文章目录
- 前言
- 一、直接内存
- 1.1 什么是直接内存
- 1.2 代码实现
- 1.3 使用直接内存的优缺点
- 二、netty 零拷贝设计
- 2.1 netty 直接内存
- 2.2 netty 内存池
- 三、零拷贝的两种方式
前言
本篇从源码层面剖析 netty 高性能架构设计之零拷贝,并且扩展讲述零拷贝的两种实现方式。
一、直接内存
1.1 什么是直接内存

直接内存,也被称为堆外内存,是Java应用程序通过直接方式从操作系统中申请的内存,不属于Java虚拟机(JVM)的内存管理范畴。这意味着直接内存的分配和释放不会受到Java堆大小的限制,但还是会受到本机总内存的大小及处理器寻址空间的限制。
直接内存的主要作用是为了提高某些操作的性能,尤其是在需要大量数据复制和IO操作的场景中。例如,在文件读写操作中,使用直接内存可以减少数据从系统缓冲区到Java缓冲区的复制步骤,从而提高读写速度。
直接内存的一个重要特点是,虽然它不由JVM直接管理,但仍然可能出现内存溢出的情况,因此在使用时需要谨慎。
在Java中,直接内存通常与Java的NIO(New I/O)库相关,特别是通过DirectByteBuffer类来操作。虽然直接内存的使用可以提高性能,但它也带来了额外的复杂性和风险,因此在决定使用直接内存时需要仔细权衡利弊。
1.2 代码实现
//分配堆内存
ByteBuffer buffer = ByteBuffer.allocate(1000);
//分配直接内存
ByteBuffer buffer = ByteBuffer.allocateDirect(1000);
直接内存源码分析:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//判断是否有足够的直接内存空间分配,可通过-XX:MaxDirectMemorySize=<size>参数指定直接内存最大可分配空间,如果不指定默认为最大堆内存大小,
//在分配直接内存时如果发现空间不够会显示调用System.gc()触发一次full gc回收掉一部分无用的直接内存的引用对象,同时直接内存也会被释放掉
//如果释放完分配空间还是不够会抛出异常java.lang.OutOfMemoryError
Bits.reserveMemory(size, cap);
long base = 0;
try {
// 调用unsafe本地方法分配直接内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
// 分配失败,释放内存
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 使用Cleaner机制注册内存回收处理函数,当直接内存引用对象被GC清理掉时,
// 会提前调用这里注册的释放直接内存的Deallocator线程对象的run方法
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
// 申请一块本地内存。内存空间是未初始化的,其内容是无法预期的。
// 使用freeMemory释放内存,使用reallocateMemory修改内存大小
public native long allocateMemory(long bytes);
// openjdk8/hotspot/src/share/vm/prims/unsafe.cpp
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size;
if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
}
if (sz == 0) {
return 0;
}
sz = round_to(sz, HeapWordSize);
// 调用os::malloc申请内存,内部使用malloc这个C标准库的函数申请内存
void* x = os::malloc(sz, mtInternal);
if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
}
//Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_END
1.3 使用直接内存的优缺点
优点:
- 不占用堆内存空间,减少了发生GC的可能
- java虚拟机实现上,本地IO会直接操作直接内存(直接内存=>系统调用=>硬盘/网卡),而非直接内存则需要二次拷贝(堆内存=>直接内存=>系统调用=>硬盘/网卡)
缺点:
- 初始分配较慢
- 没有JVM直接帮助管理内存,容易发生内存溢出。为了避免一直没有FULL GC,最终导致直接内存把物理内存耗完。我们可以指定直接内存的最大值,通过-XX:MaxDirectMemorySize来指定,当达到阈值的时候,调用system.gc来进行一次FULL GC,间接把那些没有被使用的直接内存回收掉。
二、netty 零拷贝设计
2.1 netty 直接内存

Netty的接收和发送ByteBuf采用DIRECT BUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。
所以 netty 的零拷贝只是减少了不必要的拷贝,并不是一次拷贝都没有
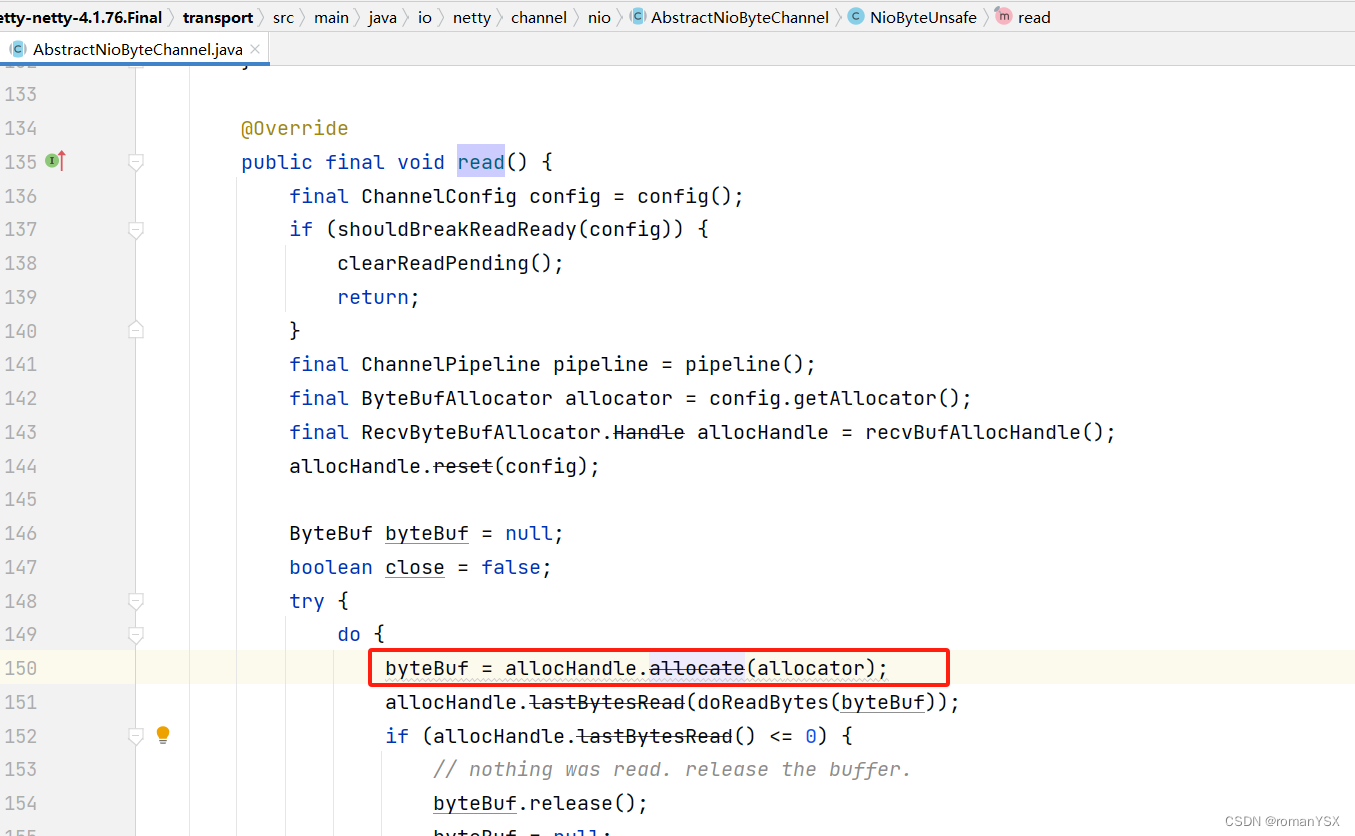
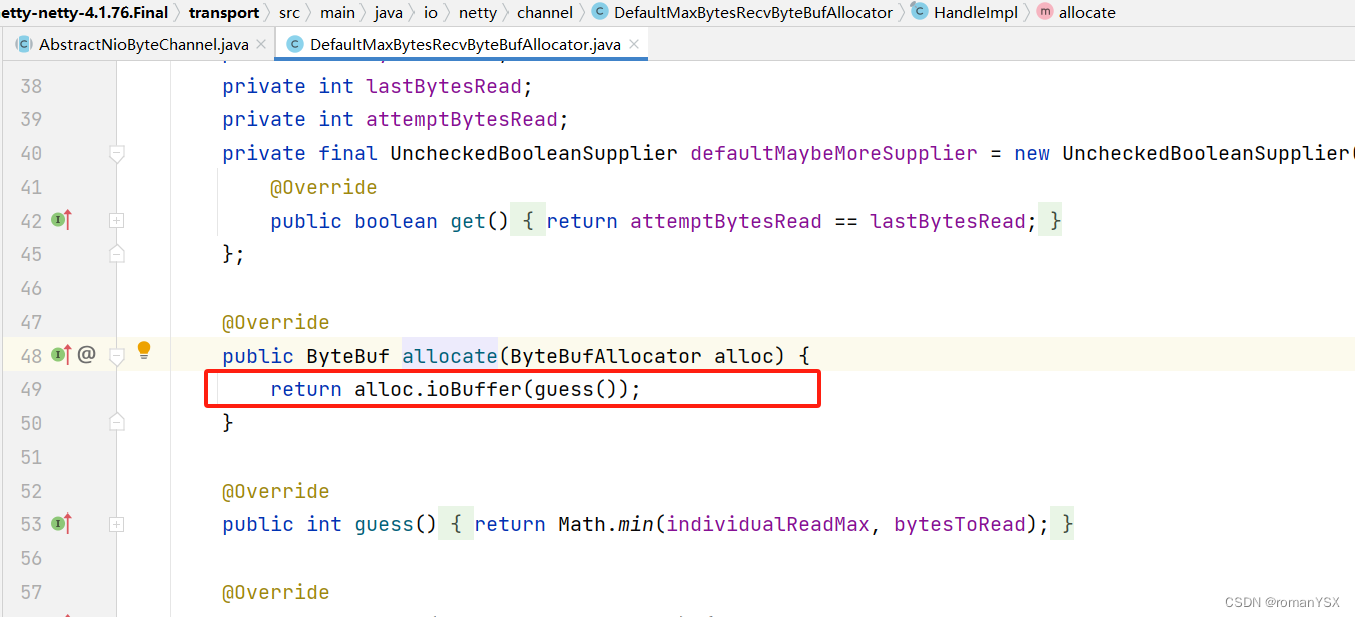
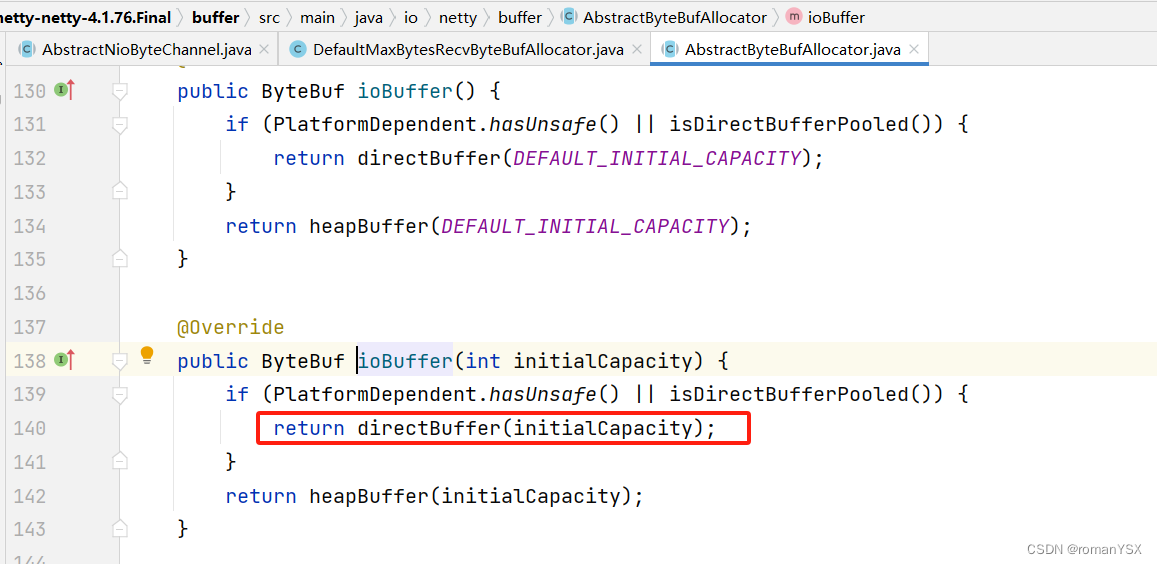
2.2 netty 内存池
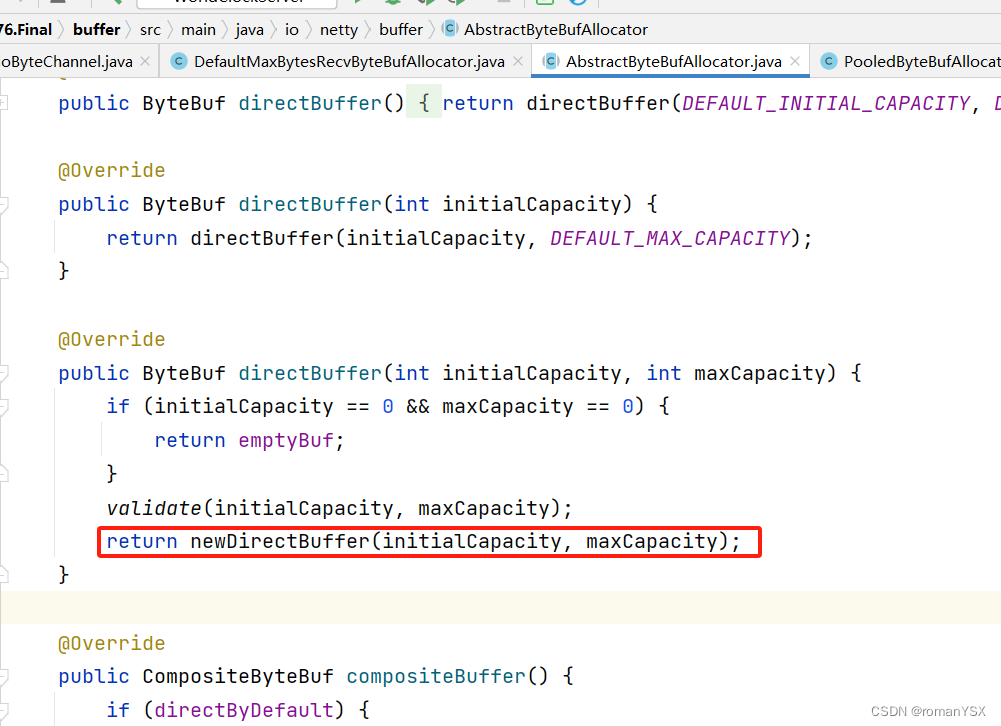
继续看newDirectBuffer的实现,会看到一个是池化的实现,一个是非池化的实现

思考一下,为什么要将内存池化呢?
我们知道,内存中的空间大都是碎片化的,想要分配到一块合适大小的内存空间是比较难的,那么,提前将一块一块的内存申请好放到一个缓冲池中,是个不错的办法
//io.netty.buffer.PooledByteBufAllocator#newDirectBuffer
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
三、零拷贝的两种方式
知道了什么是直接内存和零拷贝,接下来看一下实现零拷贝的两种方法:mmap和sendFile
这两种方法在讲kafka零拷贝的时候有讲过:深度解析Kafka为何如此高效
- mmap文件映射机制
这种方式是在用户态不再缓存整个IO的内容,改为只持有文件的一些映射信息。通过这些映射,"遥控"内核态的文件读写。这样就减少了内核态与用户态之间的拷贝数据大小,提升了IO效率。
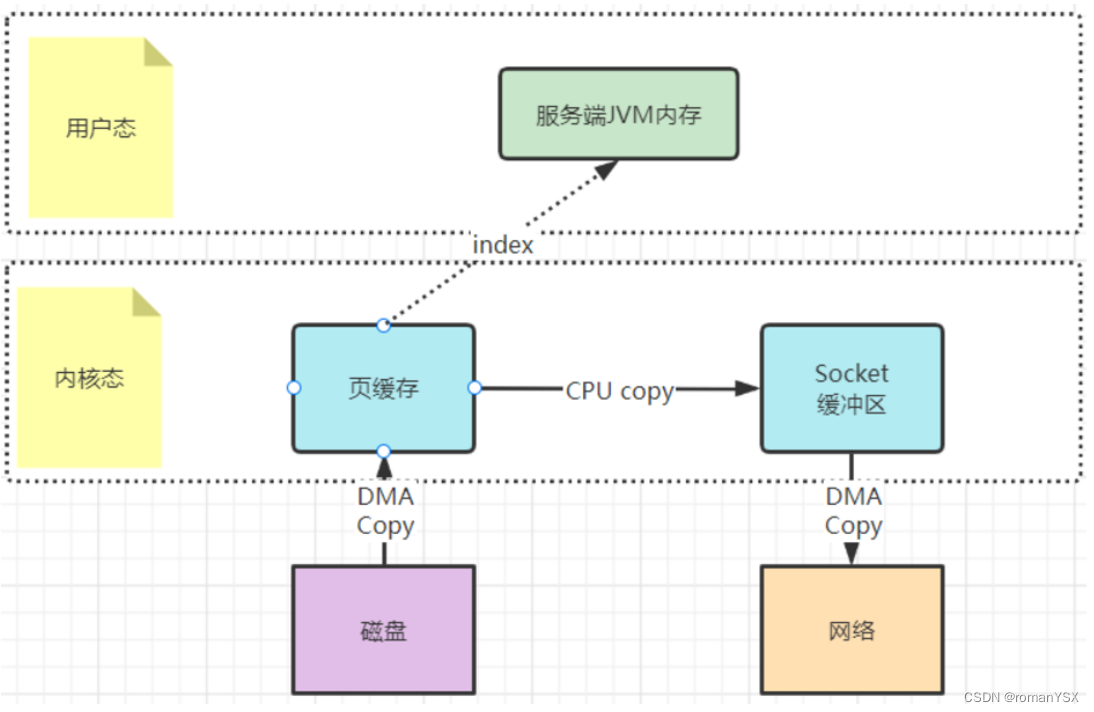
mmap文件映射机制是操作系统提供的一种文件操作机制,可以使用man 2 mmap查看。实际上在Java程序执行过程当中就会被大量使用。可以参考下JDK中的DirectByteBuffer实现机制
这种mmap文件映射方式,适合于操作不是很大的文件,通常映射的文件不建议超过2G。所以kafka将.log日志文件设计成1G大小,超过1G就会另外再新写一个日志文件。这就是为了便于对文件进行映射,从而加快对.log文件等本地文件的写入效率。
- sendfile文件传输机制
这种机制可以理解为用户态,也就是应用程序不再关注数据的内容,只是向内核态发一个sendfile指令,要他去复制文件就行了。这样数据就完全不用复制到用户态,从而实现了零拷贝。相比mmap,连索引都不读了,直接通知操作系统去拷贝就是了。
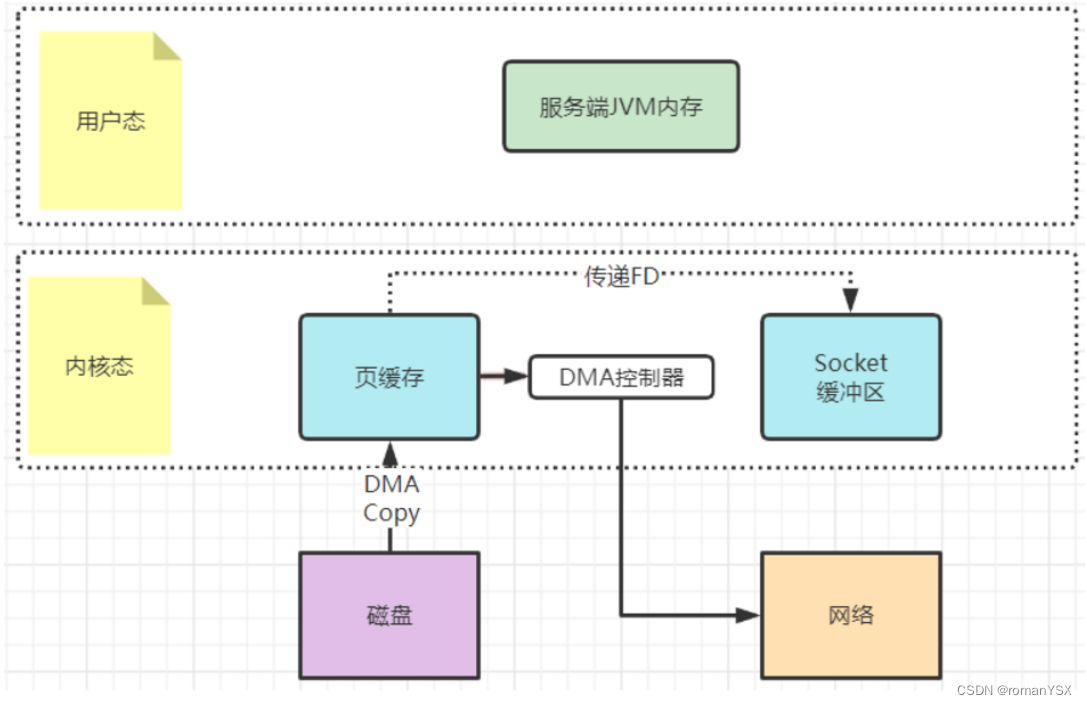 例如在Kafka中,当Consumer要从Broker上poll消息时,Broker需要读取自己本地的数据文件,然后通过网卡发送给Consumer。这个过程当中,Broker只负责传递消息,而不对消息进行任何的加工。所以Broker只需要将数据从磁盘读取出来,复制到网卡的Socket缓冲区,然后通过网络发送出去。这个过程当中,用户态就只需要往内核态发一个sendfile指令,而不需要有任何的数据拷贝过程。Kafka大量的使用了sendfile机制,用来加速对本地数据文件的读取过程。
例如在Kafka中,当Consumer要从Broker上poll消息时,Broker需要读取自己本地的数据文件,然后通过网卡发送给Consumer。这个过程当中,Broker只负责传递消息,而不对消息进行任何的加工。所以Broker只需要将数据从磁盘读取出来,复制到网卡的Socket缓冲区,然后通过网络发送出去。这个过程当中,用户态就只需要往内核态发一个sendfile指令,而不需要有任何的数据拷贝过程。Kafka大量的使用了sendfile机制,用来加速对本地数据文件的读取过程。
具体细节可以在linux机器上使用man 2 sendfile指令查看操作系统的帮助文件。JDK中8中java.nio.channels.FileChannel类提供了transferTo和transferFrom方法,底层就是使用了操作系统的sendfile机制。
这些底层的优化机制都是操作系统提供的优化机制,其实针对任何上层应用语言来说,都是一个黑盒,只能去调用,但是控制不了具体的实现过程。而上层的各种各样的语言,也只能根据操作系统提供的支持进行自己的实现。虽然不同语言的实现方式会有点不同,但是本质都是一样的。