目录
摘要
Abstract
文献阅读:基于CNN-LSTM-AM时空深度学习模型的城市供水预测
现存问题
提出方法
创新点
方法论
CNN-LSTM-AM模型
研究实验
数据集
预处理
评估指标
实验过程
合格性验证
模型实现
总结
摘要
本周阅读的文献《Urban Water Supply Forecasting Based on CNN-LSTM-AM Spatiotemporal Deep Learning Model》中,提出了一种时空深度学习模型CNN-LSTM-AM。首先通过CNN识别供水系统中的潜在模式结构,自动提取供水数据的空间特征;其次,将贝叶斯算法和AM引入LSTM网络,实现LSTM网络参数的自动选择和对时间序列数据的自主权值分配,突出重要信息的影响。该模型实现了时空特征的自动提取,对相关供水信息进行了深入挖掘,得到了高精度的预测结果。实验结果表明,提出的CNN-LSTM-AM模型不仅增强了LSTM网络中时间序列相关性信息的捕获和表示,而且提高了模型的训练速度和精度。
Abstract
The literature "Urban Water Supply Forecasting Based on CNN-LSTM-AM Spatial Deep Learning Model" read this week ,proposes a spatiotemporal deep learning model, CNN-LSTM-AM. Firstly, CNN is used to identify potential pattern structures in the water supply system and automatically extract spatial features of water supply data; Secondly, the Bayesian algorithm and AM are introduced into the LSTM network to achieve automatic parameter selection and autonomous weight allocation of time series data, highlighting the influence of important information. This model achieves automatic extraction of spatiotemporal features, conducts in-depth mining of relevant water supply information, and obtains high-precision prediction results. The experimental results show that the proposed CNN-LSTM-AM model not only enhances the capture and representation of time series correlation information in LSTM networks, but also improves the training speed and accuracy of the model.
文献阅读:基于CNN-LSTM-AM时空深度学习模型的城市供水预测
Urban Water Supply Forecasting Based on CNN-LSTM-AM Spatiotemporal Deep Learning Model![]() https://ieeexplore.ieee.org/document/10366225PDF:IEEE Xplore Full-Text PDF:
https://ieeexplore.ieee.org/document/10366225PDF:IEEE Xplore Full-Text PDF:
现存问题
城市供水状况受环境气候、政策管理、经济发展、人口规模、生活习惯等诸多因素的影响,其实际变化是线性和非线性的结合,呈现出规律性和随机性,因此供水量预测的特征提取和非线性映射具有挑战性。单个LSTM模型不能同时获得数据中固有的时空特征信息数据,使得高预测精度和广泛化性的实现要求难以满足。
提出方法
提出了一种结合卷积神经网络(CNN)、长短期记忆网络(LSTM)和注意力机制(AM)的时空深度学习模型,用于城市日供水量的预测。该模型旨在提高供水预测的准确性和效率,对城市供水管理具有重要意义。本文提出了一种CNN-LSTM-AM时空深度学习模型,通过充分利用CNN提取数据空间特征、LSTM挖掘时间依赖关系以及注意力机制增强关键信息权重的优势,在城市供水预测任务上取得了良好的效果,这为进一步优化城市供水管理、实现供水资源的合理配置提供了新的思路和方法。
创新点
一、将CNN和LSTM两种深度学习模型结合,充分利用CNN在空间特征提取和LSTM在时间特征挖掘方面的优势,构建了一个时空深度学习框架。单独使用CNN或LSTM都难以同时兼顾数据的空间关联性和时序依赖性,而将二者结合则可以更全面地建模城市供水数据的内在规律。
二、在LSTM网络中引入了注意力机制。传统的LSTM网络在训练过程中容易忽略不同时间节点的重要程度差异,而注意力机制可以自适应地调整不同时刻隐藏层输出的权重,突出关键时刻的作用,削弱非重点时刻的干扰,使得模型更聚焦于影响未来供水量的关键因素。这不仅提高了预测精度,也增强了模型的可解释性。
三、采用贝叶斯优化算法来搜索LSTM网络的最优超参数。深度学习模型的性能对超参数较为敏感,传统的网格搜索和随机搜索方法效率较低。而贝叶斯优化通过构建目标函数的概率模型,利用先验知识引导下一个采样点的选择,在有限的尝试次数内找到最优解,可以大大提升超参数寻优的效率。
方法论
卷积神经网络是具有可学习权重和偏置常数的神经元,由一个或多个卷积层,池化层和全连接层组成。CNN的特点是局部连接,权重共享,池化操作和多层结构。它可以提取数据的局部特征,降低网络训练的难度,实现数据降维,并将低层局部特征联合收割机组合成高层特征。
卷积层是CNN的核心,其思想主要是通过卷积运算提取局部特征的重要部分。卷积滤波器沿着输入数据的所有维度移动,计算输入的权重和点积,然后将其作为新序列的一部分输出。以大小为10的时间窗口为例,如图所示,卷积核的数目直接影响特征提取的抽象性,但过多的卷积核会导致资源的浪费。池化层主要涉及通过最大(Max)或平均(AVG)池化对卷积学习特征图进行子采样。前者输出窗口的最大值,后者输出窗口的平均值。池化层的意义在于它能够降低后续网络层的输入维度,减小模型的大小,提高计算速度,并提高特征映射的鲁棒性以防止过拟合。
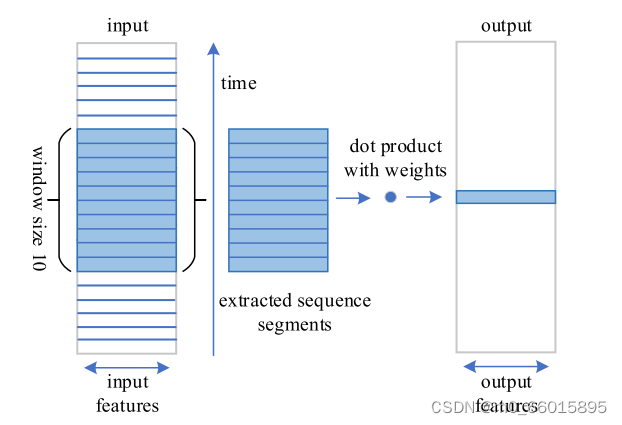
在预测领域,CNN可以自动提取数据的空间特征,完成模型拟合。如果将CNN提取的空间特征作为LSTM模型的输入作为训练数据,则可以同时考虑供水系统空间分布的结构和特征,并可以充分提取供水数据变化过程的时间序列依赖性。
在神经网络的学习过程中,加入模型参数可以增强模型的表达能力,存储更多的信息。然而,这种方法也会导致信息过载。AM 基本上实现了对信息重要性的评估和权衡。在训练过程中,不同时间节点的重要性和时间序列数据的特性很容易被LSTM网络忽略。在LSTM网络中加入AM,使得LSTM可以专注于众多输入信息中对当前任务至关重要的信息,减少对其他非重要信息的关注,甚至过滤掉不相关的信息。这种方法不仅解决了信息过载的问题,而且实现了CNN-LSTM的时空可解释性,从而提高了预测的准确性和泛化能力。
CNN-LSTM-AM模型
CNN-LSTM-AM时空深度学习模型利用CNN来提取供水数据中不同特征值之间的空间连接,从而弥补LSTM在捕获数据空间分量方面的不足。AM使LSTM网络能够区分不同供水时间点对未来供水预测的影响,增加关键信息的权重比例,降低非重要信息的权重。该模型能够挖掘存在于大量历史供水数据中的隐含特征,对这些非线性关系进行学习和建模,有效处理长期依赖和短期变化的时空关系,捕捉供水内部因素的复杂性。
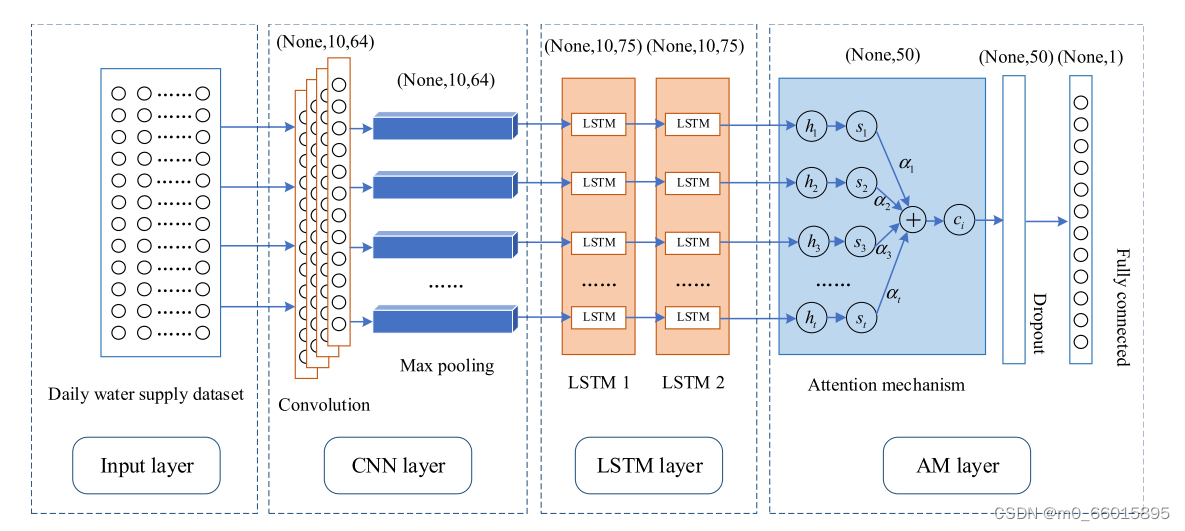
- 第一层是输入层。对城市供水历史运行数据进行分析,由输入层指定输入格式,数据又被馈送到CNN层。
- 第二层是CNN层。采用一维CNN来识别供水系统中的潜在模式结构,自动提取供水数据的空间特征。CNN层主要包括卷积和池化操作,将供水样本数据划分为三列数据矩阵,输入数据采用每次10个供水时间序列数据的滑动窗口形式,形成10 × 3向量。将10 × 3矢量变换成数据特征图,然后进行卷积运算。卷积由一组滤波器组成。滤波器的深度由输入样本数据的深度决定,可以提取不同粒度的特征。通过池化减少卷积层输出的特征向量,减少了数据的空间大小,提高了空间特征提取的鲁棒性。
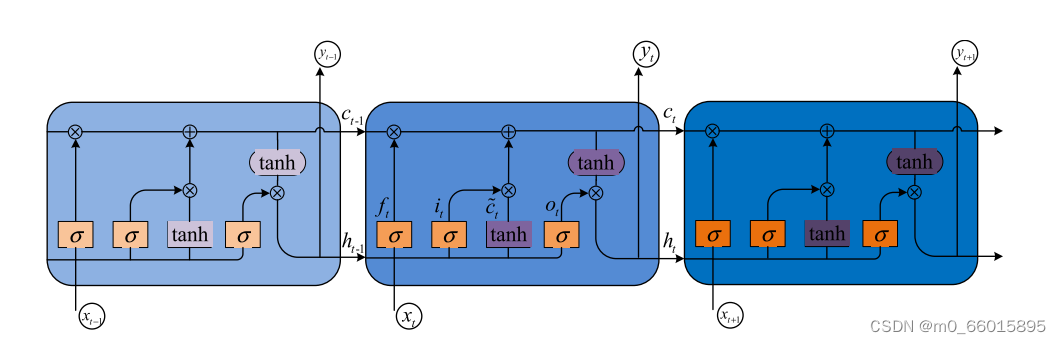
- 第三层是LSTM层。在Reshape操作之后,将CNN输出的特征向量构建成时间序列形式,作为LSTM网络的输入,并使用贝叶斯算法对LSTM网络的参数进行搜索和优化。LSTM网络具有记忆功能,用于提取供水数据的非线性时序变化,通过学习和处理其隐含层的特殊结构,控制历史供水信息的传递,挖掘其时间变化规律。
- 第四层是AM层。注意力机制本质上是对信息重要性的评估和权衡,使得模型可以集中关注对当前任务至关重要的信息。这不仅解决了信息过载问题,还增强了模型的可解释性。一方面,AM采用概率加权机制来促进LSTM网络的信息提取,集中在预测任务最重要的时间序列上,最终提高预测精度。另一方面,通过全连通层进行特征合成和维度转换,通过一系列的模型训练学习供水数据,并最终输出预测值。
研究实验
数据集
研究实例选取了中国湖南省株洲市两个不同水厂的日供水量(不考虑其他影响因素),即分别来自水厂A和B的出水表的总读数。自来水厂A共采集2007年1月1日至2012年6月22日供水数据样本2000份,自来水厂B共采集2007年1月1日至2016年12月5日供水数据样本3627份。
预处理
首先,对原始数据进行清理,以消除缺失或异常样本。其次,供水数据平滑和去噪Savitzky-Golay滤波。随后,采用最大-最小归一化方法对数据集进行标准化,降低计算复杂度和加速模型训练。
评估指标
以平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和决定系数(R2)为评价指标,对模型的预测效果进行定量验证。MAE响应于预测误差的平均值,MSE指示预测值与真实值之间的差的平方和的平均值,并且RMSE测量预测值与真实值的偏差。三个误差值越小,预测结果越准确。R2的值在[0,1]中。通常,R2值越接近1,模型拟合越好。
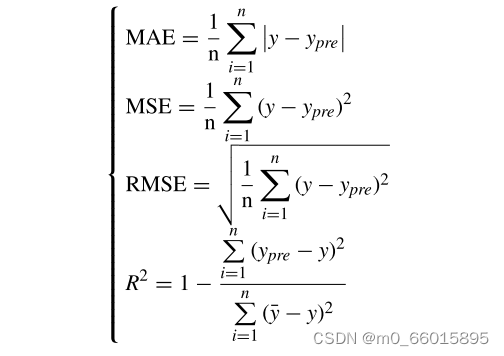
实验过程
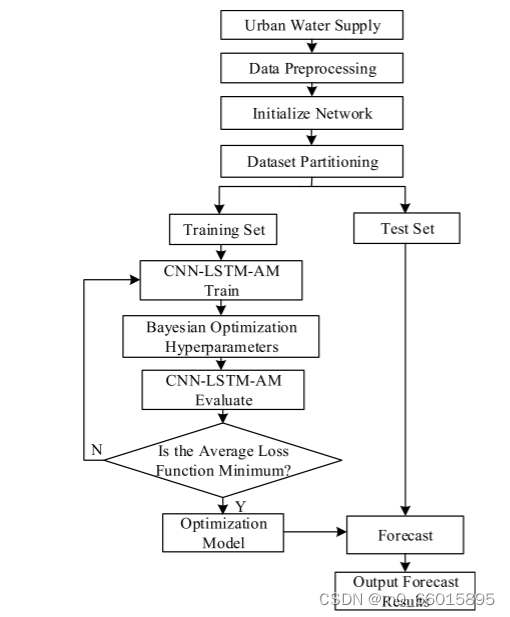
提出了一种基于CNN-LSTM-AM的城市供水预测时空特征提取模型。流程图如图所示,具体步骤如下:
- 供水数据选择数据集的两组数据用于该实验
- 在对数据进行预处理后,将其以8:2的比例分为训练集和测试集。在这种情况下,自来水厂A中的1600个数据被用作训练样本,其余400个数据被用作测试样本。然后,以自来水厂B中的2901个数据作为训练样本,其余726个数据作为测试样本。选取训练集中的数据进行训练和学习,并利用测试集中的数据检验模型的预测精度。
- 将训练集中的供水数据输入到构建的CNN-LSTM-AM模型中进行训练和学习,以优化模型。
- 可以使用贝叶斯优化算法搜索LSTM网络的最佳超参数,并使用K折交叉验证评估每组超参数。
- 对训练后的每组超参数计算平均损失函数值,选取平均损失函数值最小的超参数集作为该模型中LSTM网络的最优超参数,得到最优预测模型。
- 将测试集数据作为训练好的CNN-LSTM-AM模型的输入进行预测,并输出最终的预测值。根据预测值和真实值计算出预测结果的评价指标。
合格性验证
一、预测值拟合与散点图
为了说明所提出的算法的有效性,将所提出的CNN—LSTM—AM模型与传统的LSTM模型和组合的CNN—LSTM和LSTM—AM模型进行了比较。左(a)中比较了不同模型中的自来水厂A的预测结果,左图(B)中CNN—LSTM—AM模型中自来水厂A的预测值和真值的散点图。不同模型下的自来水厂B的预测结果预测结果比较见右图(a),CNN—LSTM—AM模型下的自来水厂B预测值与真值散点图见右图(B)。

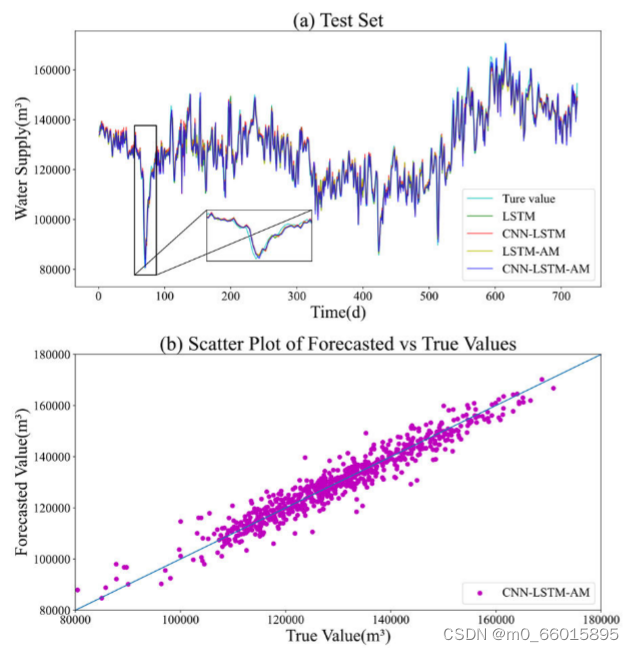
如左图(a)所示,四种模型均具有较好的预测性能,预测曲线能较好地反映真实曲线的变化趋势。尽管如此,当供水量发生突然变化时,如左图(a)和右图(a)中的峰和角,单个LSTM模型无法准确及时地跟随供水量真值的变化进行调整,导致预测误差较大。CNN-LSTM和LSTM-AM模型比单个LSTM模型更好地跟踪供水量真实值的变化,反映出更少的偏差。然而,CNN-LSTM-AM模型更准确地预测了供水量真实值的变化,在一些波动较大的点上拟合得更好,特别是在峰和角点。模型的预测曲线与真实曲线基本吻合,准确捕捉到了数值的微小变化。图中散点图说明了预测值和真实值之间的相关性。从散点图可以看出,预测值与真值基本一致,散点集中分布在直线附近,所提出的CNN-LSTM-AM模型具有强大的学习和预测能力。
二、指标评估
利用MAE、MSE、RMSE和R2等评价指标,在两个测试集上对四种模型的预测结果进行了比较。通过取10次运行的平均值来确定每个指数的最终值。
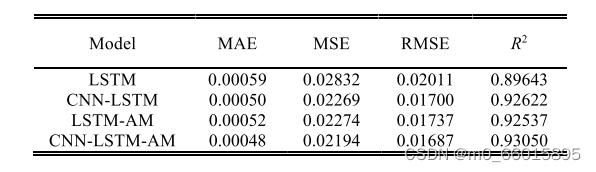
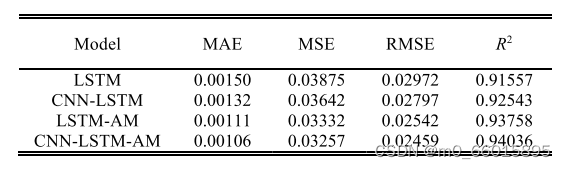
不同模型中水厂A和B的MAE、MSE、RMSE和R2值分别见表,在自来水厂 A中MAE分别降低18.6%、4%和7.6%;MSE分别降低22.5%、3.3%和3.5%;RMSE分别降低16.1%、0.7%和2.8%;R2分别提高3.8%、0.4%和0.5%。在自来水厂B中,MAE分别降低了29.3%、19.6%和4.5%;MSE分别降低了15.9%、10.5%和2.2%;RMSE分别降低了17.2%、12.0%和3.2%;R2分别提高了2.7%、1.6%和0.2%。从MAE、MSE、RMSE和R2指标的值可以看出,该模型的预测误差小于其他三种模型。历史供水数据隐含着温度、湿度、节假日等相关因素的影响,具有一定的复杂性和不确定性。在复杂城市供水量的预测过程中,CNN—LSTM—AM模型能够更好地挖掘历史数据中隐含的特征,捕捉数据的变化规律,获得更好的预测结果。
模型实现
一、实现步骤
1、CNN对输入数据进行卷积和池化操作,提取空间局部特征:
Feature_CNN = CNN(Input_Data)2、使用贝叶斯优化器进行调参
def model_tuning():
tuner = BayesianOptimization(
create_model,
objective='val_accuracy',
max_trials=10,
executions_per_trial=2,
directory='model_tuning',
project_name='cnn_lstm_am'
)
tuner.search(x_train, y_train, epochs=10, validation_data=(x_val, y_val), callbacks=[EarlyStopping(monitor='val_loss', patience=3)])
best_model = tuner.get_best_models(num_models=1)[0]
return best_model3、将CNN提取的特征重塑为时间序列格式,送入LSTM学习时间依赖关系:
H_LSTM = LSTM(Feature_CNN)其中LSTM的计算过程可以表示为:
f_t = σ(W_f * [h_{t-1}, x_t] + b_f)
i_t = σ(W_i * [h_{t-1}, x_t] + b_i)
o_t = σ(W_o * [h_{t-1}, x_t] + b_o)
C_t = f_t * C_{t-1} + i_t * tanh(W_C * [h_{t-1}, x_t] + b_C)
h_t = o_t * tanh(C_t)其中W_f, W_i, W_o, W_C分别为遗忘门、输入门、输出门、候选记忆状态的权重矩阵,h为隐藏状态,C为记忆状态。
4、对LSTM各时间步的隐藏状态计算注意力权重,并加权求和。
a_t = softmax(v * tanh(W_a * h_t + b_a))
Context_Vector = sum(a_t * h_t)其中v、W_a、b_a为注意力机制的可学习参数。
5、将注意力加权后的上下文向量送入全连接层,输出最终的预测结果:
Prediction = Dense(Context_Vector)6、损失函数采用均方误差MSE:
Loss = MSE(Prediction, Target)7、使用Adam优化器最小化损失函数,更新模型参数:
Params = Adam.minimize(Loss)重复以上过程,直至模型收敛或达到预设的迭代次数。
二、代码分析
模型的预测性能和泛化能力与网络层数成正比,一般来说,增加网络层数可以增加模型的容量和表达能力,提高训练数据的拟合度。此外,过多的网络层数容易导致过拟合,从而降低模型在测试集上的性能,降低泛化能力,并占用大量的计算资源。考虑到在这项研究中选择的历史供水量作为输入变量,模型的每个网络层采用一个层,使用单层CNN网络提取数据的空间特征,使用单层LSTM网络来提取数据的时间特,一个单层的AM网络用于权重分配。
import tensorflow as tf
# 定义超参数
input_size = 10
time_steps = 30
hidden_size = 64
attention_size = 32
output_size = 1
# 定义输入占位符
input_data = tf.placeholder(tf.float32, [None, time_steps, input_size])
target_data = tf.placeholder(tf.float32, [None, output_size])
# 定义CNN层
conv1 = tf.layers.conv1d(inputs=input_data, filters=32, kernel_size=3, activation=tf.nn.relu)
conv2 = tf.layers.conv1d(inputs=conv1, filters=64, kernel_size=3, activation=tf.nn.relu)
cnn_output = tf.layers.flatten(conv2)
# 重塑CNN输出为时间序列格式
lstm_input = tf.reshape(cnn_output, [-1, time_steps, hidden_size])
# 定义LSTM层
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_size)
outputs, states = tf.nn.dynamic_rnn(lstm_cell, lstm_input, dtype=tf.float32)
# 定义注意力层
attention_weights = tf.layers.dense(outputs, attention_size, activation=tf.nn.tanh)
attention_weights = tf.layers.dense(attention_weights, 1, activation=None)
attention_weights = tf.nn.softmax(attention_weights, axis=1)
context_vector = tf.reduce_sum(attention_weights * outputs, axis=1)
# 定义输出层
predictions = tf.layers.dense(context_vector, output_size)
# 定义损失函数和优化器
loss = tf.losses.mean_squared_error(target_data, predictions)
optimizer = tf.train.AdamOptimizer().minimize(loss)代码解释:
定义输入占位符,包括输入数据(形状为[batch_size, time_steps, input_size])和目标数据(形状为[batch_size, output_size])。
构建CNN层,这里使用了两层一维卷积,用于提取输入数据的局部特征。卷积结果经过flatten操作转为一维向量。
将CNN提取的特征重塑为时间序列格式,送入LSTM层。这里使用了基本的LSTM单元,通过dynamic_rnn实现变长序列的计算。
构建注意力层,先对LSTM的输出进行一次全连接得到注意力权重的中间表示,再通过一次全连接和softmax归一化得到不同时刻的注意力权重。最后通过注意力权重对LSTM输出进行加权求和,得到聚合的上下文向量。
将上下文向量通过全连接层映射到输出空间,得到最终的预测值。
定义损失函数为预测值
总结
文章通过大量实验论证了所提出CNN-LSTM-AM模型的优越性,但仍存在一些不足和改进空间:
(1)实验数据仅局限于单一城市,模型的泛化能力有待进一步验证。不同城市在地理环境、人口结构、产业布局等方面存在差异,这些差异可能影响模型的预测表现。
(2)模型目前仅考虑了历史供水量时间序列,而影响城市用水的因素是多方面的。如何将天气、温度、节假日、经济指标等外部因素引入模型,建立更综合的用水预测框架。可以考虑将这些异构数据通过数据融合、特征组合等方式与供水数据集成,扩充模型的输入维度。
(3)最模型解释性有待加强。目前注意力机制可以定性地揭示不同时间步的重要程度,但针对水务的特点,需要给出更直观、可操作的决策依据。


![【uniapp】阿里云OSS上传 [视频上传]](https://img-blog.csdnimg.cn/direct/4bdce6e7a00c40ff97806453e88bbe85.png)