直接用child_process.fork管理得更好。下面是用cluster实现的代码:
function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
var cluster= require('cluster');
if (cluster.isMaster) {
cluster.fork();
} else {
(function fiboLoop () {
process.stdout.write(fibo(40).toString());
process.nextTick(fiboLoop);
})();
}
(function spinForever () {
process.stdout.write(".");
process.nextTick(spinForever);
})();
代码很简单,如果是主进程,就fork()工人进程,这里也可以用循环遍历,根据CPU内核的个数繁衍相应数量甚至更多的进程;如果是工人进程,就执行fiboLoop。你可以自行用top查看一下资源占用情况,你会发现这种方式用得资源比上面那种方式要少。
虽然cluster模块可以充分利用资源,用起来也比较简单,但它只是解决了负载分配的问题。但其实做得也不是特别好,在0.10版本之前,cluster把负载分配的工作交给了操作系统,然而实践证明,最终负载都落在了两三个进程上,分配并不均衡。所以在0.12版中,cluster改用round-robin方式分配负载。详情请参见这里。
- 第三方的多线程库threads_a_gogo
功能强大的threads_a_gogo是一个比较好用的Node多线程库,使用这个库改线的多线程版本如下:
function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
var numThreads= 10;
var threadPool= require('threads_a_gogo').createPool(numThreads).all.eval(fibo);
threadPool.all.eval('fibo(40)', function cb (err, data) {
process.stdout.write(" ["+ this.id+ "]"+ data);
this.eval('fibo(40)', cb);
});
(function spinForever () {
process.stdout.write(".");
process.nextTick(spinForever);
})();
参考文献
- Node.js软肋之CPU密集型任务
- Understanding process.nextTick()
- 理解 Node.js 里的 process.nextTick()
- What exactly is a Node.js event loop tick?
- Why you should use Node.js for CPU-bound tasks
- IO - 同步,异步,阻塞,非阻塞 (亡羊补牢篇)
- Understanding the Node.js Event Loop