CRNN网络结构
论文地址:https://arxiv.org/pdf/1507.05717
参考:https://blog.csdn.net/xiaosongshine/article/details/112198145
git:https://github.com/shuyeah2356/crnn.pytorch
CRNN文本识别实现端到端的不定长文本识别。
CRNN网络把包含三部分:卷积层(CNN)、循环层(RNN)和转录层(CTC loss)
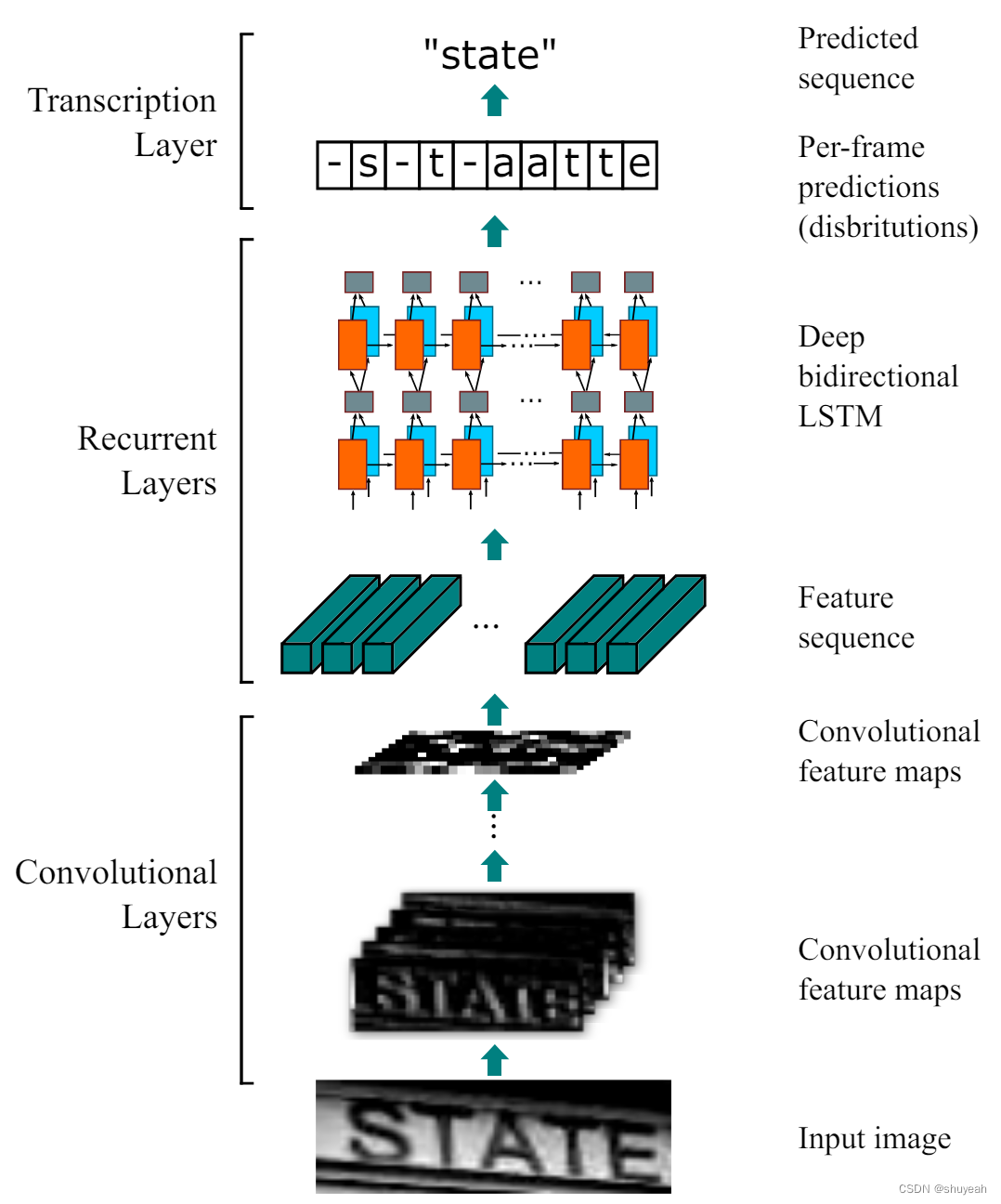
1、卷积层::通过深层卷积操作对输入图像做特征提取,得到特征图;
2、循环层: 循环层使用双向LSTM(BLSTM)对特征序列进行预测,对序列中的每一个特征向量进行学习,并输出预测标签(真实值)的分布;
3、转录层:转录层使用CTC loss ,把循环层获取的一系列标签分布转换成最终的标签序列。
对于输入图片:
输入图像为灰度图(单通道);
高度为32,经过卷积处理后高度变为1;
输入图片宽度为100,输入图片大小为(100,32,1)
CNN输出尺寸为(512, 1, 40),卷积操作输出512个特征图,每一个特征图高度为1,宽度为26。
在代码中有判断图片的高度能够被16整除。
assert imgH % 16 == 0
1、CNN
卷积层用来提取文图像的特征,堆叠使用卷积层和最大池化层,特别的,最后两个最大池化层在宽度和高度上的步长是不相等的池化的窗口尺寸是(w,h):(1,2),因为待识别的文本图片多数是高较小而宽较长,使用1×2的池化窗口尽量不丢失在宽度方向的信息。
卷积操作的具体实现代码:
# 输入图片大小为(160,32,1)
assert imgH % 16 == 0, 'imgH has to be a multiple of 16 图片高度必须为16的倍数'
# 一共有7次卷积操作
ks = [3, 3, 3, 3, 3, 3, 2] # 卷积层卷积尺寸3表示3x3,2表示2x2
ps = [1, 1, 1, 1, 1, 1, 0] # padding大小
ss = [1, 1, 1, 1, 1, 1, 1] # stride大小
nm = [64, 128, 256, 256, 512, 512, 512] # 卷积核个数,卷积操作输出特征层的通道数
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False): # 创建卷积层
nIn = nc if i == 0 else nm[i - 1] # 确定输入channel维度,如果是第一层网络,输入通道数为图片通道数,输入特征层的通道数为上一个特征层的输出通道数
nOut = nm[i] # 确定输出channel维度
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i])) # 添加卷积层
# BN层
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
# Relu激活层
if leakyRelu:
cnn.add_module('relu{0}'.format(i),
nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
# 卷积核大小为3×3,s=1,p=1,输出通道数为64,特征层大小为100×32×64
convRelu(0)
# 经过2×2Maxpooling,宽高减半,特征层大小变为50×16×64
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2))
# 卷积核大小为3×3,s=1,p=1,输出通道数为128,特征层大小为50×16×128
convRelu(1)
# 经过2×2Maxpooling,宽高减半,特征层大小变为25×8×128
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2))
# 卷积核大小为3×3,s=1,p=1,输出通道数为256,特征层大小为25×8×256,卷积后面接BatchNormalization
convRelu(2, True)
# 卷积核大小为3×3,s=1,p=1,输出通道数为256,特征层大小为25×8×256
convRelu(3)
# 经过MaxPooling,卷积核大小为2×2,在h上stride=2,p=0,s=2,h=(8+0-2)//2+1=4,w上的stride=1,p=1,s=1,w=(25+2-2)//1+1=26通道数不变,26×4×256
cnn.add_module('pooling{0}'.format(2),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 参数 (h, w)
# 卷积核大小为3×3,s=1,p=1,输出通道数为512,特征层大小为50×16×512,卷积后面接BatchNormalization
convRelu(4, True)
# 卷积核大小为3×3,s=1,p=1,输出通道数为512,特征层大小为26×4×512
convRelu(5)
# 经过MaxPooling,卷积核大小为2×2,在h上stride=2,p=0,s=2,h=(4+0-2)//2+1=2,w上的stride=1,p=1,s=1,w=(26+2-2)//1+1=27通道数不变,27×2×512
cnn.add_module('pooling{0}'.format(3),
nn.MaxPool2d((2, 2), (2, 1), (0, 1)))
# 卷积核大小为2×2,s=1,p=0,输出通道数为512,特征层大小为26×1×512
convRelu(6, True)
对应的网络结构:
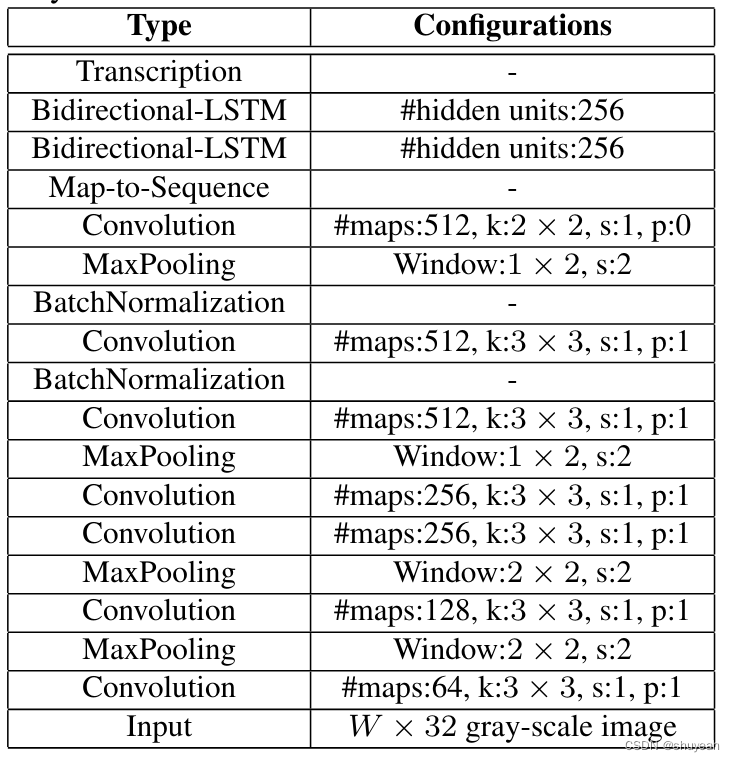
这里卷积操作后的特征图大小为26×1×512
2、RNN
对于卷积操作输出的结果经过处理之后才能输入到RNN中。
卷积操作输出的特征图高度一定为1,代码中也做约束
assert h == 1
将h,w维度合并,合并后的维度变为输入到RNN中的时间不长(time_step),每一个序列的长度为原始特征层的通道数512
输入到LSTM中的特征图大小是多少(面试被问到的问题):
每次输入到LSTM中的特征,时间不长的数量为原始特征的h×w(26),每次输入一个序列,序列长度为原始特征层的通道数512
def forward(self, input):
# conv features
conv = self.cnn(input)
b, c, h, w = conv.size()# batch_size,512,1,26
assert h == 1, "the height of conv must be 1"
# 将宽高维度合并,特征层大小为(batch_size, 512, 26)
conv = conv.squeeze(2)
# 维度顺序调整(26, batch_size, 512),w作为时间步长(作为LSTM中的一个时间不长time_step)
conv = conv.permute(2, 0, 1)
# rnn features
output = self.rnn(conv)
# print(output.size())
return output
序列是按照列从左到右生成的,每一列包含512为特征,输入到LSTM中的第i个特征是特征图第i列像素的连接。

对于卷积操作、Maxpooling层和BatchNormalization卷积操作具有平移不变性。每一个从左到右的序列对应原始图像中的一个矩形区域,且顺序是对应的。特征序列中的每一个向量对一个原图中的一个感受野。

将特征序列按照time_step输入到RNN中,RNN隐藏层的神经元数量为256,使用多层的双向LSTM。
输入时间不长的数量为26,经过RNN得到26个特征向量,输出特征向量的类别分类结果。
每一个特征向量对应的是原图中的一个小的矩形区域。RNN来判断这个矩形区域属于哪个字符。
根据输入的特征向量得到所有字符的softmax概率分布,这是一个长度为待识别字符类别总数量的向量,RNN的输出向量作为转录层CTC的输入。
LSTM实现的代码:
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True) # nIn:输入神经元个数
# *2因为使用双向LSTM,将双向的隐藏层单元拼接在一起,两层个256单元的双向LSTM
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
# 经过RNN输出feature map特征结果
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size() # T:时间步长,b:batch size,h:hiden unit
t_rec = recurrent.view(T * b, h)
# 第一次LSTM得到特征层[26×256,256],view成[26, 256, 256]
# 第二次LSTM得到特征层[26×256,num_class],view成[26, 256, num_class]
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return output
# nh为隐藏层神经节点数,nclass为所有识别字符的类别总数
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh), # 输入的时间步长为512
BidirectionalLSTM(nh, nh, nclass))
第一次LSTM得到特征层[26×256,256],view成[26, 256, 256]
第二次LSTM得到特征层[26×256,num_class],view成[26, 256, num_class]
3、转录层CTC(Connectionist Temporal Classification)
转录层将RNN对每个特征向量做的预测转换成标签序列的过程。对于不定长序列的对齐问题。
RNN进行序列分类时,可能会出现一个字被识别多次,需要去除冗余机制。
处理的方法(引入blank机制)这一过程称为解码过程:
- 在重复的字符之间增加一个空格‘-’,
- 删除连续重复的字符,
- 再去掉路径中左右的‘-’字符
编码过程是由神经网络来实现的。
文本标签可以有多个不同的字符组合路径得到。
CTC loss如何计算:
在训练阶段根据这些概率分布向量和对应的文本标签计算损失函数。
根据能得到对应标签的所有路径的分数之和类计算损失函数。
每条路径的概率为每一个时间步中对应字符的分数的乘积。CTC损失函数定义为概率的负最大似然函数,为了计算方便对函数取对数。
p(l|y)= ∑ π : B ( π ) p ( π ∣ y ) \sum\limits_{π:B(π)}p(π|y) π:B(π)∑p(π∣y)
预测过程如何实现
先使用标准的CNN网络提取文本特征;
利用BLSTM将特征向量进行融合,已提取字符序列的上下文特征,得到每列特征的概率分布;
最后通过CTC进行预测得到文本序列。
在训练阶段CRNN将特征图像统一缩放到w×32,而在测试阶段对于输入的图片拉伸会导致识别率降低。CRNN保持输入图像尺寸比例,但是图像的高度h必须统一为32,卷积特征图的尺寸动态决定了LSTM的时序长度(时间步长)。
感谢:
https://blog.csdn.net/xiaosongshine/article/details/112198145
https://github.com/meijieru/crnn.pytorch
https://www.bilibili.com/video/BV1Wy4y1473z?p=2&vd_source=91cfed371d5491e2973d221d250b54ae