第2关:决策树算法原理
任务描述
本关任务:根据本关所学知识,完成 calcInfoGain 函数。
相关知识
为了完成本关任务,你需要掌握:
- 信息熵;
- 条件熵;
- 信息增益。
信息熵
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。
直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。信源的不确定性越大,信息熵也越大。
从机器学习的角度来看,信息熵表示的是信息量的期望值。如果数据集中的数据需要被分成多个类别,则信息量 I(xi) 的定义如下(其中 xi 表示多个类别中的第 i 个类别,p(xi) 数据集中类别为 xi 的数据在数据集中出现的概率表示):
I(Xi)=−log2p(xi)
由于信息熵是信息量的期望值,所以信息熵 H(X) 的定义如下(其中 n 为数据集中类别的数量):
H(X)=−i=1∑np(xi)log2p(xi)
从这个公式也可以看出,如果概率是 0 或者是 1 的时候,熵就是 0。(因为这种情况下随机变量的不确定性是最低的),那如果概率是 0.5 也就是五五开的时候,此时熵达到最大,也就是 1。(就像扔硬币,你永远都猜不透你下次扔到的是正面还是反面,所以它的不确定性非常高)。所以呢,熵越大,不确定性就越高。
条件熵
在实际的场景中,我们可能需要研究数据集中某个特征等于某个值时的信息熵等于多少,这个时候就需要用到条件熵。条件熵 H(Y|X) 表示特征X为某个值的条件下,类别为Y的熵。条件熵的计算公式如下:
H(Y∣X)=i=1∑npiH(Y∣X=xi)
当然条件熵的一个性质也熵的性质一样,概率越确定,条件熵就越小,概率越五五开,条件熵就越大。
信息增益
现在已经知道了什么是熵,什么是条件熵。接下来就可以看看什么是信息增益了。所谓的信息增益就是表示我已知条件 X 后能得到信息 Y 的不确定性的减少程度。
就好比,我在玩读心术。你心里想一件东西,我来猜。我已开始什么都没问你,我要猜的话,肯定是瞎猜。这个时候我的熵就非常高。然后我接下来我会去试着问你是非题,当我问了是非题之后,我就能减小猜测你心中想到的东西的范围,这样其实就是减小了我的熵。那么我熵的减小程度就是我的信息增益。
所以信息增益如果套上机器学习的话就是,如果把特征 A 对训练集 D 的信息增益记为 g(D, A) 的话,那么 g(D, A) 的计算公式就是:
g(D,A)=H(D)−H(D,A)
为了更好的解释熵,条件熵,信息增益的计算过程,下面通过示例来描述。假设我现在有这一个数据集,第一列是编号,第二列是性别,第三列是活跃度,第四列是客户是否流失的标签(0: 表示未流失,1: 表示流失)。
| 编号 | 性别 | 活跃度 | 是否流失 |
|---|---|---|---|
| 1 | 男 | 高 | 0 |
| 2 | 女 | 中 | 0 |
| 3 | 男 | 低 | 1 |
| 4 | 女 | 高 | 0 |
| 5 | 男 | 高 | 0 |
| 6 | 男 | 中 | 0 |
| 7 | 男 | 中 | 1 |
| 8 | 女 | 中 | 0 |
| 9 | 女 | 低 | 1 |
| 10 | 女 | 中 | 0 |
| 11 | 女 | 高 | 0 |
| 12 | 男 | 低 | 1 |
| 13 | 女 | 低 | 1 |
| 14 | 男 | 高 | 0 |
| 15 | 男 | 高 | 0 |
假如要算性别和活跃度这两个特征的信息增益的话,首先要先算总的熵和条件熵。总的熵其实非常好算,就是把标签作为随机变量 X。上表中标签只有两种(0和1)因此随机变量 X 的取值只有 0 或者 1。所以要计算熵就需要先分别计算标签为 0 的概率和标签为 1 的概率。从表中能看出标签为 0 的数据有 10 条,所以标签为 0 的概率等于 2/3。标签为 1 的概率为 1/3。所以熵为:
−(1/3)∗log(1/3)−(2/3)∗log(2/3)=0.9182
接下来就是条件熵的计算,以性别为男的熵为例。表格中性别为男的数据有 8 条,这 8 条数据中有 3 条数据的标签为 1,有 5 条数据的标签为 0。所以根据条件熵的计算公式能够得出该条件熵为:
−(3/8)∗log(3/8)−(5/8)∗log(5/8)=0.9543
根据上述的计算方法可知,总熵为:
−(5/15)∗log(5/15)−(10/15)∗log(10/15)=0.9182
性别为男的熵为:
−(3/8)∗log(3/8)−(5/8)∗log(5/8)=0.9543
性别为女的熵为:
−(2/7)∗log(2/7)−(5/7)∗log(5/7)=0.8631
活跃度为低的熵为:
−(4/4)∗log(4/4)−0=0
活跃度为中的熵为:
−(1/5)∗log(1/5)−(4/5)∗log(4/5)=0.7219
活跃度为高的熵为:
−0−(6/6)∗log(6/6)=0
现在有了总的熵和条件熵之后就能算出性别和活跃度这两个特征的信息增益了。
性别的信息增益=总的熵-(8/15)性别为男的熵-(7/15)性别为女的熵=0.0064
活跃度的信息增益=总的熵-(6/15)活跃度为高的熵-(5/15)活跃度为中的熵-(4/15)活跃度为低的熵=0.6776
那信息增益算出来之后有什么意义呢?回到读心术的问题,为了我能更加准确的猜出你心中所想,我肯定是问的问题越好就能猜得越准!换句话来说我肯定是要想出一个信息增益最大(减少不确定性程度最高)的问题来问你。其实 ID3 算法也是这么想的。ID3 算法的思想是从训练集 D 中计算每个特征的信息增益,然后看哪个最大就选哪个作为当前结点。然后继续重复刚刚的步骤来构建决策树。
编程要求
根据提示,在右侧编辑器 Begin-End 部分补充代码,完成 calcInfoGain 函数实现计算信息增益。
calcInfoGain函数中的参数:
feature:测试用例中字典里的feature,类型为ndarraylabel:测试用例中字典里的label,类型为ndarrayindex:测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
测试说明
平台会对你编写的代码进行测试,期望您的代码根据输入来输出正确的信息增益,以下为其中一个测试用例:
测试输入: {'feature':[[0, 1], [1, 0], [1, 2], [0, 0], [1, 1]], 'label':[0, 1, 0, 0, 1], 'index': 0}
预期输出: 0.419973
提示: 计算 log 可以使用 NumPy 中的 log2 函数
代码:
import numpy as np# 计算信息熵
def calcInfoEntropy(feature, label):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:return:信息熵,类型float
'''
#*********** Begin ***********#
label_set = set(label)
#print("the type of label_set is: ",type(label_set))
'''
print( label_set)
{0, 1}
{0}
{0, 1}
'''
result=0
#每个标签出现的概率,得出对应的p;[[0,3/5],[1,2/5],[0,3/5]...]
for l in label_set:#遍历集合中的每一个元素
count = 0
for j in range(len(label)):#print(len(label))=5
if label[j] == l:
count += 1
p = count/len(label)
result+=-p*np.log2(p)#H(X)
return result
#*********** End *************#
# 计算条件熵
def calcHDA(feature, label, index, value):
'''
计算信息熵
:param feature:数据集中的特征,类型为ndarray
:param label:数据集中的标签,类型为ndarray
:param index:需要使用的特征列索引,类型为int
:param value:index所表示的特征列中需要考察的特征值,类型为int
:return:信息熵,类型float
'''
#*********** Begin ***********#
count = 0
sub_feature = []#list
sub_label = []
#print(len(feature)):5
#print(feature):[[0, 1], [1, 0], [1, 2], [0, 0], [1, 1]] 两列分别代表性别和活跃度
for i in range(len(feature)):#i=0/1/2/3/4
#print(feature[i][index]) 0 1 1 0 1
if feature[i][index] == value:#若index=1,value=
count += 1
sub_feature.append(feature[i])#提取出符合特征的feature
'''
print(feature[i])
[1, 0]
[1, 2]
[1, 1]
'''
sub_label.append(label[i])#提取出符合特征的feature的对应标签
'''
print(label[i])
1
0
1
'''
pHA = count/len(feature)
e = calcInfoEntropy(sub_feature,sub_label)
return pHA*e
#*********** End *************#
def calcInfoGain(feature, label, index):
'''
计算信息增益
:param feature:测试用例中字典里的feature
:param label:测试用例中字典里的label
:param index:测试用例中字典里的index,即feature部分特征列的索引
:return:信息增益,类型float
'''
#*********** Begin ***********#
base_e = calcInfoEntropy(feature,label)
#print("base_e= ",base_e):base_e= 0.5287712379549449
f = np.array(feature)
'''
print(f)
[[0 1]
[1 0]
[1 2]
[0 0]
[1 1]]
'''
f_set = set(f[:, index])#提取标签
#print(f_set) :{0, 1}
sum_HDA = 0
for a in f_set:
sum_HDA += calcHDA(feature, label, index, a)
return base_e-sum_HDA
#*********** End *************#
第3关:动手实现 ID3 决策树
任务描述
本关任务:补充 python 代码,完成 DecisionTree 类中的 fit 和 predict 函数。
相关知识
为了完成本关任务,你需要掌握:
ID3算法构造决策树的流程;- 如何使用构造好的决策树进行预测。
ID3 算法构造决策树的流程
ID3 算法其实就是依据特征的信息增益来构建树的。其大致步骤就是从根结点开始,对结点计算所有可能的特征的信息增益,然后选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点,然后对子结点递归执行上述的步骤直到信息增益很小或者没有特征可以继续选择为止。
因此,ID3 算法伪代码如下:
#假设数据集为D,标签集为A,需要构造的决策树为treedef ID3(D, A):if D中所有的标签都相同:return 标签if 样本中只有一个特征或者所有样本的特征都一样:对D中所有的标签进行计数return 计数最高的标签计算所有特征的信息增益选出增益最大的特征作为最佳特征(best_feature)将best_feature作为tree的根结点得到best_feature在数据集中所有出现过的值的集合(value_set)for value in value_set:从D中筛选出best_feature=value的子数据集(sub_feature)从A中筛选出best_feature=value的子标签集(sub_label)#递归构造treetree[best_feature][value] = ID3(sub_feature, sub_label)return tree
如何使用构造好的决策树进行预测
决策树的预测思想非常简单,假设现在已经构建出了一棵用来决策是否买西瓜的决策树。
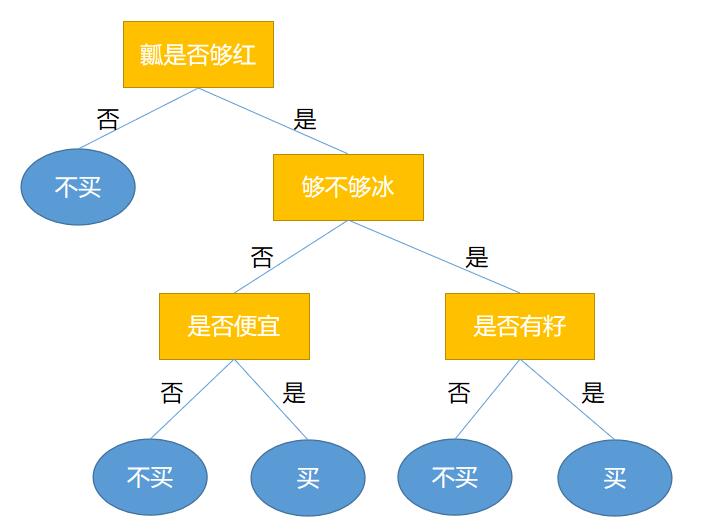
并假设现在在水果店里有这样一个西瓜,其属性如下:
| 瓤是否够红 | 够不够冰 | 是否便宜 | 是否有籽 |
|---|---|---|---|
| 是 | 否 | 是 | 否 |
那买不买这个西瓜呢?只需把西瓜的属性代入决策树即可。决策树的根结点是瓤是否够红,所以就看西瓜的属性,经查看发现够红,因此接下来就看够不够冰。而西瓜不够冰,那么看是否便宜。发现西瓜是便宜的,所以这个西瓜是可以买的。
因此使用决策树进行预测的伪代码也比较简单,伪代码如下:
#tree表示决策树,feature表示测试数据def predict(tree, feature):if tree是叶子结点:return tree根据feature中的特征值走入tree中对应的分支if 分支依然是课树:result = predict(分支, feature)return result
编程要求
根据提示,在右侧编辑器 Begin-End 部分补充代码, 填写 fit(self, feature, label) 函数,实现 ID3 算法,要求决策树保存在 self.tree 中。其中:
feature:训练集数据,类型为ndarray,数值全为整数label:训练集标签,类型为ndarray,数值全为整数
填写 predict(self, feature) 函数,实现预测功能,并将标签返回,其中:
feature:测试集数据,类型为ndarray,数值全为整数。(PS:feature中有多条数据)
测试说明
只需完成 fit 与 predict 函数即可,程序内部会调用您所完成的fit函数构建模型并调用 predict 函数来对数据进行预测。预测的准确率高于 0.92 视为过关。(PS:若 self.tree is None 则会打印决策树构建失败)
代码:
import numpy as np
# 计算熵
def calcInfoEntropy(label):
'''
input:
label(narray):样本标签
output:
InfoEntropy(float):熵
'''
label_set = set(label)
InfoEntropy = 0
for l in label_set:
count = 0
for j in range(len(label)):
if label[j] == l:
count += 1
# 计算标签在数据集中出现的概率
p = count / len(label)
# 计算熵
InfoEntropy -= p * np.log2(p)
return InfoEntropy
#计算条件熵
def calcHDA(feature,label,index,value):
'''
input:
feature(ndarray):样本特征
label(ndarray):样本标签
index(int):需要使用的特征列索引
value(int):index所表示的特征列中需要考察的特征值
output:
HDA(float):信息熵
'''
count = 0
# sub_feature和sub_label表示根据特征列和特征值分割出的子数据集中的特征和标签
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][index] == value:
count += 1
sub_feature.append(feature[i])
sub_label.append(label[i])
pHA = count / len(feature)
e = calcInfoEntropy(sub_label)
HDA = pHA * e
return HDA
#计算信息增益
def calcInfoGain(feature, label, index):
'''
input:
feature(ndarry):测试用例中字典里的feature
label(ndarray):测试用例中字典里的label
index(int):测试用例中字典里的index,即feature部分特征列的索引。该索引指的是feature中第几个特征,如index:0表示使用第一个特征来计算信息增益。
output:
InfoGain(float):信息增益
'''
base_e = calcInfoEntropy(label)
f = np.array(feature)
# 得到指定特征列的值的集合
f_set = set(f[:, index])
sum_HDA = 0
# 计算条件熵
for value in f_set:
sum_HDA += calcHDA(feature, label, index, value)
# 计算信息增益
InfoGain = base_e - sum_HDA
return InfoGain
# 获得信息增益最高的特征
def getBestFeature(feature, label):
'''
input:
feature(ndarray):样本特征
label(ndarray):样本标签
output:
best_feature(int):信息增益最高的特征
'''
#*********Begin*********#
max_infogain = 0
best_feature = 0
for i in range(len(feature[0])):
infogain = calcInfoGain(feature, label, i)
if infogain > max_infogain:
max_infogain = infogain
best_feature = i
#*********End*********#
return best_feature
#创建决策树
def createTree(feature, label):
'''
input:
feature(ndarray):训练样本特征
label(ndarray):训练样本标签
output:
tree(dict):决策树模型
'''
#*********Begin*********#
# 样本里都是同一个label没必要继续分叉了
if len(set(label)) == 1:
return label[0]
# 样本中只有一个特征或者所有样本的特征都一样的话就看哪个label的票数高
if len(feature[0]) == 1 or len(np.unique(feature, axis=0)) == 1:
vote = {}
for l in label:
if l in vote.keys():
vote[l] += 1
else:
vote[l] = 1
max_count = 0
vote_label = None
for k, v in vote.items():
if v > max_count:
max_count = v
vote_label = k
return vote_label
# 根据信息增益拿到特征的索引
best_feature = getBestFeature(feature, label)
tree = {best_feature: {}}
f = np.array(feature)
# 拿到bestfeature的所有特征值
f_set = set(f[:, best_feature])
# 构建对应特征值的子样本集sub_feature, sub_label
for v in f_set:
sub_feature = []
sub_label = []
for i in range(len(feature)):
if feature[i][best_feature] == v:
sub_feature.append(feature[i])
sub_label.append(label[i])
# 递归构建决策树
tree[best_feature][v] = createTree(sub_feature, sub_label)
#*********End*********#
return tree
#决策树分类
def dt_clf(train_feature,train_label,test_feature):
'''
input:
train_feature(ndarray):训练样本特征
train_label(ndarray):训练样本标签
test_feature(ndarray):测试样本特征
output:
predict(ndarray):测试样本预测标签
'''
#*********Begin*********#
result = []
tree = createTree(train_feature,train_label)
def classify(tree, feature):
if not isinstance(tree, dict):
return tree
t_index, t_value = list(tree.items())[0]
f_value = feature[t_index]
if isinstance(t_value, dict):
classLabel = classify(tree[t_index][f_value], feature)
return classLabel
else:
return t_value
for feature in test_feature:
result.append(classify(tree, feature))
predict = np.array(result)
#*********End*********#
return predict