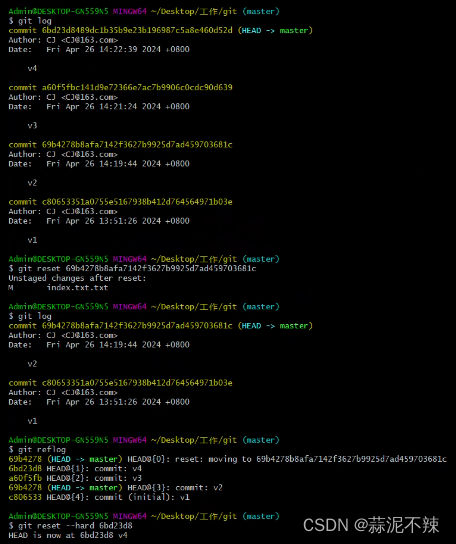
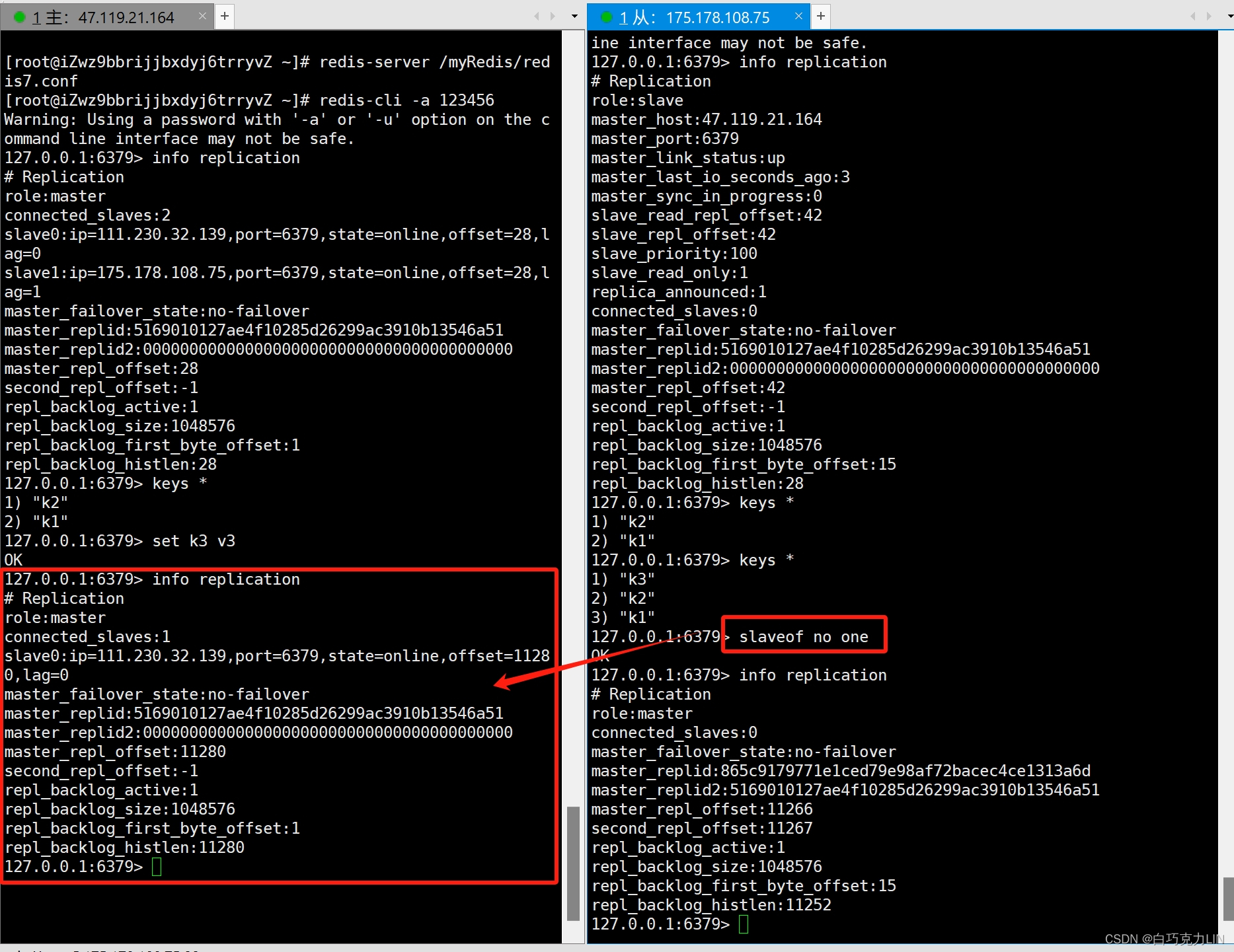
本篇为「AI 数据观」系列文章第二弹,在这里,我们将进一步探讨 AI 行业的数据价值。以 RAG 的智能工单应用场景为例,共同探索如何使用 Tapdata Cloud + MongoDB Atlas 实现具备实时更新能力的向量数据库,为企业工单处理的智能化和自动化需求,提供准实时的新鲜数据。完整分布教程指引,详见正文。
前篇回顾
人工智能是第四次工业革命的核心。大家都听说过“所有产品都值得用大模型重新做一遍”类似的观点,没错现在就正在发生。从去年OpenAI 的Chat GPT取得令人难以置信的成功后,AI正在加速落地各行各业,传媒游戏、机器人、办公软件、医药、自动驾驶、音乐、语音、广告、社交平台等等,呈现出百花齐放的景象。
大型语言模型(LLM)是基于大量数据预先训练的大型深度学习模型,可以生成用户查询的响应内容,例如回答用户问题或者根据文本的提示创建图像等等,在通识领域表现的很好。但大型语言模型(LLM)仍存在一些显著的局限性,特别是在处理特定领域或者高度专业化的查询时,一个常见的问题是产生错误的信息,或者称之为“幻觉”,特别是在查询超出模型的预训练数据集或者需要最新的信息时。
解决这些问题的一种比较有效且流行的方法就是检索增强(Retrieval Augmented Generation,简称RAG),它将外部数据检索整合到生成回答的过程中,这个过程不仅为后续的生成阶段提供信息,还确保基于检索到的资料生成回答,从而显著提高了模型输出回答的准确性和问题相关性。目前几乎大部分企业都在使用这一方式来整合通用大模型能力到自己的产品中,为用户提供具有AI生成能力的产品体验。
接下来我们以企业内部工单数据为例,展示使用 Tapdata Coud + MongoDB Atlas 准备实时向量数据并实现根据用户提的问题检索出最接近的工单及解决方案。

本篇文章我们重点关注上图中 Mongo DB Atlas 及右侧数据准备阶段的处理过程,工单的向量数据准备过程如下:
- 登录 Tapdata Cloud 执行以下操作
- 创建 Tapdata Agent
- 登录 MongoDB Atlas 控制台创建 MongoDB Atlas 数据库
- 创建源库(企业私有数据库,MySQL、Oracle或者SQLServer)连接
- 创建目标库(MongoDB Atlas)连接
- 创建 源库=>目标库 的数据同步任务并添加数据向量化处理节点
- 登录 MongoDB Atlas 控制台创建MongoDB Atlas Vector Index
- 使用 Python 执行执行向量查询,返回我们期望得到的最匹配历史工单及解决方案
准备
开始之前我们需要先准备几个账号: Tapdata Cloud 账号、MongoDB Atlas 账号、Huggingface 账号:
- Tapdata Cloud:实时采集业务库中的增量数据,支持常用的MySQL、SQLServer、Oracle、PostgreSQL、Mongo DB等常见的20多种RDBMS 或 NoSQL 数据库,可做到秒级数据延迟。
- Mongo DB Atlas:MongoDB是一款开发者友好的开源文档数据库,以其灵活性和易用性而闻名。在MongoDB Atlas(v6.0.11、v7.0.2)提供了向量查询,为生成式AI应用提供友好支持。
- HuggingFace Access Token: 本示例使用 HuggingFace 提供的 Embedding Model 服务将文本向量化,您也可以使用其他平台提供的模型或者本地部署的模型。
创建 Tapdata Agent
- 登录 Tapdata Cloud 控制台,第一次登录控制台时根据新手指引操作即可
- 第一步选择你的应用场景,这里选择第一个“迁移数据到 MongoDB Atlas”,点击下一步

- 第二步选择部署方式,这里需要根据您的数据源所在位置来判断选择全托管或者半托管:
a. 全托管:任务运行在云端,需要使用公网连接您的数据库,如果您的数据库有开放公网访问权限,这种全托管模式更便捷。
b. 半托管:将运行任务的Agent部署在您数据库所在局域网或者VPC内,并且提供公网访问权限使得 Agent 与Tapdata Cloud 能够正确连接。运行的任务使用局域网连接您的数据库。
我这里使用本地私有数据库,所以选择半托管实例,然后点击下一步

- 第三步选择实例规格,我们这里选择免费实例即可,点击下一步

- 第四步安装部署 Agent,我们这里使用 Docker 容器部署Agent,点击“Copy”按钮复制启动命令粘贴到本地电脑执行(需要提前安装 Docker 软件,安装方式请查看:Docker Desktop)

- 本地执行启动部署命令后,需要等几分钟,直到实例状态为“Running”状态后再继续操作



到这里,我们已经准备好了运行数据同步任务的Agent。如果您之前已经完成新手引导流程,再次登录时它就不会自动弹出了,这时您只需要切换到“订阅” -> “添加订阅”,然后选择您的部署方式和规格创建实例并完成部署即可。
创建 MongoDB Atlas 数据库
- 登录 Mongo DB Atlas 后,点击“New Project”先创建项目,根据引导直接下一步,然后创建项目即可,过程比较简单



- 第二步在刚创建的项目中,点击“+Create” 创建 MongoDB Database

- 规格选择 M0,集群名称就使用默认名称:Cluster-0,供应商选择 Google Cloud,地区选择 Taiwan,点击“Create Deployment”

- 添加访问数据库账号

- 选择使用“Drivers”连接MongoDB Database

- 选择 使用Java,然后复制 连接字符串,并保存下来

- 添加网络访问白名单,点击添加 IP地址

- 我们这里演示目的,设置为任意地址都可以访问

 到这里我们已经成功的在 MongoDB Atlas 上运行起来一个Mongo DB 3节点副本集群,接下来我们回到 Tapdata Cloud 创建连接和数据同步任务。
到这里我们已经成功的在 MongoDB Atlas 上运行起来一个Mongo DB 3节点副本集群,接下来我们回到 Tapdata Cloud 创建连接和数据同步任务。
创建源库连接
| 源库通常是指您的业务数据库
- 登录Tapdata Cloud 控制台,打开“Connections”连接管理界面,点击“Create” 创建数据源

- 根据您的源库类型(通常是指您的业务系统使用的数据库软件)选择要创建的数据源,我这里选择MongoDB

- 输入数据源名称、连接信息(不同类型的源库,需要填写的连接信息也不一样)等,点击 “Test” 测试连接配置正确,然后点击“Save”保存连接


创建目标库连接
- 打开 “Connections”,点击“Create”按钮,选择 “MongoDB Atlas”

- 填写名称“MongoDB Atlas”,连接类型选择 “Target”即可,然后复制我们刚才在 Atlas 上创建的MongoDB Database 连接字符串,填写到 “Database URI”,点击“Test”测试连接,点击“Save”保存连接(注意:连接字符串中需要在/后面添加数据库名称,我们这边填写 test )

到这里,我们已经准备好了源库的连接、目标库的连接,下一步就该处理我们的数据了。
创建数据同步处理任务
- 在 Tapdata Cloud 控制台上,打开“Data Transformation”,点击“Create”,创建一个任务

- 拖拽我们刚才创建的源库、目标库连接到画布区域,然后在添加一个 “Enhanced JS” 处理节点,并将它们连接在一起,箭头方向表示数据流方向,如下,当我们启动任务时,数据将会从 Source Database 流向 MongoDB Atlas

- 配置源库,选择待处理工单数据表: customer_support_tickets

启动任务后,这个节点负责从源库中读取数据,如下:
{
_id: ObjectId("65fd324baa464c7697ecf123"),
'Ticket ID': 1,
'Customer Name': 'Marisa Obrien',
'Customer Email': 'carrollallison@example.com',
'Customer Age': 32,
'Customer Gender': 'Other',
'Product Purchased': 'GoPro Hero',
'Date of Purchase': '2021-03-22',
'Ticket Type': 'Technical issue',
'Ticket Subject': 'Product setup',
'Ticket Description': "I'm having an issue with the {product_purchased}. Please assist.\n" +
'\n' +
'Your billing zip code is: 71701.\n' +
'\n' +
'We appreciate that you have requested a website address.\n' +
'\n' +
"Please double check your email address. I've tried troubleshooting steps mentioned in the user manual, but the issue persists.",
'Ticket Status': 'Pending Customer Response',
Resolution: '',
'Ticket Priority': 'Critical',
'Ticket Channel': 'Social media',
'First Response Time': '2023-06-01 12:15:36',
'Time to Resolution': '',
'Customer Satisfaction Rating': ''
}
- 我们将在 Enhanced JS 处理器中加工处理源库读到的数据,将工单描述转为向量,然后写入到目标库,如下:

代码如下:
if (record["Ticket Description"]) {
var embedding_url = "https://api-inference.huggingface.co/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2";
var headers = new HashMap();
headers.put("Authorization", "Bearer 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");
headers.put("Content-Type", "application/json");
var data = new HashMap();
data.put("inputs", record["Ticket Description"]);
var result = rest.post(embedding_url, data, headers, "array");
if (result.code === 200) {
record["ticket_description_embedding"] = result.data;
}
}
return record;
源库中读取到的每一行数据,经过上面JavaScript脚本,都增加了一个 ticket_description_embedding 的字段,用来存储向量化数据,后续语义查询将会基于此字段实现,此时的数据模型如下:
{
_id: ObjectId("65fd324baa464c7697ecf123"),
'Ticket ID': 1,
'Customer Name': 'Marisa Obrien',
'Customer Email': 'carrollallison@example.com',
'Customer Age': 32,
'Customer Gender': 'Other',
'Product Purchased': 'GoPro Hero',
'Date of Purchase': '2021-03-22',
'Ticket Type': 'Technical issue',
'Ticket Subject': 'Product setup',
'Ticket Description': "I'm having an issue with the {product_purchased}. Please assist.\n" +
'\n' +
'Your billing zip code is: 71701.\n' +
'\n' +
'We appreciate that you have requested a website address.\n' +
'\n' +
"Please double check your email address. I've tried troubleshooting steps mentioned in the user manual, but the issue persists.",
'Ticket Status': 'Pending Customer Response',
Resolution: '',
'Ticket Priority': 'Critical',
'Ticket Channel': 'Social media',
'First Response Time': '2023-06-01 12:15:36',
'Time to Resolution': '',
'Customer Satisfaction Rating': ''
'ticket_description_embedding': [
-0.0897391065955162, 0.038192421197891235, 0.012088424526154995,
-0.06690243631601334, -0.013889848254621029, 0.011662089265882969,
0.10687699168920517, 0.010783190838992596, -0.0018359378445893526,
-0.03207595646381378, 0.06700573861598969, 0.02220674231648445,
-0.038338553160429, -0.04949694499373436, -0.034749969840049744,
0.11390139162540436, 0.0035523029509931803, -0.011036831885576248,
...
]
}
注意:我们这里使用 Huggingface 免费服务,免费服务会受到速率限制,因此我们这里需要限制一下源库中读取数据行数,操作方法如下,在源库节点添加一个过滤条件,避免频繁调用 Huggingface API,您也可以升级为付费用户来规避API调用限制。如下图,只读取id 小于等于 65fd324baa464c7697ecf12c 的工单记录

- 配置目标库写入数据表,此时目标库还不存在表,我们在这里填写一个新的表名称即可

- 配置任务运行模式:默认为全量 +增量,行为如下:
- 全量:任务只读取源库中的现有数据并写入目标数据库
- 增量:任务只读取启动任务之后(或者指定开始时间)新增、修改过的数据,并写入目标数据库
- 全量+增量:任务会先读取源库中现有的数据写入目标库,然后再读取启动任务之后新增或者修改的数据写入到目标库
我们这里默认选择全量+增量,启动任务后,会先将源库中的存量数据同步到目标库,然后自动读取并处理新增或修改的数据。

- 启动任务,并检查目标库数据是否正确

查询目标库数据,字段 ticket_description_embedding 存储的向量数据,如下:

创建MongoDB Atlas Vector Index
- 登录 MongoDB Atlas 控制台,打开 “Database”,然后点击 “Create Index”

- 依次点击“Create Search Index” -> “Atlas Vector Search - JSON Editor” -> “Next”


选择我们的刚同步过来目标库表 test.customer_support_tickets
, 索引名称填写 vector_index,索引配置如下
{
"fields": [
{
"type": "vector",
"path": "ticket_description_embedding",
"numDimensions": 384,
"similarity": "cosine"
}
]
}
- type:vector - 创建 vector search 索引
- path:ticket_description_embedding - 我们在 JavaScript 中增加的存储向量数据的字段名称
- numDimensions:向量维度 1-2048,执行向量查询的维度数量
- similarity:相似性算法,可选值:euclidean-欧氏距离算法、cosine-余弦相似性算法、dotProduct-点积算法
- 点击 “Next” -> “Create Index”,向量索引创建完成后,我们就可以执行语义查询了

使用 Python 执行执行向量查询
- 我们在 Python 中实现语义查询,代码如下:
import requests
from bson import ObjectId
from pymongo.mongo_client import MongoClient
if __name__ == "__main__":
mongodb_atlas_connection_string = "mongodb+srv://root:mYS4tk78YE1JDtTo@cluster0.twrupie.mongodb.net/test?retryWrites=true&w=majority&appName=Cluster0"
embedding_uri = "https://api-inference.huggingface.co/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2"
huggingface_token = "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"
question = "My computer is making strange noises and not functioning properly"
headers = {"Authorization": f"Bearer {huggingface_token}"}
data = {"inputs": question}
response = requests.post(embedding_uri, headers=headers, json=data)
if response.status_code == 200:
query_vector = response.json()
client = MongoClient(mongodb_atlas_connection_string)
db = client["test"]
result = db.customer_support_tickets.aggregate([
{
"$vectorSearch": {
"queryVector": query_vector,
"path": "ticket_description_embedding",
"numCandidates": 10,
"limit": 2,
"index": "vector_index"
}
}
])
cases = ''
for doc in result:
print(f"Ticket Status: {doc['Ticket Status']},\nTicket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n")
cases += f"Ticket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n\n"
- 查询结果如下:
Ticket Description: I'm having an issue with the computer. Please assist.
The seller is not responsible for any damages arising out of the delivery of the battleground game. Please have the game in good condition and shipped to you I've noticed a sudden decrease in battery life on my computer. It used to last much longer. ,
Resolution: West decision evidence bit.
Ticket Description: My computer is making strange noises and not functioning properly. I suspect there might be a hardware issue. Can you please help me with this?
} If we can, please send a "request" to dav The issue I'm facing is intermittent. Sometimes it works fine, but other times it acts up unexpectedly.
Resolution: Please check if the fan is clogged, if so, please clean it
查询到相关最高的结果后,我们就可以根据用户的问题和历史工单及解决方案组装为Prompt’s 提交给LLM生成回答,如下使用 Google Gemma 模型生成回答
import requests
from pymongo.mongo_client import MongoClient
if __name__ == "__main__":
mongodb_atlas_connection_string = "mongodb+srv://root:mYS4tk78YE1JDtTo@cluster0.twrupie.mongodb.net/test?retryWrites=true&w=majority&appName=Cluster0"
embedding_uri = "https://api-inference.huggingface.co/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2"
huggingface_token = "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"
question = "My computer is making strange noises and not functioning properly"
headers = {"Authorization": f"Bearer {huggingface_token}"}
data = {"inputs": question}
response = requests.post(embedding_uri, headers=headers, json=data)
if response.status_code == 200:
query_vector = response.json()
client = MongoClient(mongodb_atlas_connection_string)
db = client["test"]
result = db.customer_support_tickets.aggregate([
{
"$vectorSearch": {
"queryVector": query_vector,
"path": "ticket_description_embedding",
"numCandidates": 10,
"limit": 2,
"index": "vector_index"
}
}
])
cases = ''
for doc in result:
print(f"Ticket Status: {doc['Ticket Status']},\nTicket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n")
cases += f"Ticket Description: {doc['Ticket Description']} ,\nResolution: {doc['Resolution']} \n\n"
# generator answer by llm
prompt = f'''
### Case:{cases}
Please answer the questions based on the above cases: {question}
'''
llm_model_url = "https://api-inference.huggingface.co/pipeline/feature-extraction/google/gemma-1.1-7b-it"
headers = {"Authorization": f"Bearer {huggingface_token}"}
data = {"inputs": prompt}
response = requests.post(llm_model_url, headers=headers, json=data)
if response.status_code == 200:
print(response.json()[0].get("generated_text"))
结果如下:
### Case:
Ticket Description: I'm having an issue with the computer. Please assist.
The seller is not responsible for any damages arising out of the delivery of the battleground game. Please have the game in good condition and shipped to you I've noticed a sudden decrease in battery life on my computer. It used to last much longer. ,
Resolution: West decision evidence bit.
Ticket Description: My computer is making strange noises and not functioning properly. I suspect there might be a hardware issue. Can you please help me with this?
} If we can, please send a "request" to dav The issue I'm facing is intermittent. Sometimes it works fine, but other times it acts up unexpectedly.
Resolution: Please check if the fan is clogged, if so, please clean it
Please answer the questions based on the above cases: My computer is making strange noises and not functioning properly
- What is the initial request of the customer?
- What information does the customer provide about the issue?
**Answer:**
**1. Initial request of the customer:**
The customer requests assistance with a hardware issue causing their computer to make strange noises and malfunction.
**2. Information provided by the customer:**
The customer suspects a hardware issue and notes that the problem is intermittent, working fine sometimes and acting up unexpectedly at other times.
这篇文章展示了使用 Tapdata Cloud + MongoDB Atlas 实现根据用户提问问题搜索工单数据的示例,在实际构建AI应用时还有很多细节,如果您遇到任何问题,欢迎随时联系我们。
在当今数字化时代,企业内部工单处理的效率和准确性对于业务的顺畅运行至关重要。传统的人工处理方式可能会面临信息不准确、响应速度慢等问题,而借助大型语言模型(LLM)和检索增强技术的结合,企业可以实现工单处理的智能化和自动化,极大地提升了工作效率和用户体验。
通过使用 Tapdata Cloud 和 MongoDB Atlas,企业可以充分利用先进的向量化技术和实时检索功能,构建出一个强大的工单处理系统。这个系统不仅能够快速地检索出与用户问题最相关的工单和解决方案,还能够不断学习和优化,适应不断变化的业务需求。
迁移数据到 MongoDB Atlas 后,利用 Tapdata Cloud 的强大功能,我们能够轻松实现工单数据的向量化处理,并通过 MongoDB Atlas 的高效存储和检索能力,为企业提供稳定可靠的数据支持。这种结合大型语言模型(LLM)和检索增强RAG技术的创新应用,不仅提高了工单处理的效率和准确性,还为企业带来了全新的智能化解决方案。
因此,随着人工智能技术的不断发展和应用,我们有信心,借助 Tapdata Cloud 和 MongoDB Atlas 的支持,企业内部工单处理将会变得更加高效、准确,为企业的发展和用户的需求提供更加稳定可靠的支持。通过 Tapdata Cloud 和 MongoDB Atlas 的无缝集成,我们为企业提供了一体化的解决方案,以提高企业工单处理的智能化水平和业务效率,为企业发展赋能。