深度优先搜索乃是注重深度,会把一条路径优先全部搜完然后再去回溯,再去搜其他路径
连通性模型
与BFS中的Flood Fill相似
AcWing.1112.迷宫
一天Extense在森林里探险的时候不小心走入了一个迷宫,迷宫可以看成是由 n∗n 的格点组成,每个格点只有2种状态,.和#,前者表示可以通行后者表示不能通行。
同时当Extense处在某个格点时,他只能移动到东南西北(或者说上下左右)四个方向之一的相邻格点上,Extense要从点A走到点B,问在不走出迷宫的情况下能不能办到。
如果起点或者终点有一个不能通行(为#),则看成无法办到。
注意:A、B不一定是两个不同的点。
输入格式
第1行是测试数据的组数 k,后面跟着 k 组输入。
每组测试数据的第1行是一个正整数 n,表示迷宫的规模是 n∗n 的。
接下来是一个 n∗n 的矩阵,矩阵中的元素为.或者#。
再接下来一行是 4 个整数 ha,la,hb,lb,描述 A 处在第 ha 行, 第 la 列,B 处在第 hb 行, 第 lb 列。
注意到 ha,la,hb,lb 全部是从 0 开始计数的。
输出格式
k行,每行输出对应一个输入。
能办到则输出“YES”,否则输出“NO”。
数据范围
1
≤
n
≤
100
1≤n≤100
1≤n≤100
输入样例:
2
3
.##
..#
#..
0 0 2 2
5
.....
###.#
..#..
###..
...#.
0 0 4 0
输出样例:
YES
NO
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 110;
const int dx[4] = {1,0,-1,0};
const int dy[4] = {0,1,0,-1};
bool st[N][N];
char g[N][N];
int n;
int xa,xb,ya,yb;
bool dfs(int x,int y){
if(x == xb && y == yb)return 1;
st[x][y] = 1;
for(int i = 0;i < 4;i++){
int a = x + dx[i],b = y + dy[i];
if(a >= 0 && a < n && y >= 0 && y < n && !st[a][b] && g[a][b] == '.'){
if(dfs(a,b))return 1;
}
}
return 0;
}
void solve(){
cin >> n;
for(int i = 0;i < n;i++)cin >> g[i];
memset(st,0,sizeof st);
cin >> xa >> ya >> xb >> yb;
if(g[xa][ya] == '#' || g[xb][yb] == '#'){
cout << "NO\n";
return;
}
if(dfs(xa,ya))cout << "YES\n";
else cout << "NO\n";
return;
}
int main(){
int t;cin >> t;
while(t--){
solve();
}
return 0;
}
AcWing.1113.红与黑
有一间长方形的房子,地上铺了红色、黑色两种颜色的正方形瓷砖。
你站在其中一块黑色的瓷砖上,只能向相邻(上下左右四个方向)的黑色瓷砖移动。
请写一个程序,计算你总共能够到达多少块黑色的瓷砖。
输入格式
输入包括多个数据集合。
每个数据集合的第一行是两个整数 W 和 H,分别表示 x 方向和 y 方向瓷砖的数量。
在接下来的 H 行中,每行包括 W 个字符。每个字符表示一块瓷砖的颜色,规则如下
1)‘.’:黑色的瓷砖;
2)‘#’:红色的瓷砖;
3)‘@’:黑色的瓷砖,并且你站在这块瓷砖上。该字符在每个数据集合中唯一出现一次。
当在一行中读入的是两个零时,表示输入结束。
输出格式
对每个数据集合,分别输出一行,显示你从初始位置出发能到达的瓷砖数(记数时包括初始位置的瓷砖)。
数据范围
1
≤
W
,
H
≤
20
1≤W,H≤20
1≤W,H≤20
输入样例:
6 9
....#.
.....#
......
......
......
......
......
#@...#
.#..#.
0 0
输出样例:
45
就是求联通块里面点的数量。
#include<bits/stdc++.h>
using namespace std;
const int N = 25;
const int dx[] = {1,0,-1,0};
const int dy[] = {0,1,0,-1};
char g[N][N];
int n,m;
int ix,iy;
bool st[N][N];
int dfs(int x,int y){
st[x][y] = 1;
int cnt = 1;
for(int i = 0;i < 4;i++){
int a = x + dx[i],b = y + dy[i];
if(a >= 0 && a < n && b >= 0 && b < m && g[a][b] == '.' && !st[a][b]){
cnt += dfs(a,b);
}
}
return cnt;
}
int main(){
while(cin >> m >> n , n != 0 || m != 0){
memset(st,0,sizeof st);
for(int i = 0;i < n;i++){
for(int j = 0;j < m;j++){
cin >> g[i][j];
if(g[i][j] == '@'){
ix = i,iy = j;
}
}
}
cout << dfs(ix,iy) << endl;
}
return 0;
}
搜索顺序
在DFS搜索的时候,需要设计出一个正确的搜索顺序来进行搜索,以保证不漏掉任何一个情况。
同时也应注意回溯状态,并且设计好回溯的时机等。
AcWing.1116.马走日
马在中国象棋以日字形规则移动。
请编写一段程序,给定 n∗m 大小的棋盘,以及马的初始位置 (x,y),要求不能重复经过棋盘上的同一个点,计算马可以有多少途径遍历棋盘上的所有点。
输入格式
第一行为整数 T,表示测试数据组数。
每一组测试数据包含一行,为四个整数,分别为棋盘的大小以及初始位置坐标 n,m,x,y。
输出格式
每组测试数据包含一行,为一个整数,表示马能遍历棋盘的途径总数,若无法遍历棋盘上的所有点则输出 0。
数据范围
1
≤
T
≤
9
,
1≤T≤9,
1≤T≤9,
1
≤
m
,
n
≤
9
,
1≤m,n≤9,
1≤m,n≤9,
1
≤
n
×
m
≤
28
,
1≤n×m≤28,
1≤n×m≤28,
0
≤
x
≤
n
−
1
,
0≤x≤n−1,
0≤x≤n−1,
0
≤
y
≤
m
−
1
0≤y≤m−1
0≤y≤m−1
输入样例:
1
5 4 0 0
输出样例:
32
使用深搜搜遍所有的情况,每次搜到填满n*m个点的时候就意味着满足了题目条件,就可以让答案加一。
在此种DFS问题中,需要注意回溯状态。
CODE:
#include <bits/stdc++.h>
using namespace std;
const int N = 10;
const int dx[] = {2, 2, -2, -2, 1, 1, -1, -1};
const int dy[] = {1, -1, 1, -1, 2, -2, 2, -2};
int n, m;
bool st[N][N];
int ans = 0;
void dfs(int ix, int iy, int cnt)
{
if (cnt == n * m) //填满了之后才符合情况
{
ans++;
return;
}
for (int i = 0; i < 8; i++)
{
int a = ix + dx[i], b = iy + dy[i];
if (a >= 0 && a < n && b >= 0 && b < m && !st[a][b])
{
st[a][b] = 1; //标记
dfs(a, b, cnt + 1);
st[a][b] = 0; //回溯
}
}
}
void solve()
{
int x, y;
cin >> n >> m >> x >> y;
ans = 0;
st[x][y] = 1; //先标上起点
dfs(x, y, 1);
st[x][y] = 0; //要注意回溯这个状态
cout << ans << endl;
return;
}
int main()
{
int t;
cin >> t;
while (t--)
{
solve();
}
return 0;
}
AcWing.1117.单词接龙
单词接龙是一个与我们经常玩的成语接龙相类似的游戏。
现在我们已知一组单词,且给定一个开头的字母,要求出以这个字母开头的最长的“龙”,每个单词最多被使用两次。
在两个单词相连时,其重合部分合为一部分,例如 beast 和 astonish ,如果接成一条龙则变为 beastonish。
我们可以任意选择重合部分的长度,但其长度必须大于等于1,且严格小于两个串的长度,例如 at 和 atide 间不能相连。
输入格式
输入的第一行为一个单独的整数 n 表示单词数,以下 n 行每行有一个单词(只含有大写或小写字母,长度不超过20),输入的最后一行为一个单个字符,表示“龙”开头的字母。
你可以假定以此字母开头的“龙”一定存在。
输出格式
只需输出以此字母开头的最长的“龙”的长度。
数据范围
n
≤
20
,
n≤20,
n≤20,
单词随机生成。
输入样例:
5
at
touch
cheat
choose
tact
a
输出样例:
23
提示
连成的“龙”为 atoucheatactactouchoose。
如果想要直接搜哪个单词连上哪个单词简直是无稽之谈,非常困难,所以我们先处理出来哪些单词之间可以相连,然后就只需要再去搜所有的连接情况就可以了。
并且如果单词相连的长度越短,那么最终能得到的长度越长。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 25;
int n;
string words[N];//记录单词
int g[N][N]; //记录两个单词之间最短的相连长度
int used[N]; //记录每个单词用过几次
int ans;
void dfs(string str,int last){
ans = max((int)str.size(),ans); //每次答案直接取最大值即可
used[last]++; //结尾的单词用的次数加1
for(int i = 0;i < n;i++){
if(g[last][i] && used[i] < 2){ //如果这个单词能够相连并且没有被用过2次
dfs(str+words[i].substr(g[last][i]),i); //接上这一个单词去搜索
}
}
used[last]--; //回溯状态
}
int main(){
cin >> n;
for(int i = 0;i < n;i++)cin >> word[i];
char st;
cin >> st;
for(int i = 0;i < n;i++){ //预处理所有单词之间相连的情况
for(int j = 0;j < n;j++){ //这里i == j的时候不要continue,因为可以有两个相同的相连
string a = words[i],b = words[j];
for(int k = 1;k < min(a.size(),b.size());k++){ //这里枚举能够相连的长度
if(a.substr(a.size() - k,k) == b.substr(0,k)){ //枚举a的结尾和b的开头
g[i][j] = k; //i和j之间能够相连的长度最小为k
break; //取最小值,所以直接break掉
}
}
}
}
for(int i = 0;i < n;i++){ //找到那个首字母是题目要求的那个单词,开始搜索
if(words[i][0] == st){
dfs(words[i],i);
}
}
return 0;
}
AcWing.1118.分成互质组
给定 n n n 个正整数,将它们分组,使得每组中任意两个数互质。
至少要分成多少个组?
输入格式
第一行是一个正整数
n
n
n。
第二行是 n n n 个不大于10000的正整数。
输出格式
一个正整数,即最少需要的组数。
数据范围
1
≤
n
≤
10
1≤n≤10
1≤n≤10
输入样例:
6
14 20 33 117 143 175
输出样例:
3
可以将这个问题转化为图论的问题,如果两个数不互质,那么就把他们连起来,那么问题就转化为了把图中的所有点最少分成多少组,才能使得每一组都没有边。
那么在用DFS的过程中,我们要保证不漏条件并且还要节省时空。
可以进行两种决策,第一种是把某个数加到最后一组,第二个数开一个新组。
并且如果某个数可以加到最后一组的时候就不要开一个新组,因为题目要求至少,所以尽可能开少,并且如果某个数加到新组里面之后是符合题目要求的,那么就算拿出来这个数,这个组余下的数还是符合要求的。
并且在这道题中,组中数的顺序和结果无关,所以直接进行组合搜索而不是排序搜索。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 10;
int n;
int p[N]; //存数
int group[N][N]; //分组
bool vis[N]; //标记搜没搜过
int ans = N; //答案最坏也是N
int gcd(int a,int b){
int c;
while(b){
c = a%b;
a = b;
b = c;
}
return a;
}
bool check(int group[],int id,int a){
for(int j = 0;j < id;j++){ //在组内,从下标0搜到当前下标,查看是否有任何一个数不满足条件
if(gcd(group[j],a) > 1){ //如果不互质返回false
return false;
}
}
return 1;
}
void dfs(int u,int id,int cnt,int st){ //当前搜到第几组,元素应该放到组内的下标,已经分完了多少元素,这一层从哪一个元素开始搜
if(u >= ans)return; //如果已经大于答案了直接返回
if(cnt == n){ //搜完了n个元素
ans = u;
}
bool flag = 1; //检测是不是有元素能够放入
for(int i = st;i < n;i++){
if(!vis[i] && check(group[u],id,p[i])){
vis[i] = 1;
group[u][id] = p[i]; //在第u组第id下标存入p[i]
dfs(u,id+1,cnt+1,i+1); //第u组下标加1,分的元素数加1,从下一个元素开始搜
vis[i] = 0; //回溯
flag = 0; //标记能放入
}
}
//如果没有元素能够放入,就新开一个组来放
if(flag)dfs(u+1,0,cnt,0);
}
int main(){
cin >> n;
for(int i = 0;i < n;i++)cin >> p[i];
dfs(1,0,0,0);
cout << ans << endl;
return 0;
}
剪枝
每一个搜索都对应了一颗搜索树,那么有的时候走到中间的时候就可以发现结果不会满足我们的要求,那么我们就可以直接抛弃这条路,达到优化搜索的结果。
剪枝策略:
优化搜索顺序:
优先选择搜索分支较少的节点。
排除等效冗余:
尽量保证不搜索重复的状态,即如果不考虑顺序就尽量进行组合搜索
可行性剪枝:
在途中把不合法的状态剪掉
最优性剪枝:
在途中把不优于当前答案的剪掉
记忆化搜索:
DP
AcWing.165.小猫爬山
翰翰和达达饲养了 N 只小猫,这天,小猫们要去爬山。
经历了千辛万苦,小猫们终于爬上了山顶,但是疲倦的它们再也不想徒步走下山了(呜咕>_<)。
翰翰和达达只好花钱让它们坐索道下山。
索道上的缆车最大承重量为 W,而 N 只小猫的重量分别是 C 1 、 C 2 … … C N C_1、C_2……C_N C1、C2……CN。
当然,每辆缆车上的小猫的重量之和不能超过 W。
每租用一辆缆车,翰翰和达达就要付 1 美元,所以他们想知道,最少需要付多少美元才能把这 N 只小猫都运送下山?
输入格式
第 1 行:包含两个用空格隔开的整数,
N
N
N 和
W
W
W。
第 2…
N
+
1
N+1
N+1 行:每行一个整数,其中第 i+1 行的整数表示第 i 只小猫的重量
C
i
C_i
Ci。
输出格式
输出一个整数,表示最少需要多少美元,也就是最少需要多少辆缆车。
数据范围
1
≤
N
≤
18
,
1≤N≤18,
1≤N≤18,
1
≤
C
i
≤
W
≤
108
1≤C_i≤W≤108
1≤Ci≤W≤108
输入样例:
5 1996
1
2
1994
12
29
输出样例:
2
在这道题中,存在两种决策,第一个是把小猫放到当前的车上,第二种是另找一辆车。
如果我们先放重猫,那么就会导致一辆车能够容纳的猫更少,所以会搜出来的节点就会更少,相反如果先放轻猫,就会导致一辆车可以容纳多个猫,就会使节点数量变多。
所以先放重猫可以使得节点数量更少。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 20;
int n,m;
int w[N];
int sum[N];
int ans = N;
void dfs(int u,int cnt){ //u:搜到第u个猫,cnt:开了多少辆车
if(cnt >= ans)return; //最优性剪枝
if(u == n){
ans = cnt;
return;
}
for(int i = 0;i < cnt;i++){ //枚举车
if(sum[i] + w[u] <= m){ //可行性剪枝
sum[i] += w[u];
dfs(u+1,cnt);
sum[i] -= w[u]; //回溯
}
}
sum[cnt] = w[u]; //新开一辆车
dfs(u+1,cnt+1);
sum[cnt] = 0;
}
int main(){
cin >> n >> m;
for(int i = 0;i < n;i++)cin >> w[i];
sort(w,w+n); //优化剪枝顺序,先搜重的
reverse(w,w+n);
dfs(0,0);
cout << ans << endl;
return 0;
}
AcWing.166.数独
数独 是一种传统益智游戏,你需要把一个 9×9 的数独补充完整,使得数独中每行、每列、每个 3×3 的九宫格内数字 1∼9 均恰好出现一次。
请编写一个程序填写数独。
输入格式
输入包含多组测试用例。
每个测试用例占一行,包含 81 个字符,代表数独的 81 个格内数据(顺序总体由上到下,同行由左到右)。
每个字符都是一个数字(1−9)或一个 .(表示尚未填充)。
您可以假设输入中的每个谜题都只有一个解决方案。
文件结尾处为包含单词 end 的单行,表示输入结束。
输出格式
每个测试用例,输出一行数据,代表填充完全后的数独。
输入样例:
4.....8.5.3..........7......2.....6.....8.4......1.......6.3.7.5..2.....1.4......
......52..8.4......3...9...5.1...6..2..7........3.....6...1..........7.4.......3.
end
输出样例:
417369825632158947958724316825437169791586432346912758289643571573291684164875293
416837529982465371735129468571298643293746185864351297647913852359682714128574936
首先考虑如何搜索才能搜遍所有的情况。
可以先随意选择一个空格子,然后取枚举这个空格子可以填什么。
在选择格子的时候,选择一个能填的数更少的那个格子,来保证分支节点最少。
还可以进行可行性剪枝,判断行,列,九宫格不能有重复的数字。
对于本题使用了位运算:对于1~9这9个数,用0表示这个数用过了,1表示这个数没有用过。
比如:001010010就代表了3,5,8可以用。然后使用lowbit就可以O1返回最后一位1了。
CODE:每次学代码部分都得重复找好几遍不同,真是醉了
#include<iostream>
using namespace std;
const int N = 9, M = 1 << N;
int ones[M]; //求每个状态里面有多少个1
int map[M]; //存2的某次方以2为底log的值
int row[N], col[N], cell[3][3];
char str[100];
void init() //每一位都设为1,每个地方都能填
{
for (int i = 0; i < N; i ++ )
row[i] = col[i] = (1 << N) - 1;
for (int i = 0; i < 3; i ++ )
for (int j = 0; j < 3; j ++ )
cell[i][j] = (1 << N) - 1;
}
void draw(int x, int y, int t, bool is_set) //在x,y位置填上t或者删掉t
{
if (is_set) str[x * N + y] = '1' + t; //如果要填入
else str[x * N + y] = '.'; //如果要删除这一点
int v = 1 << t;
if (!is_set) v = -v; //如果要删除就取反,这样就会使得相应的数位变为1,对应的数变得可取
row[x] -= v; //减掉这一位,代表这一个数不能够取了
col[y] -= v;
cell[x / 3][y / 3] -= v;
}
int lowbit(int x){return x & -x;}
int get(int x, int y)
{
return row[x] & col[y] & cell[x / 3][y / 3]; //得到这个格子能填什么数
}
bool dfs(int cnt)
{
if (!cnt) return true; //如果没有空格子,返回true
int minv = 10;
int x, y;
for (int i = 0; i < N; i ++ )
for (int j = 0; j < N; j ++ )
if (str[i * N + j] == '.') //如果这个格子是空格
{
int state = get(i, j); //求出这个格子能填的数字状态
if (ones[state] < minv) //如果这个状态的1的个数小于minV,那就更新minV
{
minv = ones[state];
x = i, y = j; //记录分支数量最小的格子
}
}
int state = get(x, y); //找到这个格子能够填入的数字有哪些
for (int i = state; i; i -= lowbit(i)) //找到这个状态里能够填入的数
{
int t = map[lowbit(i)];//lowbit返回的是2的目标数的次方,直接用map数组得到原本的数
draw(x, y, t, true); //填入这个数
if (dfs(cnt - 1)) return true; //搜下一层
draw(x, y, t, false);
}
return false;
}
int main()
{
for (int i = 0; i < N; i ++ ) map[1 << i] = i; //2的i次方对应i
for (int i = 0; i < 1 << N; i ++ )
for (int j = 0; j < N; j ++ )
ones[i] += i >> j & 1; //i状态有多少个1
while (cin >> str, str[0] != 'e')
{
init(); //每次都初始化
int cnt = 0; //表示有多少空位
for (int i = 0, k = 0; i < N; i ++ )
for (int j = 0; j < N; j ++, k ++ )
if (str[k] != '.') //如果这一位是个数字
{
int t = str[k] - '1'; //取出这个数字
draw(i, j, t, true); //填上这个数字
}
else cnt ++ ; //否则空格数量增加
dfs(cnt);
puts(str);
}
return 0;
}
AcWing.166.木棒
乔治拿来一组等长的木棒,将它们随机地砍断,使得每一节木棍的长度都不超过 50 个长度单位。
然后他又想把这些木棍恢复到为裁截前的状态,但忘记了初始时有多少木棒以及木棒的初始长度。
请你设计一个程序,帮助乔治计算木棒的可能最小长度。
每一节木棍的长度都用大于零的整数表示。
输入格式
输入包含多组数据,每组数据包括两行。
第一行是一个不超过 64 的整数,表示砍断之后共有多少节木棍。
第二行是截断以后,所得到的各节木棍的长度。
在最后一组数据之后,是一个零。
输出格式
为每组数据,分别输出原始木棒的可能最小长度,每组数据占一行。
数据范围
数据保证每一节木棍的长度均不大于 50。
输入样例:
9
5 2 1 5 2 1 5 2 1
4
1 2 3 4
0
输出样例:
6
5
先枚举木棒的长度,然后再去枚举木棍组成木棒的方式。
只有木棍的总的长度的约数才是合法的木棍的长度,因为这些木棍是等长的。
对于搜索顺序的优化,也是枚举更长的木棍,因为这样能够保证先枚举到的节点更少。所以从大到小枚举。
并且在这道题中,木棍的排列顺序是没有影响的,所以采用组合搜索的方式。
同样也有另一种排除冗余的方式,就是排除和失败的木棍相同长度的木棍。
此外,如果第一个木棍失败,那么这个分支一定失败。如果最后一个木棍失败,那么整个分支一定失败。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 70;
int n;
int w[N]; //存木棍的值
int sum,length; //sum代表所有木棍的总长度,length代表枚举的木棒的长度
bool vis[N];
bool dfs(int u,int s,int st){ //u为当前枚举到哪一根木棒,s为当前木棒的长度
if(u * length == sum)return 1; //如果当前木棍的长度乘数量能够得到总长度,那么就说明情况成立
if(s == length)return dfs(u+1,0,0); //如果当前的木棒的长度等于length,就要增加一根木棍开始搜
for(int i = st;i < n;i++){
if(vis[i])continue; //搜过了直接continue
if(s + w[i] > length)continue; //可行性剪枝,如果加上木棍长度超过了length就不成立
vis[i] = 1;
if(dfs(u,s+w[i],i+1))return 1; //搜索选上这一根木棍的情况
vis[i] = 0;
if(!s)return false; //第一根木棍失败直接失败
if(s + w[i] == length)return false; //最后一根木棍失败直接失败
//排除掉所有相同的木棍
int j = i;
while(j < n && w[j] == w[i])j++;
i = j-1;
}
return false;
}
int main(){
while(cin >> n,n){
memset(vis,0,sizeof vis);
sum = 0;
for(int i = 0;i < n;i++){
cin >> w[i];
sum += w[i];
}
//优化搜索顺序
sort(w,w+n);
reverse(w,w+n);
length = 1;
while(1){
//第一处剪枝,只找约数
if(sum % length == 0 && dfs(0,0,0)){
cout << length << endl;
break;
}
length++;
}
}
return 0;
}
AcWing.168.生日蛋糕
7 月 17 日是 Mr.W 的生日,ACM-THU 为此要制作一个体积为 N π Nπ Nπ 的 M M M 层生日蛋糕,每层都是一个圆柱体。
设从下往上数第 i i i 层蛋糕是半径为 R i R_i Ri,高度为 H i H_i Hi 的圆柱。
当 i < M i<M i<M 时,要求 R i > R i + 1 R_i>R_i+1 Ri>Ri+1 且 H i > H i + 1 H_i>H_i+1 Hi>Hi+1。
由于要在蛋糕上抹奶油,为尽可能节约经费,我们希望蛋糕外表面(最下一层的下底面除外)的面积 Q 最小。
令 Q = S π Q=Sπ Q=Sπ ,请编程对给出的 N 和 M,找出蛋糕的制作方案(适当的 Ri 和 Hi 的值),使 S 最小。
除 Q 外,以上所有数据皆为正整数。
输入格式
输入包含两行,第一行为整数 N,表示待制作的蛋糕的体积为 Nπ。
第二行为整数 M,表示蛋糕的层数为 M。
输出格式
输出仅一行,是一个正整数 S(若无解则 S=0)。
数据范围
1
≤
N
≤
10000
,
1≤N≤10000,
1≤N≤10000,
1
≤
M
≤
20
1≤M≤20
1≤M≤20
输入样例:
100
2
输出样例:
68
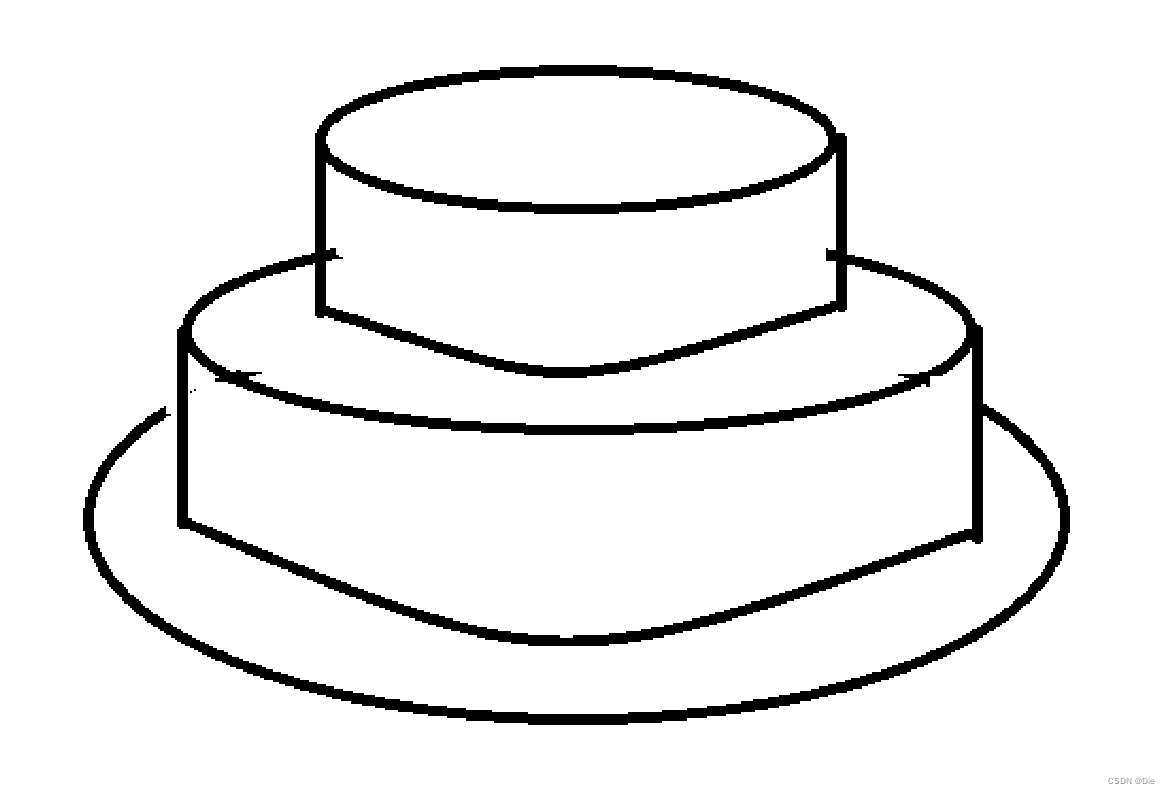
对于题目中给出的蛋糕,想要表面积最小。思考表面积的组成。
不难想出,表面积是由上表面的面积和侧面积组成,由于每一层蛋糕之间有覆盖关系,所以最终整个蛋糕的上表面的面积为最底层的那个圆柱的半径乘以 p i 2 pi^2 pi2,表面积则是每一层圆柱的 ∑ 2 ∗ p i ∗ R ∗ H \sum2*pi*R*H ∑2∗pi∗R∗H。蛋糕外表如图所示。
那么考虑搜索顺序。
对于本题可以想出两种搜索顺序,一个是从上往下搜,一个是从下往上搜。
我们应该选择从下往上搜。和前两道题一样的道理,如果先从下面开始搜,能够占到的体积更大,那么后面会出现的分支自然更小。
再细分考虑每一层的搜索。
对于每一层只有两个变量,一个是半径一个是高度,所以我们就有两种搜索方式,一个是先枚举半径再枚举高度,一个是先枚举高度再枚举半径。
在这里应该选择先枚举半径,因为半径是平方级别,也是对体积的影响更大.,并且不论对于高度还是半径,都应该从大到小来枚举,都是能够减少分支。
接下来考虑可行性剪枝:
对于每一层的半径,都应该满足
u
<
=
R
(
u
)
<
R
(
u
+
1
)
u <= R(u) < R(u+1)
u<=R(u)<R(u+1),这里的
u
+
1
u+1
u+1 是
u
u
u 的下面一层。
为什么要大于等于
u
u
u呢,因为第一层的半径最小为
1
1
1,如果全部取最小,到达第
u
u
u层也应该是大于等于
u
u
u的。
然后如果第u层取到了半径R(u),如果u往下的所有层数的体积加和为v,那么从u开始往上的体积就是N - v,
在这里从u往上的体积可以表示为:
p
i
∗
R
(
u
)
2
∗
h
(
u
)
pi*R(u)^2*h(u)
pi∗R(u)2∗h(u),在这里取最小值
h
(
u
)
=
1
h(u) = 1
h(u)=1,那么就可以列出不等式:
N
∗
p
i
−
v
∗
p
i
>
=
p
i
∗
R
(
u
)
N*pi - v*pi >= pi*R(u)
N∗pi−v∗pi>=pi∗R(u),在这里因为我们搜索的时候直接忽略了
p
i
pi
pi,所以可以将不等式列为:
N
−
v
>
=
R
(
u
)
N - v >= R(u)
N−v>=R(u)。
所以最终得到的R(u)的取值范围为:
u
<
=
R
(
u
)
<
=
m
i
n
[
R
(
u
+
1
)
−
1
,
N
−
v
]
u <= R(u) <= min[R(u+1)-1 , \sqrt{N - v}]
u<=R(u)<=min[R(u+1)−1,N−v]。
同理可以得到H(u)的取值范围为:
u
<
=
H
(
u
)
<
=
m
i
n
[
H
(
u
+
1
)
−
1
,
N
−
v
R
(
u
)
2
]
u <= H(u) <= min[H(u+1) - 1 , \frac{N-v}{R(u)^2}]
u<=H(u)<=min[H(u+1)−1,R(u)2N−v]。
其他剪枝:
预处理出来前u层的体积的最小值和表面积的最小值。
因为我们要始终保证当前层的体积加上前
u
u
u层的最小体积一定要小于等于
n
n
n。
并且还要保证当前层的表面积加上前u层的最小表面积一定要小于当前搜到的答案,大于了肯定不是最优解了。
最后的最难的剪枝:
首先,1~u层的表面积为:
∑
k
=
1
u
2
×
R
k
×
H
k
\sum_{k = 1}^{u}2 \times R_k \times H_k
k=1∑u2×Rk×Hk
1~u的体积为:
∑
k
=
1
u
R
k
2
×
H
k
\sum_{k = 1}^{u}{R_k}^2 \times H_k
k=1∑uRk2×Hk(全部省略了π)
这个时候对两个等式进行变换,首先对于表面积进行变换,可以把求和符号内的2提出来,然后这里除上一个
R
u
+
1
R_{u+1}
Ru+1,之后再乘上一个
R
u
+
1
R_{u+1}
Ru+1放到求和符号内(注意这里是可以放到求和符号内的,因为分步乘和全部乘是一个道理,因为乘法分配律)。
2
R
u
+
1
∑
k
=
1
u
R
k
×
H
k
×
R
u
+
1
\frac{2}{R_{u+1}} \sum_{k = 1}^{u}R_k \times H_k \times R_{u+1}
Ru+12k=1∑uRk×Hk×Ru+1
然后我们把
R
u
+
1
R_{u+1}
Ru+1放缩为
R
k
R_k
Rk,这里
R
k
R_k
Rk一定是小于
R
u
R_u
Ru的,所以我们可以得到不等式:
2
R
u
+
1
∑
k
=
1
u
R
k
×
H
k
×
R
u
+
1
>
2
R
u
+
1
∑
k
=
1
u
R
k
2
×
H
K
\frac{2}{R_{u+1}} \sum_{k = 1}^{u}R_k \times H_k \times R_{u+1} > \frac{2}{R_{u+1}} \sum_{k = 1}^{u}{R_k}^2 \times H_K
Ru+12k=1∑uRk×Hk×Ru+1>Ru+12k=1∑uRk2×HK
聪明的你一定注意到了大于号右边的那个式子的求和式就是1~u的体积的公式,所以我们可以得到式子
2
R
u
+
1
∑
k
=
1
u
R
k
×
H
k
×
R
u
+
1
>
2
×
(
N
−
v
)
R
u
+
1
\frac{2}{R_{u+1}} \sum_{k = 1}^{u}R_k \times H_k \times R_{u+1} > \frac{2 \times (N-v) }{R_{u+1}}
Ru+12k=1∑uRk×Hk×Ru+1>Ru+12×(N−v)
即:
S
(
1
S(1
S(1 ~
u
−
1
)
u-1)
u−1)
>
=
2
×
(
N
−
v
)
R
u
+
1
>= \frac{2 \times (N-v) }{R_{u+1}}
>=Ru+12×(N−v)(搜到最顶层的时候可以取到等于号)。
所以在搜索的过程中如果出现了 S ( u ) + 2 × ( N − v ) R u + 1 S(u) + \frac{2 \times (N-v) }{R_{u+1}} S(u)+Ru+12×(N−v) 大于等于当前已经搜到的答案的话,就可以直接 r e t u r n return return了。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 25;
int n,m;
int minV[N],minS[N];
int R[N],H[N];
int ans = 2e9;
void dfs(int u,int v,int s){
if(v + minV[u] > n)return; //可行性剪枝
if(s + minS[u] >= ans)return; //最优化剪枝
if(s + 2*(n-v)/R[u+1] >= ans)return; //数学剪枝
if(!u){ //所有层都搜完了
if(v == n)ans = s;
return;
}
for(int r = min(R[u+1] - 1,(int)sqrt(n - v));r >= u;r--){ //根据推导的范围从大到小枚举半径和高度
for(int h = min(H[u+1] - 1,(n-v)/r/r);h >= u;h--){
int t = 0;
if(u == m)t = r*r;//如果是最底层
R[u] = r,H[u] = h;
dfs(u-1,v+r*r*h,s + 2*r*h + t);
}
}
}
int main(){
cin >> n >> m;
for(int i = 1;i <= m;i++){ //预处理每一层体积和面积的最小值
minV[i] = minV[i-1] + i*i*i;
minS[i] = minS[i-1] + 2*i*i;
}
R[m+1] = H[m+1] = 2e9;
dfs(m,0,0);
if(ans == 2e9)cout << 0 << endl;
else cout << ans << endl;
return 0;
}
迭代加深
按层来搜,有些类似于宽搜。
定义一个最深层,多于最深层的所有节点都舍弃。并且迭代加深的空间复杂度小于BFS。
即迭代加深适用于有一些非常深的节点,但是答案在非常浅的节点。
虽然在搜的时候回多搜一些节点,但是对时间复杂度的影响可以忽略不计
AcWing.170.加成序列
满足如下条件的序列 X(序列中元素被标号为 1、2、3…m)被称为“加成序列”:
1.X[1]=1
2.X[m]=n
3.X[1]<X[2]<…<X[m−1]<X[m]
4.对于每个 k(2≤k≤m)都存在两个整数 i 和 j (1≤i,j≤k−1,i 和 j 可相等),使得 X[k]=X[i]+X[j]。
你的任务是:给定一个整数 n,找出符合上述条件的长度 m 最小的“加成序列”。
如果有多个满足要求的答案,只需要找出任意一个可行解。
输入格式
输入包含多组测试用例。
每组测试用例占据一行,包含一个整数 n。
当输入为单行的 0 时,表示输入结束。
输出格式
对于每个测试用例,输出一个满足需求的整数序列,数字之间用空格隔开。
每个输出占一行。
数据范围
1
≤
n
≤
100
1≤n≤100
1≤n≤100
输入样例:
5
7
12
15
77
0
输出样例:
1 2 4 5
1 2 4 6 7
1 2 4 8 12
1 2 4 5 10 15
1 2 4 8 9 17 34 68 77
在最坏的情况下,每个数只增加1,那么就能够搜到100层。但是如果我们不按照加1来构造,如果每次都让数增加1倍,那么到达100以上仅需要8层(即1,2,4,8,16,32,64,128)。
此题虽然有些分支会搜的很深,但是答案却很浅。所以可以使用迭代加深。
那么考虑搜索顺序:
直接搜索每一个数应该是什么就可以。
比如第一二个一定是1和2,第三个就可以是3或者4.
考虑剪枝:
- 优化搜索顺序:搜索时优先枚举更大的数,这样能够更快地到达n,使得节点更少。
- 排除冗余:在枚举下一个数该是什么的时候,我们就需要枚举前面所有数字中每两个数字的和,但是不同的两个数的和可能是相同的,对于这种数我们只需要枚举一次就可以。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 110;
int n;
int path[N];
bool st[N]; //标记搜过的数字,排除冗余
bool dfs(int now_depth,int max_depth){
if(now_depth > max_depth)return false; //如果超出了我们当前设置的最大层数就直接返回
if(path[now_depth - 1] == n)return true; //如果已经找到了答案了,就返回
memset(st,0,sizeof st);
for(int i = now_depth - 1;i >= 0;i--){ //从大到小枚举前面所有数
for(int j = i;j >= 0;j--){ //顺序不影响最后的和,直接从i的位置开始枚举
int s = path[i] + path[j];
//如果s超过了n,或者s小于等于上一个数,又或者s已经被搜过了,就直接continue
if(s > n || s <= path[now_depth - 1] || st[s])continue;
st[s] = 1;
path[now_depth] = s;
if(dfs(now_depth+1,max_depth))return true; //接着搜下一个数
}
}
return false;
}
int main(){
path[0] = 1; //第一个数一定是1
while(cin >> n,n){
int depth = 1; //这里先设置最大层数为1,
while(!dfs(1,depth))depth++; //如果当前设置的层数不够,那么就增加层数
for(int i = 0;i < depth;i++){
cout << path[i] << " ";
}
puts("");
}
return 0;
}
在迭代加深中,我们实现一层层的搜的操作就是规定好深度,然后再一遍遍的扩增。
双向DFS
和双向BFS是同样的道理
AcWing.171.送礼物
达达帮翰翰给女生送礼物,翰翰一共准备了 N 个礼物,其中第 i 个礼物的重量是 G[i]。
达达的力气很大,他一次可以搬动重量之和不超过 W 的任意多个物品。
达达希望一次搬掉尽量重的一些物品,请你告诉达达在他的力气范围内一次性能搬动的最大重量是多少。
输入格式
第一行两个整数,分别代表 W 和 N。
以后 N 行,每行一个正整数表示 G[i]。
输出格式
仅一个整数,表示达达在他的力气范围内一次性能搬动的最大重量。
数据范围
1
≤
N
≤
46
,
1≤N≤46,
1≤N≤46,
1
≤
W
,
G
[
i
]
≤
2
31
−
1
1≤W,G[i]≤2^{31}−1
1≤W,G[i]≤231−1
输入样例:
20 5
7
5
4
18
1
输出样例:
19
这题乍一看看起来像是背包DP,但是数据范围到达了 2 31 2^{31} 231,用DP一定会超时。
如果直接用DFS去搜,就会搜出来 2 46 2^{46} 246种情况,那么也一定会超时。
可以先去看前一半的物品能够选出来的最大重量的方案,然后再去枚举后面一半的物品要不要选。
所以前一半能够搜出来
2
23
2^{23}
223种情况,后面又能够枚举出来
2
23
2^{23}
223种情况。
在后面枚举的时候,我们就要搜出来有没有一种情况能够使得选择或者不选这个物品之后,再去和前面的方案组合之后能够达到小于等于重量W,即枚举到某一步的时候去看前面的方案中存不存在一个x,使得当前的重量加上x就能够小于等于W。
那么就需要实现一个能够快速找到一个x使得其小于等于 W - 当前重量,直接使用二分就可以了。
优化:
对于这道题也是,先去枚举更大的数,同样是减少节点数。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 46;
#define ll long long
int n,m,k;
int w[N]; //存所有的重量
int Wed[1 << 25],cnt = 1; //Wed存前面预处理出来的所有重量方案
int ans;
void dfs(int u,int sum){ //前半部分预处理
if(u == k){
Wed[cnt++] = sum;
return;
}
dfs(u+1,sum); //不选
if((ll)sum + w[u] <= m)dfs(u+1,sum + w[u]); //选
}
void dfs2(int u,int sum){ //枚举后半部分
if(u == n){ //二分找满足要求的值
int l = 0,r = cnt - 1;
while(l < r){
int mid = l + r + 1 >> 1;
if(Wed[mid] <= m - sum)l = mid;
else r = mid - 1;
}
ans = max(ans,Wed[l] + sum); //ans取最大值
return;
}
dfs2(u + 1,sum); //选
if((ll)sum + w[u] <= m)dfs2(u+1,sum + w[u]); //不选
}
int main(){
cin >> m >> n;
for(int i = 0;i < n;i++)cin >> w[i];
sort(w,w+n,[&](int a,int b){ //从大到小排序
return a > b;
});
k = n/2; //取一半,如果取n/2 + 2会搜不到答案
dfs(0,0); //先预处理
sort(Wed,Wed+cnt); //把预处理出来的答案排序
cnt = unique(Wed,Wed + cnt) - Wed; //去重剪枝
dfs2(k,0); //枚举后半段搜答案
cout << ans << endl;
return 0;
}
IDA*
在搜索的过程中,进行预估,预估答案是否一定是要超过当前规定的最大层数,如果超过的话就直接剪枝就可以了。
同样估价函数的要求与A*算法相同,那么就是估价函数要小于真实值。
AcWing.180.排书
给定 n 本书,编号为 1∼n。
在初始状态下,书是任意排列的。
在每一次操作中,可以抽取其中连续的一段,再把这段插入到其他某个位置。
我们的目标状态是把书按照 1∼n 的顺序依次排列。
求最少需要多少次操作。
输入格式
第一行包含整数 T,表示共有 T 组测试数据。
每组数据包含两行,第一行为整数 n,表示书的数量。
第二行为 n 个整数,表示 1∼n 的一种任意排列。
同行数之间用空格隔开。
输出格式
每组数据输出一个最少操作次数。
如果最少操作次数大于或等于 5 次,则输出 5 or more。
每个结果占一行。
数据范围
1
≤
n
≤
15
1≤n≤15
1≤n≤15
输入样例:
3
6
1 3 4 6 2 5
5
5 4 3 2 1
10
6 8 5 3 4 7 2 9 1 10
输出样例:
2
3
5 or more
如果对于一个长度为n的序列进行操作,假如我们现在对一直到第i项进行操作,那么就是对1~n-i+1项进行操作,那么就会有
(
n
−
i
+
1
)
×
(
n
−
i
)
+
(
n
−
i
)
×
(
n
−
i
−
1
)
+
⋯
+
2
×
1
(n-i+1)\times(n-i) + (n-i)\times(n-i-1) + \dots + 2\times1
(n−i+1)×(n−i)+(n−i)×(n−i−1)+⋯+2×1次操作,但是注意:
假如我们有两段相邻的序列,我们把前面的序列换到后面和把后面的序列换到前面是等价的,所以实际上我们搜索的次数应该是
(
n
−
i
+
1
)
×
(
n
−
i
)
+
(
n
−
i
)
×
(
n
−
i
−
1
)
+
⋯
+
2
×
1
2
\frac{(n-i+1)\times(n-i) + (n-i)\times(n-i-1) + \dots + 2\times1}{2}
2(n−i+1)×(n−i)+(n−i)×(n−i−1)+⋯+2×1那么直接爆搜必定是超时的,所以需要使用双向DFS或是IDA*。
对于IDA*我们需要考虑如何设计估价函数,那么对于当前每个状态,我们需要估计出最少需要多少次操作才能够使其变成排好的序列。
在进行操作的时候,一次序列的变换会引起三个元素的后继的变化:
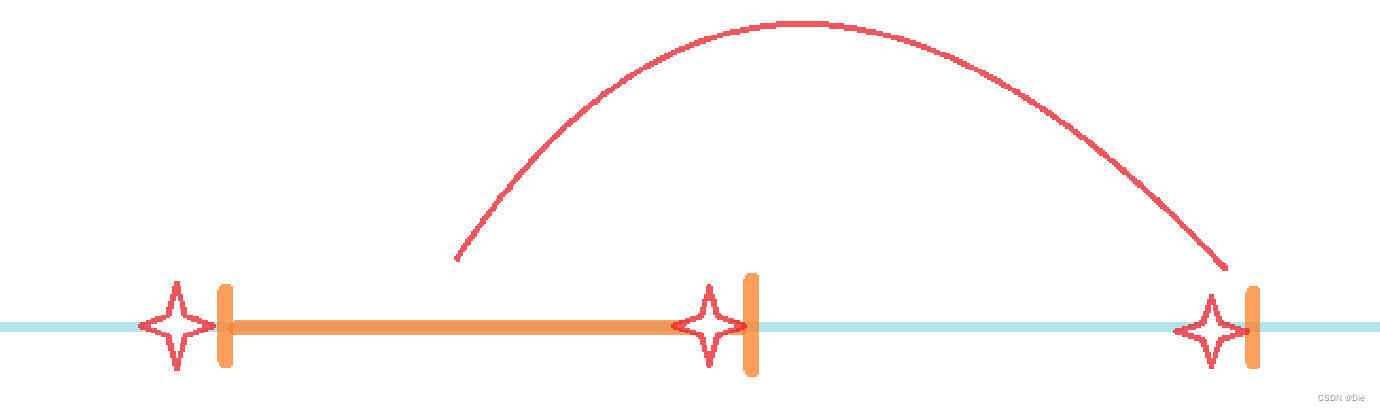
那么,只要我们在最开始的时候统计出来所有的不合理的后继关系,然后使其除以3然后上取整,就能得到最少需要多少次操作,也就是说这就成为了我们的估价函数。
CODE:
#include <bits/stdc++.h>
using namespace std;
const int N = 15;
int n;
int q[N], w[5][N];
int f() //估价函数,求总共的不合理后继数量除以3上取整
{
int res = 0;
for (int i = 0; i + 1 < n; i++)
if (q[i + 1] != q[i] + 1)
res++;
return (res + 2) / 3;
}
bool dfs(int depth, int max_depth)
{
if (depth + f() > max_depth)return false; //如果最小操作步骤超出最大深度,直接return
if (f() == 0)return true; //如果已经没有不合理后继了,直接return
for (int l = 0; l < n; l++) //枚举长度
for (int r = l; r < n; r++) //枚举起始移动距离
for (int k = r + 1; k < n; k++) //枚举终止移动距离
{
memcpy(w[depth], q, sizeof q); //备份q数组
int x, y;
for (x = r + 1, y = l; x <= k; x++, y++) //把换过去那段换完
q[y] = w[depth][x];
for (x = l; x <= r; x++, y++) //把被换过去那段换完
q[y] = w[depth][x];
if (dfs(depth + 1, max_depth)) //搜下一层
return true;
memcpy(q, w[depth], sizeof q); //复原q数组
}
return false;
}
int main()
{
int T;
scanf("%d", &T);
while (T--)
{
scanf("%d", &n);
for (int i = 0; i < n; i++)
scanf("%d", &q[i]);
int depth = 0;
while (depth < 5 && !dfs(0, depth)) //迭代加深
depth++;
if (depth >= 5)
puts("5 or more");
else
printf("%d\n", depth);
}
return 0;
}
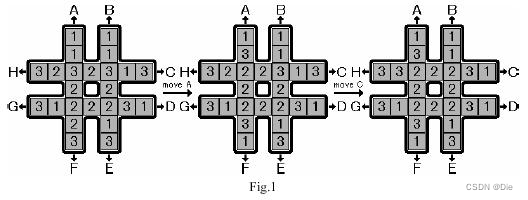
AcWing.181.回转游戏
如下图所示,有一个 # 形的棋盘,上面有 1,2,3 三种数字各 8 个。
给定 8 种操作,分别为图中的 A∼H。
这些操作会按照图中字母和箭头所指明的方向,把一条长为 7 的序列循环移动 1 个单位。
例如下图最左边的 # 形棋盘执行操作 A 后,会变为下图中间的 # 形棋盘,再执行操作 C 后会变成下图最右边的 # 形棋盘。
给定一个初始状态,请使用最少的操作次数,使 # 形棋盘最中间的 8 个格子里的数字相同。
输入格式
输入包含多组测试用例。
每个测试用例占一行,包含 24 个数字,表示将初始棋盘中的每一个位置的数字,按整体从上到下,同行从左到右的顺序依次列出。
输入样例中的第一个测试用例,对应上图最左边棋盘的初始状态。
当输入只包含一个 0 的行时,表示输入终止。
输出格式
每个测试用例输出占两行。
第一行包含所有移动步骤,每步移动用大写字母 A∼H 中的一个表示,字母之间没有空格,如果不需要移动则输出 No moves needed。
第二行包含一个整数,表示移动完成后,中间 8 个格子里的数字。
如果有多种方案,则输出字典序最小的解决方案。
输入样例:
1 1 1 1 3 2 3 2 3 1 3 2 2 3 1 2 2 2 3 1 2 1 3 3
1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3
0
输出样例:
AC
2
DDHH
2
对于本题要求的字典序,仅需要保证搜索的时候是按照字典序来搜的就可以。
在本题中,可能会出左右横跳的无用功,导致搜索树变得非常深,但是答案不会在那样深的节点上,所以在此种情况下,我们使用IDA*去做这道题。
那么估价函数如何设计?
首先在进行操作的时候,每次都只能对中间区域进行一个格子的元素的改变,所以可以先统计中间八个格子里出现的最多的数字出现的次数,那么用8减去次数就可以得到最少需要操作的次数,就以此作为估价。
优化:
如果当前层做出一个操作之后,下一层的操作就不要进行反向的操作,这样是无用功。
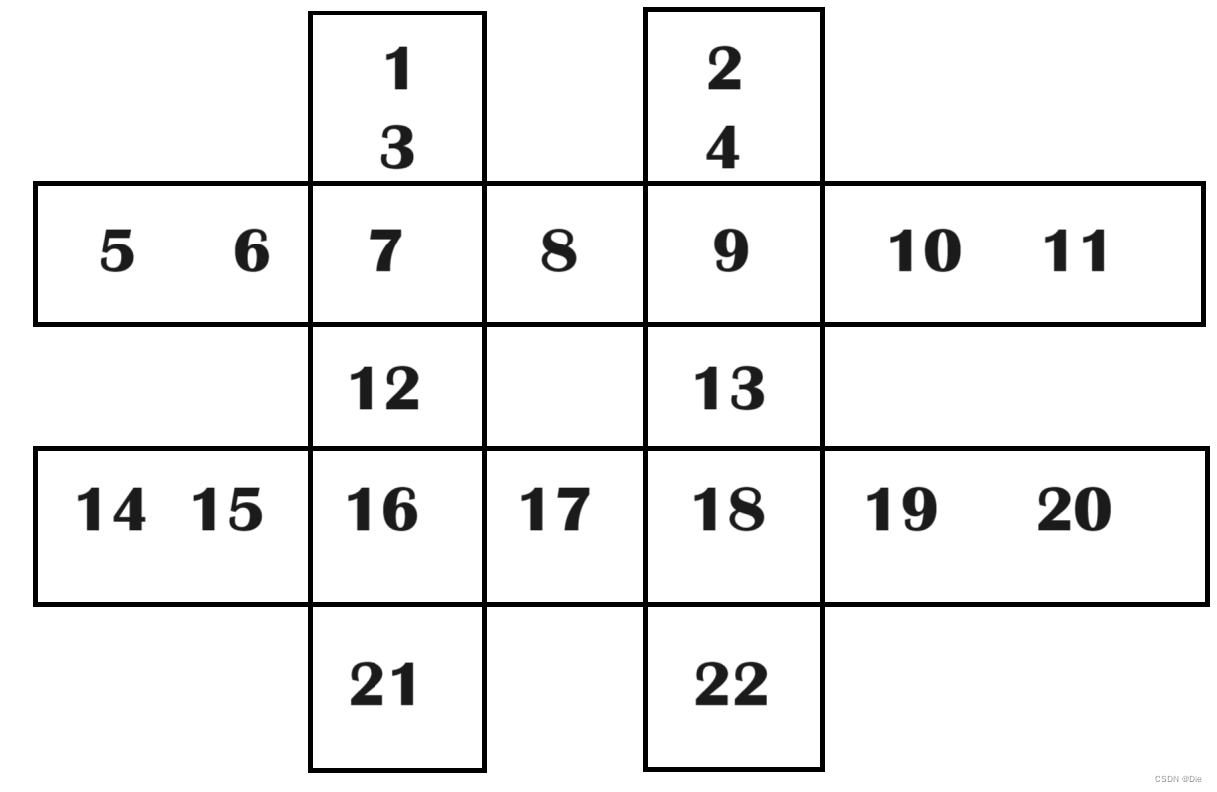
可以对每一个部位的元素定一个号,并且对每一个操作定一个编号,这样就可以使得操作更加方便。
操作直接按照字典序进行即可。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 25;
int q[N];
int op[8][7] = { //记录每一个操作的对应的元素
{0, 2, 6, 11, 15, 20, 22},
{1, 3, 8, 12, 17, 21, 23},
{10, 9, 8, 7, 6, 5, 4},
{19, 18, 17, 16, 15, 14, 13},
{23, 21, 17, 12, 8, 3, 1},
{22, 20, 15, 11, 6, 2, 0},
{13, 14, 15, 16, 17, 18, 19},
{4, 5, 6, 7, 8, 9, 10}
};
int center[8] = {6, 7, 8, 11, 12, 15, 16, 17}; //中心对应的元素
int opposite[8] = {5, 4, 7, 6, 1, 0, 3, 2}; //记录每个操作对应的逆操作
int path[100]; //记录路径
int f() //估价函数
{
int sum[4] = {0};
for (int i = 0; i < 8; i ++ ) sum[q[center[i]]] ++ ; //统计中间部分所有的数的个数
int s = 0;
for (int i = 1; i <= 3; i ++ ) s = max(s, sum[i]); //找到最大值
return 8 - s;
}
void operation(int x)
{
int t = q[op[x][0]];
for (int i = 0; i < 6; i ++ ) q[op[x][i]] = q[op[x][i + 1]]; //全部往前移
q[op[x][6]] = t;
}
bool dfs(int depth, int max_depth, int last)
{
if (depth + f() > max_depth) return false; //如果最小操作次数都要超过最大层,就直接return
if (f() == 0) return true; //如果已经满足要求,return
for (int i = 0; i < 8; i ++ ) //枚举方案
{
if (opposite[i] == last) continue;//避免和上一层是相反的操作
operation(i); //进行操作
path[depth] = i; //记录路径
if (dfs(depth + 1, max_depth, i)) return true; //搜索下一层
operation(opposite[i]); //逆向回溯状态
}
return false;
}
int main()
{
while (scanf("%d", &q[0]), q[0])
{
for (int i = 1; i < N; i ++ ) scanf("%d", &q[i]);
int depth = 0;
while (!dfs(0, depth, -1))depth ++ ;
if (!depth) printf("No moves needed");//如果一步都不需要
for (int i = 0; i < depth; i ++ ) printf("%c", 'A' + path[i]);//输出路径
printf("\n%d\n", q[6]);
}
return 0;
}