目录
一、YARN的简介
1.1 MapReduce 1.x
1.1.1 MapReduce 1.x的角色
1.2 YARN的介绍
1.3 YARN的设计思想
二 YARN的配置
1. mapred-site.xml
2. yarn-site.xml
编辑
3. hadoop-env.sh
4. 分发到其他节点
5.YARN的服务启停
6. 任务测试
三 YARN的历史日志
1. 历史日志概述
2. mr-historyserver
1.配置文件
2.分发配置
3. 开启历史服务
四 YARN的Job提交
五 Yarn的命令
六 Yarn的三种调度器
什么是Scheduler(调度器)
YARN提供的三种内置调度器
1.FIFO Scheduler (FIFO调度器)
七 YARN的队列配置
1. 配置任务队列
2. 默认队列设置
八 YARN的Node Label机制
1. Node Label的介绍
2. 开启标签
3. 标签管理
1. 添加标签
2. 查看标签
3. 删除标签
4. 为节点打上标签
5. 为队列绑定标签
6. 测试
搭建好hadoop的分布式文件系统(HDFS), 在HDFS上存储数据,将数据进行切块,分布在不同的数据节点进行存储。这些解决了存储问题,下面开始来解决将这些节点上存储的数据文件来做计算。
谷歌发表的一篇论文《GFS》,Nutch团队对这个论文使用Java进行了实现,命名为NDFS,也就是后来的HDFS。谷歌还发表过另一篇论文《MapReduce》, 介绍的就是如何解决分布式文件系统上存储的数据进行计算的问题.也就是一个分布式计算的框架。
需要计算的文件分布在不同节点上,在进行数据计算的时候民有两种方式:
-
将数据移动到一个节点上,在这个节点上进行数据的计算。
-
将计算程序分发到每一个数据节点,在每一个节点计算自己的数据。
Hadoop使用第二种计算方式,也就是将计算程序分发到不同的数据节点进行计算。Hadoop官方案例就是分布式的计算程序。而为每个计算任务分配计算资源(内存,CPU),如何协调第一个节点上的计算任务,如何监控每一个节点上的计算任务等。而这些,都由YARN实现.
一、YARN的简介
1.1 MapReduce 1.x
第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成。其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。对应Hadoop版本为Hadoop 1.x, 和0.21.x, 0.22.x。
1.1.1 MapReduce 1.x的角色
-
client: 作业提交发起者
-
JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业
-
TaskTracker: 保持JobTracker通信,在分配的数据片段上执行MapReduce任务
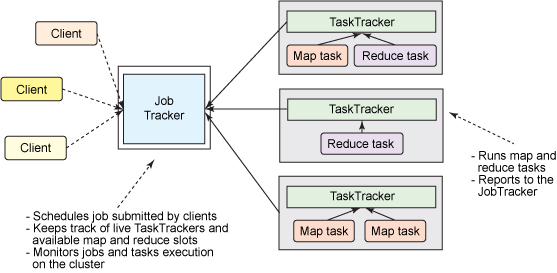
1.1.2 MapReduce 1.x执行流程
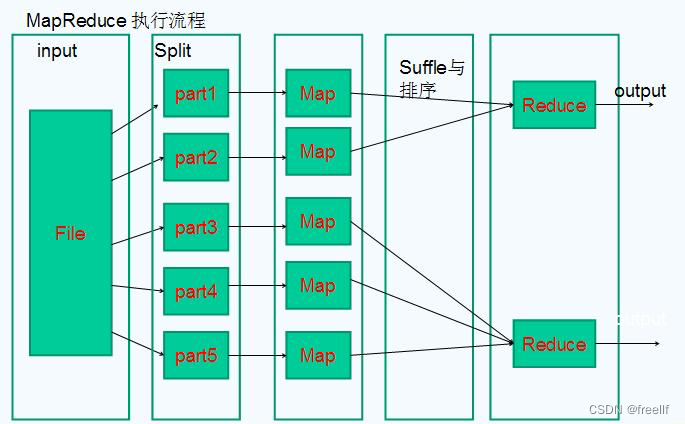
-
提交作业
编写MapReduce程序代码,创建Job对象,并进行配置,比如输入和输出路径,压缩格式等,然后通过JobClient来提交作业.
-
初始化作业
客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
-
分配任务
TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
-
执行任务
申请到任务后,TaskTracker会作如下事情:
-
拷贝代码到本地
-
拷贝任务的信息到本地
-
启动JVM运行任务
-
-
状态与任务的更新
任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。任务进度是通过计数器来实现的。
-
作业的完成
JobTracker是在接受到最后一个任务运行完成后,才会将任务标记为成功。此时会做删除中间结果等善后处理工作。
1.2 YARN的介绍
为克服Hadoop 1.0中的HDFS和MapReduce存在的各种问题而提出的,针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARM。
Apache YARM(Yet another Resource Negotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序。
YARN被引入Hadoop 2,最初是为了改善MapReduce的实现,但是因为具有足够的通用性,同样可以支持其他的分布式计算模式,比如Spark, Tez等计算框架。
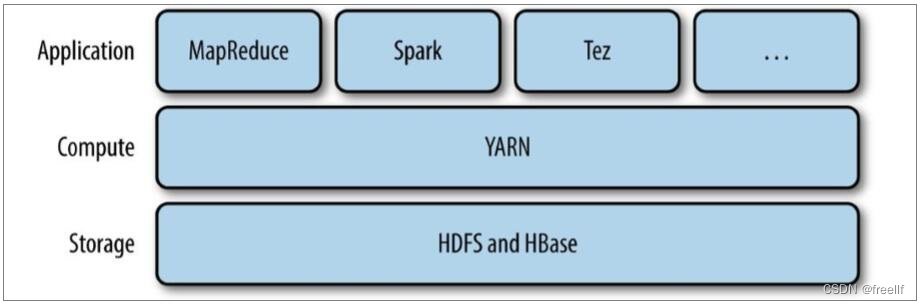
注意: 还有一层应用是运行在MapReduce, Sqark或者Tez之上的处理框架,如Pig, Hive和Crunch等.
1.3 YARN的设计思想
YARN的基本思想是将资源管理和作业调度/监视功能划分为单独蝗守护进程。其思想是拥有一个全局ResourceManager(RM), 以及每个应用程序拥有一个ApplicationMaster(AM)。应用程序可以是单个作业,也可以是一组作业。
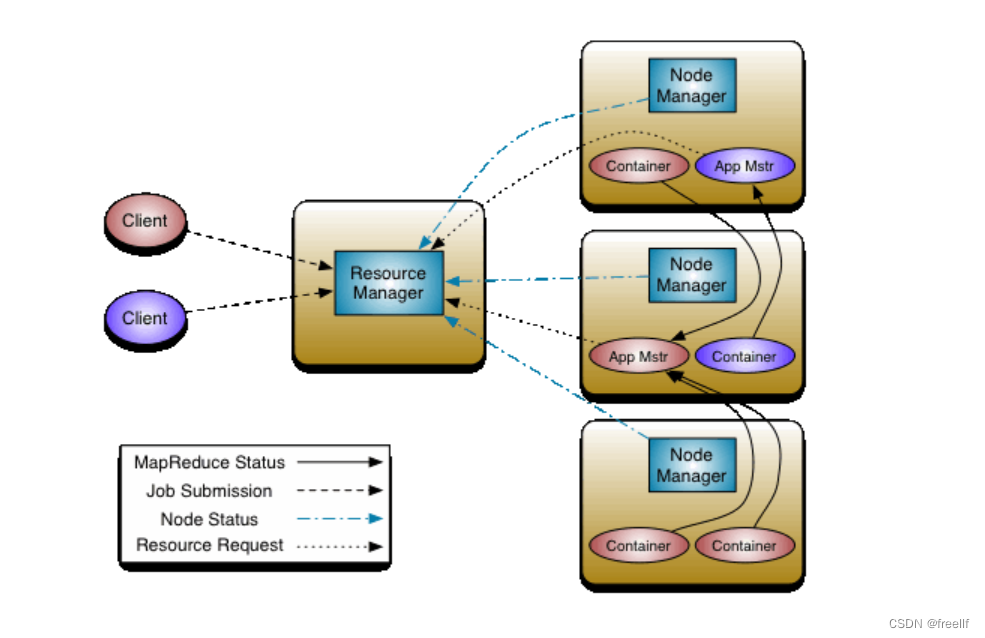
一个ResourceManager和多个Nodemanager构成了YARM资源管理框架。他们是YARM启动后长期运行的守护进程,来提供核心服务。
ResourceManager
是在系统中的所有应用程序之间仲裁资源的最终权威,即管理整个集群上的所有资源分配,内部含有一个Scheduler(资源调度器)
NodeManager
是每台机器的资源管理器,也就是单个节点的管理者,负责启动和监视容器(container)资源使用情况,并向ResourceManager及其Scheduler报告使用情况
container
即集群上的可使用资源,包含cpu、内存、磁盘、网络等
ApplicationMaster(简称AM)
实际上是框架的特定的库,每启动一个应用程序,都会启动一个AM,它的任务是与ResourceManager协商资源,并与NodeManager一起执行和监视任务。
YARN的角色 MapReduce 1.x的角色 ResourceManager、Application Master、Timeline Server JobTracker NodeManager TaskTracker Container Slot
二 YARN的配置
YARN属于Hadoop的核心组件,不需要单独安装,只需要修改一些配置文件件即可。
1. mapred-site.xml
<!-- 指定MapReduce作业执行时,使用YARN进行资源调度 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>2. yarn-site.xml
<!-- 设置ResourceManager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopmaster</value>
</property>
<!--配置yarn的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3. hadoop-env.sh
#添加如下:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root4. 分发到其他节点
cd $HADOOP_HOME/etc/
scp -r hadoop hadoopnode1:$PWD
scp -r hadoop hadoopnode2:$PWD5.YARN的服务启停
| 描叙 | 命令 |
|---|---|
| 开启YARN全部服务 | start-yarn.sh |
| 停止YARN全部服务 | stop-yarn.sh |
| 单点开启YARN相关进程 | yarn --daemon start resourcemanager yarn --daemon start nodemanager |
| 单点关闭YARN相关进程 | yarn --daemon stop resourcemanager yarn --daemon stop nodemanager |
验证:http://192.168.68.128:8088/cluster

如果此页面启动不起来,需在yarn-site.xml里添加:
<!--然后在yarn-site.xml添加配置: -->
<!--yarnweb http通讯地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>详见:hadoop yarn 历史服务器 web无法访问_yarn webui无法访问历史服务器-CSDN博客
6. 任务测试
当开启所有的YARN的进程之后,我们再次运行之前的Hadoop官方案例:wordcount
hadoop jar /usr/local/hadoop-3.3.1/share/hadoop//mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /newInput /output2hadoop jar /usr/local/hadoop-3.3.1/share/hadoop//mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 101.错误处理
错误: 找不到或无法加载主类 org.apache.hadoop.mapred.YarnChild
在命令窗口输入下面命令
hadoop classpath将显示出来的路径添加到 "yarn.application.classpath"的Value值里,如下
<property>
<name>yarn.application.classpath</name>
<value>
/usr/local/hadoop-3.3.1/etc/hadoop,
/usr/local/hadoop-3.3.1/share/hadoop/common/lib/*,
/usr/local/hadoop-3.3.1/share/hadoop/common/*,
/usr/local/hadoop-3.3.1/share/hadoop/hdfs,
/usr/local/hadoop-3.3.1/share/hadoop/hdfs/lib/*,
/usr/local/hadoop-3.3.1/share/hadoop/hdfs/*,
/usr/local/hadoop-3.3.1/share/hadoop/mapreduce/*,
/usr/local/hadoop-3.3.1/share/hadoop/yarn,
/usr/local/hadoop-3.3.1/share/hadoop/yarn/lib/*,
/usr/local/hadoop-3.3.1/share/hadoop/yarn/*
</value>
</property>将这段内容编辑进 yarn-site.xml里面,并重启yarn.
2 错误:
INFO conf.Configuration: resource-types.xml not found INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
参见:Apache Hadoop 3.0.0 – Hadoop: YARN Resource Configuration
hadoop jar /usr/local/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10三 YARN的历史日志
1. 历史日志概述
当在YARN上运行MapReduce的程序的时候,可以在控制台上看到任务的日志输出,以获取到任务的运行状态。同时,YARN也会将日志写在本地的$HADOOP_HOME/logs/userlogs文件夹中,我们可以到文件夹中进行日志的查看,但是这个文件夹中的内容,会随意YARN的重启而被删除掉,那么此时我们将如何查看日志?
此时就需要开启Hadoop的历史日志服务了,Hadoop会将MapReduce的任务日志在HDFS也保留一份,我们可以通过Hadoop的历史任务服务来查看到之前的历史日志!
但是每一个程序会被分布在不同的节点上进行运行,我们在进行任务查看的时候还得一个个的指定节点进行查看,并一个个的找MapTask或者ReduceTask的日志, 很麻烦!预设Yarn提供了历史日志聚合的服务!
顾名思义,就是将每一个程序的历史日志都聚合在一起,存储在HDFS上,方便查看!
2. mr-historyserver
记录MapReduce的历史日志的,接下来从配置开始,到日志聚合,运行任务。
1.配置文件
mapred-site.xml
<!-- 历史任务的内部通讯地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoopmaster:10020</value>
</property>
<!-- 历史任务的外部监听页面 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoopmaster:19888</value>
</property>yarn-site.xml
<!-- 开启日志聚集功能 -->
<!-- 开启日志聚集功能后,将会将各个Container的日志保存在yarn.nodemanager.remote-app-log-dir的位置 -->
<!-- 默认保存在/tmp/logs-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoopmaster:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<!-- 默认的是-1, 表示永久保存-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>2.分发配置
[~]# pwd
/usr/local/hadoop-3.3.1/etc/hadoop
[~]# scp mapred-site.xml yarn-site.xml hadoopnode1:$PWD
[~]# scp mapred-site.xml yarn-site.xml hadoopnode2:$PWD3. 开启历史服务
#重启yarn集群
[~]# stop-yarn.sh
[~]# start-yarn.sh
#打开历史服务
[~]# mapred --daemon start historyserver
#开启之后,通过jps可以查看到 JobHistoryServer 进程,表示开启成功四 YARN的Job提交
在MR程序运行时,有五个独立的进程:
YarnRunner:用于提交作业的客户端程序
ResourceManager: yarn资源管理器,负责协调集群上计算机资源的分配
NodeManager: yarn节点管理器,负责启动和监视集群中机器上的计算容器(container)
Application Master: 负责协调运行MapReduce作业的任务,他和任务都在容器中运行,这些容器由资源管理分配并由节点管理器进行管理。
HDFS: 用于共享作业所需文件。
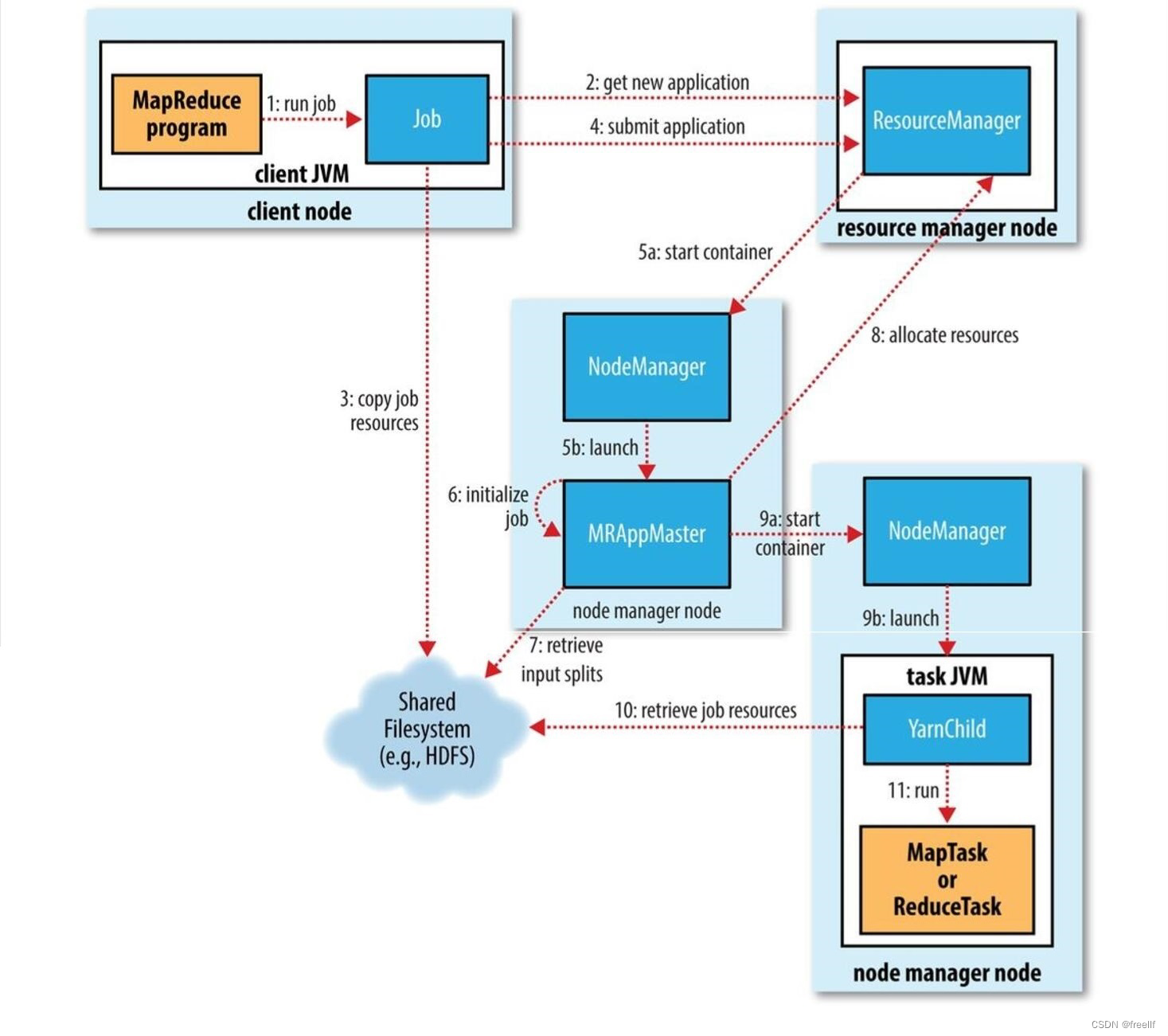
1. 调用waitForCompletion方法每秒轮询作业的进度,内部封装了submit()方法,用于创建JobCommiter实例,并且调用其的submitJobInternal方法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到控制台 2. JobCommiter实例会向ResourceManager申请一个新应用ID,用于MapReduce作业ID。这期间JobCommiter也会进行检查输出路径的情况,以及计算输入分片。 3. 如果成功申请到ID,就会将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片元数据文件)上传到一个用ID命名的目录下的HDFS上。此时副本个数默认是10. 4. 准备工作已经做好,再通知ResourceManager调用submitApplication方法提交作业。 5. ResourceManager调用submitApplication方法后,会通知Yarn调度器(Scheduler),调度器分配一个容器,在节点管理器的管理下在容器中启动 application master进程。 6. application master的主类是MRAppMaster,其主要作用是初始化任务,并接受来自任务的进度和完成报告。 7. 然后从HDFS上接受资源,主要是split。然后为每一个split创建MapTask以及参数指定的ReduceTask,任务ID在此时分配 8. 然后Application Master会向资源管理器请求容器,首先为MapTask申请容器,然后再为ReduceTask申请容器。(5%) 9. 一旦ResourceManager中的调度器(Scheduler),为Task分配了一个特定节点上的容器,Application Master就会与NodeManager进行通信来启动容器。 10. 运行任务是由YarnChild来执行的,运行任务前,先将资源本地化(jar文件,配置文件,缓存文件) 11. 然后开始运行MapTask或ReduceTask。 12. 当收到最后一个任务已经完成的通知后,application master会把作业状态设置为success。然后Job轮询时,知道成功完成,就会通知客户端,并把统计信息输出到控制台
五 Yarn的命令
-
yarn top
类似于Linux的top命令,查看正在运行的程序资源占用情况。
-
yarn queue -status root.default
查看指定队列使用情况,下文会讲解任务队列
-
yarn application
-
-list
#通过任务的状态,列举YARN的任务,使用-appStates指定状态 #任务状态:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED #e.g. #查看所有正在运行的任务 yarn application -list -appStates RUNNING #查看所有的失败的任务 yarn application -list -appStates FAILED-
-movetoqueue
#将一个任务移动到指定的队列中 yarn application -movetoqueue application_xxxxxx_xxx -queue root.small -
-kill
#杀死指定的任务 yarn application -kill application_xxxxxx_xxx
-
-
yarn container
-
-list
#查看正在执行的任务的容器信息 yarn container -list application_xxxxxxxxxx_xxx -
-status
#查看指定容器信息 yarn container -status container_xxxxx
-
-
yarn jar
#提交任务到YARN执行 yarn jar $HADOOP_HOME/share/hadoop/mapreduce-examples-3.3.1.jar /input /output -
yarn logs
#查看yarn的程序运行时的日志信息
yarnlogs -applicationId application_xxxxxxxxxx_xxx-
yarn node -all -list
查看所有节点信息
六 Yarn的三种调度器
-
什么是Scheduler(调度器)
Scheduler即调度器,队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
-
YARN提供的三种内置调度器
1.FIFO Scheduler (FIFO调度器)
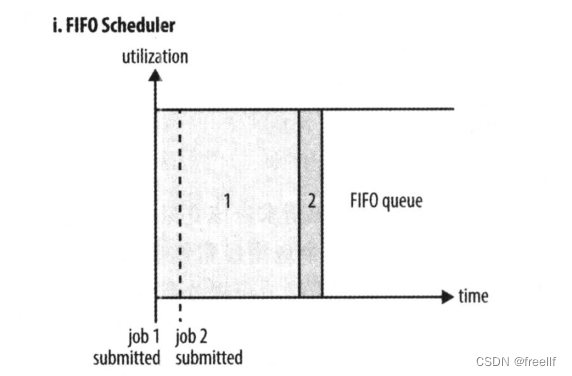
FIFO 为 First Input First Output 的缩写,先进先出。FIFO调度器将应用放在一个队列中,按照先后顺序运行应用。这种策略较为简单,但不适合共享集群,因为大的应用会占用集群的所有资源,每个应用必须等待直到轮到自己。 优点: 简单易懂, 不需要任何配置 缺点: 不适合共享集群,大的应用会占据集群中的所有资源,所以每个应用都必须等待,直到轮到自己执行。
如下图所示,只有当job1全部执行完毕,才能开始执行job2
2. Capacity Scheduler (容量调度器)
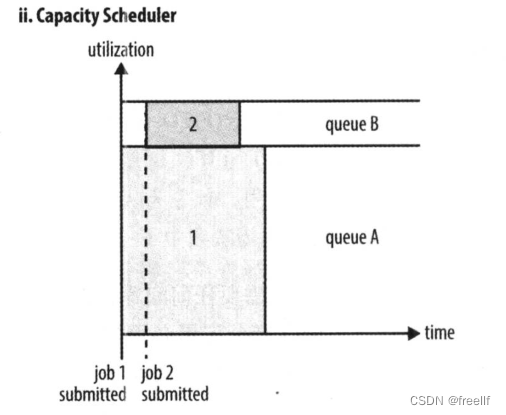
如图所示,专门留了一部分资源给小任务,可以在执行job1的同时,不会阻塞job2的执行,但是因为这部分资源是一直保留给其他任务的,所以就算只有一个任务,也无法为其分配全部资源,只能让这部分保留资源闲置着,有着一定的资源浪费问题。
3. Fair Scheduler (公平调度器)
公平调度器的目的就是为所有运行的应用公平分配资源,使用公平调度超时,不需要预留一定量的资源,因为调度器会在所有运行的作业之间动态平衡资源,第一个(大)作业启动时,它也是唯一运行的作业。因而获得集群中的所有资源,当第二个(小)作业启动时,它被分配到集群的一半资源,这样每个作业都能公平共享资源。
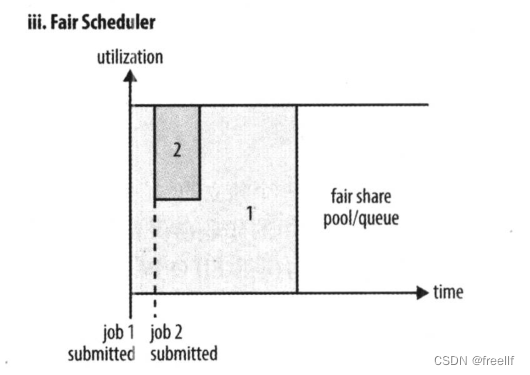
如图所示,就像是把好几个任务拼接成了一个任务,可以充分利用资源,同时又不会因为大任务在前面执行而导致小任务一直无法完成。
七 YARN的队列配置
YARN默认采用的调度器是容量调度,且默认只有一个任务队列。该调度器内单个队列的调度策略为FIFO,因此在单个队列中的任务并行度为1。那么就会出现单个任务阻塞的情况,如果随着业务的增长,充分的利用到集群的使用率,我们就需要手动的配置多条任务队列。
1. 配置任务队列
默认YARN只有一个default任务队列,现在我们添加一个small的任务队列。
修改配置文件: $HADOOP_HOME/etc/hadoop/capacity-scheduler.xml
<configuration>
<!-- 不需要修改 -->
<!-- 容量调度器中最多容纳多少个Job -->
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
Maximum number of applications that can be pending and running.
</description>
</property>
<!-- 不需要修改 -->
<!-- MRAppMaster进程所占的资源可以占用队列总资源的百分比,可以通过修改这个参数来限制队列中提交Job的数量 -->
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
<!-- 不需要修改 -->
<!-- 为Job分配资源的时候,使用什么策略 -->
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
<!-- 修改!!! -->
<!-- 调度器中有什么队列,我们添加一个small队列 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,small</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<!-- 修改!!! -->
<!-- 配置default队列的容量百分比 -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>Default queue target capacity.</description>
</property>
<!-- 新增!!! -->
<!-- 新增small队列的容量百分比 -->
<!-- 所有的队列容量百分比和需要是100 -->
<property>
<name>yarn.scheduler.capacity.root.small.capacity</name>
<value>30</value>
<description>Default queue target capacity.</description>
</property>
<!-- 不需要修改 -->
<!-- default队列用户能使用的容量最大百分比 -->
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<!-- 添加!!! -->
<!-- small队列用户能使用的容量最大百分比 -->
<property>
<name>yarn.scheduler.capacity.root.small.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<!-- 不需要修改 -->
<!-- default队列能使用的容量最大百分比 -->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<!-- 添加!!! -->
<!-- small队列能使用的容量最大百分比 -->
<property>
<name>yarn.scheduler.capacity.root.small.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<!-- 不需要修改 -->
<!-- default队列的状态 -->
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<!-- 添加!!! -->
<!-- small队列的状态 -->
<property>
<name>yarn.scheduler.capacity.root.small.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<!-- 不需要修改 -->
<!-- 限制向队列提交的用户-->
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<!-- 添加!!! -->
<property>
<name>yarn.scheduler.capacity.root.small.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<!-- 不需要修改 -->
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<!-- 添加!!! -->
<property>
<name>yarn.scheduler.capacity.root.small.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<!-- 不需要修改 -->
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
Typically this should be set to number of nodes in the cluster, By default is setting
approximately number of nodes in one rack which is 40.
</description>
</property>
<!-- 不需要修改 -->
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
<description>
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same name
as the user.
</description>
</property>
<!-- 不需要修改 -->
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>
If a queue mapping is present, will it override the value specified
by the user? This can be used by administrators to place jobs in queues
that are different than the one specified by the user.
The default is false.
</description>
</property>
</configuration><configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
Maximum number of applications that can be pending and running.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,small</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>Default queue target capacity.</description>
</property>
<!-- 新增!!! -->
<!-- 新增small队列的容量百分比 -->
<!-- 所有的队列容量百分比和需要是100 -->
<property>
<name>yarn.scheduler.capacity.root.small.capacity</name>
<value>30</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<!-- 添加!!! -->
<!-- small队列用户能使用的容量最大百分比 -->
<property>
<name>yarn.scheduler.capacity.root.small.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<!-- 添加!!! -->
<!-- small队列能使用的容量最大百分比 -->
<property>
<name>yarn.scheduler.capacity.root.small.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<!-- 添加!!! -->
<!-- small队列的状态 -->
<property>
<name>yarn.scheduler.capacity.root.small.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<!-- 添加!!! -->
<property>
<name>yarn.scheduler.capacity.root.small.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<!-- 添加!!! -->
<property>
<name>yarn.scheduler.capacity.root.small.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name>
<value>*</value>
<description>
The ACL of who can submit applications with configured priority.
For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}]
</description>
</property>
<!-- 添加 -->
<property>
<name>yarn.scheduler.capacity.root.small.acl_application_max_priority</name>
<value>*</value>
<description>
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-application-lifetime
</name>
<value>-1</value>
<description>
Maximum lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
This will be a hard time limit for all applications in this
queue. If positive value is configured then any application submitted
to this queue will be killed after exceeds the configured lifetime.
User can also specify lifetime per application basis in
application submission context. But user lifetime will be
overridden if it exceeds queue maximum lifetime. It is point-in-time
configuration.
Note : Configuring too low value will result in killing application
sooner. This feature is applicable only for leaf queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.small.maximum-application-lifetime</name>
<value>-1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.default-application-lifetime
</name>
<value>-1</value>
<description>
Default lifetime of an application which is submitted to a queue
in seconds. Any value less than or equal to zero will be considered as
disabled.
If the user has not submitted application with lifetime value then this
value will be taken. It is point-in-time configuration.
Note : Default lifetime can't exceed maximum lifetime. This feature is
applicable only for leaf queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.small.default-application-lifetime</name>
<value>-1</value>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
When setting this parameter, the size of the cluster should be taken into account.
We use 40 as the default value, which is approximately the number of nodes in one rack.
Note, if this value is -1, the locality constraint in the container request
will be ignored, which disables the delay scheduling.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.rack-locality-additional-delay</name>
<value>-1</value>
<description>
Number of additional missed scheduling opportunities over the node-locality-delay
ones, after which the CapacityScheduler attempts to schedule off-switch containers,
instead of rack-local ones.
Example: with node-locality-delay=40 and rack-locality-delay=20, the scheduler will
attempt rack-local assignments after 40 missed opportunities, and off-switch assignments
after 40+20=60 missed opportunities.
When setting this parameter, the size of the cluster should be taken into account.
We use -1 as the default value, which disables this feature. In this case, the number
of missed opportunities for assigning off-switch containers is calculated based on
the number of containers and unique locations specified in the resource request,
as well as the size of the cluster.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
<description>
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same name
as the user.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>
If a queue mapping is present, will it override the value specified
by the user? This can be used by administrators to place jobs in queues
that are different than the one specified by the user.
The default is false.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name>
<value>1</value>
<description>
Controls the number of OFF_SWITCH assignments allowed
during a node's heartbeat. Increasing this value can improve
scheduling rate for OFF_SWITCH containers. Lower values reduce
"clumping" of applications on particular nodes. The default is 1.
Legal values are 1-MAX_INT. This config is refreshable.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.application.fail-fast</name>
<value>false</value>
<description>
Whether RM should fail during recovery if previous applications'
queue is no longer valid.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings</name>
<value></value>
<description>
A list of mappings that will be used to override application priority.
The syntax for this list is
[workflowId]:[full_queue_name]:[priority][,next mapping]*
where an application submitted (or mapped to) queue "full_queue_name"
and workflowId "workflowId" (as specified in application submission
context) will be given priority "priority".
</description>
</property>
<property>
<name>yarn.scheduler.capacity.workflow-priority-mappings-override.enable</name>
<value>false</value>
<description>
If a priority mapping is present, will it override the value specified
by the user? This can be used by administrators to give applications a
priority that is different than the one specified by the user.
The default is false.
</description>
</property>
</configuration>分发到hadoopnode1和hadoopnode2节点
scp capacity-scheduler.xml hadoopnode1:$PWD
scp capacity-scheduler.xml hadoopnode2:$PWD重启yarn服务或刷新
stop-yarn.sh
start-yarn.sh
#或
yarn rmadmin -refreshQueues刷新yarn的web页面可以看到
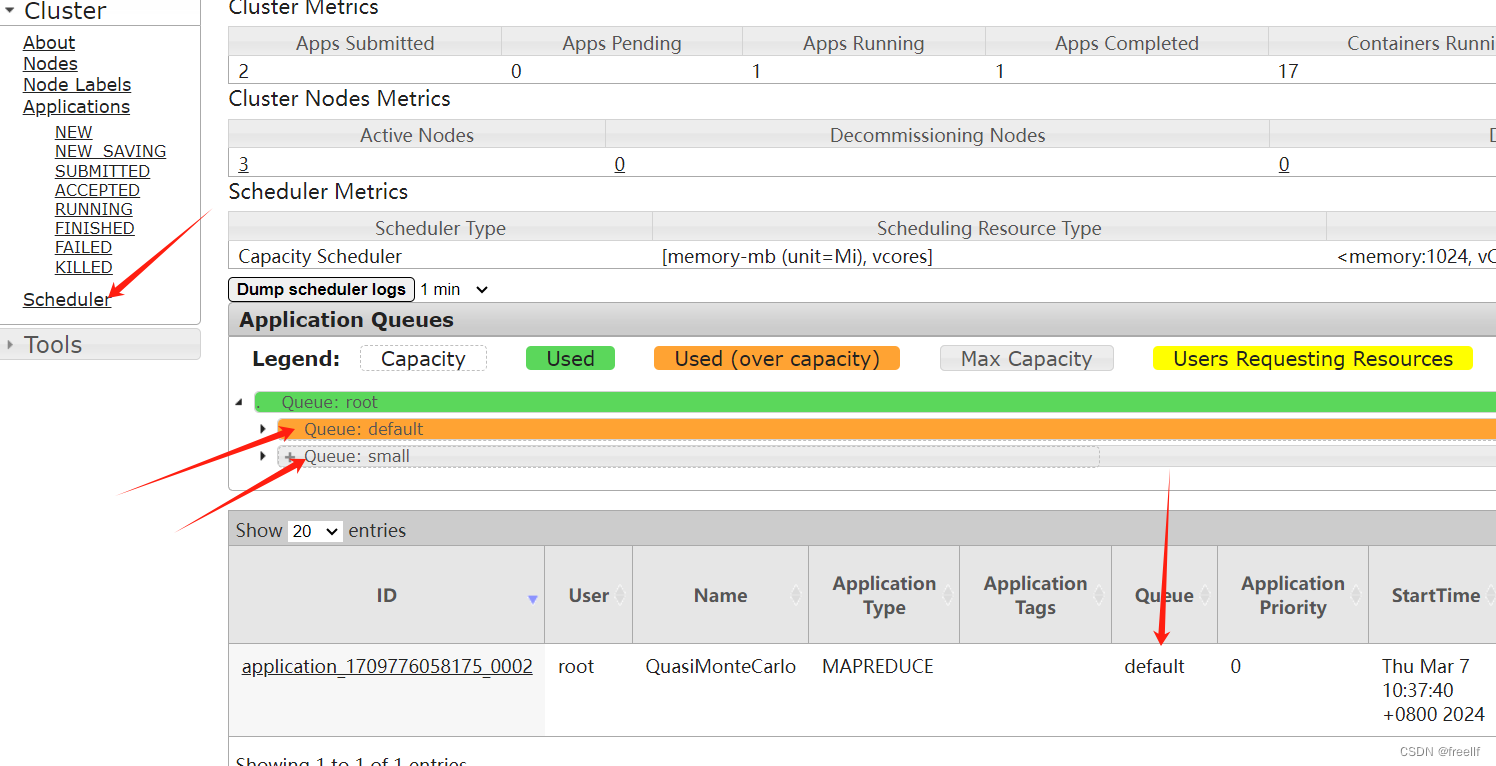
指定提交队列
-Dmapreduce.job.queuename=small如:
hadoop jar /usr/local/hadoop-3.3.1/share/hadoop//mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount -Dmapreduce.job.queuename=small /input /output22hadoop jar /usr/local/hadoop-3.3.1/share/hadoop//mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi -Dmapreduce.job.queuename=small 50 50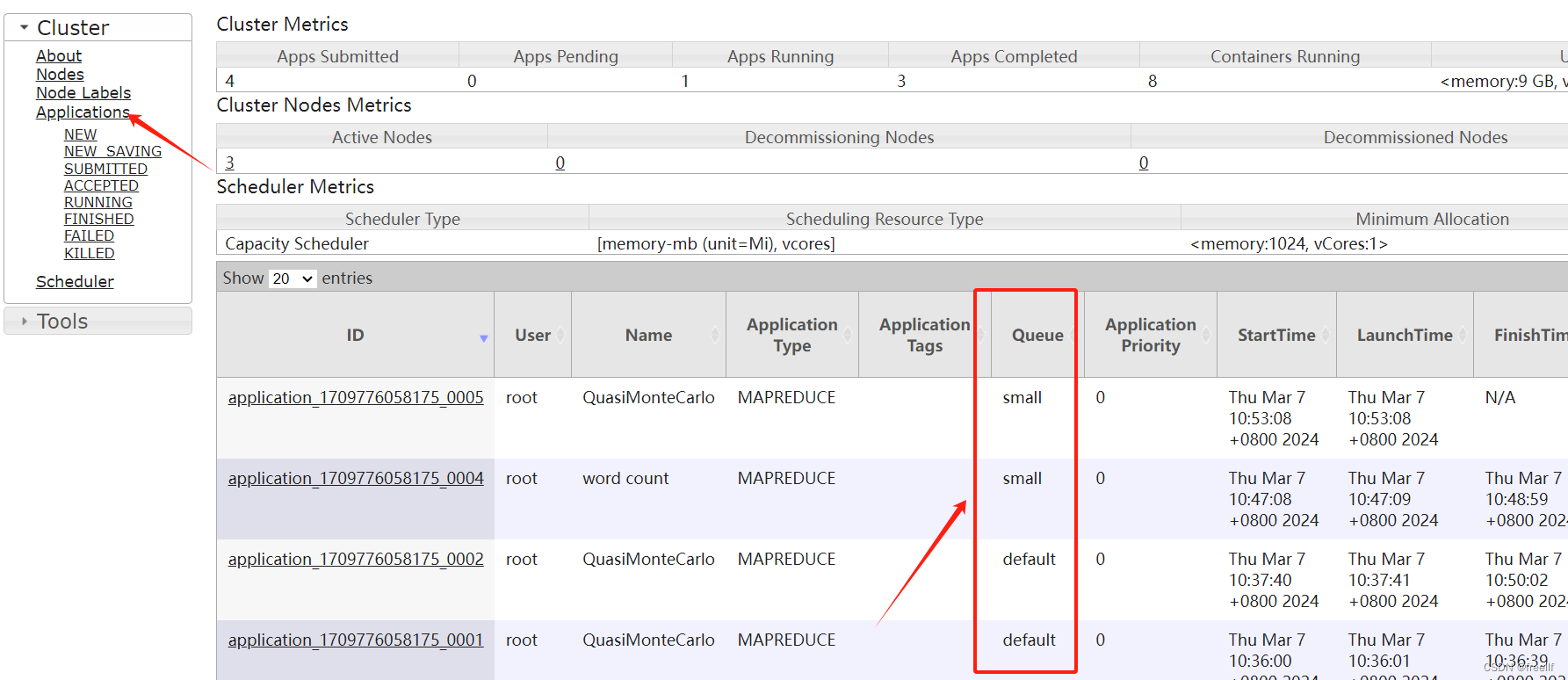
如不用-Dmapreduce.job.queuename指定队列,默认队列是 default .
2. 默认队列设置
YARN默认将任务提交到default队列,如果需要提交到其他的队列中,可以使用 -Dmapreduce.job.queuename指定提交的队列,也可以设置默认的任务提交队列。
例如:Hive的底层会把HQL语句翻译成MapReduce的程序执行,可以创建一个hive队列,将这个队列的容量设置的大一些,我们可以设置默认将任务提交到这个队列中,如果需要往其他的队列中提交任务的话,可以再使用 -Dmapreduce.job.queuename去提交了.
<!-- 配置默认的提交队列 -->
<property>
<name>mapreduce.job.queuename</name>
<value>small</value>
</property>修改mapred-site.xml文件,不需要重启,直接提交任务,自动使用指定的队列去执行。
八 YARN的Node Label机制
1. Node Label的介绍
官网对NodeLabel的介绍如下:
Node Label is a way to group nodes with similar characteristics and applications can specify where to run. 节点标签是一种对具有相似特征的节点进行分组的方法,应用程序可以指定在哪里运行。
那么标签到底是做什么的?
我们可以创建多个队列,划分集群的总的资源,例如队列hive占集群总资源的70%,那么这个70%具体会落地在哪一个节点上呢?没办法确定,有可能在hadoopmaster, 也有可能在hadoopnode2上,而节点标签,可以为每一个NodeManager打上标签,可以限定某一个程序只能够运行在哪些节点上。例如希望我们提交的程序wordcount的程序只会运行在hadoopnode1和hadoopnode2节点上,这就是标签的作用。
2. 开启标签
修改 yarn-site.xml文件,添加如下配置:
<!-- 启用节点标签 -->
<property>
<name>yarn.node-labels.enabled</name>
<value>true</value>
</property>
<!-- 节点标签存储的路径,可以是HDFS,也可以是本地文件系统 -->
<!-- 如果是本地文件系统,使用类似 file://home/yarn/node-label这样的路径-->
<!-- 无论是HDFS,还是本地文件系统,需要保证RM有权限去访问 -->
<property>
<name>yarn.node-labels.fs-store.root-dir</name>
<value>hdfs://hadoopnode1:9820/tmp/yarn/node-labels</value>
</property>
<!-- 保持默认即可,也可以不配置这个选项 -->
<property>
<name>yarn.node-labels.configuration-type</name>
<value>centralized</value>
</property>分发到各各节点,并重启 yarn 服务.
3. 标签管理
1. 添加标签
yarn rmadmin -addToClusterNodeLabels "label_1"
yarn rmadmin -addToClusterNodeLabels "label_2,label_3"2. 查看标签
yarn cluster --list-node-labels3. 删除标签
yarn rmadmin -removeFromClusterNodeLabels label_14. 为节点打上标签
# 绑定一个NodeManager与Label
yarn rmadmin -replaceLabelsOnNode "qianfeng02=label_2"
# 绑定多个NodeManager与Label的关系,中间用空格分隔
yarn rmadmin -replaceLabelsOnNode "qianfeng02=label_2 qianfeng03=label_2"
# 一个标签可以绑定多个NodeManager,一个NodeManager只能绑定一个标签。
# 例如上方的,label_2就绑定在了qianfeng02和qianfeng03的NodeManager上。
# 绑定完成后,可以使用WebUI进行查看。
# 在WebUI的左侧,有Node Labels的查看,可以查看到所有的标签,以及对应的节点信息。
# 需要注意的是,如果某节点没有进行标签的绑定,则其在一个默认的<DEFAULT_PARTITION>上绑定。5. 为队列绑定标签
通过修改capacity-scheduler.xml实现:
<!-- 前文,我们已经新增了一个队列,现在共有两个队列: default、small -->
<!-- 设置某个队列可以使用的标签,*表示通配,可以使用所有标签 -->
<property>
<name>yarn.scheduler.capacity.root.default.accessible-node-labels</name>
<value>*</value>
</property>
<!-- 设置small队列可以使用label_3标签的节点资源 -->
<property>
<name>yarn.scheduler.capacity.root.small.accessible-node-labels</name>
<value>label_3</value>
</property>
<!-- 设置default队列可以使用label_2标签的节点资源最多60% -->
<property>
<name>yarn.scheduler.capacity.root.default.accessible-node-labels.label_2.capacity</name>
<value>60</value>
</property>
<!-- 设置small队列可以使用label_3标签的节点资源最多80% -->
<property>
<name>yarn.scheduler.capacity.root.small.accessible-node-labels.label_3.capacity</name>
<value>80</value>
</property>
<!-- 设置default队列,如果没有明确的标签指向,则默认使用label_3 -->
<property>
<name>yarn.scheduler.capacity.root.default.default-node-label-expression</name>
<value>label_3</value>
</property>修改之后,无需重启,直接刷新一下队列即可: yarn rmadmin -refreshQueues
6. 测试
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi -Dmapreduce.job.queuename=small 10 10