SP(Streaming Processor)流处理器
流处理器是GPU最基本的处理单元,在fermi架构开始被叫做CUDA core。
SM(Streaming MultiProcessor)
一个SM由多个CUDA core组成。SM还包括特殊运算单元(SFU),共享内存(shared memory),寄存器文件(Register File)和调度器(Warp Scheduler)等。
可向量化循环
可向量化循环通常是指在编程中,能够被转换为向量操作或矩阵运算的循环结构。
f可以使用向量化操作的for循环。
例如,如numpy.array([1, 2, 3]) + numpy.array([4, 5, 6]),由NumPy库实现的高效矢量化计算。
识别出循环体内的操作可以并行执行,并且这些操作通常是对同维度数据执行相同类型的数学运算,比如加法、乘法等。通过将这些操作合并成单个向量操作,编译器或运行时环境可以利用SIMD(单指令多数据流)指令或其他并行计算资源,使得多个数据元素能够同时被处理。
向量化循环体
将可向量化循环转换为使用向量一次性对多个元素进行处理的方式。
grid(网格)
一个Kernel函数对应一个grid。一个Grid中会分成若干个Block。同一Grid下的不同Block可能会被分发到不同的SM上执行。同一个SM也可以执行不同grid的block。
block(线程块)
一个block可以包含多个wrap,线程块内的线程可以通过共享内存进行通信和数据共享。
同一个block内的线程会尽可能在同一SM上执行,以利用共享内存,减少通信开销。
thread(线程)
一个 cuda 的并行程序会被以许多个Thread来执行。每个Thread中的局域变量被映射到SM的寄存器上,而Thread的执行由cuda core (SP) 来完成。
cuda中每一个线程都有一个唯一标识id即threadIdx,ID随Grid和Block的划分方式的不同而变化:
// 一维的block,一维的thread
int tid = threadIdx.x + blockIdx.x * blockDim.x;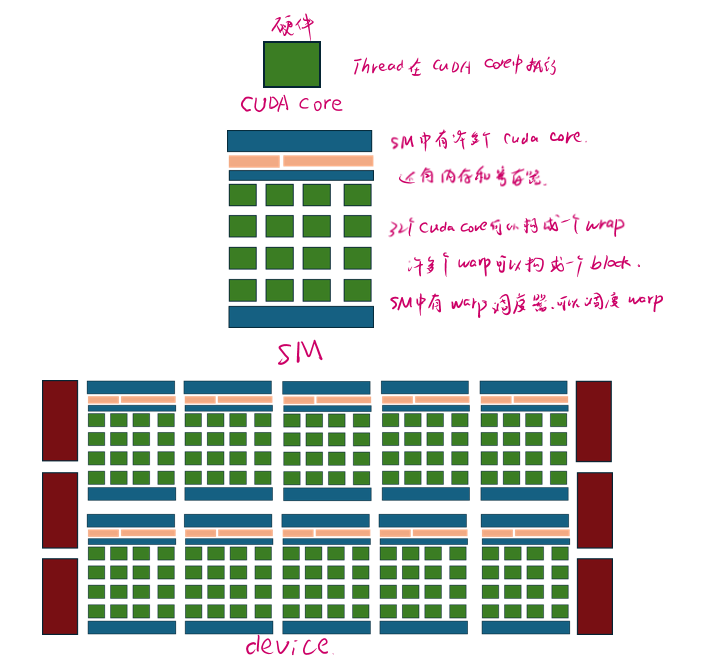
Grid、Block、Thread是一种软件组织结构,是线程组织的三个层次,并不是硬件的,因此理论上我们可以以任意的维度(一维、二维、三维)去排列Grid,Block,Thread;在硬件上就是一个个的SM或者SP,并没有维度这一说,只是软件上抽象成了具有维度的概念。
wrap(线程束)
线程束(Warp)是GPU执行程序时的基本调度单位。一个wrap通常包含32个线程,这些线程一起执行相同的指令,但是可以作用于不同的数据。在SIMT模式下,虽然warp中的线程执行相同的指令,但每个线程拥有独立的程序计数器和状态寄存器,以及各自的私有数据。
一个SM的cuda core会分成几个Warp,由Warp scheduler负责调度。
一个Warp中的线程必然在同一个block中,如果block所含线程数目不是Warp大小的整数倍,那么多出的那些thread所在的Warp中,会剩余一些inactive的thread,也就是说,即使凑不够Warp整数倍的thread,硬件也会为Warp凑足。
例:如果一个块中有128个线程,那么线程0-31将在一个Warp中,32—63将在下一个Warp中。

(内存访问)为了优化性能,设计核函数时会考虑wrap局部性,warp内的线程访问相邻的内存地址。减少内存延迟,因为warp中线程访问的数据一起被预取和处理。
(不活跃线程)如果一个block的大小不是32的整数倍,那么最后一个线程束将包含不活跃的线程,但这个线程束仍然作为一个整体被调度和执行。
(挂起与切换)在某些情况下,如等待内存访问完成时,wrap可能会挂起。GPU硬件会在此时切换到另一个可执行的线程束继续执行,以维持计算的连续性,直到所有线程束都执行完毕或遇到等待状态,这称为上下文切换。
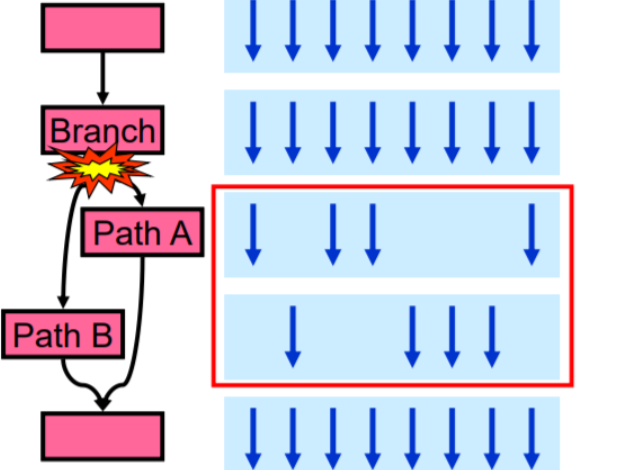
线程束发散:线程束内的线程编号连续,并且在遇到条件分支时,即使分支条件不同,所有线程也会一起执行两种可能的路径,但只有符合条件的线程会更新结果,这称为“线程束发散”。