最近发现通过Edge和chrome或者其他浏览器下载的文件都存放在一个地方就很繁琐,于是翻找以前的脚本来归纳这些文件,虽然有IDM下载独有会自动分类,但是相信很多同学都在一个文件里找文件,这次就写个Py脚本来实现这个功能。
# -*- coding: utf-8 -*-
# @Time : 2022/3/4 13:41
# @Author : 五指山下的泼猴!!
# @FileName: 文件分类-2.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/m0_57076217
import hashlib
import os
import shutil
def get_file_hash(file_path):
# 计算文件的 SHA-256 哈希值
with open(file_path, 'rb') as file:
return hashlib.sha256(file.read()).hexdigest()
def organize_files(folder_path):
# 创建一个名为“Duplicates”的文件夹,用于存放重复文件
duplicates_folder = os.path.join(folder_path, 'Duplicates')
os.makedirs(duplicates_folder, exist_ok=True)
# 遍历文件夹中的文件
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
if os.path.isfile(file_path):
# 获取文件扩展名并转换为小写
_, extension = os.path.splitext(filename)
extension = extension.lower()
# 确定目标文件夹
if extension in ['.jpg', '.jpeg', '.png', '.gif', '.bmp']:
destination_folder = 'Images'
elif extension in ['.mp4', '.mov', '.avi', '.mkv']:
destination_folder = 'Videos'
else:
destination_folder = extension[1:] if extension else 'Other'
destination_path = os.path.join(folder_path, destination_folder)
os.makedirs(destination_path, exist_ok=True)
# 计算文件哈希值
file_hash = get_file_hash(file_path)
# 检查文件是否是重复文件
if os.path.exists(os.path.join(destination_path, filename)) or \
file_hash in os.listdir(duplicates_folder):
# 如果是重复文件,则移动到“Duplicates”文件夹
shutil.move(file_path, os.path.join(duplicates_folder, filename))
print(f"成功将文件 {filename} 移动到 Duplicates 文件夹.")
else:
# 否则移动到目标文件夹
shutil.move(file_path, os.path.join(destination_path, filename))
print(f"成功将文件 {filename} 移动到 {destination_path}")
if __name__ == "__main__":
# 获取用户输入的文件夹路径
folder_path = input("请输入要整理的文件夹路径(复制绝对路径):")
# 调用函数进行文件整理
organize_files(folder_path)
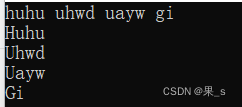
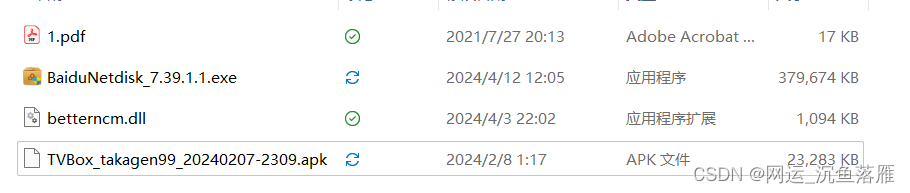
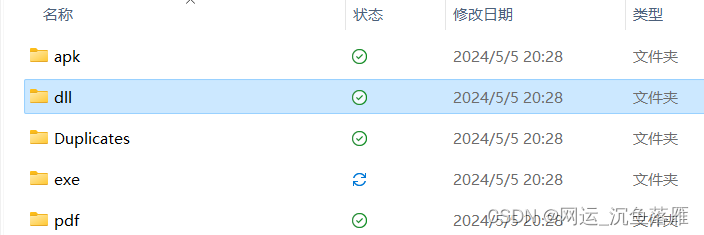
以下是效果:







![【uniapp】阿里云OSS上传 [视频上传]](https://img-blog.csdnimg.cn/direct/4bdce6e7a00c40ff97806453e88bbe85.png)