论文:Text and Code Embeddings by Contrastive Pre-Training
⭐⭐⭐⭐
OpenAI
一、论文速读
这篇论文基于大型生成式 LLM 通过对比学习来微调得到一个高质量的 text 和 code 的 embedding 模型。
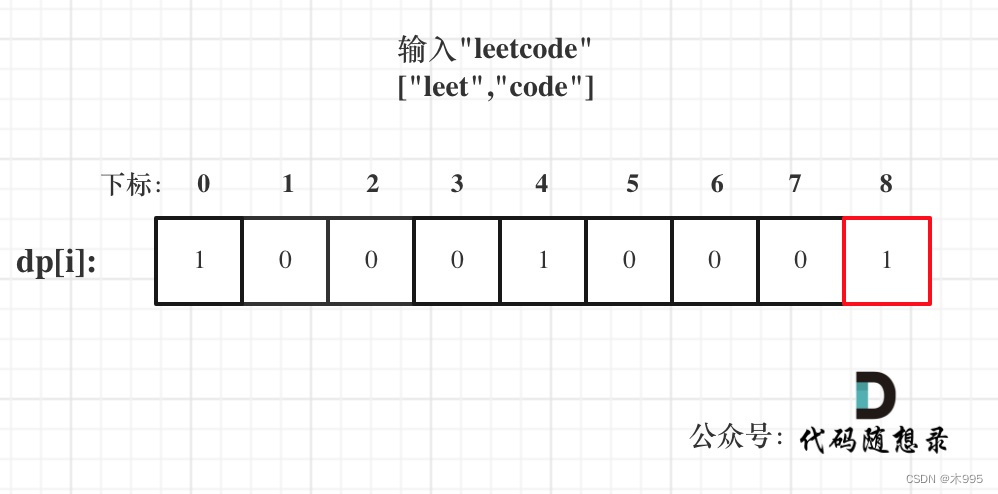
训练数据的格式:是一堆 ( x i , y i ) (x_i, y_i) (xi,yi) 形式的 positive pairs,这些 pairs 的 x i x_i xi 与 y i y_i yi 存在着语义相似性或者上下文相关性。在具体训练时,使用 in-batch negatives 的方法来构造出 negative pairs。
在训练 text embedding model 和训练 code embedding model 时,所使用的数据不一样:
- 训练 text embedding model 时,互联网上相邻 piece 的文本就作为 positive pair
- 训练 code embedding model 时,function 上方的 docstring 与其实现作为 positive pair ( t e x t , c o d e ) (text, code) (text,code)
Embedding Model:这个 encoder 将一个 sentence 转为一个 vector representation:
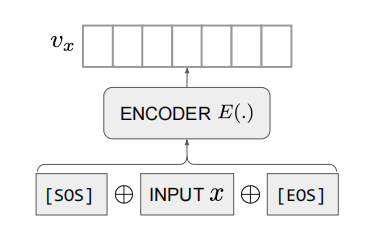
具体做法是:对于输入 sentence input x x x,将其前后拼接上 [SOS] 和 [EOS] 两个特殊 token,之后输入给 LLM,然后将 [EOS] token 的 hidden state 作为编码后的 embedding 结果。
相似度计算方式:将 x 和 y 分别输入给 encoder 得到 representation,然后计算 cosine 相似度即可:
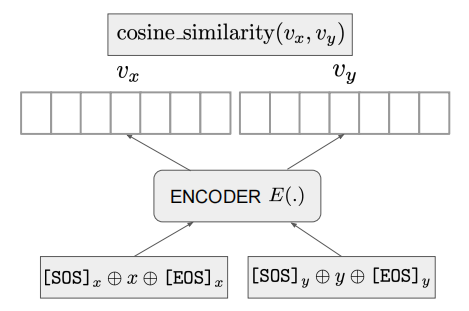
该工作训练得到的模型,可以为 text 和 code 编码出高质量的 representation,其 embedding 效果在文本 classification、sentence similarity、semantic search 等实验中都表现出不错的效果。
二、模型的训练
模型的推理过程较为简单直接,这里重点详细介绍一下他的训练过程。
前面说了训练数据的格式,按照上面所述,我们可以得到一批用于训练模型的数据,然后将其划分为多个 mini-batch 对模型迭代训练微调。
每一个 mini-batch 由 M M M 个 positive pairs,在使用它们的训练过程中,首先使用 in-batch negatives 的方法可以得到这个 batch 的 negative pairs,然后针对每一个 pair,将 x 与 y 输入给 encoder 得到其向量表示,然后计算这个 pair 的 logit 值:
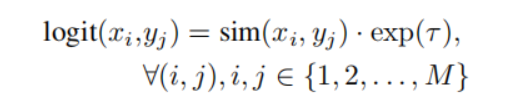
其中 τ \tau τ 是一个可训练的温度参数,用于调整相似度的缩放。
这样,可以计算出 M × M M \times M M×M 个 logits 组成一个 logit matrix,其中对角线上的元素是 positive pairs 的 logits,其余是负样本的 logits,然后针对 matrix 的每一行每一列计算 cross-entropy 损失,这样的损失是希望模型让正样本的 logit 最大化,让负样本的 logit 最小化,这里计算损失的伪代码如下:
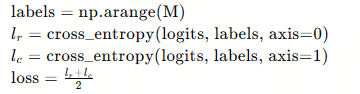
可以看到, l r l_r lr 和 l c l_c lc 分别是行方向和列方向上计算的交叉熵损失,然后取它们的平均值作为最终的损失函数值,它衡量了区分 positive pairs 和 negative pairs 方面的表现。
通过最小化这个损失函数,模型学习到的嵌入表示能够捕捉输入样本之间的语义相似性,从而在不同的下游任务中发挥作用。
关于 cross entropy 损失,如果忘了可以参考相关资料,从而理解这里为什么用这个函数。
三、实验
论文使用 GPT-3 来初始化 text embedding model 的基座模型,使用 Codex 来初始化 code embedding model 的基座模型,分别对两个模型进行了训练。
论文做了很多实验,这里选取了在文本检索任务上做的实验结果:
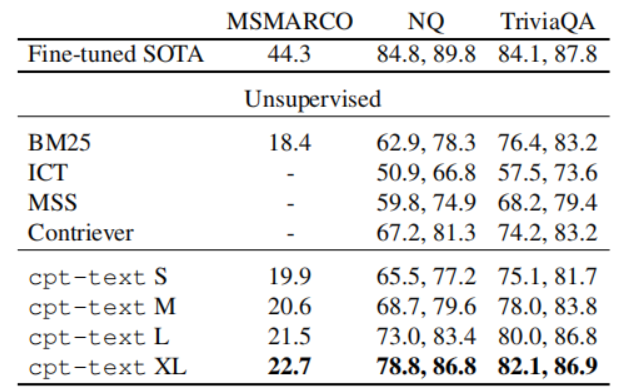
其中,cpt-text 就是本论文基于 GPT-3 微调得到的 text embedding model,可以看到:
- 模型越大(参数越多),其效果可以越好
- 该模型的效果远远超过了无监督的检索模型,其中 cpt-text XL 版本的表现已经可以与微调的 SOTA 模型相比较了
四、分析 ⭐
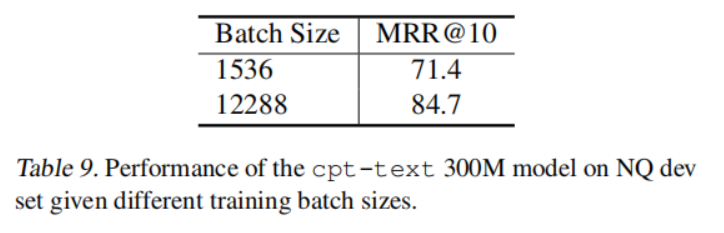
4.1 Batch Size 的影响
论文的消融实验研究了 batch size 对模型训练的影响。
已经公认的是,由于对比学习的机制,当 batch size 越大时,学习难度就越高,使得模型可以学得更好。论文的实验也证明了这一点:
4.2 训练时长的影响
一般认为,训练越久,效果越好,后面会趋于稳定。但是该论文的实验显示,训练越久,在检索和分类任务上效果越好,但是对于句子相似度任务来说,却恰好相反。
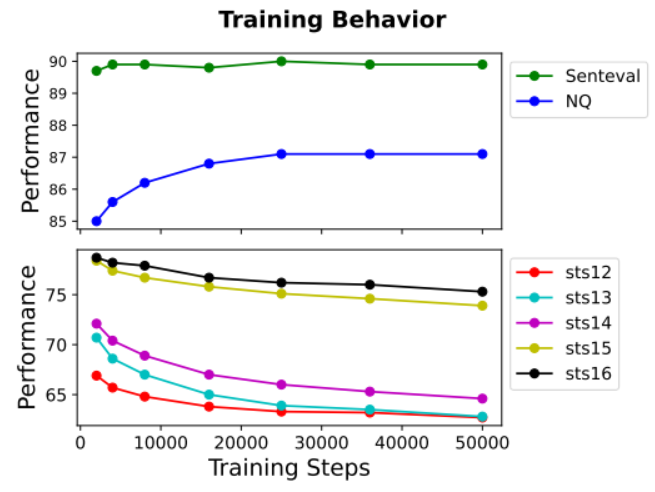
这其实涉及到一个很重要的讨论点:训练 embedding 时,检索任务和句子相似度任务是存在冲突的。
这两个任务看似类似,都可以基于 sentence embedding 完成,但两种却是属于两个研究方向,各有自己侧重的研究 topic。从本质上,这两个任务就是存在冲突的,比如一个句子及其否定可以被相似度任务认为是相关的,但在句子相似度任务中则却不应该被认为是“相似-相似”的。
在本论文的 model checkpoint 评估时,也是给检索任务和分类任务赋予了更高的重要性,因为它们往往与现实世界的应用相关联,而句子相似度任务则没那么重要。
总结
这篇论文表明,基于 GPT 系列的 LLM,在足够大的批处理的无监督数据上进行对比预训练,可以获得高质量的文本和代码的 embedding 表示,并可以应用于其他的下游任务中得到不错的表现。



![[AI OpenAI-doc] 迁移指南 Beta](https://img-blog.csdnimg.cn/direct/5570d89e0c564ce1b903b2b501f3959b.png)