文章目录
- 1.卷积操作
- 1.1 卷积操作
- 1.2 padding-填充
- 1.3 stride-步长
- 1.4 pooling-池化
- 1.5 基础版CNN代码示例
- 1.6 完整CNN代码示例
1.卷积操作
卷积神经网络概览
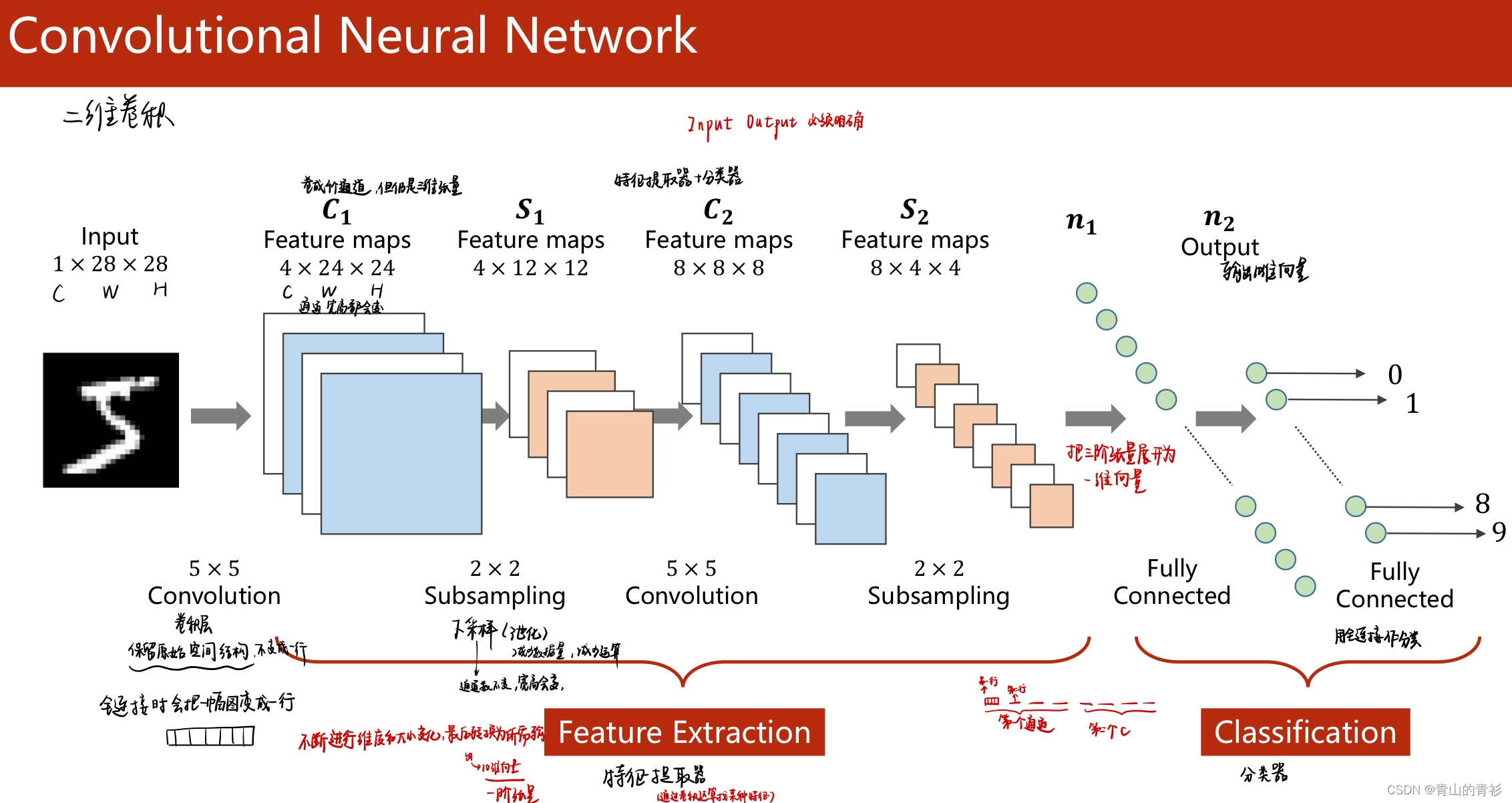
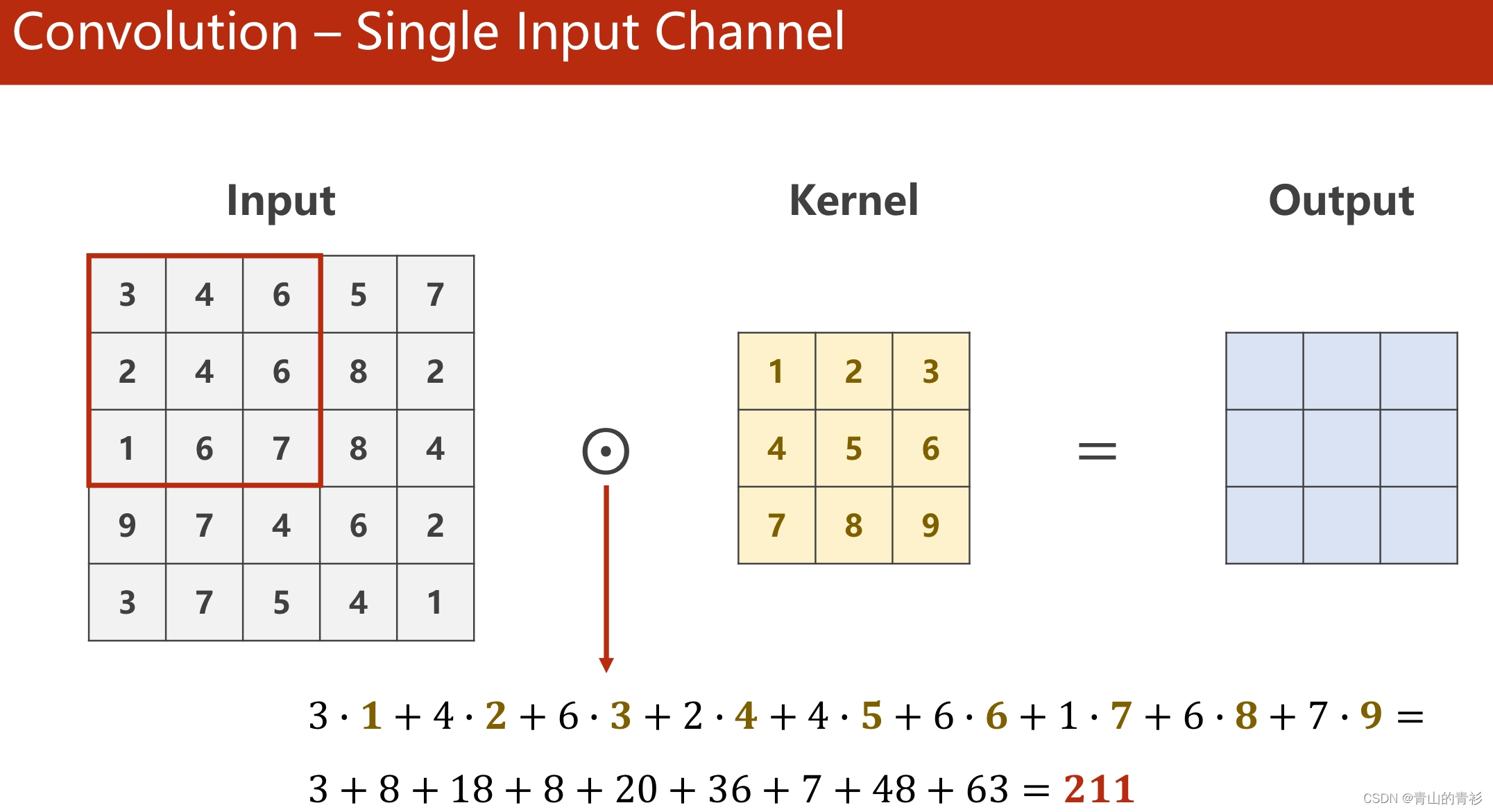
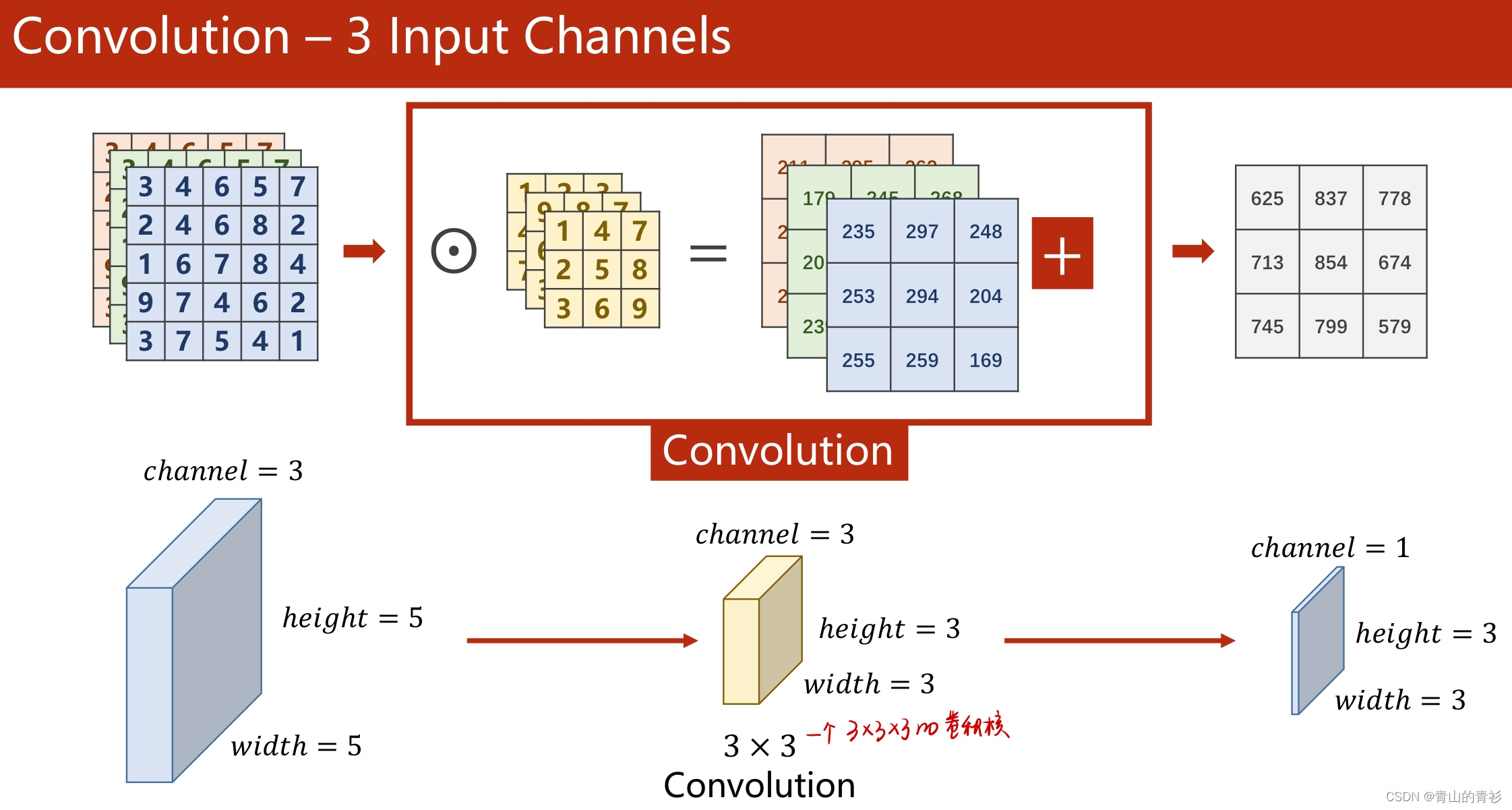
1.1 卷积操作
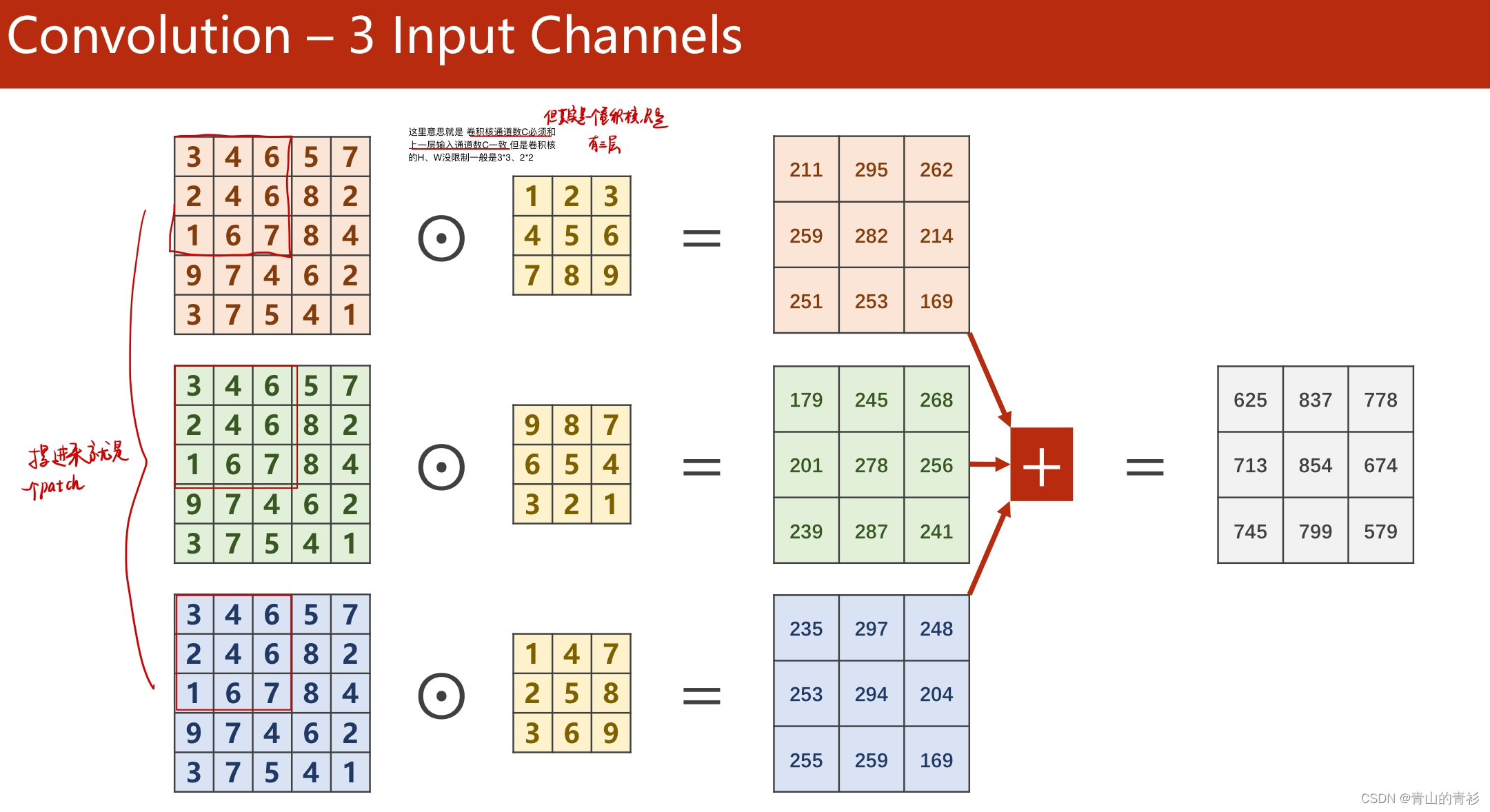
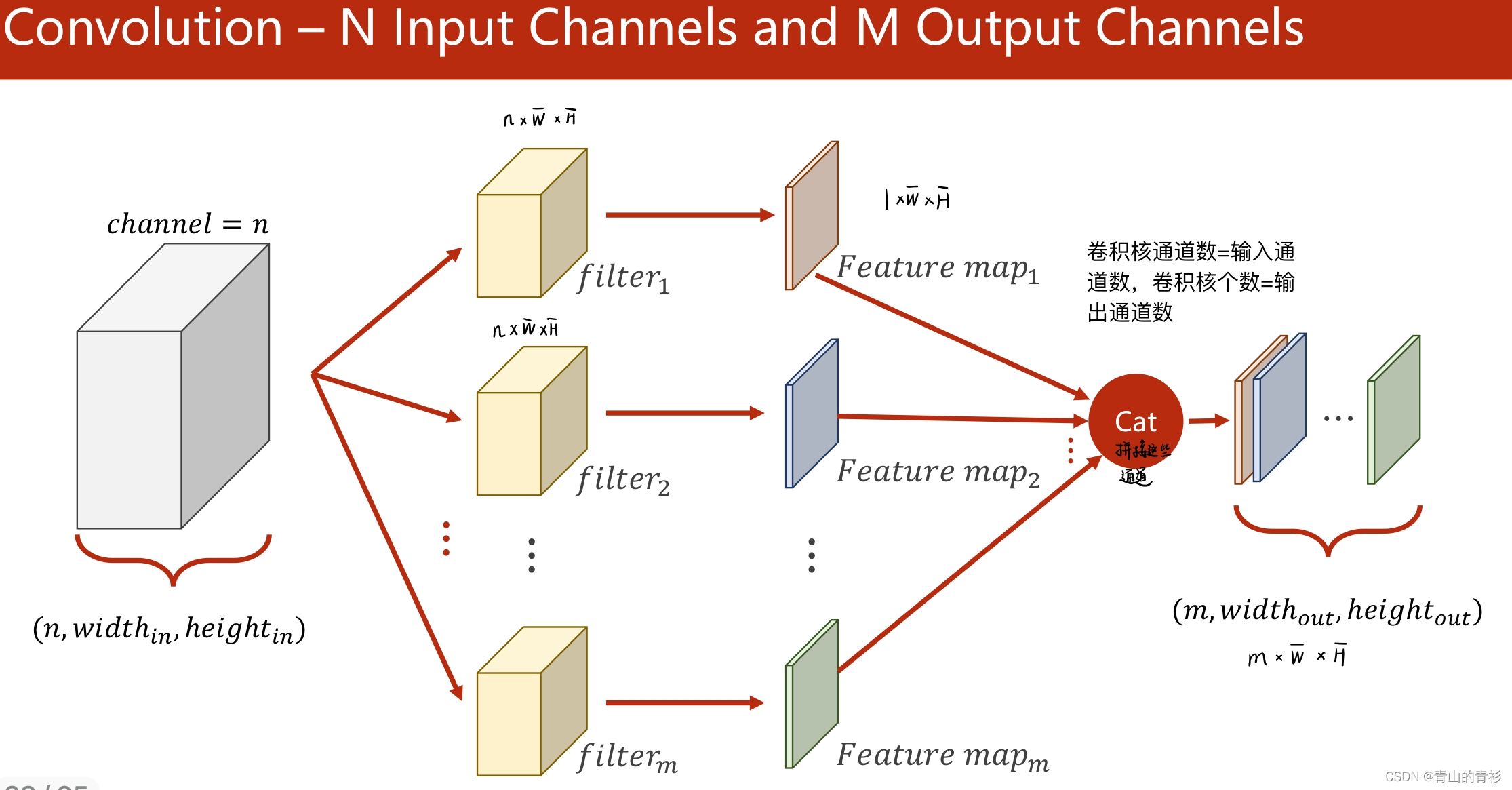
输入通道数=卷积核通道数,卷积核个数=输出通道数
1.2 padding-填充
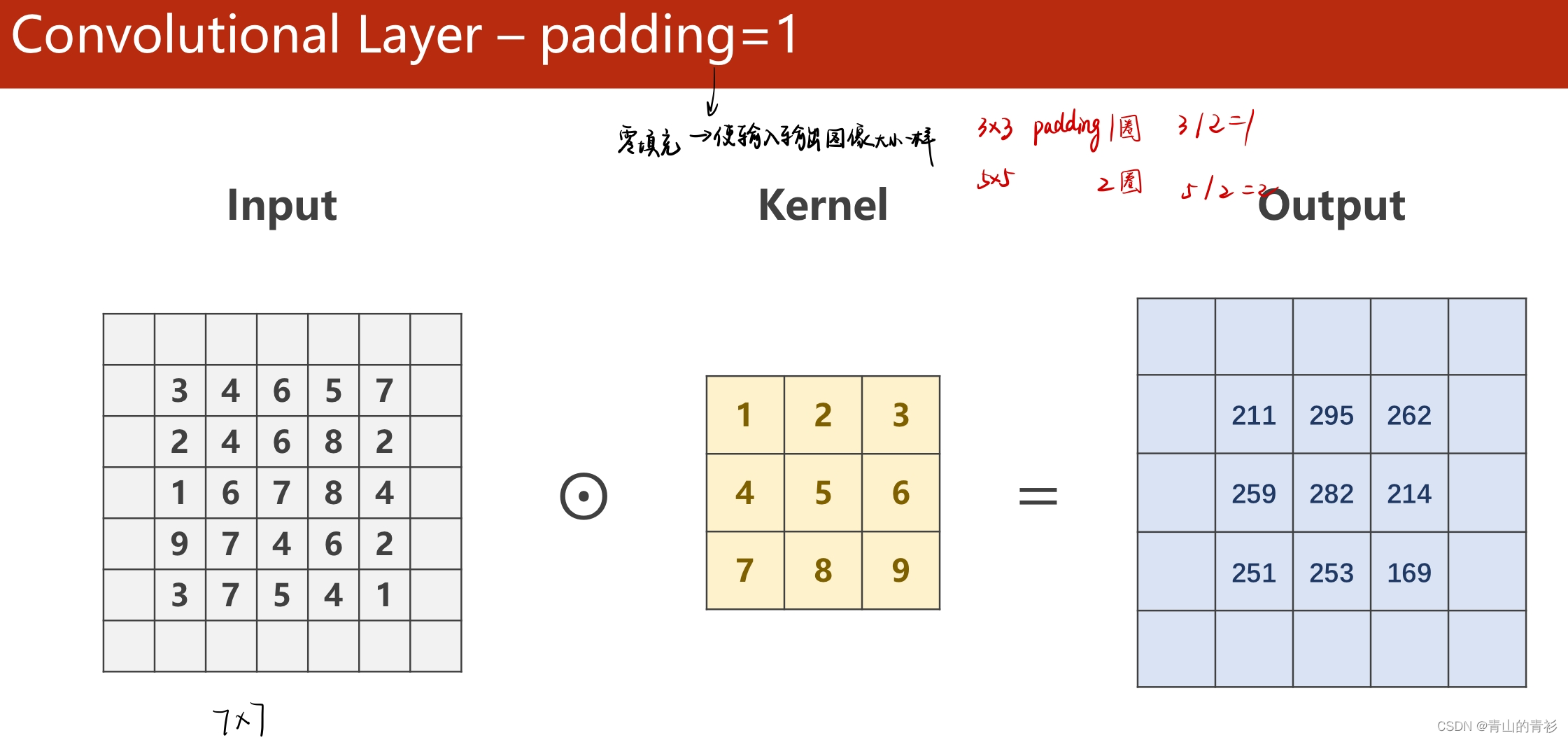
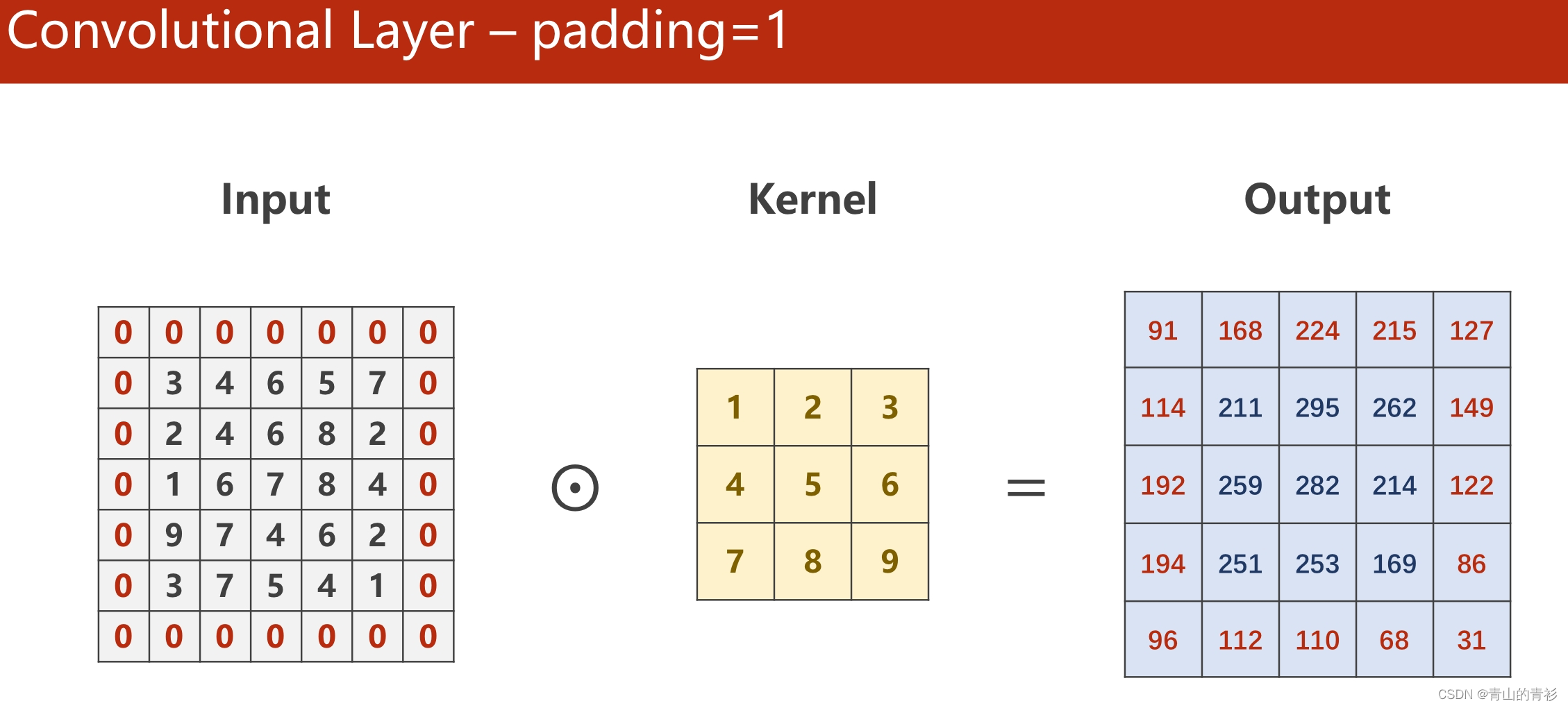
padding是为了让源图像最外一圈或多圈像素(取决于kernel的尺寸),能够被卷积核中心取到。
这里有个描述很重要:想要使源图像(1,1)的位置作为第一个与kernel中心重合,参与计算的像素,想想看padding需要扩充多少层,这样就很好计算了
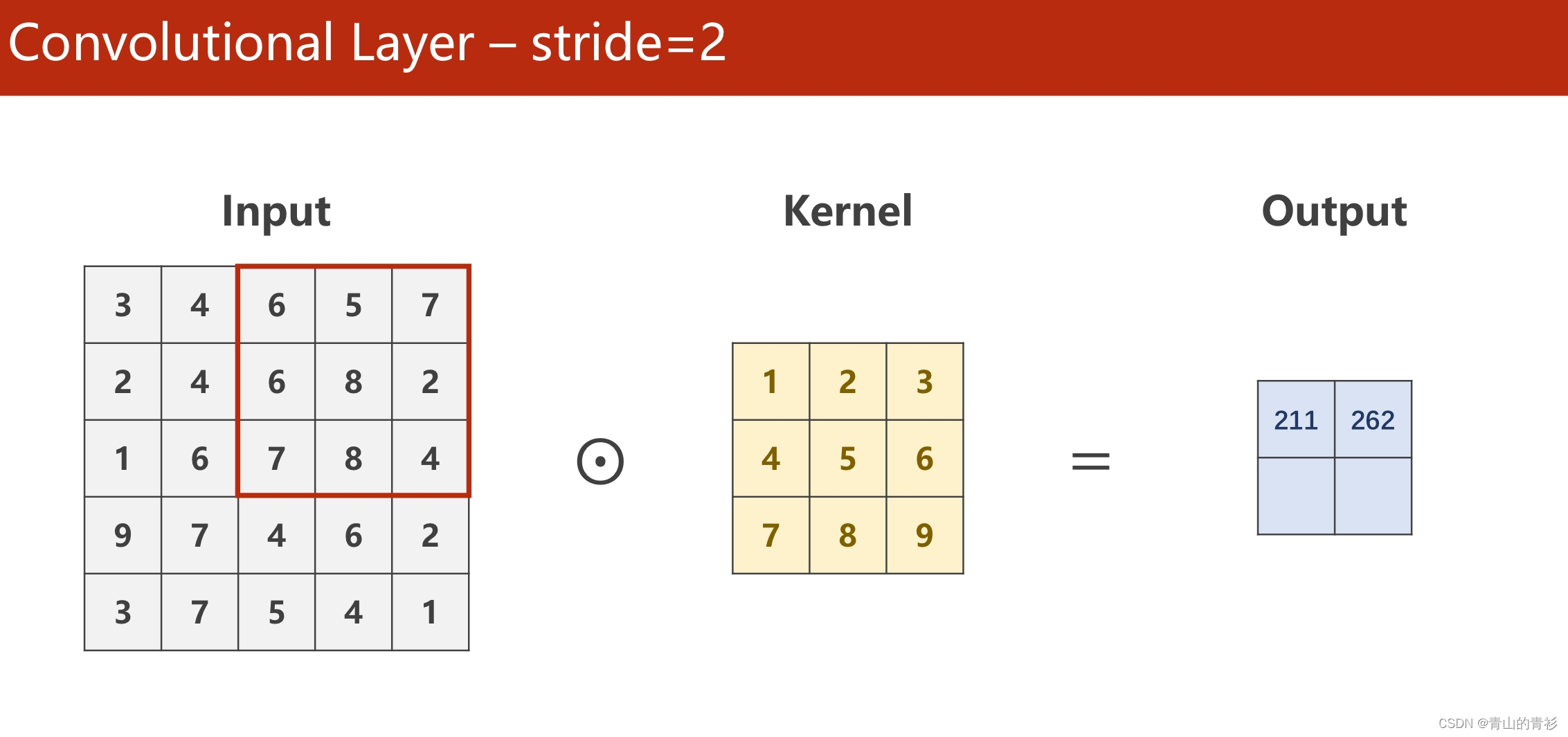
1.3 stride-步长
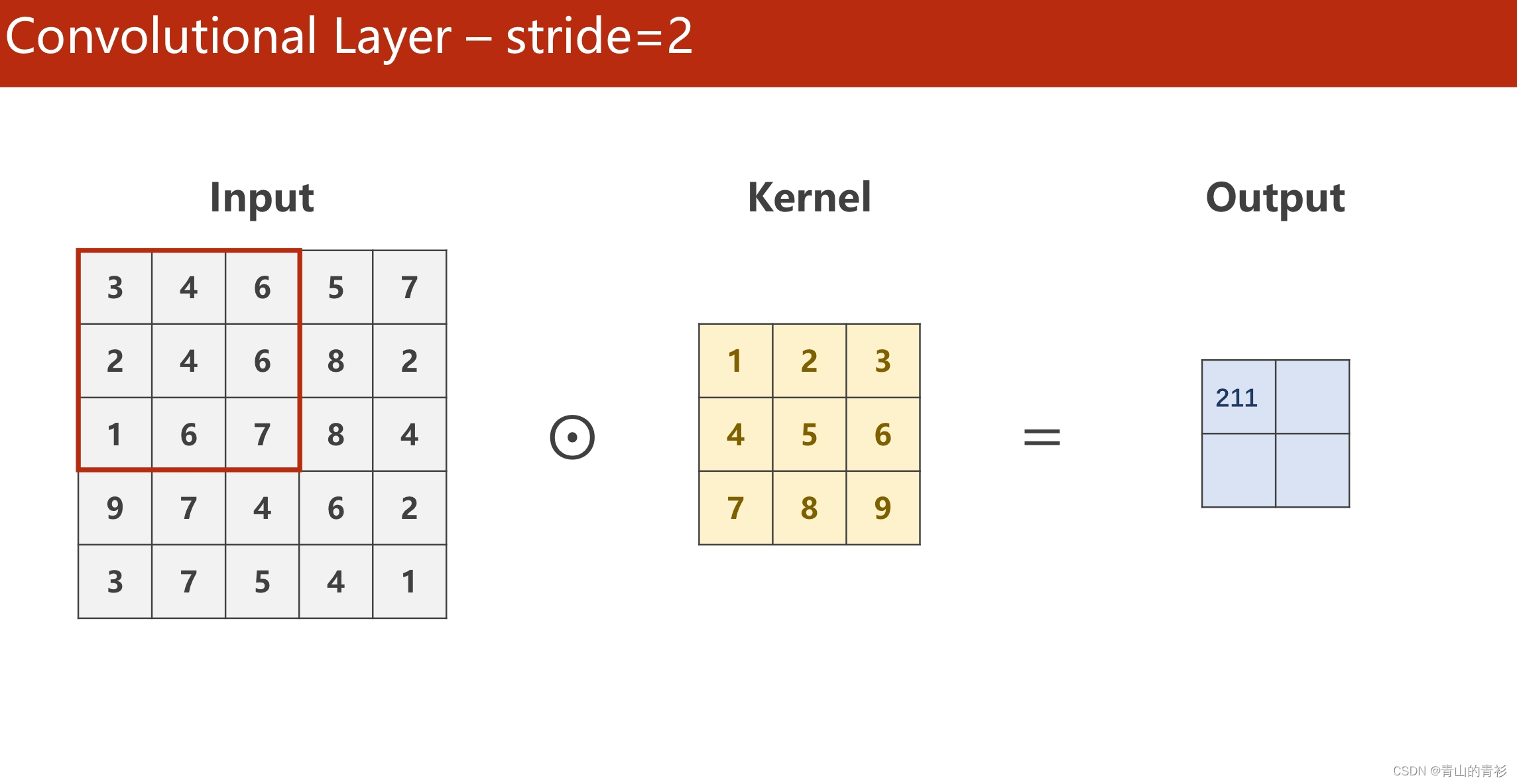
stride操作指的是每次kernel窗口滑动的步长,默认值是1
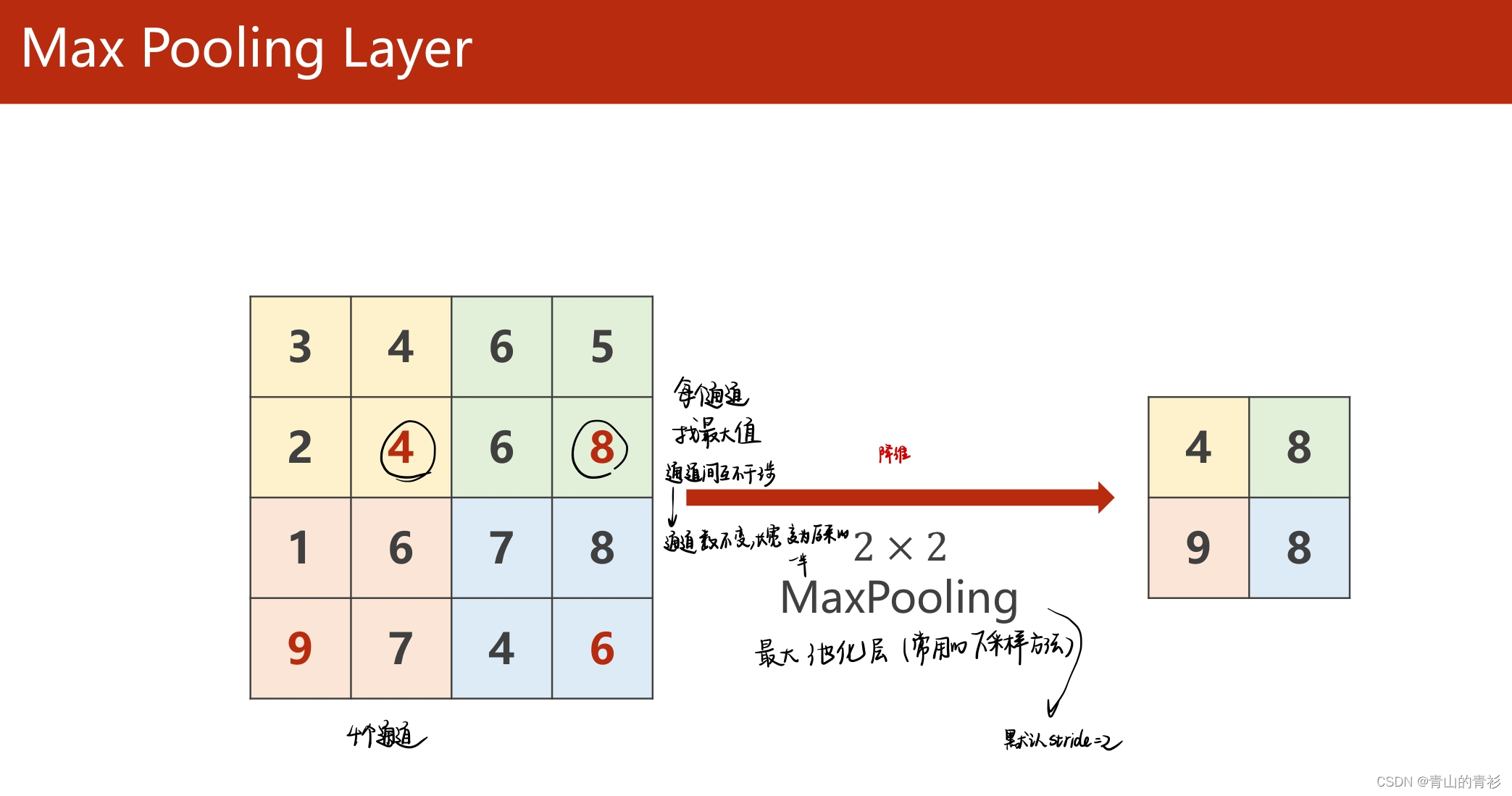
1.4 pooling-池化
以最大池化为例
卷积神经网络示例
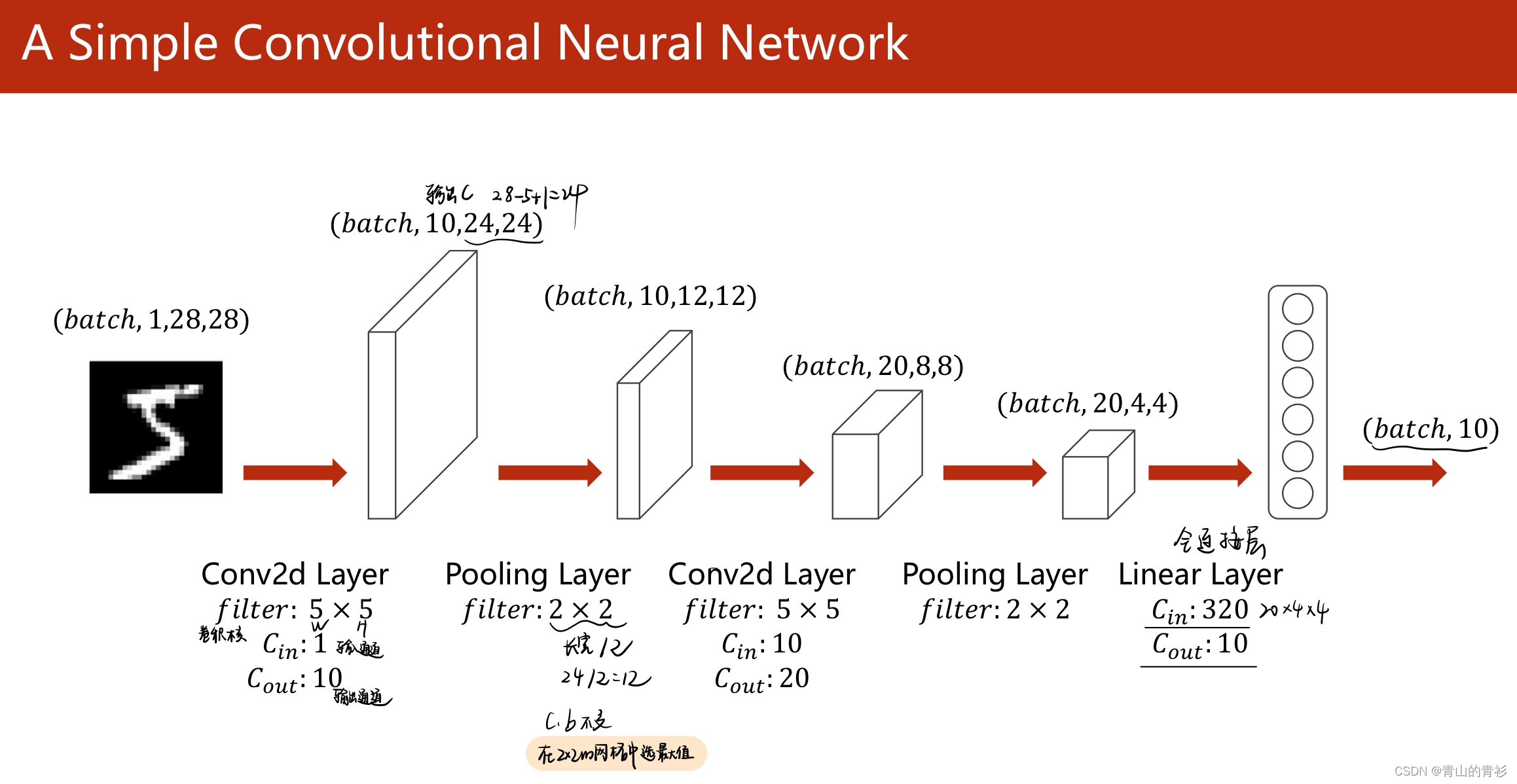
1.5 基础版CNN代码示例
import torch
in_channels, out_channels=5, 10
width, height = 100, 100 # 图像大小
kernel_size = 3 # 卷积核大小
batch_size = 1 # 所有输入pytorch中的data必须是小批量
input = torch.randn(
batch_size, # B 表明是小批量第几个
in_channels, # n 输入通道数
width, # W 宽
height # H 高
)
conv_layer = torch.nn.Conv2d(
in_channels, # 输入通道数
out_channels, # 输出通道数
kernel_size=kernel_size # 内核大小
)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
1.6 完整CNN代码示例
import matplotlib.pyplot as plt
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # (可有可无)
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size,
)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size,
)
class Net(torch.nn.Module):
def __init__(self):
super().__init__() # 卷积层
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5) # 卷积层1
self.conv2 = torch.nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5) # 卷积层2
self.pooling = torch.nn.MaxPool2d(2) # 池化层,没有涉及到权重,实例化一个就可以
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0) # 用于求维度
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # 用于变成全连接
x = self.fc(x)
return x
model = Net()
# 选择是GPU CPU
#device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 表示把整个模型涉及到的权重迁移到GPU
#model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_index, (inputs, labels) in enumerate(train_loader, 0):
# 迁移至GPU(模型数据要在同一块显卡上)
# inputs, labels = inputs.to(device), labels.to(device)
y_hat = model(inputs)
loss = criterion(y_hat, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_size % 10 == 9:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_index + 1, running_loss / 300))
def test():
correct = 0
total = 0
with torch.no_grad():
for (images, labels) in test_loader:
# images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, pred = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (pred == labels).sum().item()
print('accuracy on test set: %d %%' % (100 * correct / total))
return correct / total
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()