作者:翟天保Steven
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
共享内存是什么?
共享内存是在多个处理单元之间共享数据的一种内存区域。在计算机体系结构中,共享内存通常指的是多个处理器核心或线程之间可以直接访问的内存区域。这些处理单元可以是在同一片硅芯片上的多个处理器核心,也可以是在多个硬件设备上运行的并行线程。
共享内存在并行计算中扮演着重要的角色,因为它允许多个处理单元之间快速共享数据,而无需通过显式的通信机制。这种直接的共享机制可以大大提高并行计算的效率和性能。
在GPU编程中,共享内存通常是在GPU的多个线程之间共享的硬件缓存区域。每个线程块(block)内的线程可以访问共享内存中存储的数据,并且这些数据对于同一个线程块内的所有线程都是可见的。共享内存通常具有更高的带宽和更低的访问延迟,因此可以用来加速数据的读取和写入操作。
共享内存的使用可以提高并行计算的性能,并减少通信开销,特别是在需要大量数据共享的情况下,如矩阵乘法、图像处理等算法中。因此,共享内存是许多并行计算框架和编程模型中的重要组成部分。
常规算法
在讲解共享内存法之前先回顾常规算法,常规算法通过分配区block和线程thread,使矩阵计算过程拆解,进而达到并行目的。
// 常规算法的核
__global__ void vectorMulGPU(const float* a, const float* b, float* c, int size)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < size && col < size)
{
float sum = 0.0f;
for (int k = 0; k < size; ++k)
{
sum += a[row * size + k] * b[k * size + col];
}
c[row * size + col] = sum;
}
}共享内存法
矩阵计算中(row0,col0)的值,等于前一个矩阵对应行row0和后一个矩阵对应列col0的数据点乘之和;同理,在(row0,col1)的计算中,又读取了一次row0的数据信息;那么如何将这两个读取类似数据的过程进行优化,便是共享内存法的意义所在。
下面是共享内存法的核函数。
// 共享内存法的核
__global__ void vectorMulGPU2(const float* a, const float* b, float* c, int size)
{
__shared__ float as[TILE_WIDTH][TILE_WIDTH];
__shared__ float bs[TILE_WIDTH][TILE_WIDTH];
// 索引
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
// 行列
int row = by * TILE_WIDTH + ty;
int col = bx * TILE_WIDTH + tx;
// 遍历不同块
float temp = 0.0;
for (int k = 0; k < size / TILE_WIDTH; k++)
{
// 在同一块中的不同线程会计算各自数据,并存在共享存储中互相使用
as[ty][tx] = a[row * size + k * TILE_WIDTH + tx];
bs[ty][tx] = b[(k * TILE_WIDTH + ty) * size + col];
__syncthreads(); // 等待块中其他线程同步
// 将对应数据计算
for (int m = 0; m < TILE_WIDTH; m++)
temp += as[ty][m] * bs[m][tx];
__syncthreads(); // 等待其他线程,如果不加这一句,部分线程中的as和bs会被后续循环的计算覆盖,进而导致结果错误
}
c[row * size + col] = temp;
}逐步解释代码:
-
vectorMulGPU2是一个 GPU 的核函数,用于执行向量相乘操作。它接受三个参数:两个输入向量a和b,一个输出向量c,以及向量的大小size。 -
as和bs这两行定义了共享内存中的两个二维数组,用于存储输入向量的部分数据。 -
接下来是一系列的变量定义和计算,其中涉及到了线程、块、行、列等概念的索引计算,以及关于如何在输入矩阵中定位数据的计算。
-
for (int k = 0; k < size / TILE_WIDTH; k++)这个循环迭代地处理输入向量,将其分割成大小为TILE_WIDTH的小块。 -
在循环中,首先将当前处理的小块数据从输入向量
a和b中加载到共享内存中的as和bs数组中,每个线程负责加载一部分数据。 -
__syncthreads()这是一个同步函数,用于确保所有线程都已经加载完数据,才能继续执行下一步计算。 -
然后,在加载完数据后,每个线程会计算部分结果,并将其叠加在
temp变量中,这个过程利用了共享内存中的数据。 -
再次使用同步函数确保所有线程都完成了计算,以免后续的数据加载覆盖了当前线程的计算结果。
-
最后,将计算得到的结果写入到输出向量
c中。
相较常规算法,共享内存法速度之所以提升,在于如下几点:
-
共享内存(Shared Memory):在CUDA编程中,共享内存是每个线程块共享的内存空间,它的读写速度比全局内存快得多。这段代码中使用了
__shared__修饰符定义了as和bs两个二维数组,用于存储每个线程块所需的部分输入数据。 -
矩阵块计算(Matrix Tile Computation):这段代码将整个矩阵分割成小块,每个线程块负责处理一个小块的计算。这样做的好处是利用了共享内存的局部性原理,减少了全局内存的访问次数,提高了内存访问效率。
-
线程同步(Thread Synchronization):在每个矩阵块计算完毕后,使用
__syncthreads()函数进行线程同步,确保所有线程都完成了对共享内存的写入操作,然后再进行下一步的计算。这样可以避免数据竞争和不一致性。 -
数据重用(Data Reuse):由于每个线程块的计算结果都存储在共享内存中,可以重复利用这些数据进行后续计算,减少了对全局内存的访问次数,提高了数据重用率。
-
数据局部性(Data Locality):通过共享内存和矩阵块计算,每个线程块都在处理相邻的数据片段,这样可以提高数据局部性,减少了数据的跨越和访问延迟。
改进共享内存法
如果你观察细致,那你必定会注意到如果矩阵行列数不是分块尺寸的整数倍,则上述代码便会出错,它会读取不在原计算序列中的数据,进而导致计算错误。假设矩阵是64*64,那单列或者单行可以分块为4个16,刚刚好,如果矩阵是70*70,那除了4个16外,还会余出6个数据没有参与运算。
接下来对算法进行改进。
// 共享内存法(改进)的核
__global__ void vectorMulGPU3(const float* a, const float* b, float* c, int size)
{
__shared__ float as[TILE_WIDTH][TILE_WIDTH];
__shared__ float bs[TILE_WIDTH][TILE_WIDTH];
// 索引
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
// 行列
int row = by * TILE_WIDTH + ty;
int col = bx * TILE_WIDTH + tx;
// 遍历不同块
float temp = 0.0;
for (int k = 0; k < ceil(float(size) / TILE_WIDTH); k++)
{
// 在同一块中的不同线程会计算各自数据,并存在共享存储中互相使用
if ((k * TILE_WIDTH + tx) < size && row < size)
{
as[ty][tx] = a[row * size + k * TILE_WIDTH + tx];
}
else
{
as[ty][tx] = 0.0f;
}
if ((k * TILE_WIDTH + ty) < size && col < size)
{
bs[ty][tx] = b[(k * TILE_WIDTH + ty) * size + col];
}
else
{
bs[ty][tx] = 0.0f;
}
__syncthreads(); // 等待块中其他线程同步
if (row < size && col < size)
{
// 将对应数据计算
for (int m = 0; m < TILE_WIDTH; m++)
temp += as[ty][m] * bs[m][tx];
}
__syncthreads(); // 等待其他线程,如果不加这一句,部分线程中的as和bs会被后续循环的计算覆盖,进而导致结果错误
}
if (row < size && col < size)
{
c[row * size + col] = temp;
}
}改进的几点如下:
-
循环终止条件:
- 原算法中,循环终止条件是
k < size / TILE_WIDTH,这意味着它只会遍历足够数量的块以处理整个矩阵。 - 改进的算法中,循环终止条件是
k < ceil(float(size) / TILE_WIDTH),这使得它处理了多余的块。这样做是为了确保即使矩阵的大小不是块大小的整数倍时,也能正确处理。
- 原算法中,循环终止条件是
-
数据加载:
- 在原算法中,数据加载时没有进行边界检查。这可能导致一些线程加载了超出数组边界的数据,造成错误的计算。
- 改进的算法在加载数据时,会检查当前索引是否超出数组边界,如果超出则将对应元素置为0。这样可以避免超出边界的数据加载,确保计算的正确性。
-
结果存储:
- 原算法和改进的算法都会在计算完毕后将结果存储到全局内存中。但是在改进的算法中,存储结果时也进行了边界检查,以避免将结果存储到超出数组边界的位置。
-
性能优化:
- 改进的算法中,对于不在矩阵边界内的线程,避免了不必要的计算。这样可以减少不必要的计算量,提高了性能。
C++完整代码
Test.cuh
#ifndef MUL_H
#define MUL_H
#define TILE_WIDTH 16
void warmupCUDA();
void vectorMulCUDA(const float* a, const float* b, float* c, int N);
void vectorMulCUDA2(const float* a, const float* b, float* c, int N);
void vectorMulCUDA3(const float* a, const float* b, float* c, int N);
#endif // MUL_HTest.cu
#include <vector>
#include <cuda_runtime.h>
#include <iostream>
#include "Test.cuh"
// 常规算法的核
__global__ void vectorMulGPU(const float* a, const float* b, float* c, int size)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < size && col < size)
{
float sum = 0.0f;
for (int k = 0; k < size; ++k)
{
sum += a[row * size + k] * b[k * size + col];
}
c[row * size + col] = sum;
}
}
// 共享内存法的核
__global__ void vectorMulGPU2(const float* a, const float* b, float* c, int size)
{
__shared__ float as[TILE_WIDTH][TILE_WIDTH];
__shared__ float bs[TILE_WIDTH][TILE_WIDTH];
// 索引
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
// 行列
int row = by * TILE_WIDTH + ty;
int col = bx * TILE_WIDTH + tx;
// 遍历不同块
float temp = 0.0;
for (int k = 0; k < size / TILE_WIDTH; k++)
{
// 在同一块中的不同线程会计算各自数据,并存在共享存储中互相使用
as[ty][tx] = a[row * size + k * TILE_WIDTH + tx];
bs[ty][tx] = b[(k * TILE_WIDTH + ty) * size + col];
__syncthreads(); // 等待块中其他线程同步
// 将对应数据计算
for (int m = 0; m < TILE_WIDTH; m++)
temp += as[ty][m] * bs[m][tx];
__syncthreads(); // 等待其他线程,如果不加这一句,部分线程中的as和bs会被后续循环的计算覆盖,进而导致结果错误
}
c[row * size + col] = temp;
}
// 共享内存法(改进)的核
__global__ void vectorMulGPU3(const float* a, const float* b, float* c, int size)
{
__shared__ float as[TILE_WIDTH][TILE_WIDTH];
__shared__ float bs[TILE_WIDTH][TILE_WIDTH];
// 索引
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
// 行列
int row = by * TILE_WIDTH + ty;
int col = bx * TILE_WIDTH + tx;
// 遍历不同块
float temp = 0.0;
for (int k = 0; k < ceil(float(size) / TILE_WIDTH); k++)
{
// 在同一块中的不同线程会计算各自数据,并存在共享存储中互相使用
if ((k * TILE_WIDTH + tx) < size && row < size)
{
as[ty][tx] = a[row * size + k * TILE_WIDTH + tx];
}
else
{
as[ty][tx] = 0.0f;
}
if ((k * TILE_WIDTH + ty) < size && col < size)
{
bs[ty][tx] = b[(k * TILE_WIDTH + ty) * size + col];
}
else
{
bs[ty][tx] = 0.0f;
}
__syncthreads(); // 等待块中其他线程同步
if (row < size && col < size)
{
// 将对应数据计算
for (int m = 0; m < TILE_WIDTH; m++)
temp += as[ty][m] * bs[m][tx];
}
__syncthreads(); // 等待其他线程,如果不加这一句,部分线程中的as和bs会被后续循环的计算覆盖,进而导致结果错误
}
if (row < size && col < size)
{
c[row * size + col] = temp;
}
}
// 预准备过程
void warmupCUDA()
{
float *dummy_data;
cudaMalloc((void**)&dummy_data, sizeof(float));
cudaFree(dummy_data);
}
// 常规算法
void vectorMulCUDA(const float* a, const float* b, float* c, int size)
{
float *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, size * size * sizeof(float));
cudaMalloc((void**)&d_b, size * size * sizeof(float));
cudaMalloc((void**)&d_c, size * size * sizeof(float));
cudaMemcpy(d_a, a, size * size * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size * size * sizeof(float), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(TILE_WIDTH, TILE_WIDTH);
dim3 blocksPerGrid((size + threadsPerBlock.x - 1) / threadsPerBlock.x, (size + threadsPerBlock.y - 1) / threadsPerBlock.y);
vectorMulGPU << <blocksPerGrid, threadsPerBlock >> > (d_a, d_b, d_c, size);
cudaMemcpy(c, d_c, size * size * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
// 共享内存法
void vectorMulCUDA2(const float* a, const float* b, float* c, int size)
{
float *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, size * size * sizeof(float));
cudaMalloc((void**)&d_b, size * size * sizeof(float));
cudaMalloc((void**)&d_c, size * size * sizeof(float));
cudaMemcpy(d_a, a, size * size * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size * size * sizeof(float), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(TILE_WIDTH, TILE_WIDTH);
dim3 blocksPerGrid((size + threadsPerBlock.x - 1) / threadsPerBlock.x, (size + threadsPerBlock.y - 1) / threadsPerBlock.y);
vectorMulGPU2 << <blocksPerGrid, threadsPerBlock >> > (d_a, d_b, d_c, size);
cudaMemcpy(c, d_c, size * size * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
// 共享内存法改进
void vectorMulCUDA3(const float* a, const float* b, float* c, int size)
{
float *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, size * size * sizeof(float));
cudaMalloc((void**)&d_b, size * size * sizeof(float));
cudaMalloc((void**)&d_c, size * size * sizeof(float));
cudaMemcpy(d_a, a, size * size * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size * size * sizeof(float), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(TILE_WIDTH, TILE_WIDTH);
dim3 blocksPerGrid((size + threadsPerBlock.x - 1) / threadsPerBlock.x, (size + threadsPerBlock.y - 1) / threadsPerBlock.y);
vectorMulGPU3 << <blocksPerGrid, threadsPerBlock >> > (d_a, d_b, d_c, size);
cudaMemcpy(c, d_c, size * size * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}main.cpp
#include <iostream>
#include <vector>
#include <time.h>
#include "Test.cuh"
using namespace std;
void vectorMulCPU(const std::vector<float>& a, const std::vector<float>& b, std::vector<float>& c, int size)
{
#pragma omp parallel for
for (int i = 0; i < size; ++i)
{
for (int j = 0; j < size; ++j)
{
float sum = 0.0f;
for (int k = 0; k < size; ++k)
{
sum += a[i * size + k] * b[k * size + j];
}
c[i * size + j] = sum;
}
}
}
int main()
{
// 乘法测试
const int N = 1000; // 矩阵大小
std::vector<float> a0(N * N, 0.0f);
std::vector<float> b0(N * N, 0.0f);
std::vector<float> c0(N * N, 0.0f);
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
a0[i * N + j] = float(rand() % 255);
b0[i * N + j] = float(rand() % 255);
}
}
std::vector<float> a1 = a0;
std::vector<float> b1 = b0;
std::vector<float> c1 = c0;
std::vector<float> a2 = a0;
std::vector<float> b2 = b0;
std::vector<float> c2 = c0;
std::vector<float> a3 = a0;
std::vector<float> b3 = b0;
std::vector<float> c3 = c0;
// CPU矩阵乘法
clock_t sc, ec;
sc = clock();
vectorMulCPU(a0, b0, c0, N);
ec = clock();
cout << "mul CPU time:" << float(ec - sc) / 1000 << endl;
// 准备工作
bool flag = true;
clock_t sw, ew;
sw = clock();
warmupCUDA();
ew = clock();
cout << "warmup time:" << float(ew - sw) / 1000 << endl;
// GPU矩阵乘法
clock_t sg1, eg1;
sg1 = clock();
vectorMulCUDA(a1.data(), b1.data(), c1.data(), N);
eg1 = clock();
cout << "mul GPU time:" << float(eg1 - sg1) / 1000 << endl;
// 检查结果
for (int i = 0; i < N * N; ++i)
{
if (c0[i] != c1[i])
{
std::cerr << "mul GPU Error: Incorrect result at index " << i << std::endl;
flag = false;
break;
}
}
// GPU矩阵乘法2
clock_t sg2, eg2;
sg2 = clock();
vectorMulCUDA2(a2.data(), b2.data(), c2.data(), N);
eg2 = clock();
cout << "mul GPU2 time:" << float(eg2 - sg2) / 1000 << endl;
// 检查结果
for (int i = 0; i < N * N; ++i)
{
if (c0[i] != c2[i])
{
std::cerr << "mul GPU2 Error: Incorrect result at index " << i << std::endl;
flag = false;
break;
}
}
// GPU矩阵乘法3
clock_t sg3, eg3;
sg3 = clock();
vectorMulCUDA3(a3.data(), b3.data(), c3.data(), N);
eg3 = clock();
cout << "mul GPU3 time:" << float(eg3 - sg3) / 1000 << endl;
// 检查结果
for (int i = 0; i < N * N; ++i)
{
if (c0[i] != c3[i])
{
std::cerr << "mul GPU3 Error: Incorrect result at index " << i << std::endl;
flag = false;
break;
}
}
// 输出结果
if (flag)
{
std::cout << "successful!" << std::endl;
}
else
{
std::cout << "error!" << std::endl;
}
return 0;
}测试效果
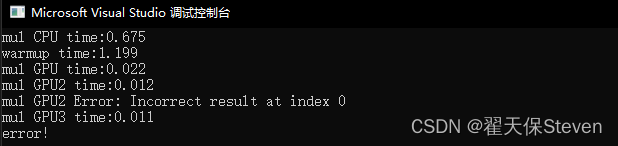
在测试代码中有一段是warmup,这是GPU预准备过程,用于执行一些额外开销,如果不进行这一步直接运行后续算法,则会耗时变长,干扰判断。
相较常规算法,共享内存法提升了约1倍,而改进的共享内存法面对矩阵1000*1000的计算,得到了正确的结果,共享内存法提示错误。如果你把矩阵尺寸改为16的整数倍,则共享内存法也可以顺利通过。
如果文章帮助到你了,可以点个赞让我知道,我会很快乐~加油!