馒头老师要说的话:
我近期看了一下北京的脑机公司,大概是我之前对这一行业太过于乐观,北京的BCI公司和研究所,比上海、深圳、杭州甚至是重庆都要少,门槛也要高很多。也有我自己的原因,有时站的太高,看得太远,反而忽视了BCI的发展进度和同学们的学习程度,这些公司对于同学们还是有难度的,这像古人说的:‘何不食肉糜?’,这种现象也发生在我和其他所谓的专家身上,好比专家质问外卖小哥:‘送外卖时可以把家里的宝马X5租出去开出租,可以把家里150平的房子也出租嘛,这部都是收入’,还好我及时省身。
但同学们,你们还年轻,年轻就有无限的可能,你们生机勃勃,这个世界是我们的,但终究是属于你们的,我们来看一下使用ML和DL技术处理各个病例数据的赛道吧,这也是目前我和北京某国重实验室老师带的国自然项目的赛道。
本文由郑州大学附属肿瘤医院肿瘤内科,河南肿瘤医院,郑州大学附属肿瘤医院DRGs(诊断相关组)办公室病务科,郑州大学第三附属医院放射科,河南中医药大学人民医院转化医学研究中心,共同在2024年发表于BMC Public Health IF:4.7\JCR:Q1
Abstract:
深度学习(DL)是机器学习(ML)的一种特殊形式,在预测各种疾病的生存方面很有价值。其在现实世界胃癌(GC)患者中的临床适用性尚未得到广泛验证。
方法采用来自监测、流行病学和最终结果(SEER)数据库的11414例胃癌患者和来自中国数据集的2846例患者的联合队列。通过在SEER数据库上的训练集和测试集对DL模型、传统ML模型和美国癌症联合委员会(AJCC)阶段模型进行内部验证,然后在中文数据集上进行外部验证。
利用接收机工作特性曲线、决策曲线和校准曲线下的面积来评估算法的性能。
结果DL模型在术后1年、3年和5年的曲线下面积(AUC)方面表现优异,优于其他ML模型和AJCC阶段模型,SEER数据集的AUC分别为0.77、0.80和0.82,中文数据集的AUC分别为0.77、0.76和0.75。此外,决策曲线分析显示DL模型在3年的净收益大于其他ML模型和AJCC阶段模型,并且3年的校准图表明ML与外部验证时的实际观测值之间具有良好的一致性。
在这里我说一下:
SEER胃癌公开数据可类比于我们的BCI-2A数据,该数据在此病例数据中广泛应用,用到的验证模型的评价指标是生存概率Kaplan-Meier法以及死亡概率(风险概率)COX比例风险回归,也就是我们建立的模型,除了要得到患者最终的生存率,还要预测到1年、3年、5年之后的术后患者的生存和死亡概率,至于K-M、COX都可以通过python实现来画图。
Background:
背景这里也说一下,引用原文:
胃癌(Gastric cancer, GC)是常见的恶性肿瘤之一,手术切除仍是早期胃癌治疗的唯一选择,也是胃癌的主要治疗方法[1]。即使胃癌患者行根治性手术,影响其生存和病情进展的因素仍有很多,包括临床因素和病理因素,如分期、组织学类型、浸润深度、淋巴结及远处转移等[2-5]。因此,准确预测术后生存率对患者和医疗机构都至关重要。胃癌是一种异质性、多因素的疾病,多因素的多变性和胃癌的复杂性使得治疗和生存预测极其困难[6]。目前,临床医生通常根据美国癌症联合委员会(American Joint Committee on Cancer, AJCC)分期结合自身医疗经验来评估患者的生存,忽略了其他影响生存因素的作用[7]。分期系统在指导胃癌治疗决策方面应用广泛,效果显著。然而,它没有考虑到性别、年龄、肿瘤大小、组织病理类型等各种因素,这些因素都会显著影响生存预后。此外,传统的生存分析方法,如Cox回归,在生存分析中遇到了局限性,包括对比例风险的要求和连续变量线性的假设。这些约束可能会限制它们在复杂场景中的适用性。然而,基于深度学习的预测模型代表了一个重大的进步,因为它们有效地解决了这些问题。它们可以处理非比例风险,并为变量和结果之间的非线性关系建模,使它们在不同临床环境下的生存预测更加通用和准确。
机器学习(Machine learning, ML)擅长从高维、复杂的数据中获取信息,自动学习并以监督或无监督的方式进行预测,在疾病预测中发挥着重要作用[8]。与AJCC分期模型相比,ML预测模型可能更适合临床环境,指导临床决策。据我们所知,目前还缺乏一些临床因素与胃癌患者术后预后之间关系的有效预测模型。深度学习(DL)是一种特殊的机器学习模型,它包含多个神经网络,可以处理更复杂的信息。与传统的多任务逻辑回归和随机森林模型相比,深度学习方法具有许多优点。首先,深度学习可以从大型数据集中学习复杂的模式和表示,与传统的ML算法相比,其性能优越。其次,深度学习算法可以有效地扩展大量数据。第三,深度学习模型具有自动学习和提取相关信息的能力来自原始数据的特征。最后,深度学习模型可以利用大型数据集上的预训练模型,从而实现迁移学习。这种方法能够将现有的知识从一个领域应用到另一个领域,即使有有限的标记数据,从而减少了对大量训练数据的需求。一些研究在外科肿瘤研究中使用DL模型进行分析[9-11]。
然而,(话锋一转,敲黑板!这里我B站视屏也给大家说如何写论文了)这些研究大多集中在诊断应用上,如放射图像的自动量化、数字组织病理学图像解释或生物标志物分析[12-15]。据我们所知,在外科肿瘤学中,特别是在GC领域,利用DL模型进行预后预测的已发表研究有限。因此,基于dl的生存分析有助于预测胃癌术后的生存。
美国国家癌症研究所(National Cancer Institute)建立的监测、流行病学和最终结果(SEER)数据库是一个全面的癌症登记处,拥有完善且定期更新的数据,提供了关于患者临床特征、治疗和生存数据的丰富信息[16]。本研究旨在从SEER数据库中提取胃癌术后患者的信息,利用DL算法构建胃癌生存预测模型,并利用实际胃癌患者的信息评价构建模型的准确性,分析胃癌生存概率的影响因素及5年生存状况,为胃癌的临床治疗和预后提供决策支持。
Methods:
介绍了SEER数据:
SEER数据库收集了来自18个癌症登记处的癌症发病率和生存率信息,覆盖了大约27.8%的美国人口。本研究还纳入了2016年至2020年间在郑州大学附属肿瘤医院、河南省肿瘤医院诊断为胃癌的患者,形成了一个中国数据集。本研究中涉及人类参与者的所有程序均遵循机构和/或国家研究委员会制定的伦理标准,以及1964年赫尔辛基宣言及其后续修订或同等伦理标准。由于本研究为回顾性研究,不需要患者的知情同意。
介绍了ML方法:
Multi-task logistic regression (MTLR)
Random Survival Forests (RSF)
DeepSurv
本研究采用了多种机器学习算法。我们对生存分析模型实施了两个阶段的验证过程。最初,我们使用SEER数据库进行内部验证,其中数据随机分为两部分:60%用于模型训练,40%用于验证。这种划分使我们能够在相同的数据集内开发和随后评估模型。我们采用网格搜索方法结合c指数来选择生存分析模型的参数。该方法需要探索一组预定义的参数组合,在训练数据集上训练模型,然后使用C-index在内部验证数据集上评估其性能。该过程系统地确定了通过有效地对生存时间排序来提高模型预测准确性的最佳参数。网格搜索的结果在补充资料中提供。为了进行外部验证,我们使用了来自中国的独立数据集,使我们能够评估模型在不同患者群体中的表现。这种全面的方法确保了我们的模型在不同临床背景下的全面评估[17]。本研究中测试的ML算法包括DL、MTLR和RF。将这些ML模型的准确性与TNM阶段进行比较。为了评估模型的性能,计算了各种指标,包括接收器工作特性曲线下的面积[18]。曲线下面积(AUC)是一种不受特定阈值影响的性能度量,它提供了对模型性能的全面评估。
AUC的取值范围为0.5 ~ 1.0,其中0.5代表随机概率,1.0代表完美分类(也使用了AUC评价model)此外,通过目视检查校准图来评估模型的校准,将预测结果与观察结果进行比较。采用决策曲线分析计算各预测模型的临床净收益。
净效益衡量的是使用模型预测来指导决策所获得的优势。采用这些策略的净收益与依赖基于预后的干预的模型进行了比较,这意味着基于预测风险超过特定阈值的干预。
Result:
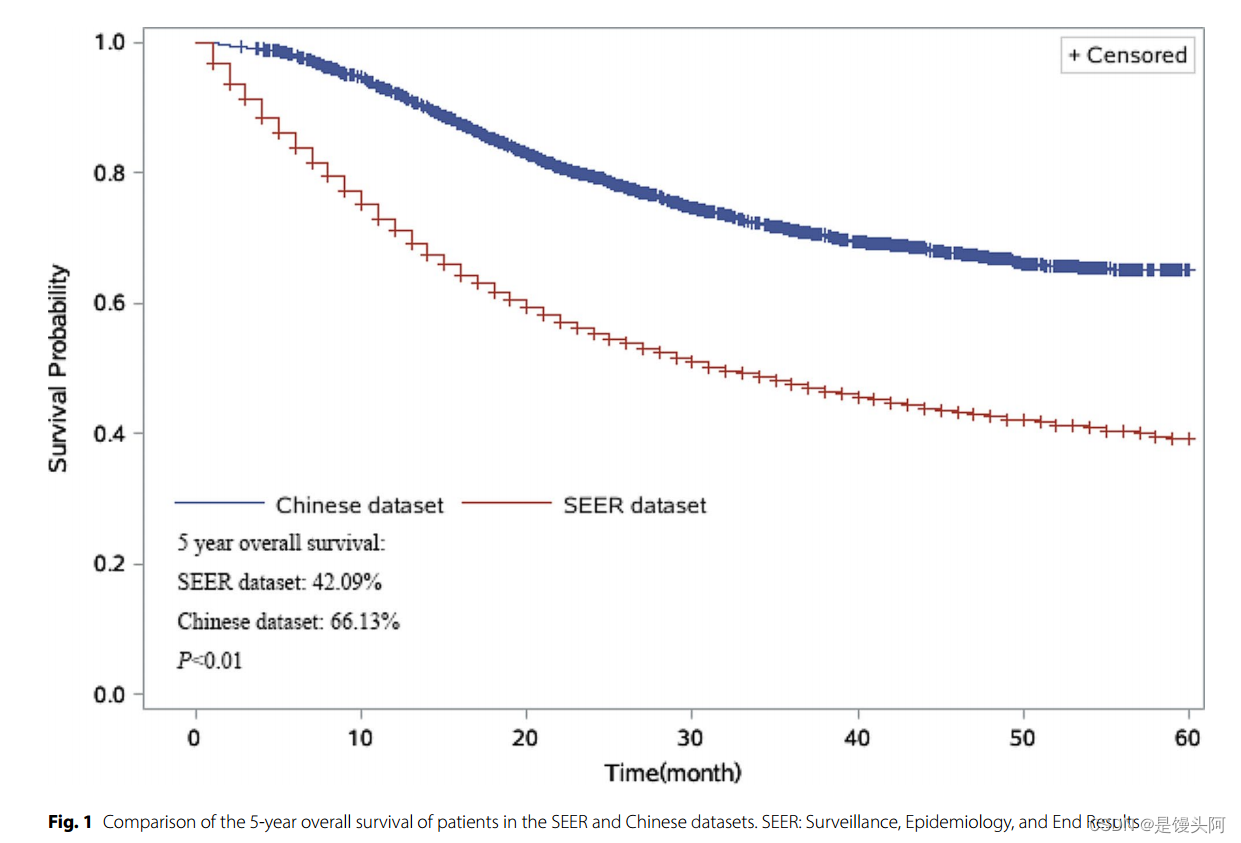
这是在中国数据和SEER数据上的总体的预测对比,随着X轴的延申,患者生存率从1开始下降到0.4

对SEER数据术后患者的K-M曲线分析,从A到I依次取不同的特征数列进行预测,分别为性别、年龄、分级、种族、T分期、N分期、M分期、放疗、化疗的5年预测结果
在这里:
测试集中,3年生存预测的准确性高于1年、5年生存预测的准确性。1年生存预测概率高于实际概率,5年生存预测概率低于实际概率。造成这种现象的原因有以下几点:
(1)肿瘤患者1年的死亡率相对较低,5年的死亡率相对较高,这使得模型识别更加困难。
(2)训练集的准确率高而验证集的准确率低,可能是由于训练集和验证集中患者的遗传背景、种族、治疗方式的差异造成的。
在后续的研究中可以考虑迁移学习等方法来提高验证集的准确性。
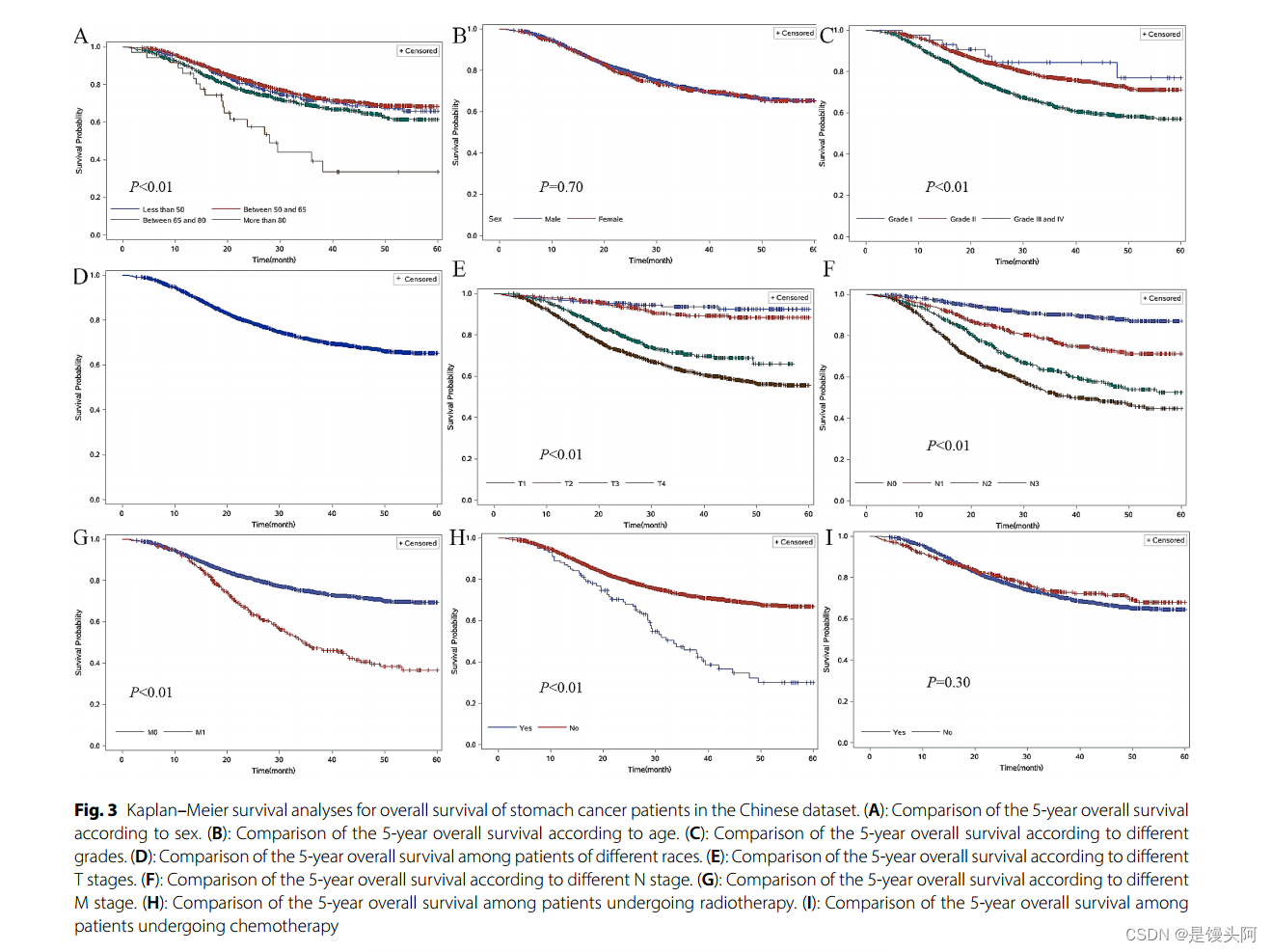
中国数据集中胃癌患者总生存率的Kaplan-Meier生存分析。(A):按性别的5年总生存率比较。(B):按年龄分组的5年总生存率比较。(C):不同分级的5年总生存率比较。(D):不同种族患者5年总生存率比较。(E):不同T分期的5年总生存率比较。(F):不同N分期的5年总生存率比较。(G):不同M分期的5年总生存率比较。(H):放疗患者5年总生存率比较。(1):化疗患者5年总生存期比较
Conclusions:
我们首次使用SEER和中国人口数据库的数据构建了基于dl的模型,并对其进行了内部和外部验证,以预测胃癌术后患者的预后。我们的研究结果表明,基于dl的模型可以准确预测胃癌术后患者的生存率。
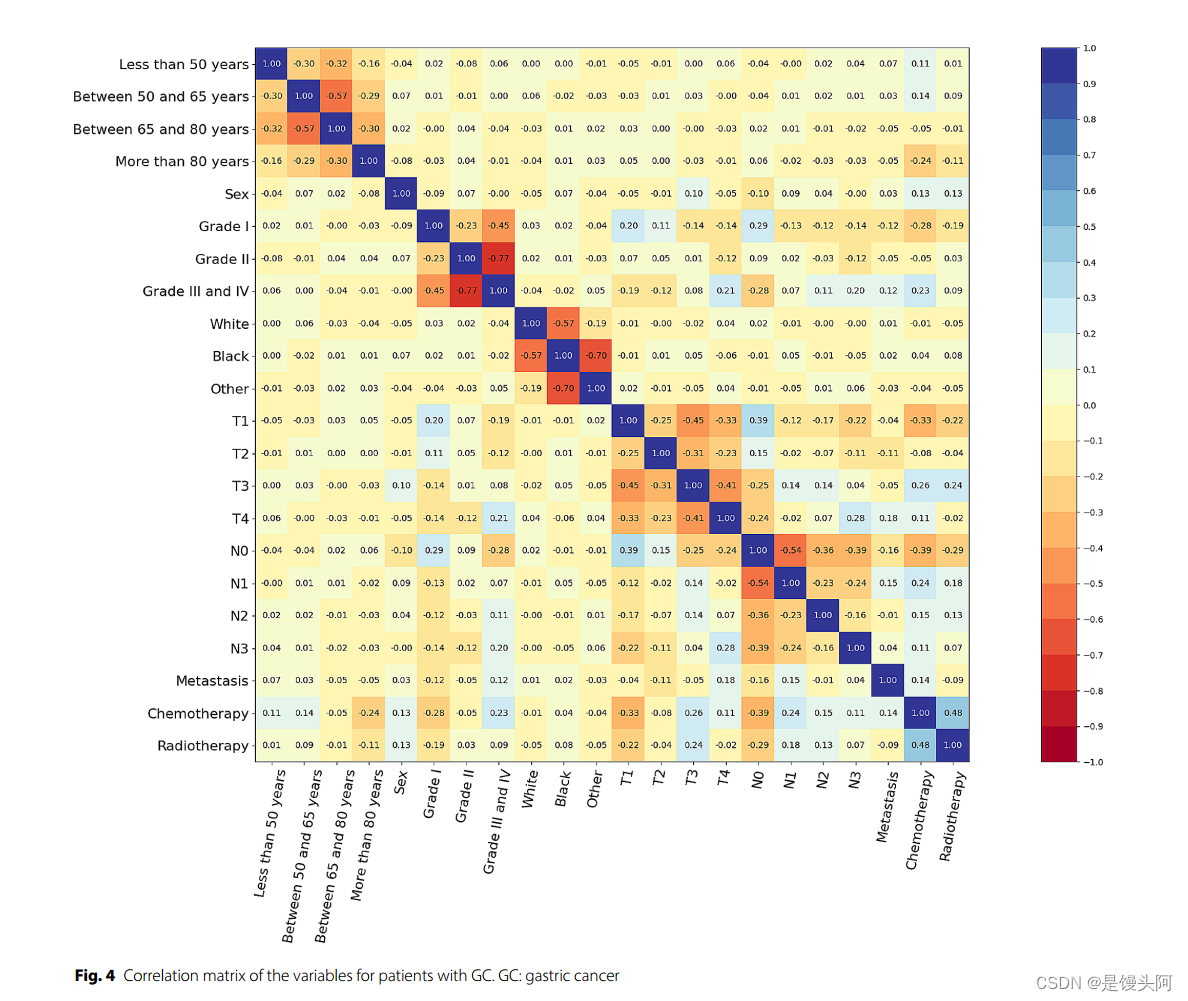
本文是噱头是把DL技术首次用到SEER中,发了个1区的文章,对于SEER数据是个csv文件,共计20多列特征数据,也很好分析处理,感觉对于这个数据ML初学者也能处理了,大家也可以关注该赛道,多多出论文!