01.在翻译、语音识别等将一个时序数据转换为另一个时序数据的任务中,时序数据之间常常存在对应关系
引入了Attention的概念,介绍了Attention的注意力机制:

困难出现,seq2seq的问题引入:固定化长度问题(过于死板)占用的资源过多
具体化实例引入:就好比把衣服乱塞,早晚都会出问题———衣服找不到的,回到案例:我们用固定化长度,终将会造成信息溢出的问题。
解决方案引入:编码器改进(核心:根据输出的隐藏层来对信息进行合理的长度规划) 
长度改变的策略:隐藏层线索改善
问题连锁发现:各个输出的向量中蕴含着各个单词的对应信息,为接下来的Attention从数据中学习两个时序的对应关系埋下伏笔:
讲述了编码器的改进:可以根据输出的隐藏层灵活变换,减少不必要的信息扩充(核心:简化)
解码器随着编码器的改进一同改进:核心目的:提高机器学习seq2seq的效率,优化程序。

下面核心强调了对齐对机器翻译的好处:(这里是专注于一个单词,或者是单词集合的;举个例子:例如:中文“猫”,翻译程序就将英文“cat”与“绑定”,像不像一个男孩极致去只爱一个女孩!!!浪漫,为什么我热衷于这种思维?嘿嘿,看过斗罗大陆的宝子们都知道答案的嘞,每部都是男主只爱女主一个人,无论发生什么!所以这也许是斗罗留给我童年最珍贵的礼物吧,O(∩_∩)O哈哈~)
类比人类玩极致(就是将精力全部放在一件事情上,也类似于斗罗大陆的极致武魂:斗罗大陆2:绝世唐门:霍雨浩的极致之冰(冰碧帝皇蝎),王秋儿的极致之光明和极致之力量(金龙王),马小桃的极致之火(邪火凤凰),斗罗大陆4:终极斗罗:蓝轩宇的九种元素全部极致,(蓝银皇武魂,龙神血脉!!!)哈哈)
极致就是那么无敌!!!
也可以理解绝对的专注!!!
一生专注做于一件事!!!
一生专注爱一个人!!!
一生专注于一个梦想!!!


介绍了改进后的解码器层结构,然后引出了下文Atttention的可微对下面用到的神经网络的学习核心:误差反向传播法的重要性,为啥重要?因为:不可微分的话,误差反向传播法就用不了啦(没错,就是数学的可微分的意思,宝子要相信自己!)
02.Attention 从数据中学习两个时序数据之间的对应关系
接下来,介绍了一个实战案例:日期格式转换的嘞
核心:就是你随便输一个格式的日期,她都会给你转换成一种固定的格式。

机器学习的本质:你给他准备好一个一个好的数据集,给他些时间,他会自己探索其中的规律的。
这里我们给他了一个5000个日期的数据集,让他学习一下。

学习结果:通过终端看:
学习正确率:通过图像来看
通过图像对比基础状态,偷窥状态,和注意力状态学习的效率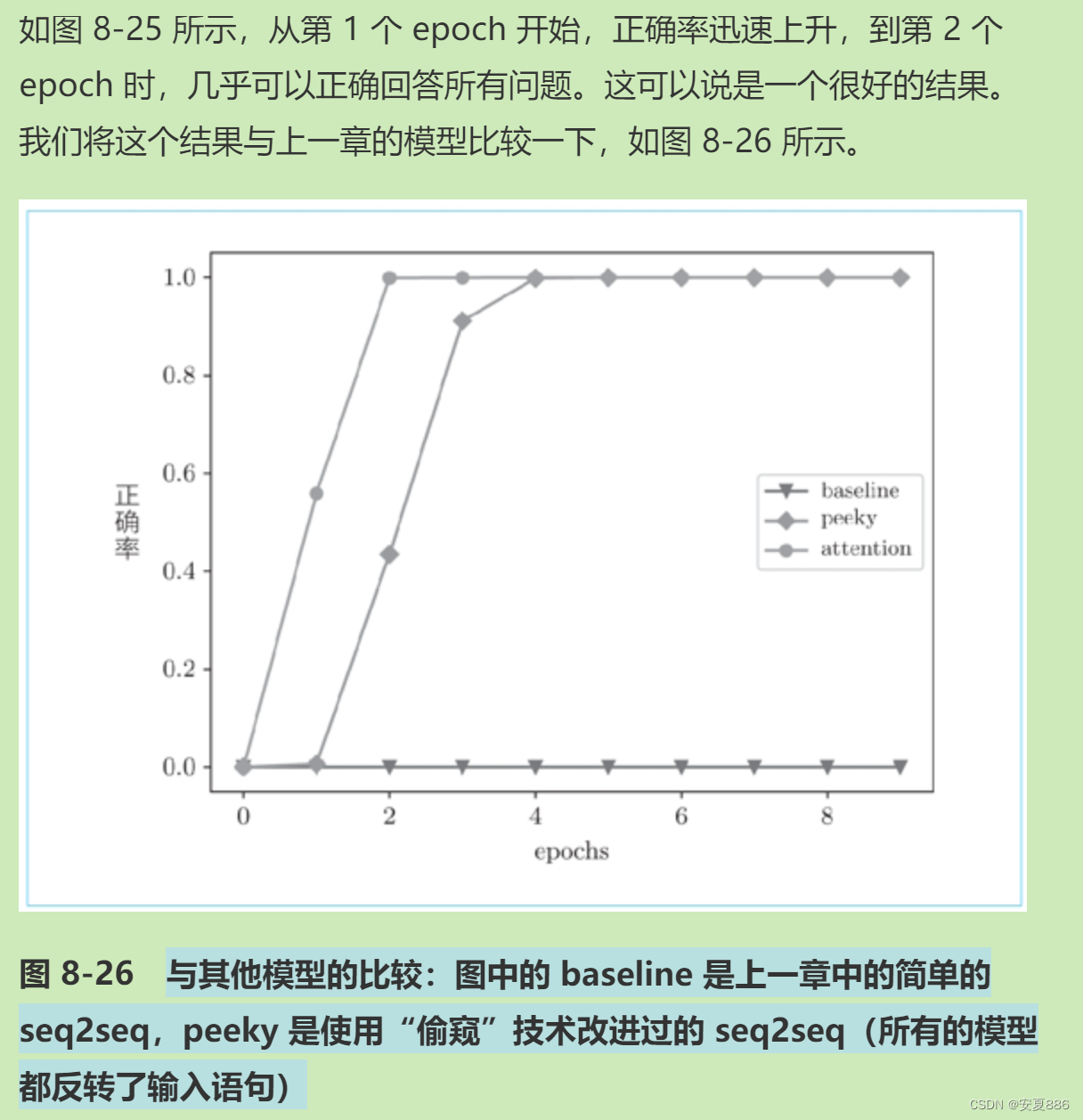
03.Attention 使用向量内积(方法之一)计算向量之间的相似度,并输出这个相似度的加权和向量
先说明:向量内积计算相似度,并输出加权和的核心目的:就是为了帮助更好的实现之前所说的Attention的对齐,也就是玩极致,让每个单词都对应一个翻译后的单词,提高翻译效率和准确率(书上称为精度:也就是精准度,看你翻译的好不好的嘞)。然后就没了的,所以学习这部分不用害怕的。


讲述了通过加权和计算可以得到上下文的向量(也就是坐标) ,抽象可以理解为机器理解啦翻译这个工作的嘞
(偷偷说,这难道不是我们小学的记答案,摸索答案的规律,然后蒙答案嘛,真的神似,说实话,机器其实啥也不会的,很笨很笨,但是,一些大牛通过让机器(也就是电脑,还可以称呼他为图灵机)学习大量的数据,从大量数据中摸索规律,然后成功的让机器大概了解怎么为人类工作的,对的,机器就是那么笨的,不怕你笑话的,但是机器有几点优点:不死性和可以精准学习我们人类根本难以想象的数据内容的,这就决定了人类通过现有的方式是永远也没有任何胜算的,但人类也有机器无法媲美的优点,那就是人类不完美中绽放着完美之花!!!熠熠生辉。人类的任何灵感和大胆的想法,更加是机器所无法取代的!!!)
人类可以没有机器聪明,但是可以比机器更蠢哇!有时候,做个可爱的小蠢货也挺好得嘞!
两个极端都是一种智慧!聪明与蠢蠢,大智如愚嘛!
未来,我就做个可爱的小蠢货啦!哈哈



接着再讲一下解码器的改进:
核心:为Attention服务
初心:为了让机器翻译功能更精准!优化机器翻译。


介绍了向量内积的基础概念和实战案例:
然后啥是相似度?
(
hs是个啥?
使用编码器各个时刻(各个单词)的 LSTM 层的隐藏状态(这里表示为 hs)
)
LSTM这个加工厂的隐藏层状态的加工品和另一个工厂的加工品对比一下的嘞
可以类似:华强北的师傅们的copyApple的优秀产品的
向优秀者学习:这可是乔布斯老爷子的至理名言!
没说谎,Stay hungry,stay foolish.
Good artists copy, great artists steal!
优秀者模仿,伟大者剽窃!
高尚是高尚者的墓志铭,卑鄙是卑鄙者的通行证!
--这也许就是好人难做的法则吧!
做人嘛,我个人还是分裂型人格的,善良与邪恶都要有的
面对善良的人,那就是善良的
面对恶人,那就是邪恶的!
用善良对待值得的人,用邪恶保护善良!


然后老一套,softmax


import sys
sys.path.append('..')
from common.layers import Softmax
import numpy as np
N, T, H = 10, 5, 4
hs = np.random.randn(N, T, H)
h = np.random.randn(N, H)
hr = h.reshape(N, 1, H).repeat(T, axis=1)
# hr = h.reshape(N, 1, H) # 广播
t = hs * hr
print(t.shape)
# (10, 5, 4)
s = np.sum(t, axis=2)
print(s.shape)
# (10, 5)
softmax = Softmax()
a = softmax.forward(s)
print(a.shape)
# (10, 5) 


class Attention:
def __init__(self):
self.params, self.grads = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = None
def forward(self, hs, h):
a = self.attention_weight_layer.forward(hs, h)
out = self.weight_sum_layer.forward(hs, a)
self.attention_weight = a
return out
def backward(self, dout):
dhs0, da = self.weight_sum_layer.backward(dout)
dhs1, dh = self.attention_weight_layer.backward(da)
dhs = dhs0 + dhs1
return dhs, dh 


TimeAttention代码实现:
class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None
def forward(self, hs_enc, hs_dec):
N, T, H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer = Attention()
out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:])
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return out
def backward(self, dout):
N, T, H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer = self.layers[t]
dhs, dh = layer.backward(dout[:, t, :])
dhs_enc += dhs
dhs_dec[:,t,:] = dh
return dhs_enc, dhs_dec解释:

作者提出用一个更加简单的数据集来验证我们上述学习的正确性的:

04.因为 Attention 中使用的运算是可微分的,所以可以基于误差反向传播法进行学习

05.通过将 Attention 计算出的权重(概率)可视化,可以观察输入与输出之间的对应关系

通过下图,我们可以发现:
机器学习出了时间格式转换的规律的:



作者态度也是那样,他也不理解机器是怎么最基础的学习的,但是我们可以用自己所理解的方式去理解机器如何学习的!

06.在基于外部存储装置扩展神经网络的研究示例中,Attention 被用来读写内存
三个实际应用的介绍:
证明作者教我们的知识是有用的!
1.谷歌公司 机器翻译案例:



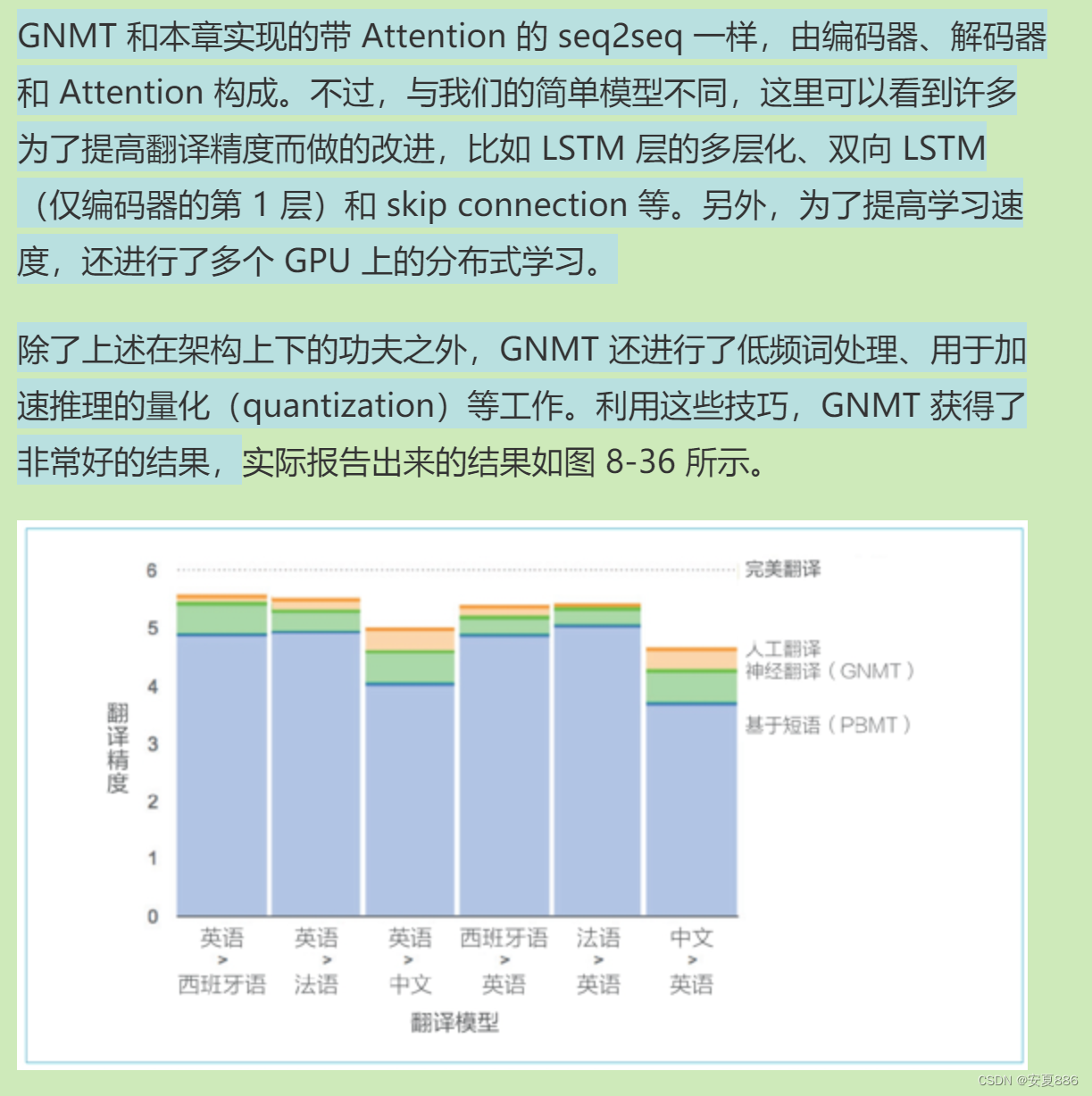

2.Transformer案例:取代RNN优化学习



3.NTM:基于外部存储装置的扩展的光明前景







小结
本章我们学习了 Attention 的结构,并实现了 Attention 层。然后,我们使用 Attention 实现了 seq2seq,并通过简单的实验,确认了 Attention 的出色效果。另外,我们对模型推理时的 Attention 的权重(概率)进行了可视化。从结果可知,具有 Attention 的模型以与人类相同的方式将注意力放在了必要的信息上。
另外,本章还介绍了有关 Attention 的前沿研究。从多个例子可知,Attention 扩展了深度学习的可能性。Attention 是一种非常有效的技术,具有很大潜力。在深度学习领域,今后 Attention 自己也将吸引更多的“注意力”。