上篇文章中我们了解了多头注意力和位置编码,本文我们继续了解Transformer中剩下的其他组件。
层归一化
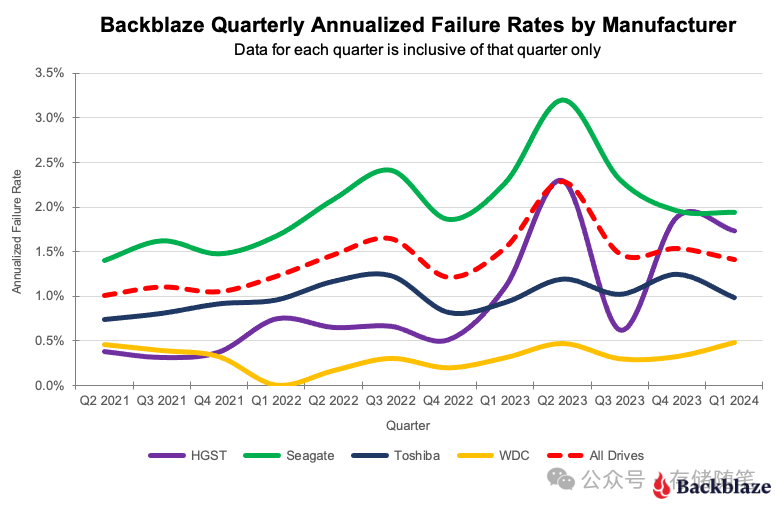
层归一化想要解决一个问题,这个问题在Batch Normalization的论文中有详细的描述,即深层网络中内部结点在训练过程中分布的变化问题。
如果神经网络的输入都保持同一分布,比如高斯分布,那么网络的收敛速度会快得多。但如果不做处理的话,这很难实现。由于低层参数的变化(梯度更新),会导致每层输入的分布也会在训练期间变化。
批归一化首先被提出来通过在深度神经网络中包含额外的归一化阶段来减少训练时间。批归一化通过使用训练数据中每个批次输入的均值和标准差来归一化每个输入。它需要计算累加输入统计量的移动平均值。在具有固定深度的网络中,可以简单地为每个隐藏层单独存储这些统计数据。针对的是同一个批次内所有数据的同一个特征。
然而批归一化并不适用于Transformer,通常在NLP中一个批次内的序列长度各有不同,所以需要进行填充,存在很多填充token。如果使用批归一化,则容易受到长短不一中填充token的影响,造成训练不稳定。而且需要为序列中每个时间步计算和存储单独的统计量,如果测试序列不任何训练序列都要长,那么这也会是一个问题。
而层归一化针对的是批次内的单个序列样本,通过计算单个训练样本中一层的所有神经元(特征)的输入的均值和方差来归一化。没有对批量大小的限制,批归一化是不同训练数据之间对单个隐藏单元(神经元,特征)的归一化,层归一化是单个训练数据对同一层所有隐藏单元(特征)之间的归一化。对比见下图:

如上图所示,批归一化针对批次内的所有数据的单个特征(Feature);层归一化针对批次内的单个样本的所有特征,它们都包含所有时间步。层归一化的公式为:
y
=
x
−
E
[
x
]
V
a
r
[
x
]
+
ϵ
⋅
γ
+
β
y=\frac{x-E[x]}{\sqrt{Var[x]+\epsilon}}\cdot \gamma+\beta
y=Var[x]+ϵx−E[x]⋅γ+β 其中,x是归一化层的输入,y是归一化层的输出,
γ
\gamma
γ和
β
\beta
β是为归一化曾分配的一个自适应的缩放和平移参数,
ϵ
\epsilon
ϵ是一个很小的值,防止除零。
残差连接
残差连接(residual connection,skip residual,也称为残差块)原理很简单,如下图: x为网络层的输入,该网络层包含非线性激活函数,记为F(x),即:
y
=
x
+
F
(
x
)
y=x+F(x)
y=x+F(x) y是该网络层的输出,它作为第二个网络层的输入。在这个过程中,输入x没有被遗忘。
x为网络层的输入,该网络层包含非线性激活函数,记为F(x),即:
y
=
x
+
F
(
x
)
y=x+F(x)
y=x+F(x) y是该网络层的输出,它作为第二个网络层的输入。在这个过程中,输入x没有被遗忘。
残差是ResNet提出的概念,一般网络层数越深,模型的表达能力越强,性能也就越好。但随着网络的加深,也带来了很多问题,比如梯度消失、梯度爆炸。残差连接可以缓解这个问题。

上图是ResNet网络有无残差连接损失平面的区别,可以看出来,增加了残差连接后,损失平面更加平滑,没有那么多局部极小值。直观地看,有了残差连接了,x的信息可以直接传递到下一层,哪怕中间F(x)是一个非常深的网络,只要它能学到将自己的梯度设成很小,不影响x梯度的传递即可。