目录
- 前言
- 一、pivot_table 透视表
- 二、crosstab 交叉表
- 三、实际应用
前言
透视表是excel和其他数据分析软件中一种常见的数据汇总工具。它是根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中。
一、pivot_table 透视表
pivot_table()默认显示指定索引列和所有数值列。
语法:
pivot_table(data: ‘DataFrame’, values=None, index=None, columns=None, aggfunc: ‘AggFuncType’ = ‘mean’, fill_value=None, margins: ‘bool’ = False, dropna: ‘bool’ = True, margins_name: ‘str’ = ‘All’, observed: ‘bool’ = False, sort: ‘bool’ = True)
参数解析:
- data:dataframe数据框。
- value:需要聚合的列的名称,可选。默认聚合所有数值列。
- index:用于分组的列名或其他分组键,出现在结果透视表的行。
- columns:用于分组的列名或其他分组键,出现在结果透视表的列。
- aggfunc:聚合函数或函数列表,默认为"mean",可以是任何对groupby有效的函数。
- fill_value:用于替换结果表中的缺失值。
- margins:添加行/列小计和总计,默认为False。
- dropna:不聚合所有值都为NA的列,默认为True。
- margins_name:如果margins=True,设置添加行/列小计和总计的名称,默认为"All"。
举例:
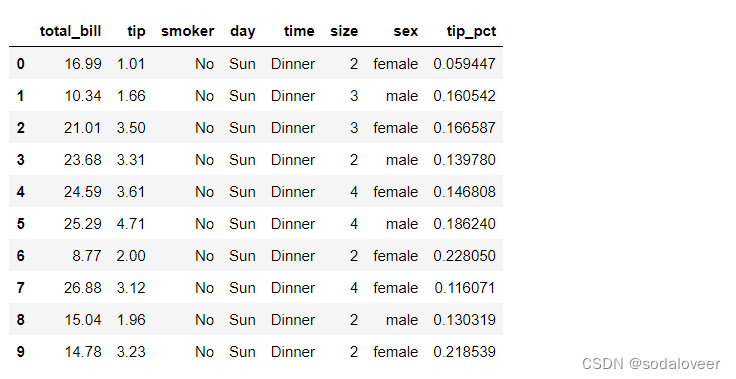
以小费数据集为例,数据情况如下:
import pandas as pd
tips=pd.read_csv('F:\\pydata-book-2nd-edition\\examples\\tips.csv')
tips["tip_pct"]=tips["tip"]/tips["total_bill"] #添加一列小费比例tip_pct
tips.head(10)
tips.shape # (244, 8)
tips.columns

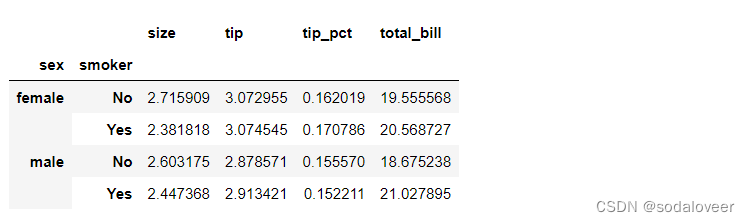
参数index:根据sex和smoker计算分组平均数。
#pivot_table的默认聚合类型:平均数
tips.pivot_table(index=['sex ','smoker'])
参数values和columns:只想聚合"tip_pct"和"size",根据"sex","day"分组,将"smoker"放到列上,"day"放到行上。
tips.pivot_table(['tip_pct','size'],index=['sex ','day'],columns='smoker')
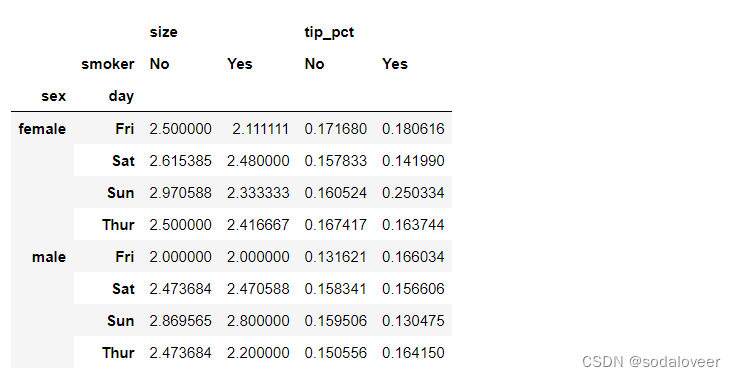
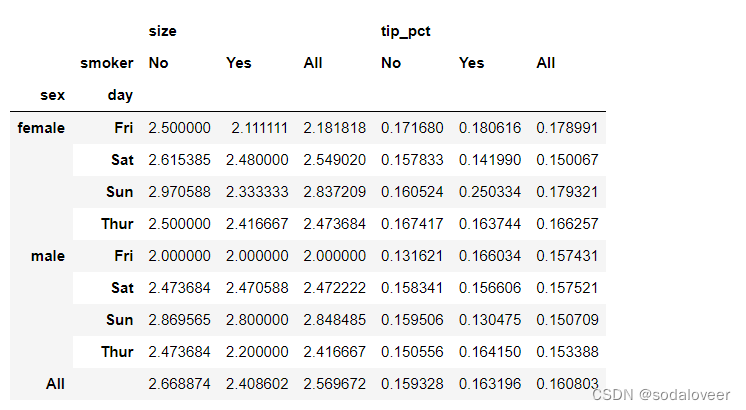
参数margins:margins=True 添加分项小计,这将会添加标签为all的行和列,其值对应单个等级中所有数据的分组统计,all值为平均值。
tips.pivot_table(['tip_pct','size'],index=['sex ','day'],columns='smoker',margins=True)
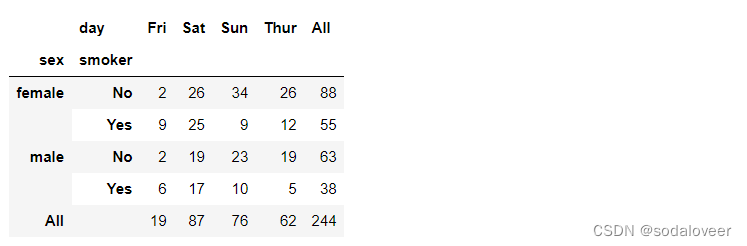
参数aggfunc:要使用其他的聚合函数,将其传给aggfunc即可,用len或count可以得到有关分组大小的交叉表。
tips.pivot_table('tip_pct',index=['sex ','smoker'],columns='day',aggfunc=len,margins=True)
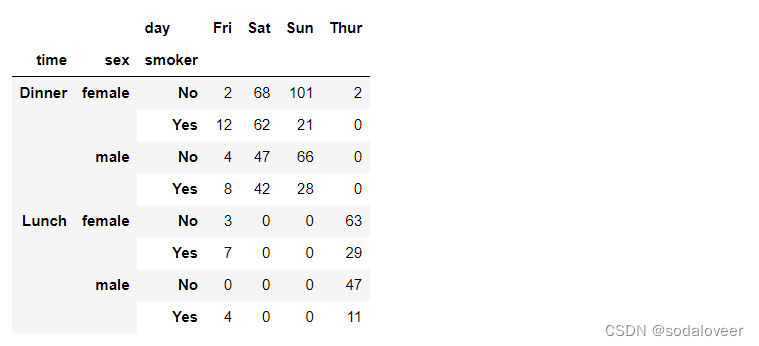
参数fill_value:fill_value可以填补空值(NA)
tips.pivot_table('size',index=['time','sex ','smoker'],columns='day',aggfunc='sum',fill_value=0)
二、crosstab 交叉表
交叉表作为一种特殊的透视表,用于计算分组频率的特殊透视表。
语法:
crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins: ‘bool’ = False, margins_name: ‘str’ = ‘All’, dropna: ‘bool’ = True, normalize=False)
参数解析:
- index:接收string、数组、Series或数组list,表示行索引键,无默认。
- columns:接收string、数组、Series或数组list,表示列索引键,无默认。
- values:接收array,表示聚合数据,置信为None。
- rownames:表示行分组键名,无默认。
- colnames:表示列分组键名,无默认。
- aggfunc:接收function,表示聚合函数,默认为None。
- margins:布尔值,默认为True。表示汇总(total)功能的开关,设置为True后,结果集中会出现名为"ALL"的行和列。
- margins_name:设置总计行(列)的名称(默认名称是“All”)
- dropna:布尔值,表示是否对值进行标准化,默认为False。
- normalize:布尔值,表示是否对值进行标准化,默认为False。
举例:
import numpy as np
data = pd.DataFrame({"Sample":np.arange(10),"Gender":np.random.choice(("Female","Male"),10),"Handedness":np.random.choice(("Right-handed","Left-handed"),10)})
data

根据性别和用手习惯对这段数据进行统计汇总。
import pandas as pd
pd.crosstab(data["Gender"],data["Handedness"],margins=True)

三、实际应用
示例1:数据聚合与分组实际应用
数据集情况:
import pandas as pd
fec=pd.read_csv('F:\\pydata-book-2nd-edition\\datasets\\fec\\P00000001-ALL.csv')
fec.shape #(1001731, 16)
fec.columns

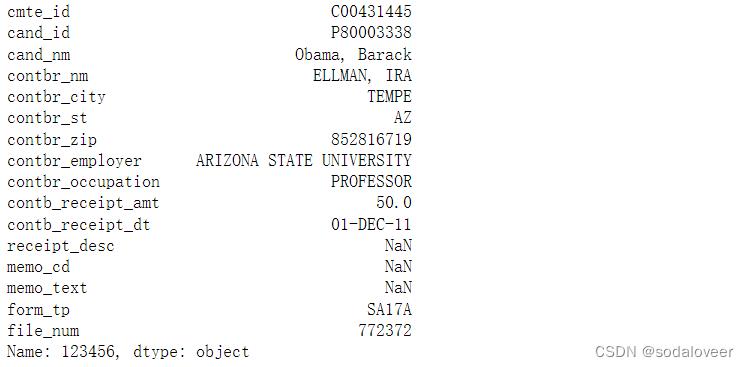
fec.iloc[123456]
- 分析1: 获取全部的候选人的名单
uniques_cands=fec.cand_nm.unique()
uniques_cands
uniques_cands[2]

- 分析2: 补充党派信息
第一步:利用字典说明党派关系。
parties={'Bachmann, Michelle':'Republican',
'Romney, Mitt':'Republican',
'Obama, Barack':'Democrat',
"Roemer, Charles E. 'Buddy' III":'Republican',
'Pawlenty, Timothy':'Republican',
'Johnson, Gary Earl':'Republican',
'Paul, Ron':'Republican',
'Santorum, Rick':'Republican',
'Cain, Herman':'Republican',
'Gingrich, Newt':'Republican',
'McCotter, Thaddeus G':'Republican',
'Huntsman, Jon':'Republican',
'Perry, Rick':'Republican'}
第二步:通过映射以及series对象的map方法,你可以根据候选人姓名得到一组党派信息,将其添加一个新列。
fec['party']=fec.cand_nm.map(parties)
fec['party'].value_counts()

数据集中“contb_receipt_amt”既包括退款也包括赞助,因此限定数据集只有正的出资额。
(fec["contb_receipt_amt"]>0).value_counts()
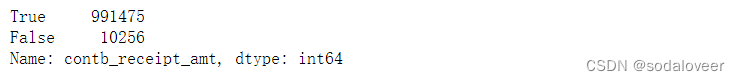
fec=fec[fec["contb_receipt_amt"]>0]
- 分析3: 根据职业和雇主统计赞助信息
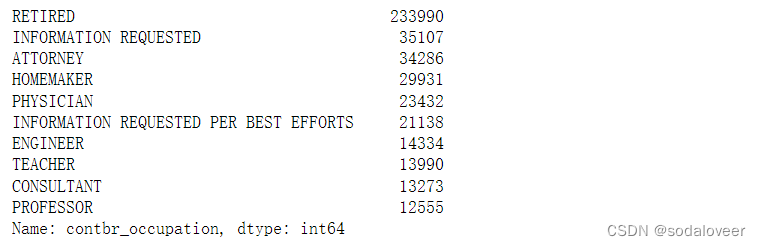
第一步:根据职业计算出资总额。
fec["contbr_occupation"].value_counts()[:10]
第二步:对职业信息、雇主信息进行映射。
occ_mapping={'INFORMATION REQUESTED':'NOT PROVIDED','INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED','INFORMATION REQUESTED(BEST EFFORTS)':'NOT PROVIDED','C.E.O':'CEO'}
#如果没有映射消息则返回x
f=lambda x:occ_mapping.get(x,x)
fec["contbr_occupation"]=fec["contbr_occupation"].map(f)
emp_mapping={'INFORMATION REQUESTED':'NOT PROVIDED','INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED','SELF':'SELF-EMPLOYED','SELF EMPLOYED':'SELF-EMPLOYED'}
f=lambda x:emp_mapping.get(x,x)
fec["contbr_employer"]=fec["contbr_employer"].map(f)
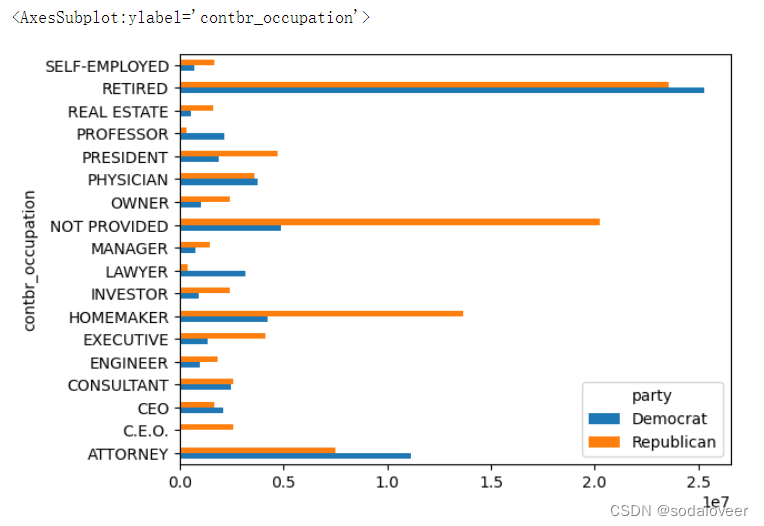
第三步:根据党派和职业对数据进行聚合,过滤掉总出资额不足200万美元的数据,生成透视表。
by_occupation = pd.pivot_table(fec,values='contb_receipt_amt',index='contbr_occupation',columns='party',aggfunc="sum")
第四步:生成柱状图
over_2mm = by_occupation[by_occupation.sum(1)>2000000]
over_2mm
over_2mm.plot(kind='barh')
- 分析4: 总出资额最高的职业和企业
求最大值方法
def get_top_amounts(group,key,n=5):
totals=group.groupby(key)['contb_receipt_amt'].sum()
return totals.sort_values(ascending=False)[n:] #根据key对totals进行降序排列
根据职业和雇主进行聚合
fec_mrbo=fec[fec['cand_nm'].isin(['Obama, Barack','Romney, Mitt'])]
grouped=fec_mrbo.groupby('cand_nm')
grouped.apply(get_top_amounts,'contbr_occupation',n=7)#get_top_amounts函数的参数值
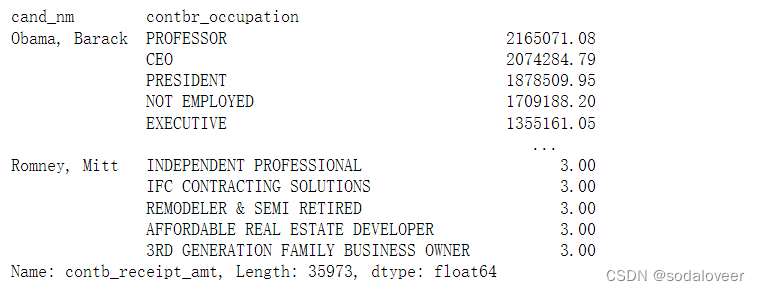
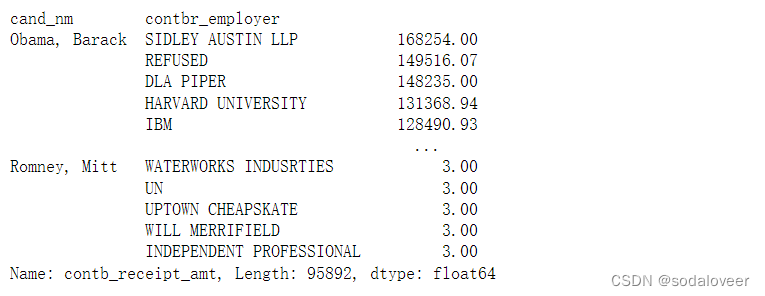
grouped.apply(get_top_amounts,'contbr_employer',n=10)
- 分析5: 对出资额分组
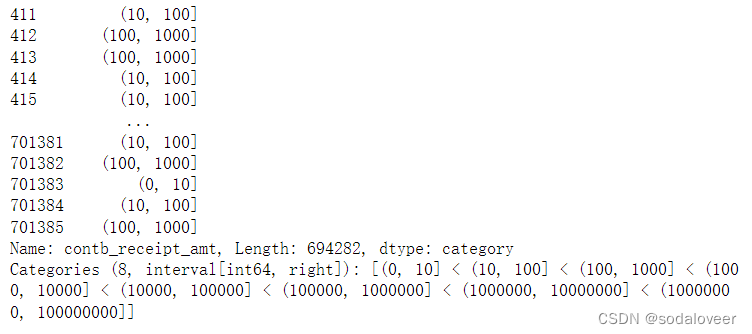
第一步:利用cut函数根据出资额大小将数据离散到多个面元中。
bins=np.array([0,10,100,1000,10000,100000,1000000,10000000,100000000])
labels=pd.cut(fec_mrbo.contb_receipt_amt,bins)
labels
第二步:根据候选人的姓名以及面元标签对数据进行分组。
grouped=fec_mrbo.groupby(['cand_nm',labels])
grouped.size().unstack(0)
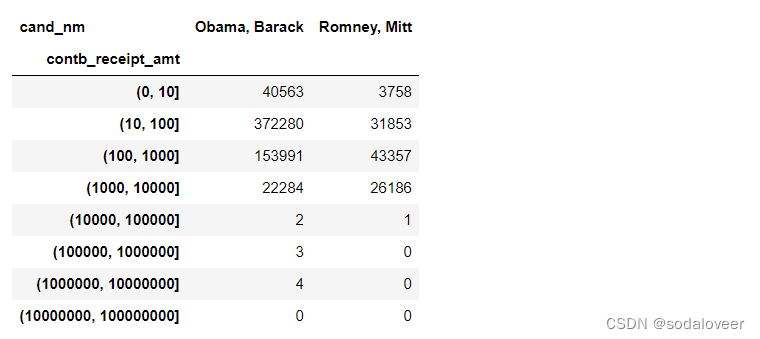
可以看到obama在小额赞助的数量比romney多得多。
第三步:对出资额求和并在面元内规格化,以便图形化显示两位候选人各种赞助额度的比例:
bucket_sums=grouped.contb_receipt_amt.sum().unstack(0)
bucket_sums
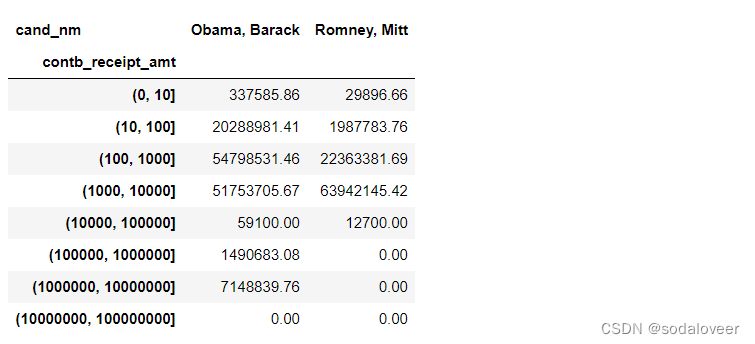
数据按行求频率如下:
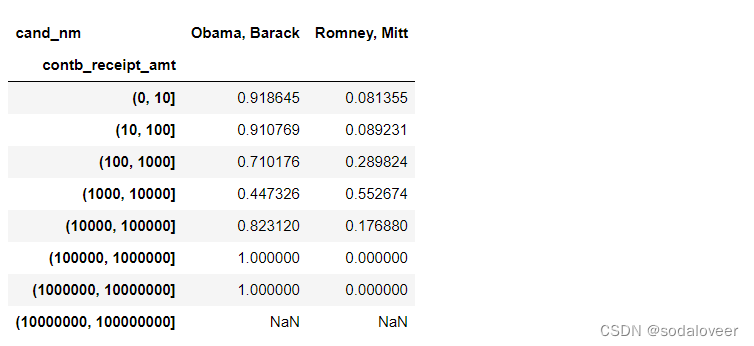
normed_sums=bucket_sums.div(bucket_sums.sum(axis=1),axis=0)
normed_sums
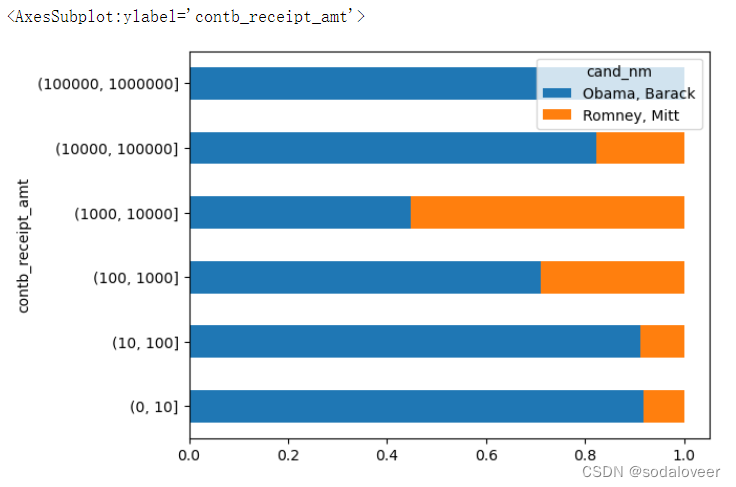
两位候选人收到的各种捐赠额度的总额比例:
normed_sums[:-2].plot(kind='barh',stacked=True) #排除了两具最大的面元。
- 分析6: 根据州统计赞助信息
第一步:根据候选人和州对数据进行聚合。
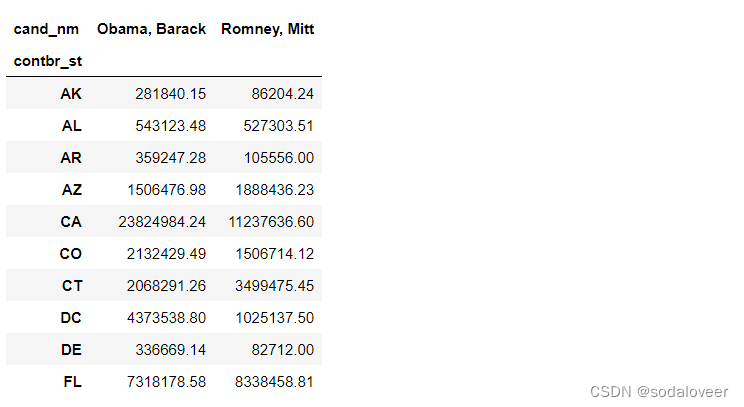
grouped=fec_mrbo.groupby(['cand_nm','contbr_st'])
totals=grouped.contb_receipt_amt.sum().unstack(0).fillna(0)
totals=totals[totals.sum(1)>100000]
totals[:10]
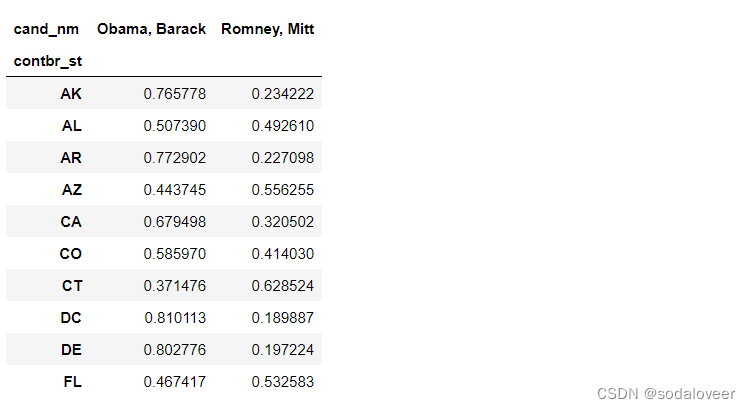
第二步:对各行除以总赞助额,就会得到各候选人在各州的总赞助额比例。
percent=totals.div(totals.sum(1),axis=0)
percent[:10]








![【uniapp】阿里云OSS上传 [视频上传]](https://img-blog.csdnimg.cn/direct/4bdce6e7a00c40ff97806453e88bbe85.png)