🌟欢迎来到 我的博客 —— 探索技术的无限可能!
🌟博客的简介(文章目录)
前言
-
本项目综合了基本数据分析的流程,包括数据采集(爬虫)、数据清洗、数据存储、数据前后端可视化等
-
推荐阅读顺序为:数据采集——>数据清洗——>数据库存储——>基于Flask的前后端交互,有问题的话可以留言,有时间我会解疑~
-
感谢阅读、点赞和关注
开发环境
- 系统:Window 10 家庭中文版。
- 语言:Python(3.9)、MySQL。
- Python所需的库:pymysql、pandas、numpy、time、datetime、requests、etree、jieba、re、json、decimal、flask(没有的话pip安装一下就好)。
- 编辑器:jupyter notebook、Pycharm、SQLyog。
(如果下面代码在jupyter中运行不完全,建议直接使用Pycharm中运行)
文件说明
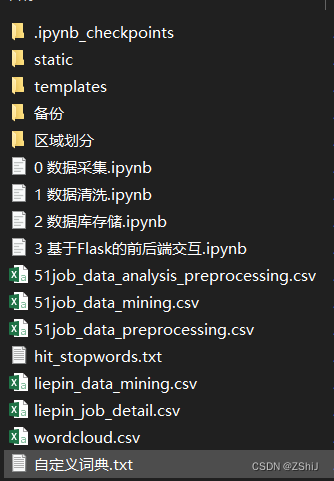
本项目下面有四个.ipynb的文件,下面分别阐述各个文件所对应的功能:(有py版本 可后台留言)
-
数据采集:分别从前程无忧网站和猎聘网上以关键词数据挖掘爬取相关数据。其中,前程无忧上爬取了270页,有超过1万多条数据;而猎聘网上只爬取了400多条数据,主要为岗位要求文本数据,最后将爬取到的数据全部储存到csv文件中。
-
数据清洗:对爬取到的数据进行清洗,包括去重去缺失值、变量重编码、特征字段创造、文本分词等。
-
数据库存储:将清洗后的数据全部储存到MySQL中,其中对文本数据使用jieba.analyse下的extract_tags来获取文本中的关键词和权重大小,方便绘制词云。
-
基于Flask的前后端交互:使用Python一个小型轻量的Flask框架来进行Web可视化系统的搭建,在static中有css和js文件,js中大多为百度开源的ECharts,再通过自定义controller.js来使用ajax调用flask已设定好的路由,将数据异步刷新到templates下的main.html中。
技术栈
- Python爬虫:(requests和xpath)
- 数据清洗:详细了解项目中数据预处理的步骤,包括去重去缺失值、变量重编码、特征字段创造和文本数据预处理 (pandas、numpy)
- 数据库知识:select、insert等操作,(增删查改&pymysql) 。
- 前后端知识:(HTML、JQuery、JavaScript、Ajax)。
- Flask知识:一个轻量级的Web框架,利用Python实现前后端交互。(Flask)
一、数据采集(爬虫)
1.前程无忧数据爬虫
前程无忧反爬最难的地方应该就是在点击某个网页进入之后所得到的具体内容,这部分会有个滑动验证码,只要使用Python代码爬数据都会被监视到,用selenium自动化操作也会被监视
这里使用猎聘网站上数据挖掘的岗位要求来代替前程无忧
import requests
import re
import json
import time
import pandas as pd
import numpy as np
from lxml import etree
通过输入岗位名称和页数来爬取对应的网页内容
job_name = input('请输入你想要查询的岗位:')
page = input('请输入你想要下载的页数:')
浏览器伪装
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
# 每个页面提交的参数,降低被封IP的风险
params = {
'lang': 'c',
'postchannel': '0000',
'workyear': '99',
'cotype': '99',
'degreefrom': '99',
'jobterm': '99',
'companysize': '99',
'ord_field': '0',
'dibiaoid': '0'
}
href, update, job, company, salary, area, company_type, company_field, attribute = [], [], [], [], [], [], [], [], []
为了防止被封IP,下面使用基于redis的IP代理池来获取随机IP,然后每次向服务器请求时都随机更改我们的IP(该ip_pool搭建相对比较繁琐,此处省略搭建细节)
假如不想使用代理IP的话,则直接设置下方的time.sleep,并将proxies参数一并删除
proxypool_url = 'http://127.0.0.1:5555/random'
# 定义获取ip_pool中IP的随机函数
def get_random_proxy():
proxy = requests.get(proxypool_url).text.strip()
proxies = {'http': 'http://' + proxy}
return proxies
使用session的好处之一便是可以储存每次的cookies,注意使用session时headers一般只需放上user-agent
session = requests.Session()
# 查看是否可以完成网页端的请求
session.get('https://www.51job.com/', headers = headers, proxies = get_random_proxy())
爬取每个页面下所有数据
for i in range(1, int(page) + 1):
url = f'https://search.51job.com/list/000000,000000,0000,00,9,99,{job_name},2,{i}.html'
response = session.get(url, headers = headers, params = params, proxies = get_random_proxy())
# 使用正则表达式提取隐藏在html中的岗位数据
ss = '{' + re.findall(r'window.__SEARCH_RESULT__ = {(.*)}', response.text)[0] + '}'
# 加载成json格式,方便根据字段获取数据
s = json.loads(ss)
data = s['engine_jds']
for info in data:
href.append(info['job_href'])
update.append(info['issuedate'])
job.append(info['job_name'])
company.append(info['company_name'])
salary.append(info['providesalary_text'])
area.append(info['workarea_text'])
company_type.append(info['companytype_text'])
company_field.append(info['companyind_text'])
attribute.append(' '.join(info['attribute_text']))
# time.sleep(np.random.randint(1, 2))
遍历每个链接,爬取对应的工作职责信息
可以发现有些页面点击进去需要进行滑动验证,这可能是因为频繁爬取的缘故,需要等待一段时间再进行数据的抓取,在不想要更换IP的情况下,可以选择使用time模块
for job_href in href:
job_response = session.get(job_href)
job_response.encoding = 'gbk'
job_html = etree.HTML(job_response.text)
content.append(' '.join(job_html.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div//p/text()')[1:]))
time.sleep(np.random.randint(1, 3))
保存数据到DataFrame
df = pd.DataFrame({'岗位链接': href, '发布时间': update, '岗位名称': job, '公司名称': company, '公司类型': company_type, '公司领域': company_field, '薪水': salary, '地域': area, '其他信息': attribute})
df.head()
看一下爬到了多少条数据
len(job)
保存数据到csv文件中
df.to_csv('./51job_data_mining.csv', encoding = 'gb18030', index = None)
2.爬取猎聘网站数据
浏览器伪装和相关参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'
}
job, salary, area, edu, exp, company, href, content = [], [], [], [], [], [], [], []
session = requests.Session()
session.get('https://www.liepin.com/zhaopin/', headers = headers)
通过输入岗位名称和页数来爬取对应的网页内容
job_name = input('请输入你想要查询的岗位:')
page = input('请输入你想要下载的页数:')
遍历每一页上的数据
for i in range(int(page)):
url = f'https://www.liepin.com/zhaopin/?key={job_name}&curPage={i}'
time.sleep(np.random.randint(1, 2))
response = session.get(url, headers = headers)
html = etree.HTML(response.text)
for j in range(1, 41):
job.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/h3/@title')[0])
info = html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/p[1]/@title')[0]
ss = info.split('_')
salary.append(ss[0])
area.append(ss[1])
edu.append(ss[2])
exp.append(ss[-1])
company.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[2]/p[1]/a/text()')[0])
href.append(html.xpath(f'//ul[@class="sojob-list"]/li[{j}]/div/div[1]/h3/a/@href')[0])
每页共有40条岗位信息
遍历每一个岗位的数据
for job_href in href:
time.sleep(np.random.randint(1, 2))
# 发现有些岗位详细链接地址不全,需要对缺失部分进行补齐
if 'https' not in job_href:
job_href = 'https://www.liepin.com' + job_href
response = session.get(job_href, headers = headers)
html = etree.HTML(response.text)
content.append(html.xpath('//section[@class="job-intro-container"]/dl[1]//text()')[3])
保存数据
df = pd.DataFrame({'岗位名称': job, '公司': company, '薪水': salary, '地域': area, '学历': edu, '工作经验': exp, '岗位要求': content})
df.to_csv('./liepin_data_mining.csv', encoding = 'gb18030', index = None)
df.head()